一种基于高通量测序技术的基因定量测序方法与流程
本发明涉及基因定量测序技术领域,具体涉及一种基于高通量测序技术的基因定量测序方法。
背景技术:
pcr(聚合酶链式反应)是一种用于放大扩增特定的dna片段的分子生物学技术,它可看作是生物体外的特殊dna复制,pcr的最大特点,是能将微量的dna大幅增加。多重pcr,又称多重引物pcr或复合pcr,它是在同一pcr反应体系里加上二对以上引物,同时扩增出多个核酸片段的pcr反应,其反应原理,反应试剂和操作过程与一般pcr相同,具有高效性、系统性、经济便捷性等特点。
荧光定量pcr是1996年由美国appliedbiosystems公司推出的一种基因定量检测技术,它是通过pcr扩增时在加入一对引物的同时加入一个特异性的荧光探针,该探针为一寡核苷酸,两端分别标记一个报告荧光基团和一个淬灭荧光基团。探针完整时,报告基团发射的荧光信号被淬灭基团吸收;刚开始时,探针结合在dna任意一条单链上;pcr扩增时,taq酶的5’端-3’端外切酶活性将探针酶切降解,使报告荧光基团和淬灭荧光基团分离,从而荧光监测系统可接收到荧光信号,即每扩增一条dna链,就有一个荧光分子形成,实现了荧光信号的累积与pcr产物形成完全同步。或者使用荧光染料sybr。sybr可以结合到双链dna上面,当体系中的模板被扩增时,sybr可以有效结合到新合成的双链上面,随着pcr的进行,结合的sybr染料越来越多,被仪器检测到的荧光信号越来越强,从而达到定量检测的目的。但是目前阶段,荧光定量pcr技术一般一个反应只能检测一个靶标基因,检测效率较低,并且一般常用于mrna的水平检测,适用范围较小。
目前,高通量测序技术已广泛应用,能够同时对多个靶标基因进行测序,建库过程需要进行多重pcr,而由于引物扩增效率或者实验等等问题,多重pcr过程中存在不同引物在一次实验中扩增效率差异数倍,以及同一引物在不同的实验中差异数倍的情况,从而导致检测目的基因表达或者cnv的数据时被差异覆盖的情况,即使是通过管家基因也无法很好校正这种差异,使得基于高通量测序对多个靶标同时定量测序检测效率低,准确率低,耗时长,成本高。
技术实现要素:
本发明实施例的目的在于提供一种检测效率高,准确率高,耗时短,成本低的基于高通量测序技术的基因定量测序方法。
为实现上述目的,本发明实施例的技术方案如下:
一种基于高通量测序技术的基因定量测序方法,所述方法包括以下步骤:在所述待测的至少两个靶标基因的序列中分别增加、修改或删除至少一个碱基制备标准模板;再将所述标准模板分别克隆至载体中制备合成载体,然后将所述合成载体进行多重pcr扩增和纯化;再将所述合成载体的纯化产物等摩尔量混合得到合成载体混合物;
进一步地,所述的一种基于高通量测序技术的基因定量测序方法可以包括以下步骤:
s1:对待测的至少两个靶标基因进行浓度定量检测;
s2:在所述待测的至少两个靶标基因的序列中分别增加、修改或删除至少一个碱基制备标准模板;再将所述标准模板分别克隆至载体中制备合成载体,然后将所述合成载体进行多重pcr扩增和纯化;再将所述合成载体的纯化产物等摩尔量混合得到合成载体混合物;
s3:将合成载体混合物与靶标基因共同进行多重pcr扩增、纯化和回收;
s4:将步骤s3中多重pcr扩增的回收产物进行高通量测序分析,将每一个合成载体及每一个合成载体对应的靶标基因进行分类统计,计算合成载体与合成载体对应的靶标基因的相对表达量。
优选地,所述步骤s1中对待测的至少两个靶标基因进行定量检测可以荧光分析试剂盒(如
其中,所述步骤s2的靶标基因的序列中增加、修改或删除碱基,所述增加、修改或删除的位置需位于测序范围内,以不影响扩增效率,又能被准确识别出为前提。优选地,靶标基因的序列每100个碱基中增加、修改或删除3-20个碱基。
优选地,所述步骤s2中的载体为质粒,所述质粒可以为puc57等。
其中,所述步骤s2中所述合成载体进行多重pcr扩增的反应体系可以为常用体积的反应体系。优选地,所述反应体系为30μl,包括如下组分:20-100μmol/l的合成载体引物1-8μl、10ng合成载体、扩增试剂盒/扩增酶8-20μl,余量为无核酸酶水。
优选地,步骤s2中所述合成载体进行多重pcr扩增程序为:热启动条件为96℃3min;15-30个循环条件为96℃30sec,60℃30sec;延伸条件为72℃2min。
优选地,所述步骤s2中所述合成载体进行多重pcr扩增产物的纯化步骤如下:
1)在pcr产物中加1倍体积磁珠(即30μl体系加30μl)用移液器上下吹打,使回收产物与ampurexp磁珠充分混匀。室温静置5-10分钟。用强力磁铁或磁力架吸附磁珠,直至溶液澄清为止。用移液器吸取上清,抛弃上清,保留磁珠。
