一种核灵活流形嵌入电熔镁炉故障监测方法与流程
本发明涉及一种电熔镁炉故障监测与诊断技术,具体地说是一种核灵活流形嵌入电熔镁炉故障监测方法。
背景技术:
在我国,氧化镁的生产过程自动化程度差,生产过程复杂,生产过程中具有非线性、非高斯、强耦合等特性,容易发生故障,从而造成巨大的经济损失,急需一种有效的过程监测方法对生产状况进行预测,减少故障发生率,降低经济损失。近几年来,随着计算机和自动化的发展,生产过程中的数据能够得以保存,且生产的安全性也越来越受到重视。利用大量历史数据的一类基于数据驱动的过程监控方法得到了广泛的关注,并且成为了过程监控领域中的一个研究热点。
在生产过程中,经验丰富的工人能够保证生产安全进行且获得高质量的产品,然而,这样的生产效果,一般的工人却很难实现,由此如何利用老工人的经验知识来实现工业生产监控,成为了重要的研究方向。近年来,大量高维的数据已能够通过可靠的数据采集系统所获得,然而在利用数据实现故障检测时,数据多且维数大成为了影响过程监测效果的重要因素,因此在利用数据进行过程监控时,约简数据维数成为了一个很重要的问题,其直接影响着实际过程监控的效果。在过去几年里,很多过程监控算法被提出,而这些算法都没有充分利用老工人的经验知识来实现实际工业的过程监控。
技术实现要素:
针对现有技术中氧化镁的生产过程监控算法没有充分利用老工人的经验知识等不足,本发明要解决的问题是提供一种结合了老工人的经验知识、利用少量的标记数据和大量未标记数据来实现对于过程监测模型建立的核灵活流形嵌入电熔镁炉故障监测方法。
为解决上述技术问题,本发明采用的技术方案是:
本发明一种核灵活流形嵌入电熔镁炉故障监测方法,包括以下步骤:
采集各类故障数据和正常数据;
进行离线建模,根据采集到的数据获取KICA监控模型,训练KFME故障诊断模型;
在线监测,利用KICA监控模型进行实时在线监测,采集过程数据;
如果监测到故障,则通过KFME监控模型进行故障识别;
如果识别出故障,则一次故障监测过程结束。
如果没有识别出故障,则分析未诊断出的故障数据并进行标记,转至训练KFME故障诊断模型步骤。
根据采集到的数据获取KICA监控模型,训练KFME故障诊断模型包括以下步骤:
1)对收集到的故障状态下的故障数据和正常状态下的正常数据进行中心化和标准化处理,得到原始数据;
2)将上述原始数据映射到特征空间,将特征空间原始数据中的正常数据做为样本数据;
3)利用样本数据通过核独立元方法的基本原理建立KICA模型;
4)映射到特征空间的样本数据经过KICA模型处理后的数据作为KFME方法的建模数据;
5)基于知识分析的核灵活流形嵌入算法的基本原理进行建模,得到KFME模型。
根据核独立元方法的基本原理建立KICA模型步骤如下:
31)对映射到特征空间的样本数据中正常数据进行中心化和标准化处理,得到标准化后的核矩阵
32)在标准化后的核矩阵中计算特征值和特征向量,提取d个最大的特征值以及对应的特征向量,其提取的特征值的数目根据下述标准确定:
其中λi为特征值,i为特征值编号;
33)对于特征空间的正常数据,计算白化矩阵并将映射的数据进行白化,得到被白化的数据;
34)根据负熵公式J(y)=[E{G(y)}-E{G(v)}]2将被白化的数据进行处理,从而确定出过渡矩阵Cn,进一步确定非线性成分。
根据基于知识分析的核灵活流形嵌入算法的基本原理进行建模步骤如下:
51)根据特征向量y和训练数据Xw∈Rf×n,获得特征矩阵Y∈Rn×c;
