用于表征脂蛋白的方法与流程
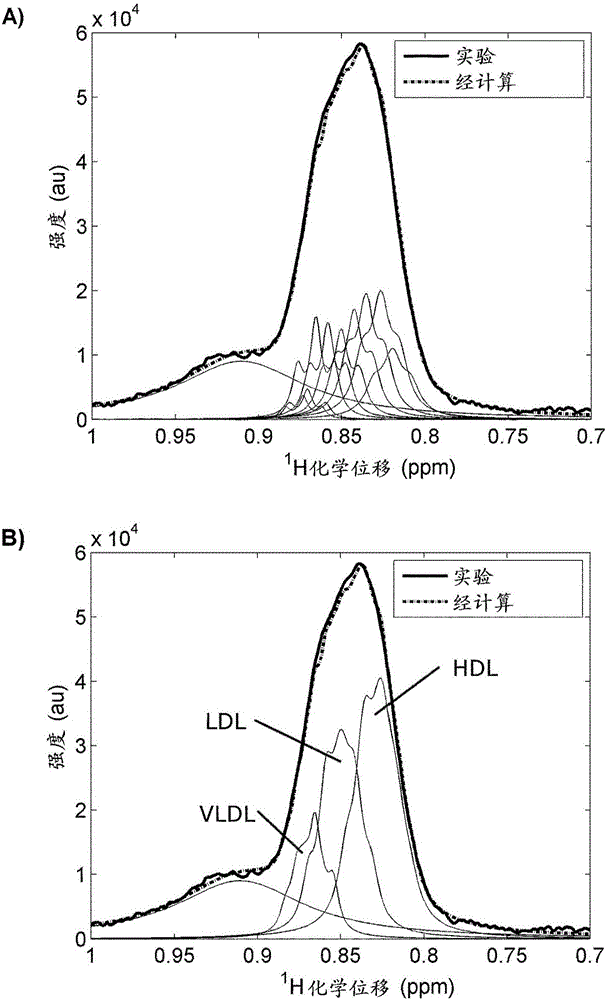
本发明涉及用于表征脂蛋白的方法,并且适用于生物医学领域。现有技术脂质在血液中主要以脂蛋白的形式存在,脂蛋白是在肝和肠中合成的运输胆固醇、甘油三酯及其他脂质通过血流进入外周组织的颗粒。血脂的异常水平可指示心血管疾病。为了评估心血管风险,一般使用标准脂质组,其包括血浆甘油三酯、总胆固醇、LDL胆固醇和HDL胆固醇的浓度。所有这些参数均可实验测量,LDL胆固醇例外,其使用Friedewald公式进行估算。该公式的一个关键限制是其在某些条件下不精确。而且,由于脂蛋白颗粒的尺寸和颗粒数也可与脂质相关性疾病的正确诊断有关,因此测量HDL和LDL脂蛋白级分中胆固醇的量不能满足在每种情况下预测心血管风险。因此,脂蛋白颗粒在心血管疾病和代谢紊乱中起主要作用。脂蛋白根据其尺寸和密度分为五个主要级分:乳糜微粒(Q;半径)、极低密度脂蛋白(verylowdensitylipoprotein,VLDL;半径)、中密度脂蛋白(intermediatedensitylipoprotein,IDL;半径)、低密度脂蛋白(lowdensitylipoprotein,LDL;半径)和高密度脂蛋白(highdensitylipoprotein,HDL;半径)。这些主要级分可进一步分为不同的亚类(subclass)以获得更为详细的脂蛋白谱。公认的是,脂蛋白颗粒的结构基本上为球形并且包括内核心和外壳,其中非极性脂质(三酰甘油和胆固醇酯)见于核心中,而极性脂质(磷脂和游离胆固醇)分布于整个表面单层(壳)。脂蛋白的蛋白质组分(称为载脂蛋白或脱辅基蛋白)与极性脂质一起位于壳上。高级脂蛋白测试(advancedlipoproteintesting,ALT)旨在提供有关脂蛋白颗粒的最详细信息。在目前使用的高级脂蛋白测试的分析技术中,可提及以下:■密度梯度超速离心(DensityGradientUltracentrifugation),其允许测量不同脂蛋白亚类的相对胆固醇分布(K.R.Kulkarni等,QuantificationofcholesterolinalllipoproteinclassesbytheVAP-IImethod,JournalofLipidResearch35(1994)159-168)。然而,其不提供甘油三酯的浓度,或者脂蛋白颗粒的数目和尺寸。■梯度凝胶电泳(GradientGelElectrophoresis),其可根据LDL和HDL亚类的尺寸直接从血浆对LDL和HDL亚类进行分级(G.R.Warnick等,Polyacrylamidegradientgelelectrophoresisoflipoproteinsubclasses,ClinicsinLaboratoryMedicine26(2006)803)。该方法需要定制的凝胶并且需要严格注意实验室质量控制,因为凝胶质量和实验室条件的小变化可影响准确度。■高效液相色谱法(HighPerformanceLiquidChromatography)测量主要脂蛋白及其亚类的尺寸以及胆固醇和甘油三酯含量(M.Okazaki等,ComponentanalysisofHPLCprofilesofuniquelipoproteinsubclasscholesterolsfordetectionofcoronaryarterydisease,ClinicalChemistry52(2006)2049-2053)。