2)加入50-150μl70wt%-80wt%的乙醇,用磁力架反复在不同的两面来回吸附磁珠以充分悬浮磁珠以便洗涤。用磁铁或磁力架吸附磁珠,直至溶液澄清为止。用移液器小心去除上清,避免吸到磁珠。
3)室温放置,直至乙醇挥发干净。本步骤亦可将磁珠放于烘箱内快速蒸干乙醇。优选地,所述速蒸干乙醇的条件为将磁珠放于40-55℃烘箱2-6min。
4)加入20-100μl洗脱缓冲液,充分悬浮磁珠,室温静置2min以洗脱dna。将磁珠用磁铁吸附,所得到的上清dna溶液吸至新的1.5/0.5/0.2ml离心管/96孔pcr管。所述的洗脱缓冲液优选为10mmtris-hcl,ph8.0-8.5或te。
优选地,所述磁珠为可商购获得的ampurexp磁珠。
优选地,再将所述合成载体的纯化产物定量,等摩尔量混合后得到合成载体混合物。优选地,每次使用合成载体混合物时,取1ng稀释10-7-10-5倍使用。更优选地,每次使用合成载体混合物时,取1ng稀释10-6倍使用。
优选地,所述步骤s3中合成载体混合物与靶标基因按摩尔量的0.1-10倍混合。
优选地,所述步骤s3中进行多重pcr扩增包括两轮扩增程序:其中,第一轮扩增程序中的反应体系可以为常用体积的反应体系,优选地,所述反应体系为30μl,包括如下组分:5-50nmol/μl第一扩增引物组5-8μl、靶标基因可以为10-250ng,优选为20-200ng、每ng稀释10-7-10-5倍的合成载体混合物2-6μl、扩增试剂盒/扩增酶8-15μl,余量为无核酸酶水。
优选地,步骤s3中所述多重pcr第一轮扩增程序为:热启动条件为96℃3min;15-28个循环条件为96℃30sec,60℃4min,其中,若靶标基因为10-20ng,可以适当增加1-2循环;延伸条件为72℃2min。
优选地,所述步骤s3中所述多重pcr第一轮扩增产物的纯化步骤如下:
1)在所述中加入反应体系体积1-1.5倍的磁珠(30μl体系加30-45μl),用移液器上下吹打,使第一轮扩增产物与ampurexp磁珠充分混匀。室温静置3-10min。
2)用强力磁铁或磁力架吸附磁珠,直至溶液澄清为止。
3)抛弃上清,保留磁珠。
4)加入50-150μl70wt%-80wt%的乙醇,用磁力架反复在不同的两面来回吸附磁珠以充分悬浮磁珠以便洗涤。
5)用磁铁或磁力架吸附磁珠,直至溶液澄清为止。用移液器小心去除上清,避免吸到磁珠。
6)室温放置,直至乙醇完全挥发。本步骤亦可将磁珠放于烘箱内快速蒸干乙醇。优选地,所述快速蒸干乙醇的条件为将磁珠放于40-55℃烘箱内2-6min,快速蒸干乙醇此步绝不可省略,否则残余的乙醇会严重影响得率和后续实验。
7)等待乙醇挥发期间,可准备第二轮扩增反应。
优选地,所述磁珠为可商购获得的ampurexp磁珠。
优选地,所述第一轮扩增程序得到的扩增产物经过纯化后,再进行第二轮扩增程序,所述第二轮扩增程序的反应体系可以为常用体积的反应体系,优选地,所述反应体系为30μl,包括如下组分:5-50μmol/l第二扩增引物组2-6μl、扩增试剂盒/扩增酶8-20μl,余量为无核酸酶水。
优选地,步骤s3中所述多重pcr第二轮扩增程序为:热启动条件为96℃3min;5-15个循环条件为96℃20sec,58℃20sec,72℃30sec;延伸条件为72℃5min。
优选地,所述步骤s3中所述多重pcr第二轮扩增产物的回收步骤如下:
1)在所述多重pcr第二轮扩增产物中加入反应体系体积0.7-1.1倍的磁珠(30μl体系加21-33μl)用移液器上下吹打,使回收产物与磁珠充分混匀。室温静置5-10min。用强力磁铁或磁力架吸附磁珠,直至溶液澄清为止。用移液器吸取上清,抛弃上清,保留磁珠。
2)加入50-150μl70wt%-80wt%的乙醇,用磁力架反复在不同的两面来回吸附磁珠以充分悬浮磁珠便洗涤。
3)用磁铁或磁力架吸附磁珠,直至溶液澄清为止。用移液器小心去除上清,避免吸到磁珠。
4)室温放置,直至乙醇挥发干净。本步骤亦可将磁珠放于烘箱内快速蒸干乙醇。优选地,所述速蒸干乙醇的条件为将磁珠放于40-55℃烘箱2-6min。
5)加入20-100μl洗脱缓冲液,充分悬浮磁珠,室温静置2-6min以洗脱dna。将磁珠用磁铁吸附,所得到的上清dna溶液吸至新的1.5/0.5/0.2ml离心管/96孔pcr管。优选地,所述洗脱缓冲液为10mmtris-hcl,ph8.0-8.5或te。
其中,所述扩增试剂为本领域常用的扩增试剂盒/扩增酶,优选地,所述扩增试剂选自phusion高保真pcr扩增试剂盒(phusionhigh-fidelitypcrkit,购自thermofisher公司)、kapa高保真热启动pcr混合液(kapahifihotstartreadymix)、nebq5系列扩增酶中的至少一种。
优选地,所述扩增试剂盒/扩增酶酶活性为1-3u/μl。