52)根据特征矩阵Y∈Rn×c构造近邻图并计算图拉普拉斯矩阵L=D-S,其中,D为特征矩阵Y∈Rn×c的对角矩阵,S为特征矩阵Y∈Rn×c的对称矩阵,对角矩阵D的对角元素Dii为特征矩阵S中每列元素之和;
53)使用非线性映射函数Φ(·)将训练数据投影到高维特征空间;
54)根据高维特征空间中数据的特征,选择核函数;
55)计算上述核函数的值;
56)根据训练数据计算故障预测矩阵Fw,获得投影矩阵W和偏差项b;
57)根据在线数据,计算故障检测矩阵Ft,得到在线监控矩阵Ft。
对称矩阵S中元素Sii'采用如下方式计算:如果xi是xi'的m个近邻点,则Sii'=exp(-||xi-xi'||2/t),否则Sii'=0,其中,t为经验值,xi'为历史数据,i'=1,2,…,n。
所述特征空间为4维及4维以上的高维特征空间。
本发明具有以下有益效果及优点:
1.本发明方法能够很好地利用少量的标记数据和大量未标记数据来实现对于过程监测模型的建立,这使得此模型更加准确,监控效果得以提高。
2.本发明方法使用KICA处理后的数据来对KFME建模,不仅能够降低程序的运算成本而且能够提高KFME方法的故障诊断效果,能很好的实现数据降维及保留原始数据信息,提高故障诊断模型的准确率,实现有效的故障诊断,不仅高了算法的抗干扰能力,而且实现了对未知故障的监测。
附图说明
图1为本发明方法流程图;
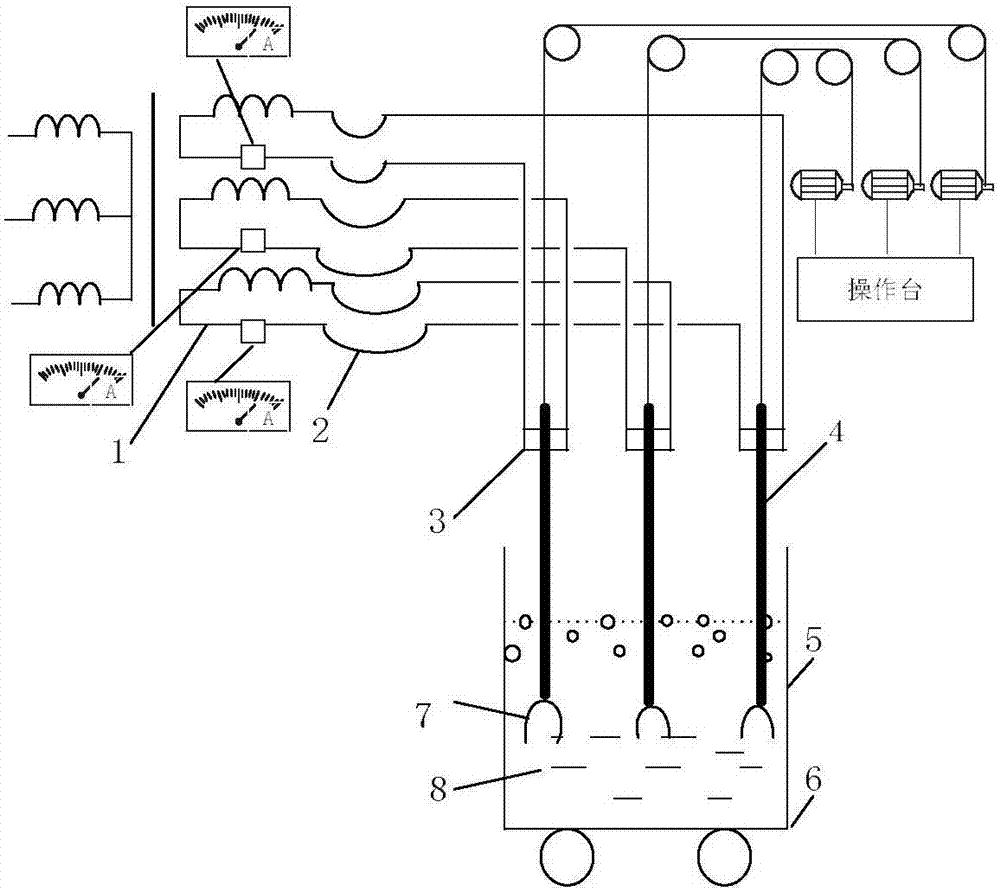
图2为本发明中涉及的电熔镁炉结构示意图;
图3A为0.5%标记数据进行预测模型的建模的诊断结果图示;
图3B为1%标记数据进行预测模型的建模的诊断结果图示;
图3C为1.5%标记数据进行预测模型的建模的实验结果图示;
图4A为0.5%数据进行预测模型的建模的诊断结果图示;
图4B为1%标记数据进行预测模型的建模的诊断结果图示;
图4C为1.5%标记数据进行预测模型的建模的实验结果图示;
图5为应用本发明方法对连续出现故障1和故障2的诊断结果图。
具体实施方式
下面结合说明书附图对本发明作进一步阐述。
如图1所示,本发明一种核灵活流形嵌入电熔镁炉故障监测方法,包括以下步骤:
采集各类故障数据和正常数据;
进行离线建模,根据采集到的数据获取KICA监控模型,训练KFME故障诊断模型;
在线监测,利用KICA监控模型进行实时在线监测,采集过程数据;
如果监测到故障,则通过KICA监控模型进行故障识别;
如果识别出故障,则一次故障监测过程结束。
如果没有识别出故障,则分析未诊断出的故障数据并进行标记,转至训练KFME故障诊断模型步骤。
其中,根据采集到的数据获取KICA监控模型,训练KFME故障诊断模型包括以下步骤:
1)对收集到的故障状态下的数据和正常状态下的数据进行中心化和标准化处理,得到原始数据;
2)将上述原始数据映射到特征空间,将特征空间原始数据中的正常状态下的数据做为样本数据;
3)利用样本数据通过核独立元方法的基本原理建立KICA模型;
4)映射到特征空间的样本数据经过KICA模型处理后的数据作为KFME方法的建模数据;
5)基于知识分析的核灵活流形嵌入算法的基本原理进行建模,得到KFME模型。
步骤2)中,样本数据被表示为xk∈Rm,k=1,…,n,通过使用非线性映射函数把数据映射到特征空间,计算核矩阵K∈Rn×n;
步骤3)利用样本数据通过核独立元方法的基本原理建立KICA模型包括以下步骤:
31)对映射到特征空间的样本数据中的正常状态下的数据进行中心化和标准化处理,得到标准化后的核矩阵
32)在标准化后的核矩阵中计算特征值和特征向量,提取d个最大的特征值以及对应的特征向量,其提取的特征值的数目根据下述标准确定:
其中λi为特征值,i为特征值编号;
33)对于特征空间的正常状态下的数据,计算白化矩阵并将映射的数据进行白化,得到被白化的数据;
34)根据负熵公式J(y)=[E{G(y)}-E{G(v)}]2将被白化的数据进行处理,从而确定出过渡矩阵Cn,进一步确定非线性成分。
步骤5)基于知识分析的核灵活流形嵌入算法的基本原理进行建模,得到KFME模型包括以下步骤:
51)根据正常数据的特征向量y和训练数据Xw∈Rf×n,获得特征矩阵Y∈Rn×c;
正常数据,用于建立KICA模型,当模型建立完毕后,需要对新来的数据(可以称之为在线数据或者实时数据)进行监测,确定是否符合模型,不符合的即为故障。先用正常数据建立KICA模型,得到模型后对实时数据进行监控,判断是否有故障的发生,这样也就确定了哪些数据是故障的。再输入到KFME模型中,这样KFME模型就能分类出数据是正常的,还是第一种故障或者第二种故障,是对故障的细化。同样,KFME也需要训练数据进行建模,涉及KFME的训练数据,包含故障和正常的数据。
52)根据特征矩阵Y∈Rn×c构造近邻图并计算图拉普拉斯矩阵L=D-S,其中,D为特征矩阵Y∈Rn×c的对角矩阵,S为特征矩阵Y∈Rn×c的对称矩阵,对角矩阵D的对角元素Dii为特征矩阵S中每列元素之和;
53)使用非线性映射函数Φ(·)将训练数据投影到特征空间;
54)根据特征空间中数据的特征,选择核函数;
55)计算上述核函数的值;
56)根据训练数据计算故障预测矩阵Fw,获得投影矩阵W和偏差项b;
57)根据在线数据,计算故障检测矩阵,得到在线监控矩阵Ft。
对称矩阵S中元素Sii'采用如下方式计算:如果xi是xi'的m个近邻点,则Sii'=exp(-||xi-xi'||2/t),否则Sii'=0,其中,t为经验值,xi'为历史数据,i'=1,2,…,n。
本发明中的特征空间是指4维及4维以上的高维特征空间。
本发明将KICA(Kernel Idependent Component Analysis,核独立元)方法和KFME(Kernel Flexible Manifold Embedding,核灵活流形嵌入)方法融合,使用核技巧将线性算法进行推广,使其能够处理非线性数据,在本发明中,这两种方法都使用相同形式的核函数。但是它们是不同领域的学习算法,KFME是基于图的半监督算法,能够诊断已知故障,对干扰很敏感,而KICA是无监督算法,能够实现故障监测,去除干扰信息。因此在本发明中,使用KICA方法去实现故障检测且去除干扰信息,使用KFME实现故障诊断,为了实现这个目的,在故障被检测到的时候,故障数据的独立成分被用作KFME方法的输入数据去实现故障诊断,KFME对独立成分进行处理找到其对应的故障类别,从而实现故障诊断。
本发明以如图2所示结构的电熔镁炉为例,在电熔镁炉运行过程中,分别采集电熔镁炉三个电极的电压值(UA、UB、UC)、三个电极的电流值(IA、IB、IC)、三个电极位置值(PA、PB、PC)以及炉温Temp,并对数据进行处理。
令X=[x1,x2,...,xn]∈Rm×n为数据集,考虑数据矩阵中的每一列数据xk∈Rm(k=1,…,n),n表示样本的数目,m表示变量数。非线性函数Φ:Rm→F将原始空间的观察数据投影到高维特征空间Φ(xk)∈F,数据xk的映射被表示为Φ(xk),因此在特征空间的协方差矩阵被表示为:
令Θ=[Φ(x1),...,Φ(xn)],特征空间的协方差矩阵CΦ能被写为CΦ=(1/n)ΘΘT。Θ为映射到高维特征空间之后的数据集。
定义一个n×n的Gram矩阵K为:
[K]ij=Kij=<Φ(xi),Φ(xj)>=k(xi,xj)
Gram矩阵表示为K=ΘTΘ,这个核函数k(xi,xj)=<Φ(xi),Φ(xj)>避免了非线性映射的执行以及在高维空间计算内积,最终使得特征空间的内积计算能够实现。使用径向基核函数(k(xi,xj)=exp(-||xi-xj||2/σ))并对特征空间数据Φ(xk)执行中心化以及标准化操作,中心化后的核矩阵表示为:
式中1n为所有元素的均为的方阵。
对核矩阵标准化处理能够得到:
对于上述矩阵进行特征值分解,下面计算式能够得到:
通过特征值分解,使标准化后的核矩阵的d个最大的特征值λ1≥λ2≥...≥λd以及对应的正交向量α1,α2,…,ad,根据Gram核矩阵和特征空间协方差矩阵之间的关系,协方差矩阵的特征值为λ1/n,λ2/n,…,λd/n,其相应的特征向量表示如下:
根据上述讨论的内容,CΦ的特征向量矩阵V=[v1,v2,...,vd]表示为:
V=ΘHΛ-1/2 H为特征向量矩阵,Λ为特征值构成的对角矩阵
式中,H=[α1,α2,...,αd]且Λ=diag(λ1,λ2,...,λd),然后这个白化矩阵P表示为:
PTCΦP=I
由此,通过下面的表达式对高维特征空间中的数据进行白化去干扰处理:
z=PTΦ(x) z为白化后的数据
白化细节如下所示:
式中是Kx进行均值中心化得到的,Kx=ΘTΦ(x)。
根据z∈Rd,需要去寻找满足独立元于是独立元可以写为:
式中变换阵C∈Rd×p并且CTC=D。
为了得到满足要求的独立成分,令标准化的独立成分yn为:
从上式可以知道,且根据白化步骤,得到无关的白化数据z,从而能够对矩阵初始化。
式中Ip是p维单位矩阵并且0是p×(d-p)维零矩阵。
KICA方法的关键步骤就是计算矩阵Cn,为了计算Cn,每一个列向量被初始化,并且不断地对该值进行更新,最终使得第i个独立成分yn,i=(cn,i)Tz能获得最大的高斯性,cn,i表示Cn的第i列,为了实现独立元yn,i(i=1,…,p)的统计独立,则令其非高斯性最大化。负熵作为非高斯性的评价标准,负熵越大,非高斯性越强。以下式子为负熵值的计算式。
J(y)=[E{G(y)}-E{G(v)}]2
式中假设y的均值为0,方差为1。v为高斯变量,其均值为0,方差为1,并且G为任何非二次函数;E是求熵所用的函数符号。
矩阵Cn的计算步骤:
(1)选择独立成分p的数目,为了去计算矩阵Cn,设置计数器i←1。
(2)初始化向量cn,i为等式(4.13)中矩阵的第i行。
(3)最大化负熵估计,令式中g是G的一阶导数,g′为G的二阶导数。
(4)为了排除已经发现的信息,执行正交化:
(5)标准化
(6)如果cn,i不收敛,则返回到步骤3。
(7)如果cn,i收敛,则输出向量cn,i。如果i≤p则令i←i+1并且返回到步骤2。
原始数据的核独立成分能够被得到。
为了通过对生产过程的监测,实现安全生产,控制限需要被定义,因此在KICA故障监控方法中,Hotelling’s T2统计量以及SPE统计量被定义,并且Hotelling’s T2统计量的控制限以及SPE统计量的控制限也被分别定义。当统计量超过其对应的控制限的时候则说明故障发生。在KICA方法中,Hotelling’s T2被定义:
本发明使用单变量核密度估计计算T2统计量的控制限,核密度估计函数如下:
式中l为应该计算的控制限,正常的采样数据被表示为li,i=1,…,n,采样样本的数目为n,对于控制限的计算,h是很重要的,其被称为平滑系数,K(·)表示核函数,占概率密度函数的99%的上边界作为T2统计量的控制限。