■离子迁移率分析(IonMobilityAnalysis)依赖于气相化脂蛋白颗粒的电泳迁移率的差异并且允许测量一些脂蛋白亚类的尺寸和浓度(M.P.Caulfield等,Directdeterminationoflipoproteinparticlesizesandconcentrationsbyionmobilityanalysis,ClinicalChemistry54(2008)1307-1316)。■1H-NMR光谱学,其基于复杂的线形拟合技术来量化脂蛋白亚类(M.Ala-Korpela等,1HNMR-basedabsolutequantificationofhumanlipoproteinsandtheirlipidcontentsdirectlyfromplasma,JournalofLipidResearch(1994)2292-2304)。然而,所述技术需要使用之前表征的谱文库,并且具有在分析血浆谱中发生广泛脂蛋白信号重叠的缺点。■脂蛋白级分的扩散-排序NMR光谱学(Diffusion-OrderedNMRSpectroscopy),其使用分离的脂蛋白的甲基峰来计算脂蛋白的扩散系数并且由该数值估算其尺寸(R.Mallol等,ParticlesizemeasurementoflipoproteinfractionsusingdiffusionorderedNMRspectroscopy,AnalyticalandBioanalyticalChemistry402(2012)2407-2415)。然而,该方法需要对样品进行超速离心以获得不同脂蛋白级分的前步骤,并且不能在血清或血浆样品中直接使用。物理分离不同脂蛋白级分和亚类的分析方法(例如超速离心)费力且耗时。此外,样品经受高度操作,并且其可能在4℃下持续数天。此外,ALT方法尚未准备好用于常规临床用途,其一些限制为缺乏标准化和可变操作。因此,需要这样的方法,其允许使用单一分析并且无需处理或破坏样品来由血清或血浆样品直接可靠地表征不同的脂蛋白级分和亚类。这将可用于开发和监测饮食和药物治疗,并且了解心血管疾病的病理生理学。技术实现要素:本发明通过提供根据权利要求1所述的方法克服了上述问题。从属权利要求对本发明的一些优选实施方案进行了限定。目前,LDL和HDL胆固醇是常规用于评估个体的心血管风险的两个心血管风险因素。然而,高百分比遭受心血管事件的个体具有正常的LDL胆固醇水平。患有代谢紊乱(例如糖尿病)的患者往往具有更小、胆固醇含量更差并且更加致动脉粥样化的LDL脂蛋白。这一较小尺寸与较多的颗粒数有关,由此导致胆固醇浓度类似于以下模式的胆固醇浓度:较低浓度的较大较不致动脉粥样化颗粒。这是为什么关注确定LDL脂蛋白颗粒的尺寸和数目而非其脂质载量来评估患者的心血管风险的原因。此外,有研究指出,与HDL胆固醇相比,HDL颗粒的尺寸和数目是更好的心血管风险预示。本发明允许彻底地表征脂蛋白颗粒,在样品中以快速且可靠的方式提供主要脂蛋白级分和亚类的颗粒尺寸和数目而无需对不同的脂蛋白级分和亚类进行物理分离。