所述的第一扩增引物组和第二扩增引物组均依据引物设计的常用规则。
优选地,所述第一扩增引物组为apy150panelmix引物组。
优选地,所述第二扩增引物组包括通用引物和条形码引物。
其中,所述条形码引物在高能量测序中起识别作用,不同的样品采用不同的条形码引物,更优选地,所述的条形码引物序列中包括不完全相同的6-15碱基条形码(barcode)序列,例如可以为atatctctatat,ggaattccaa。
其中,步骤s4中将步骤s3中的多重pcr第二轮扩增后的回收产物进行高通量测序分析,由于标准模板序列与靶标基因序列基本一致,序列与引物的结合也是遵循随机原则,在整个过程中引物对于合成载体中的标准模板序列和靶标基因的扩增效率是一致的。所以通过最终的合成载体拷贝数就可以计算出靶标基因的扩增量。将每一个合成载体及每一个合成载体对应的靶标基因的reads数进行分类统计,保留能识别出引物且正确配对的reads数作为有效数据,并保留靶标基因的扩增量是合成载体拷贝数的0.1-10倍的数据为有效数据,相对表达量=-log10(靶标基因reads数/合成载体reads数),靶标基因的扩增量=合成载体拷贝数*靶标基因reads数/合成载体reads数,通过上述数据处理和计算方法达到准确定量的目的。
本发明还提供所述的一种基于高通量测序技术的基因定量测序方法在检测基因变异(如拷贝数变异)中的应用。所述的判断方法为将检测样本的在特定基因或位置上的相对表达量除以对照样本的中对应的相对表达量或者除以各特定基因或位置上的相对表达量的中位数。如果得到的比值在0.7以下,则认为靶标基因存在拷贝数减少变异,如果得到的比值在1.2以上,则认为靶标基因存在拷贝数增加变异。本发明实施例具有如下优点:
本发明的基于高通量测序技术的基因定量测序方法通过在所述待测的至少两个靶标基因的序列中分别增加、修改或删除至少一个碱基制备标准模板等步骤并通过合理的数据处理和计算方法,实现了同时对多个靶标基因的定量检测,提高了检测效率,并与荧光定量pcr检测的准确率相比基本持平或更高,保证了准确率,耗时短,节约了检测测序成本。
附图说明
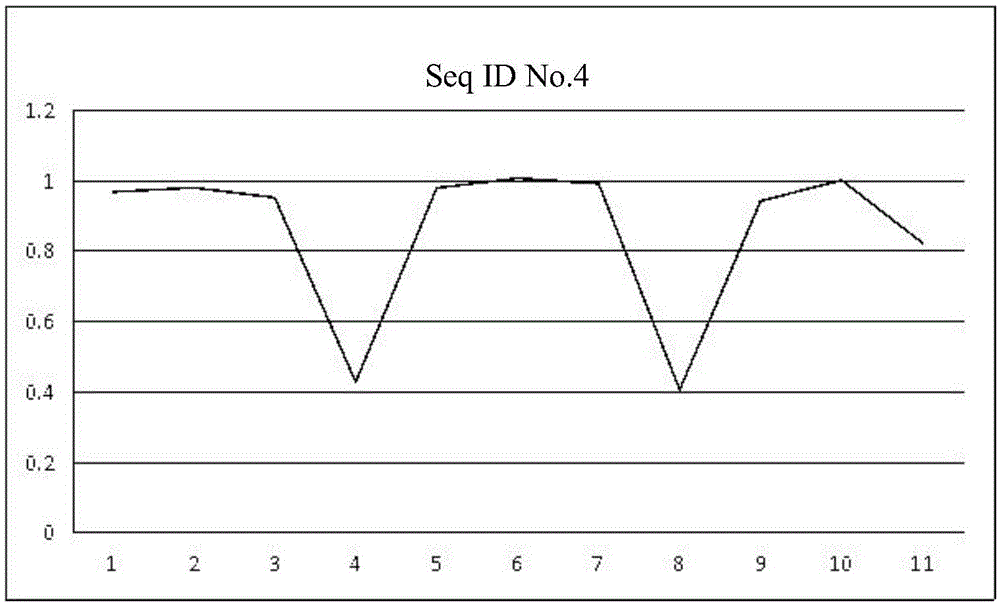
图1为本发明实施例5中seqidno.4的相对表达量除以相对表达量的中位数得到的折线图。
图2为本发明实施例5中seqidno.5的相对表达量除以相对表达量的中位数得到的折线图。
具体实施方式
以下实施例用于说明本发明,但不用来限制本发明的范围。
实施例1对待测的靶标基因进行定量检测
对待测的靶标基因seqidno.1-7所在的基因组样本进行
seqidno.1:
gaacccccatcgtgggatcttgcttataatactccactatgtagctggtgctggaactctggggttctcccaggctcttacctgtgggcatgttggtgaagggcccatagcaacagatttctagccccctgaagatctggaagaagagaggaagagagagggacaggggaatggagagaaggaaaatctagttataaaa
seqidno.2:
gaatattggcttttattcaaaaaacagactttcaaaaaggaagagcttttctttgaaaaggtacagcagactgtggaatgtatggatcatttatattacatttagtttctagtaaataacttaaatgtttttgtagtgaagattctagtagttaatgaaaatttttggtaaattcagttttggtttgttataattgttt
seqidno.3:
tacgtatggcgtttctaaacattgcataaaaattaacagcaaaaatgcagagtcttttcagtataaatatgtgggtttgcaatttataaagcagcttttccacttattttcttgacatactttgcaatgaagcagaaaacaagcttatgcatatactgcatgcaaatgatcccaagtggtccaccccaactaaagactg
seqidno.4:
aaagtatctagcactgtgtatgtatgtaataagtcttacaaaatgaagcggcccatctctgcaaaggggagtggaatacagagtggtggggtggtcaacttgagggagggagctttacctttctgtcctgggattctcttgctcgctttggaccttggtggtttcttccattgaccacatctcctctgacttcaaaatc
seqidno.5:
