检测树鼩NF-κB基因转录水平的引物、试剂盒及方法与流程
本发明属于分子生物技术领域,具体涉及一种检测树鼩nf-κb基因转录水平的引物、试剂盒及方法。
背景技术:
nf-κb(核因子κb)参与细胞增殖、分化和凋亡等多种生物学过程,是细胞内重要的转录因子。其水平的异常上调将导致多种疾病的发生,是炎症与免疫反应的重要影响因子。
急性肾损伤(aki)以肾功能突然恶化为特征,可通过血清肌酐(scr)或少尿的增加来诊断。aki与心血管疾病、慢性肾脏疾病(ckd)和终末期肾脏疾病(esrd)的风险增加以及死亡率增加相关。据报道,大约一半的脓毒症患者会发生aki,并将死亡率提高六到八倍。tlr4的激活使nf-κb通路敏感,这与启动促炎性细胞因子il-1β、il-6和tnf-α的表达有关。tlr4/nf-κb途径的激活已被确定为肾脏炎症的主要诱因。此外,已经证实抑制tlr4/nf-κb介导的炎症反应对lps诱导的aki具有肾脏保护作用。抑制tlr4/nf-κb途径的可能机制包括靶向核因子κb激酶抑制剂和抑制其他酶。高尿酸血症将会引起肾损伤,所以研究尿酸对nf-κb的影响具有意义。
文献报道中对nf-κb的研究主要集中在其结构、序列、功能上,对转录水平的检测方法的研究国内外未见报道。
技术实现要素:
本发明的目的是为了解决现有技术的不足,提供一种检测树鼩nf-κb基因转录水平的引物、试剂盒及方法,以在转录水平上对nf-κb基因进行定量检测。
为实现上述目的,本发明采用的技术方案如下:
检测树鼩nf-κb基因转录水平的引物,包括树鼩nf-κb基因表达水平的特异性上、下游引物和作为内参基因的树鼩gapdh基因的特异性上、下游引物;
其中,树鼩nf-κb基因表达水平的特异性上、下游引物序列如下:
nf-κbf:5'-cagaaattgggcctggggat-3';
nf-κbr:5'-ttcagtgtggcccatctgtc-3';
作为内参基因的树鼩gapdh基因的特异性上、下游引物序列如下:
gapdhf:5'-agccccatcaccatcttcc-3';
gapdhr:5'-aatgagccccagccttctc-3'。
本发明同时提供含有上述检测树鼩nf-κb基因转录水平的引物的试剂盒。
本发明还提供上述引物、试剂盒在非诊断目的检测树鼩nf-κb基因转录水平的应用。
本发明另外提供用于非诊断目的检测树鼩nf-κb基因转录水平的方法,包括如下步骤:
步骤(1),分别以健康和待测树鼩新鲜肾脏组织提取的总rna为模板,逆转录合成得树鼩肾脏组织cdna第一链;
步骤(2),建立树鼩gapdh基因及nf-κb基因标准曲线:以easydilution梯度稀释步骤(1)得到的健康树鼩肾脏组织cdna第一链,分别以未稀释cdna第一链及稀释后的cdna为模板,进行实时荧光定量检测,并分别以nf-κbf和nf-κbr、gapdhf和gapdhr为特异性引物,进行实时荧光定量pcr扩增,分别得到健康树鼩nf-κb基因、gapdh基因的溶解曲线和扩增曲线;
之后以起始模板量拷贝数log10的对数值为x轴,以ct值为y轴进行绘制,分别得到gapdh基因、nf-κb基因的标准曲线;
步骤(3),将步骤(1)得到的待测树鼩肾脏组织cdna第一链分别以nf-κbf和nf-κbr、gapdhf和gapdhr为特异性引物,进行实时荧光定量pcr扩增,扩增体系和扩增程序与步骤(2)相同,分别得到待测树鼩nf-κb基因、gapdh基因的溶解曲线和扩增曲线;
之后根据步骤(2)得到的标准曲线进行计算,得到树鼩nf-κb基因转录水平。