为了监测KICA模型中残差空间非统计部分的变化,则SPE统计量被定义:
式中并且是z的估计,其能够通过下面的式子计算得到:
SPE控制限根据χ2分布进行计算。
μ=b/2a,h=2a2/b
式中a和b分别是从正常数据中估计得到的均值和方差。
在实际的监测过程中,实时工业数据被采集,此时运用建立好的KICA模型对实时数据进行故障监测,详细步骤归纳如下:
(1)获取实时数据,对其进行中心化和标准化操作,该实时数据被记为xi∈Rm
(2)计算核向量kt∈R1×n,其计算式为[kt]j=[kt(xj,xt)],式中xj为正常操作数据xj∈Rm,j=1,…,n,xt为步骤一处理后的数据。
(3)对核向量kt做均值中心化处理:
(4)标准化处理:
(5)通过下述的式子,对实时数据进行白化处理,其非线性成分能被提取。
(6)获得该数据的独立成分,其计算式为
(7)计算实时数据的T2和SPE监控统计量。
(8)监控T2、SPE是否超过其对应的统计量。
KICA方法被使用去实现故障检测,当KICA方法检测出实时工业生产中有故障发生时,该故障数据作为输入,输入到已经建立好的KFME模型中,通过KFME方法来实现故障诊断。其步骤如下:
(1)新的生产实时数据被采集作为输入,输入到已经建立好的KICA模型中;
(2)当统计量超出其对应的控制限时,则表明有故障发生;
(3)KICA处理的故障数据作为KFME模型的输入;
(4)通过KFME方法,故障被实现准确的分类;
但是由于已知的故障是有限的,在实际生产中,随着时间的推移,由于设备的老化,以及设备的变更,也会发生一些以前未知的故障,而当这些故障被KICA监测发现后作为KFME的输入,其并不能通过KFME模型进行故障诊断,因为KFME方法是半监督方法,该方法依赖于标记数据,也就是说其只能分类已知故障,此时需要对新的故障数据进行故障特征及故障原因进行分析,最后再将其加入到KFME模型的训练数据中,更新KFME模型,最终实现对该故障的故障诊断。
电熔镁炉运行过程中历史数据集X=[x1,x2,...,xi,xi+1,...,xn]∈Rf×n,其中,xi为历史数据,n为数据采样的个数,f为变量个数,i=1,2,…,n;对部分历史数据进行标记,标记数据为k∈[1,n),标记数据的类标签为yi∈{1,2,...,j,...,C},yi的值是标记数据xi所属的类,j=1,2,…,C,C表示标记数据所属类的数目,并利用先验知识赋予yi实际意义;
本发明中,正常数据、故障1数据、故障2数据的类标签分别取1、2、3,即yi∈{1,2,3}。
构造特征矩阵Y∈Rn×c,式中
构造对称矩阵S∈Rn×n,矩阵S中元素Sii'采用如下方式计算:如果xi是xi'的m个近邻点,则Sii'=exp(-||xi-xi'||2/t),否则Sij=0,其中,t为经验值,i'=1,2,…,n;
计算图拉普拉斯矩阵L=D-S,L∈Rn×n,D为对角矩阵,其对角元素为
将历史数据集X通过核函数Φ从原始数据空间映射到高维特征空间,即X→Φ(X);在核方法中,存在特征映射其中的Ff是一个特征空间,输入数据通过特征映射函数被映射到这个特征空间,本发明中,通过非线性映射函数Φ(·)将所有数据包括标记和未标记数据从低维空间映射到高维空间,这个处理能使得非线性问题转化为线性问题或者近似线性问题。
根据流形嵌入算法的原理,建立可以获得故障预测矩阵的优化模型:
故障预测矩阵可定义为F=Φ(Xw)TW+ebT,从这个式子中,可知故障预测矩阵受到数据的严格约束,这样的约束往往使得获得最终模型泛化能力不强,因此,为了使得其使用更加灵活,将故障预测矩阵重写为F=h(Φ(Xw))+F0=Φ(Xw)TW+ebT+F0,式中投影矩阵为W∈Rf×c,偏差项为b∈Rc×1并且e=[1,1,...,1]T,在这种方法中,目标是同时发现最优的故障预测矩阵F,回归残差矩阵F0以及线性回归函数h(Φ(X))。
初始优化函数为Tr(F-Y)TU(F-Y)+Tr(FTMF),为了防止出现过拟合,以及使得拟合误差最小,在上述的优化目标函数中加入了正则项α(||W||2+ξ||F0||2),获得更加准确的预测标记矩阵。由分析,可得到以下的目标函数:
其中,两个系数α和ξ是用来平衡两个不同正则项的,α≥0,ξ≥0并且M=L=D-S,M∈Rn×n是拉普拉斯矩阵,对角矩阵U的具体形式如下:
令F-Φ(Xw)TW-ebT去代替残差F0,能够得到新的优化目标函数如下:
根据历史离线数据X,特征矩阵Y和拉普拉斯矩阵L计算故障预测矩阵Fw:
求解投影矩阵W和偏差项b:
根据最终的优化函数,为了得到最优的解,从而对该式子分别对b和W求偏导,并且令其偏导为0:
得到投影矩阵W和偏差项b:
W=ξ(ξΦ(X)HcΦ(X)T+I)-1Φ(X)HcFw=PFw
式中,P=ξ(ξΦ(Xw)HcΦ(Xw)T+I)-1Φ(Xw)Hc。
新的关于故障预测矩阵的目标函数如下所示:
通过对上式进行处理,得到:
g(F)=Tr(F-Y)TU(F-Y)+Tr(FTMF)+α(Tr(FTPTPF)+ξTr(QF-F)T(QF-F))
对函数g(F)的变量F求导并令其为0可得:
求解上式,故障预测矩阵的解析式能够被表示:
F=(U+M+αξ(Q-I)T(Q-I)+αPTP)-1UY
令Φ(Xc)=Φ(X)Hc,可得:
αξPTΦ(X)HcΦ(X)TP+αPTP=αξPTΦ(X)Hc=αξHcΦ(X)TP
Q=HcΦ(X)TP+(1/n)eeT
P=ξ(ξΦ(X)HcΦ(X)Φ(X)T+I)-1Φ(X)Hc
化简后,可得:
Q=HcΦ(X)Tξ(ξΦ(X)HcΦ(X)T+I)-1Φ(X)Hc+(1/n)eeT
=HcΦ(X)Tξ(ξΦ(Xw)HcΦ(Xw)T+I)-1Φ(Xc)+(1/n)eeT
=ξHcΦ(X)TΦ(Xc)(ξΦ(X)HcΦ(X)T+I)-1+(1/n)eeT
得到故障预测矩阵Fw的表达式如下:
式中,K(X,X)=Φ(X)TΦ(X),Hc=I-(1/n)eeT。
电熔镁炉生产过程中,获取电熔镁炉在线过程变量监测数据Xt进行标准化,并计算故障监测矩阵Ft。
Ft=Φ(Xt)TW+ebT=[ξHcK(Xt,Xw)Hc(ξK(Xw,Xw)Hc+I)-1+I-Hc]Fw
根据Ft能够直接的了解测试数据的特征,即能知道该数据是故障数据还是正常数据,因为Ft的每一行对应着每一个数据点,每行中理论上只有一个为1的数据,而实际情况是每一行有一个最大的数值,其接近1,该数所对应的列即为该数据所属的类,即该列对应着C类中的一类,即可根据下式进行故障监测和诊断:
对第一组670个采样数据进行仿真,这些数据中含有正常数据和故障1的数据,其前300个数据为正常数据,在300个点后开始引入故障1,为了确定标记数据数目对于故障诊断效果的影响,进行了三次实验,在第一次实验(实验一)中,选择了三类数据中各一个标记数据进行预测模型的建模;在第二次实验(实验二)中,选择了三类数据中各两个标记数据进行预测模型的建模;在第三次实验(实验三)中,选择了三类数据中各三个标记数据进行预测模型的建模。这三个实验的实验结果分别如图3A~3C所示,在图中正常状态用折线表示,故障1用点表示,故障2用“+”表示。