ctgtgcctgactggcatttggttgtacttttttttctttatctcttcactgctagaacaactatcaatttgcaattcagggtgggcttagatttctactgactactagttcaagcgcatgaatatgcctggtagaagacttcctcctcagcctattctttttaggtgcttttgaattgtggatatttaattcgagttcc
seqidno.6:
caaacttcctgagttttcatggacagcacttgagtgtcattcttgggatattcaacacttacactccaaacctgtgtcaagcacaaatgattttcaatagctcttcaacaagttgactaaatctcgtactttcttgtaggctcctgaaattaaattgtttgagaaacacactcagcaagtgattatcaaccttttaagg
seqidno.7:
gaaaagacatgtaaacaaataaaaataagatgcagcaacagtagaaaacctctattcattatcatggaaaatttgtgcattgttaaggaaagtggtgcattgatggaaggaagcaaataactatatgactgaatgaatatctctggttagtttgtaacatcaagtacttacctcattcagcatttttctttctttaata
实施例2制备标准模板和合成载体混合物
a.在待测的seqidno.1-7靶标基因的序列中分别增加gcggccgc8个碱基,并制备出如下所示对应的seqidno.1-7(standard)标准模板,将标准模板序列克隆至质粒puc57中制备合成质粒。
seqidno.1(standard):
gaacccccatcgtgggatcttgcttataatactccactatgtagcggccgcgctggtgctggaactctggggttctcccaggctcttacctgtgggcatgttggtgaagggcccatagcaacagatttctagccccctgaagatctggaagaagagaggaagagagagggacaggggaatggagagaaggaaaatctagttataaaa
seqidno.2(standard):
gaatattggcttttattcaaaaaacagactttcaaaaaggaagagcttttctttgaaaaggtacagcagactgtggaatgtatggatcatttatattacagcggccgctttagtttctagtaaataacttaaatgtttttgtagtgaagattctagtagttaatgaaaatttttggtaaattcagttttggtttgttataattgttt
seqidno.3(standard):
tacgtatggcgtttctaaacattgcataaaaattaacagcaaaaatgcagagtcttttcagtataaatatgtgggtttgcaatttataaagcagcttttccacttattttcttgcggccgcgacatactttgcaatgaagcagaaaacaagcttatgcatatactgcatgcaaatgatcccaagtggtccaccccaactaaagactg
seqidno.4(standard):
aaagtatctagcactgtgtatgtatgtaataagtcttacaaaatgaagcggcccatctctgcaaaggggagtggaatacagagtggtggggtggcggccgcgtcaacttgagggagggagctttacctttctgtcctgggattctcttgctcgctttggaccttggtggtttcttccattgaccacatctcctctgacttcaaaatc
seqidno.5(standard):
ctgtgcctgactggcatttggttgtacttttttttctttatctcttcactgctagaacaactatcaatttgcaattcaggcggccgcggtgggcttagatttctactgactactagttcaagcgcatgaatatgcctggtagaagacttcctcctcagcctattctttttaggtgcttttgaattgtggatatttaattcgagttcc
seqidno.6(standard):
caaacttcctgagttttcatggacagcacttgagtgtcattcttgggatattcaacacttacactccaaacctgtgtcagcggccgcagcacaaatgattttcaatagctcttcaacaagttgactaaatctcgtactttcttgtaggctcctgaaattaaattgtttgagaaacacactcagcaagtgattatcaaccttttaagg