基于实时荧光定量检测的原理,即每个模板的cq值与该模板的起始拷贝数的对数存在线性关系,公式如下:cq=-1/lg(1+ex)*lgx0+lgn/lg(1+ex)(n为扩增反应的循环次数,x0为初始模板量,ex为扩增效率,n为荧光扩增信号达到阈值强度时扩增产物的量。)起始拷贝数越多,cq值越小。利用已知起始拷贝数的标准品可作出标准曲线,其中横坐标代表起始拷贝数的对数,纵坐标代cq值。因此,获得未知样品的cq值,即可从标准曲线上计算出该样品的起始拷贝数。所以根据步骤(2)得到的标准曲线和每个样品的cq值,利用bio-radcfxmanager3.1软件中自带的基因表达计算功能就能得到树鼩nf-κb基因转录水平。
进一步,优选的是,以easydilution梯度稀释步骤(1)树鼩肾脏组织cdna第一链,梯度稀释倍数分别为5倍、25倍、125倍、625倍。
进一步,优选的是,实时荧光定量pcr扩增体系下:sybrpremixextaqii(2x)5μl,上、下游引物各0.4μl,cdna模板0.8μl,去离子水3.4μl,总计10μl,上、下游引物浓度均为10μm。
进一步,优选的是,实时荧光定量pcr扩增程序为:95℃预变性30s,95℃变性10s、60℃退火30s、40个循环。
在检测时,当溶解曲线上峰不唯一时,则说明实验中存在污染,需要重新进行检测。
本发明与现有技术相比,其有益效果为:
本发明适用于实时荧光定量pcr检测。应用本发明所公开的引物序列可实现对树鼩gapdh基因及nf-κb基因的特异性扩增,对材料中非目的基因没有扩增信号,通过本发明的引物可对树鼩nf-κb基因转录水平的变化情况实施定量检测,其操作简单,可重复性高,特异性强,灵敏度好。本发明为研究树鼩nf-κb基因的功能及影响因素提供了有效工具。
附图说明
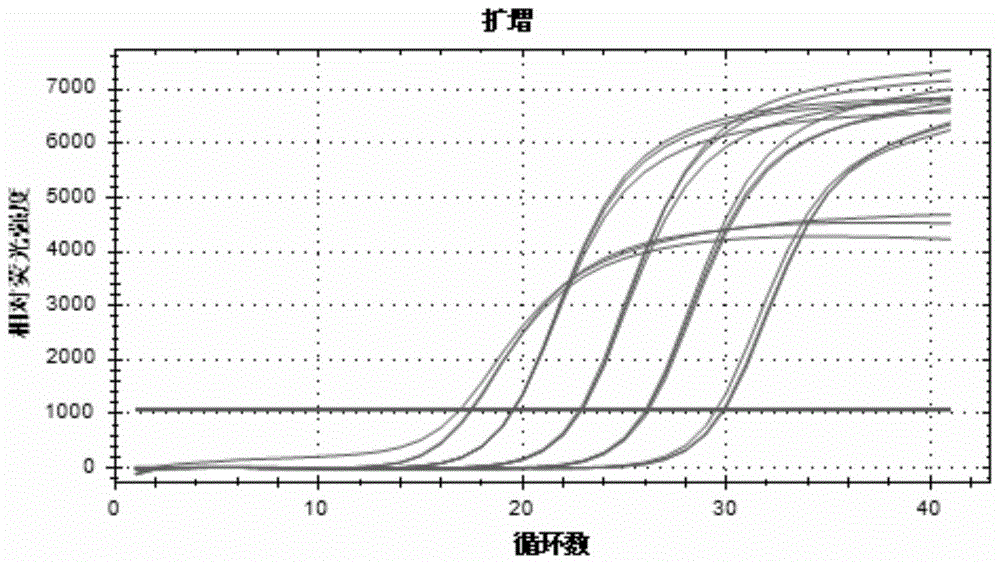
图1树鼩gapdh基因的扩增曲线;
图2树鼩gapdh基因的标准曲线;
图3树鼩nf-κb基因的扩增曲线;
图4树鼩nf-κb基因的标准曲线;
图5树鼩gapdh基因的表达扩增曲线;
图6树鼩gapdh基因的表达熔解峰;
图7树鼩nf-κb基因的表达扩增曲线;
图8树鼩nf-κb基因的表达熔解峰;
图9树鼩nf-κb基因的表达相对表达;
图10树鼩nf-κb基因扩增产物胶图,m:maker;1~4为四只不同的树鼩扩增产物胶图。
具体实施方式
下面结合实施例对本发明作进一步的详细描述。
本领域技术人员将会理解,下列实施例仅用于说明本发明,而不应视为限定本发明的范围。实施例中未注明具体技术或条件者,按照本领域内的文献所描述的技术或条件或者按照产品说明书进行。所用材料或设备未注明生产厂商者,均为可以通过购买获得的常规产品。
下述实施例中所使用的试验方法,如无特殊说明,均为常规方法。
下述实施例中所使用的材料试剂等,如无特殊说明,均为商业途径得到。
1、本实施例中所使用的实验动物:树鼩,雌性9只,雄性10只。
2、实验动物的分组及给药:将做过空白血清检测的19只树鼩取出1只雄性树鼩待取肾脏组织做标准曲线,剩余18只树鼩随机分成对照组、30天给药组,120天给药组,各6只。雌雄各半,雌性体重均在110g~135g,雄性体重均在120g~150g。对照组每日腹腔注射(ip)质量浓度为1%羧甲基纤维素钠溶液(cmc-na,1g羧甲基纤维素钠溶于100ml去离子水)40mg/kg,给药时间为120天,给药组以同样剂量ip注射氧嗪酸钾(oa),给药时间分别为30天和120天。
3、实验方法
3.1大鼠肾脏组织的采集
取肾脏组织置于rna助溶剂(tripure,roche公司)用于nf-κb基因转录水平的检测。
3.2肾脏总rna的提取