从图3A中可以看出,在300个点以前,正常状态值处于0.6附近,故障1状态值处于0.4附近,故障2的状态值处于0附近,该图中正常状态值是最大的,即数据表现出其特征,所以可以认为前300个数据点为正常状态的数据点,但是由于正常状态和故障2状态的状态值很接近,所以在参数调节不好的情况下,很容易发生同一个数据既表现出故障2状态又表现出正常状态的情况,即出现二义性,这样就无法了解数据的真正特征,从而无法实现故障检测,而且理论上认为每个数据点唯一的只表现出一种状态,并且表现出的状态对应的状态值应该接近1。此处正常状态的状态值虽然是最大的,但是其值仅为0.6,并没有接近1,所以实验一表示其故障检测效果并不好。
从图3B中可以看出,在前300个数据点内,正常状态的状态值处于0.8附近,故障1的状态值处于0附近,故障2的状态值处于0附近,由于前300个点的正常状态的状态值处于0.8附近,很接近1,而且在前300个数据点中,故障1和故障2的状态值接近0,这就能充分的说明前300个数据点表现出正常状态,即此时电熔镁炉生产安全进行。在后370个点中,能发现故障1的状态值处于0.9附近,接近1,同时正常状态和故障2的状态值处于0附近,这就说明在后370个点发生故障1,而且在本实验中,状态值趋于1的状态和另外两个状态的状态值相距很远,避免了二义性的出现,这就说明在利用此少量标记数据时能够很好地实现故障监测。
从图3C中可以知道,在前300个数据点内,其数据表现出正常状态,即电熔镁生产工作在正常状态,在后370个数据点中,故障1发生,而且在图中,还能知道在300个点以前,故障1的状态值开始慢慢的变大,这就预示着故障1可能即将发生。观察图3B和3C,能够发现,实验二和实验二的实验效果基本一致,但是实验三使用了更多的标记数据,而在实际的生产中,标记数据是很难获得的,因此实验三浪费了标记数据,并且说明利用实验二中的标记数据就能达到有效的故障诊断效果。
测试数据主要是包括正常数据和故障1的数据,其只测试了标记数据的数据量对于故障1监测效果的影响,并没有测试标记数据的数据量对于故障2的故障诊断效果的影响。因此在图4A~4C中使用了670个测试数据来研究标记数据的数据量对于故障诊断的影响,这670个标记数据中,前330个数据点为正常数据,后340个数据点为故障2数据。对于此测试数据,也做了三个实验,在第一次实验(实验一)中,选择了三类数据中各一个标记数据进行预测模型的建模;在第二次实验(实验二)中,选择了三类数据中各两个标记数据进行预测模型的建模;在第三次实验(实验三)中,选择了三类数据中各三个标记数据进行预测模型的建模,其实验结果分别为图4A~4C。
从图4A中可以看出,在330个点以前,正常状态值处于0.6附近,故障2的状态值处于0.4附近,故障1的状态值处于0附近,图中正常的状态值是最大的,即数据表现出其特征,所以前330个数据点为正常状态的数据点,但是由于正常状态和故障2状态的状态值很接近,所以在参数调节不好的情况下,很容易发生同一个数据点出现二义性,这样就无法了解数据的真正特征,这就无法实现故障检测,而且理论上认为每个数据点唯一的只表现出一种状态,并且表现出的状态对应的状态值应该接近1。此处正常状态的状态值虽然是最大的,但是其值仅为0.6,并没有接近1,所以实验一故障检测效果并不好。