seqidno.7(standard):
gaaaagacatgtaaacaaataaaaataagatgcagcaacagtagaaaacctctattcattatcatggaaaatttgtgcattgttaaggaaagtggtgcattgatggaaggaagcaaatagcggccgcactatatgactgaatgaatatctctggttagtttgtaacatcaagtacttacctcattcagcatttttctttctttaata
b.合成质粒按照如下反应体系和扩增程序进行多重pcr扩增:
采用0.2mlpcr管/96孔pcr板,在超净台里按照如下体系配置反应:
其中,合成质粒引物f/r的序列如下所示:
合成质粒引物f为seqidno.8:
cgccagggttttcccagtcacgac
合成质粒引物r为seqidno.9:
agcggataacaatttcacacagga
pcr结束后,采用ampurexp磁珠纯化产物,纯化步骤如下:
1)pcr产物中加1倍体积的ampurexp磁珠(30μl体系加30μl)用移液器上下吹打,使回收产物与ampurexp磁珠充分混匀。室温静置5-10分钟。用强力磁铁或磁力架吸附磁珠,直至溶液澄清为止。用移液器吸取上清,抛弃上清,保留磁珠。
2)加入100μl70wt%乙醇,用磁力架反复在不同的两面来回吸附磁珠以充分悬浮磁珠便洗涤。用磁铁或磁力架吸附磁珠,直至溶液澄清为止。用移液器小心去除上清,避免吸到磁珠。
3)将磁珠亦可放于50℃烘箱2min,快速蒸干乙醇。
4)加入20μl10mmtris-hcl,ph8.0-8.5洗脱缓冲液,充分悬浮磁珠,室温静置2min以洗脱dna。将磁珠用磁铁吸附,所得到的上清dna溶液吸至新的0.5ml离心管,得到pcr产物。
c.将得到的pcr产物混合制备合成载体混合物
将步骤b的纯化产物定量,按照等质量混合,混合后产物即为合成载体混合物母液,每次使用时,取1ng稀释10-6倍使用。
实施例3将合成载体混合物与靶标基因共同进行多重pcr扩增、纯化和回收
a.合成载体混合物与靶标基因共同进行多重pcr第一轮扩增反应:
采用0.2mlpcr管/96孔pcr板,在超净台里按照如下第一轮扩增体系配置反应:
其中,所述apy150panelmix引物组包括如下序列:
seqidno.10:
gaacccccatcgtgggatcttgctctcttcctctcttcttccagatc
seqidno.11:
tattggcttttattcaaaaaacagactttcattaactactagaatcttcac
seqidno.12:
taaacattgcataaaaattaacagcagaccacttgggatcatttgcatgca
seqidno.13:
agcactgtgtatgtatgtaataagtcttaggagatgtggtcaatggaagaaaccac
seqidno.14:
ctcttcactgctagaacaactatcaatggaactcgaattaaatatccacaa
seqidno.15:
cttcctgagttttcatggacagcacttgaggagtgtgtttctcaaacaatttaatttcagg
seqidno.16:
aagatgcagcaacagtagaaaaccgaaaaatgctgaatgaggtaagtacttgatg
多重pcr第一轮扩增程序:
b.多重pcr第一轮扩增产物的纯化步骤如下:
1)在多重pcr第一轮扩增产物反应液中加入1.1倍体积ampurexpbeads(30μl体系加33μl),用移液器上下吹打,使扩增产物与ampurexpbeads充分混匀。室温静置5分钟。
2)用强力磁铁或磁力架吸附磁珠,直至溶液澄清为止。
3)抛弃上清,保留磁珠。
4)加入100μl70%乙醇,用磁力架反复在不同的两面来回吸附磁珠以充分悬浮磁珠便洗涤。
5)用磁铁或磁力架吸附磁珠,直至溶液澄清为止。用移液器小心去除上清,避免吸到磁珠。
6)将磁珠放于50℃烘箱2min,快速蒸干乙醇。
7)等待乙醇挥发期间,可准备第二轮扩增反应。
c.多重pcr第二轮扩增反应:
第一轮扩增程序得到的扩增产物经过纯化后,所得带有磁珠的管中加入以下pcr体系:
其中,第二轮pcr通用引物f和条形码(barcode)引物中,
通用引物f为seqidno.17:
aatgatacggcgaccaccgagatctacactctttccctacacgacgctcttccg
条形码(barcode)引物通式为caagcagaagacggcatacgagat(barcode)gtgactggagttccttggcacccgagaattcca,不同的样本采用不同的条形码(barcode)引物。