19只动物都取新鲜肾脏0.1g于匀浆器中,加入1mltripure在室温下充分匀浆,静置5min,再将其转移至1.5mlep管中静置5min,加入200μl-20℃预冷的氯仿,漩涡震荡充分,静置15min后4℃、12000r/min离心25min,吸取上清液450μl于另一只1.5mlep管中,等体积加入-20℃预冷的异丙醇,充分混匀静置10min,4℃、12000r/m离心10min,弃上清液,待管内壁稍干,加1ml-20℃预冷的体积百分浓度为75%乙醇洗涤沉淀,4℃、7500r/m离心5min,弃上清液,待管内壁稍干,加入30μldepc水溶解沉淀,65℃水浴10min,所提取的总rna样品取1μl经nanodrop-1000超微量核酸测定仪测定浓度及吸光度比值。测定浓度后加depc水稀释至1000ng/μl,放入-80℃冰箱备用。
3.3cdna的合成
按照逆转录试剂盒primescript™rtreagentkit说明操作,每30μl体系中依次加入5×primescriptbuffer6μl,primescriptrtenzymemix1.5μl,oligodtprimer1.5μl,random6mers1.5μl,总rna(浓度稀释为1000ng/μl)3μl,rnasefreedh2o16.5μl,逆转录条件为:37℃15min,85℃5s,4℃10min。
3.4目的基因引物的设计
根据ncbi基因库中树鼩的nf-κb和gapdh的基因序列,利用引物设计软件pimerexpress5.0分别进行引物设计,经上海生工公司合成,gapdh作为内参基因。
3.5本实施例树鼩nf-κb基因表达水平定量用引物序列及片段大小见表1.
表1
3.6目的基因荧光定量pcr反应体系的确定
按takara生物有限公司产品pcr试剂(sybrpremixextaqii),在实时荧光定量仪cfx96real-timesystem上进行扩增和数据分析,pcr扩增体系如下:sybrpremixextaqii(2x)5μl,上、下游引物各0.4μl,cdna模板0.8μl,去离子水3.4μl,总计10μl,上、下游引物浓度均为10μm;进行下列pcr扩增:95℃预变性30s,95℃变性10s、60℃退火30s、40个循环。
其中,所扩增的树鼩nf-κb基因片段的核苷酸序列如seqidno.5所示;所扩增的树鼩内参基因gapdh片段的核苷酸序列如seqidno.6所示。
3.7树鼩gapdh基因及nf-κb基因标准曲线的建立:以easydilution梯度稀释步骤3.3逆转录合成的未给药树鼩肾脏cdna第一链,分别依次对其5倍、25倍、125倍、625倍稀释,以原始cdna第一链及稀释后的cdna为模板,各做2个平行样进行实时荧光定量检测,按步骤3.6荧光定量pcr体系进行实时荧光定量pcr。实时荧光定量检测的原理,即每个模板的cq值与该模板的起始拷贝数的对数存在线性关系,公式如下:ct=-1/lg(1+ex)*lgx0+lgn/lg(1+ex)(n为扩增反应的循环次数,x0为初始模板量,ex为扩增效率,n为荧光扩增信号达到阈值强度时扩增产物的量。)起始拷贝数越多,cq值越小。基于以上原理,利用bio-radcfxmanager3.1软件可得到nf-κb基因和gapdh基因的溶解曲线和标准曲线。
3.8样品基因表达差异分析
根据步骤3.7得到的nf-κb基因和gapdh基因标准曲线和每个样品的cq值,利用bio-radcfxmanager3.1软件中自带的基因表达计算功能就能得到树鼩nf-κb基因转录水平。
4结果
4.1树鼩nf-κb基因荧光定量pcr反应的溶解曲线
由图8和图10可见,在nf-κb基因扩增过程中荧光定量pcr反应的溶解曲线仅见单独的峰,反应产物的电泳结果仅见一条特异性表达条带,表明扩增的目的片段特异性良好。
4.2树鼩nf-κb基因和gapdh基因的标准曲线
由图2和图4可见,树鼩nf-κb基因和gapdh基因的标准曲线r2均接近1,说明以此标准曲线进行相对定量较准确,由于荧光强度均较强,故能保证荧光强度的增加与pcr的扩增相对同步,能准确检测pcr的表达,以gapdh为内源控制物,得到mrna表达水平的变化。