从图4B中可以看出,在前330个数据点内,正常状态的状态值处于0.8附近,故障1的状态值处于0附近,故障2的状态值处于0附近,由于前330个点的正常状态的状态值处于0.8附近,很接近1,而且在前300个数据点中,故障1和故障2的状态值接近0,这就能充分的说明前330个数据点表现出正常状态,即此时电熔镁炉工作在安全情况下。在后340个点中,能发现故障2的状态值处于0.8附近,接近1,同时正常状态和故障1的状态值处于0附近,这就说明在后340个点发生故障2,而且在本实验中,状态值趋于1的状态和另外两个状态的状态值相距很远,使得在监测时不可能出现同一数据点既表现出正常状态,又表现出故障状态,这就说明在利用此标记数据时能够很好地实现故障监测。
从图4C中可以知道,在前330个数据点内,其数据表现出正常状态,在后340个数据点中,故障2发生,在330个点以前,故障1的状态值开始慢慢的变大,这就预示着故障2可能即将发生。观察图4B和4C,能够发现,实验二和实验三的实验效果基本一致,但是实验三使用了更多的标记数据,而在实际的生产中,标记数据是很难获得的,因此实验三浪费了标记数据,并且说明利用实验2中的标记数据就能实现有效的故障诊断。
对比图3A~3C和图4A~4C,此模型诊断故障2的效果并没有诊断故障1的效果好,对于图4A~4C,在330点后,其上下波动很严重,而且在第360个数据点附近出现了既有故障2发生,同时又有正常状态的特征,这说明了此模型在诊断故障2时,效果并不是很好,这是由于,故障2的建模数据不足,以及故障2的特征和正常数据区分不明显,从而使得该算法无法很好的诊断故障2。
为了验证算法是否能够连续诊断两个故障,所以做了一个新的实验仿真,该仿真的参数依然和上面的仿真参数选择一样,即α=10-8,ξ=105,并且选了1370个数据点作为测试数据,此实验的仿真图如图5所示,观察该图,能发现在300个点后故障1发生,在1000个点后故障2发生。
本发明提出了基于核独立元知识分析的核灵活流形嵌入的方法,由于其结合了老工人的经验知识,相比于其他算法具有一定的优越性。本方法通过利用老工人知识来对数据进行标记,使经验知识能够通过机器语言得以表示,从而使得机器能够学习到此知识。由于在实际过程中,对数据的标记需要耗费大量的人力物力,故带有知识的数据的数量是很少的,而本发明方法能够很好地利用少量的标记数据和大量未标记数据来实现对于过程监测模型的建立,这使得此模型更加准确,监控效果得以提高。由于KFME对噪声较为敏感且生产数据具有非高斯特性,故提出了基于KICA知识分析的KFME故障监测方法,该方法使用KICA处理后的数据来对KFME建模,不仅能够降低程序的运算成本而且能够提高KFME方法的故障诊断效果,这是由于通过KICA处理后的数据能很好的实现数据降维及保留原始数据信息,提高故障诊断模型的准确率,实现有效的故障诊断。因此本发明提出的方法,不仅提高了算法的抗干扰能力,而且实现了对未知故障的监测。
核方法是最近发展起来的一种在机器学习领域应用广泛的非线性回归方法,它通过一个非线性的变换Φ(x)将n维输入空间中的样本向量x映射到高维特征空间F,将原空间的非线性问题转化为高维空间中线性或者近似线性的问题,然后在高维特征空间中运用线性的方法来处理。核方法在许多算法中都有应用,如核主元成分分析,核偏最小二乘方法,核Fisher判别方法等。
核独立元分析方法是独立元方法的推广,独立元方法能够很好的提取非高斯数据中的独立成分并且去除干扰信号的影响,但是其也有限制,由于其假设数据都是线性的,所以不能够对非线性数据进行独立元提取,故产生了核独立元分析方法,其通过将非线性数据投影到高维空间进行线性化近似处理,并使用核技巧避免了高维空间的复杂计算,最终实现了对非线性数据的独立元提取。
- 还没有人留言评论。精彩留言会获得点赞!