多重pcr第二轮扩增程序:
d.多重pcr第二轮扩增产物的回收步骤如下:
1)pcr产物中加0.8倍体积ampurexp磁珠(30μl体系加24μl)用移液器上下吹打,使回收产物与ampurexp磁珠充分混匀。室温静置5-10分钟。用强力磁铁或磁力架吸附磁珠,直至溶液澄清为止。用移液器吸取上清,抛弃上清,保留磁珠。
2)加入100μl70wt%乙醇,用磁力架反复在不同的两面来回吸附磁珠以充分悬浮磁珠便洗涤。
3)用磁铁或磁力架吸附磁珠,直至溶液澄清为止。用移液器小心去除上清,避免吸到磁珠。
4)将磁珠放于50℃烘箱2min,快速蒸干乙醇。
5)加入20μl10mmtris-hcl,ph8.0-8.5的洗脱缓冲液,充分悬浮磁珠,室温静置2min以洗脱dna。将磁珠用磁铁吸附,所得到的上清dna溶液吸至新的0.5ml离心管。
实施例4将实施例3中多重pcr扩增的回收产物进行高通量测序分析
将实施例3的多重pcr第二轮扩增后的回收产物进行高通量测序分析,将每一个合成质粒及每一个合成质粒对应的靶标基因的reads数的样本进行统计,保留能识别出引物且正确配对的reads数作为有效数据,并保留靶标基因的扩增量是合成载体拷贝数的0.1-10倍的数据为有效数据,
相对表达量=-log10(靶标基因reads数/合成载体reads数),靶标基因的扩增量=合成载体拷贝数*靶标基因reads数/合成载体reads数,通过上述数据处理和计算方法得到的11个样本的检测结果如下表1、表2、图1和图2所示。
表1
表2
通过以上数据可知,本发明的基于高通量测序技术的基因定量测序方法实现了同时对多个靶标基因的定量检测,提高了检测效率,保证了准确率,整个测序程序耗时不超过24小时,耗时短,节约了检测测序成本。
另外,将上表中相对表达量除以相对表达量的中位数,如果得到的数值为0.7以下,则能够确定靶标基因存在变异,经计算并从图1和图2可以看出,seqidno.4和seqidno.5存在部分缺失序列。
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
序列表
<110>上海优甲医疗科技有限公司
<120>一种基于高通量测序技术的基因定量测序方法
<130>gg18296548a
<160>24
<170>siposequencelisting1.0
<210>1
<211>199
<212>dna
<213>人工序列(artificialsequence)
<400>1
gaacccccatcgtgggatcttgcttataatactccactatgtagctggtgctggaactct60
ggggttctcccaggctcttacctgtgggcatgttggtgaagggcccatagcaacagattt120
ctagccccctgaagatctggaagaagagaggaagagagagggacaggggaatggagagaa180
ggaaaatctagttataaaa199
<210>2
<211>199
<212>dna
<213>人工序列(artificialsequence)
<400>2
gaatattggcttttattcaaaaaacagactttcaaaaaggaagagcttttctttgaaaag60
gtacagcagactgtggaatgtatggatcatttatattacatttagtttctagtaaataac120
ttaaatgtttttgtagtgaagattctagtagttaatgaaaatttttggtaaattcagttt180
tggtttgttataattgttt199
<210>3
<211>199
<212>dna
<213>人工序列(artificialsequence)
<400>3
tacgtatggcgtttctaaacattgcataaaaattaacagcaaaaatgcagagtcttttca60
gtataaatatgtgggtttgcaatttataaagcagcttttccacttattttcttgacatac120
tttgcaatgaagcagaaaacaagcttatgcatatactgcatgcaaatgatcccaagtggt180
ccaccccaactaaagactg199
<210>4
<211>199
<212>dna
<213>人工序列(artificialsequence)
<400>4
aaagtatctagcactgtgtatgtatgtaataagtcttacaaaatgaagcggcccatctct60
gcaaaggggagtggaatacagagtggtggggtggtcaacttgagggagggagctttacct120