4.3氧嗪酸钾所致的高尿酸血症树鼩肾脏组织nf-κbmrna表达水平的变化的定量检测
步骤2各组所获得的新鲜肾脏组织所提取的rna,反转录得cdna,经实时荧光定量pcr检测,可得各组nf-κbmrna表达水平差异,腹腔注射40mg/kg剂量的氧嗪酸钾,nf-κb在肾脏的mrna表达水平,对照组为1.1,30天给药组为1.0,较对照组下调。120天给药组为1.3,较对照组上调;见图9。
4.4氧嗪酸钾(oa)是尿酸酶抑制剂,能通过抑制尿酸酶活性,减少尿酸的分解与排泄,使尿酸值升高,可造成树鼩高尿酸血症,在灵长类动物造模中运用较多,用于上述实施例可使nf-κbmrna表达上调;说明本发明可用于nf-κbmrna表达水平的检测,为研究树鼩nf-κb基因的功能及影响因素提供了有效工具,为高尿酸血症等疾病的研究提供可靠手段。
以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
序列表
seqidno.1
cagaaattgggcctggggat20
seqidno.2
ttcagtgtggcccatctgtc20
seqidno.3
agccccatcaccatcttcc19
seqidno.4
aatgagccccagccttctc19
seqidno.5
cagaaattgggcctggggatacttaataatgccttccggcttagccctgccccttcaaaa60
acactgatggacaactacgaggtctccgggggaacagtcagagagctggtggaggccctg120
agacagatgggat133
seqidno.6
ggcacagtcaaggctgagaatgggaagctggtcatcaacgggaaacccatcaccatcttc60
caggagcgagatcccgctaacatcaaatggggtgatgctggtgctgagtatgtcgtggag120
tctactggcgtcttcaccaccat143
序列表
<110>中国医学科学院医学生物学研究所
<120>检测树鼩nf-κb基因转录水平的引物、试剂盒及方法
<160>6
<170>siposequencelisting1.0
<210>1
<211>20
<212>dna
<213>人工序列()
<400>1
cagaaattgggcctggggat20
<210>2
<211>20
<212>dna
<213>人工序列()
<400>2
ttcagtgtggcccatctgtc20
<210>3
<211>19
<212>dna
<213>人工序列()
<400>3
agccccatcaccatcttcc19
<210>4
<211>19
<212>dna
<213>人工序列()
<400>4
aatgagccccagccttctc19
<210>5
<211>133
<212>dna
<213>人工序列()
<400>5
cagaaattgggcctggggatacttaataatgccttccggcttagccctgccccttcaaaa60
acactgatggacaactacgaggtctccgggggaacagtcagagagctggtggaggccctg120
agacagatgggat133
<210>6
<211>143
<212>dna
<213>人工序列()
<400>6
ggcacagtcaaggctgagaatgggaagctggtcatcaacgggaaacccatcaccatcttc60
caggagcgagatcccgctaacatcaaatggggtgatgctggtgctgagtatgtcgtggag120
tctactggcgtcttcaccaccat143
- 还没有人留言评论。精彩留言会获得点赞!