ttctgtcctgggattctcttgctcgctttggaccttggtggtttcttccattgaccacat180
ctcctctgacttcaaaatc199
<210>5
<211>199
<212>dna
<213>人工序列(artificialsequence)
<400>5
ctgtgcctgactggcatttggttgtacttttttttctttatctcttcactgctagaacaa60
ctatcaatttgcaattcagggtgggcttagatttctactgactactagttcaagcgcatg120
aatatgcctggtagaagacttcctcctcagcctattctttttaggtgcttttgaattgtg180
gatatttaattcgagttcc199
<210>6
<211>199
<212>dna
<213>人工序列(artificialsequence)
<400>6
caaacttcctgagttttcatggacagcacttgagtgtcattcttgggatattcaacactt60
acactccaaacctgtgtcaagcacaaatgattttcaatagctcttcaacaagttgactaa120
atctcgtactttcttgtaggctcctgaaattaaattgtttgagaaacacactcagcaagt180
gattatcaaccttttaagg199
<210>7
<211>199
<212>dna
<213>人工序列(artificialsequence)
<400>7
gaaaagacatgtaaacaaataaaaataagatgcagcaacagtagaaaacctctattcatt60
atcatggaaaatttgtgcattgttaaggaaagtggtgcattgatggaaggaagcaaataa120
ctatatgactgaatgaatatctctggttagtttgtaacatcaagtacttacctcattcag180
catttttctttctttaata199
<210>8
<211>207
<212>dna
<213>人工序列(artificialsequence)
<400>8
gaacccccatcgtgggatcttgcttataatactccactatgtagcggccgcgctggtgct60
ggaactctggggttctcccaggctcttacctgtgggcatgttggtgaagggcccatagca120
acagatttctagccccctgaagatctggaagaagagaggaagagagagggacaggggaat180
ggagagaaggaaaatctagttataaaa207
<210>9
<211>207
<212>dna
<213>人工序列(artificialsequence)
<400>9
gaatattggcttttattcaaaaaacagactttcaaaaaggaagagcttttctttgaaaag60
gtacagcagactgtggaatgtatggatcatttatattacagcggccgctttagtttctag120
taaataacttaaatgtttttgtagtgaagattctagtagttaatgaaaatttttggtaaa180
ttcagttttggtttgttataattgttt207
<210>10
<211>207
<212>dna
<213>人工序列(artificialsequence)
<400>10
tacgtatggcgtttctaaacattgcataaaaattaacagcaaaaatgcagagtcttttca60
gtataaatatgtgggtttgcaatttataaagcagcttttccacttattttcttgcggccg120
cgacatactttgcaatgaagcagaaaacaagcttatgcatatactgcatgcaaatgatcc180
caagtggtccaccccaactaaagactg207
<210>11
<211>207
<212>dna
<213>人工序列(artificialsequence)
<400>11
aaagtatctagcactgtgtatgtatgtaataagtcttacaaaatgaagcggcccatctct60
gcaaaggggagtggaatacagagtggtggggtggcggccgcgtcaacttgagggagggag120
ctttacctttctgtcctgggattctcttgctcgctttggaccttggtggtttcttccatt180
gaccacatctcctctgacttcaaaatc207
<210>12
<211>207
<212>dna
<213>人工序列(artificialsequence)
<400>12
ctgtgcctgactggcatttggttgtacttttttttctttatctcttcactgctagaacaa60
ctatcaatttgcaattcaggcggccgcggtgggcttagatttctactgactactagttca120
agcgcatgaatatgcctggtagaagacttcctcctcagcctattctttttaggtgctttt180
gaattgtggatatttaattcgagttcc207
<210>13
<211>207
<212>dna
<213>人工序列(artificialsequence)
<400>13
caaacttcctgagttttcatggacagcacttgagtgtcattcttgggatattcaacactt60
acactccaaacctgtgtcagcggccgcagcacaaatgattttcaatagctcttcaacaag120
ttgactaaatctcgtactttcttgtaggctcctgaaattaaattgtttgagaaacacact180
cagcaagtgattatcaaccttttaagg207
<210>14
<211>207
<212>dna
<213>人工序列(artificialsequence)
<400>14
gaaaagacatgtaaacaaataaaaataagatgcagcaacagtagaaaacctctattcatt60
atcatggaaaatttgtgcattgttaaggaaagtggtgcattgatggaaggaagcaaatag120
cggccgcactatatgactgaatgaatatctctggttagtttgtaacatcaagtacttacc180
tcattcagcatttttctttctttaata207
<210>15
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>15
cgccagggttttcccagtcacgac24
<210>16
<211>24
<212>dna
<213>人工序列(artificialsequence)
<400>16
agcggataacaatttcacacagga24
<210>17
<211>47
<212>dna
<213>人工序列(artificialsequence)
<400>17
gaacccccatcgtgggatcttgctctcttcctctcttcttccagatc47
<210>18
<211>51
<212>dna
<213>人工序列(artificialsequence)
<400>18
tattggcttttattcaaaaaacagactttcattaactactagaatcttcac51
<210>19
<211>51
<212>dna
<213>人工序列(artificialsequence)
<400>19
taaacattgcataaaaattaacagcagaccacttgggatcatttgcatgca51
<210>20
<211>56
<212>dna
<213>人工序列(artificialsequence)
<400>20
agcactgtgtatgtatgtaataagtcttaggagatgtggtcaatggaagaaaccac56
<210>21
<211>51
<212>dna
<213>人工序列(artificialsequence)
<400>21
ctcttcactgctagaacaactatcaatggaactcgaattaaatatccacaa51
<210>22
<211>61
<212>dna
<213>人工序列(artificialsequence)
<400>22
cttcctgagttttcatggacagcacttgaggagtgtgtttctcaaacaatttaatttcag60
g61
<210>23
<211>55
<212>dna
<213>人工序列(artificialsequence)
<400>23
aagatgcagcaacagtagaaaaccgaaaaatgctgaatgaggtaagtacttgatg55
<210>24
<211>54
<212>dna
<213>人工序列(artificialsequence)
<400>24
aatgatacggcgaccaccgagatctacactctttccctacacgacgctcttccg54
- 还没有人留言评论。精彩留言会获得点赞!