根据本发明的方法包括以下步骤:-获得样品的2D扩散-排序1HNMR谱;-使用多个模型函数来进行对应于甲基信号的谱部分的曲面拟合(surfacefitting),每个模型函数对应于与脂蛋白级分和亚类相关联的给定颗粒尺寸并且包括至少一个在所述拟合期间待估算的模型参数,估算的模型参数为模型参数组,为此使NMR信号和作为所述模型函数之线性组合而建立的模型信号之间的差异最小化,其中每个模型函数为具有以下形式的洛伦兹函数(lorentzianfunction)的三元组(triplet):三元组j=洛伦兹(h1j,fj-f0j,wj,Dj)+洛伦兹(h2j,fj,wj,Dj)+洛伦兹(h3j,fj+f0j,wj,Dj)其中hij(au)、fj(ppm)、wj(ppm)和Dj(cm2s-1)分别为与脂蛋白颗粒尺寸j相关联的强度、化学位移、宽度和扩散系数。侧(side)洛伦兹函数相对于中心(central)洛伦兹函数在化学位移轴中等间距,即为量f0。针对脂蛋白颗粒尺寸待确定的模型参数为来自f、f0、h1、h2、h3、w和D中的一个或数个。有利地,与其他方法相比,使用洛伦兹的三元组作为与每个脂蛋白颗粒尺寸相关联的模型函数使得更精确地拟合NMR信号。所述样品优选地为血浆样品或血清样品,但是也可使用其他生物流体的样品,例如脑脊液、脑脊髓流体或羊水。因此,将NMR甲基信号分解为多个模型函数,每个模型函数与脂蛋白颗粒尺寸相对应。因此,每个模型函数根据其脂蛋白颗粒尺寸而与给定的脂蛋白级分和亚类相关联。并非拟合中包括的所有模型函数都一定对建立的模型信号具有贡献,因为并非拟合中包括的所有脂蛋白颗粒尺寸都一定存在于样品中。根据本发明的方法,鉴定样品中存在的脂蛋白并通过确定关联脂蛋白信号的强度、化学位移、宽度和扩散系数来对其进行表征。对于样品中存在的脂蛋白的进一步表征,可基于模型函数并且基于估算的模型参数在后续步骤中确定另外的脂蛋白参数。优选地,与每个脂蛋白颗粒尺寸j相关联的三元组中的洛伦兹函数具有以下形式:其中k为玻耳兹曼常数并且G为施加的梯度强度(高斯cm-1)。洛伦兹的第一商数部分(qoutientpart)对应于1D洛伦兹,而指数部分包括通过扩散梯度的衰减效应。洛伦兹函数的这一优选形式适用于本发明的每个实施方案。在一个优选实施方案中,所述方法包括鉴定样品中存在的脂蛋白为与对由拟合产生的理论模型信号具有非零贡献的模型函数相关联的那些,并且所述方法包括确定以下中的至少一项且优选全部:脂蛋白颗粒类的平均尺寸、脂蛋白颗粒亚类的平均尺寸、类和/或亚类脂蛋白颗粒浓度、至少一个脂蛋白颗粒类的脂质浓度和/或至少一个脂蛋白颗粒亚类的脂质浓度。在一个优选实施方案中,对于与每个脂蛋白颗粒尺寸j相关联的模型函数,使侧洛伦兹函数的强度与中心洛伦兹函数的强度成比例:h1j=αj·h2j,其中并且h3j=βj·h2j,其中在一个实施方案中,使比例因子αj对所有的脂蛋白颗粒尺寸而言都相同,和/或使比例因子βj对所有的脂蛋白颗粒尺寸而言都相同。在一个优选实施方案中,使侧洛伦兹函数的强度取成相等,即h1j=h3j。在一个优选实施方案中,即,侧洛伦兹函数的强度大致为中心洛伦兹函数之强度的一半,和/或f0=0.01ppm,即,侧洛伦兹函数相对于中心洛伦兹函数在化学位移轴中间隔约0.01ppm。在一个优选实施方案中,所使用之模型函数的数目大于或等于9,每个模型函数均与脂蛋白颗粒尺寸相对应。在一个优选实施方案中,基于例如通过NMR、HPLC、梯度凝胶电泳或原子力显微镜获得的实验结果定义在拟合中使用的脂蛋白颗粒尺寸。用于所述方法的脂蛋白颗粒尺寸可基于任何其他技术选择。优选地,在所述方法中使用对应于数个脂蛋白级分和/或亚类的脂蛋白颗粒尺寸。在所述拟合期间,曲面拟合可以以所有模型参数作为待确定的自由函数来进行。然而,在一个优选实施方案中,如下进行曲面拟合:固定多个模型参数,并且使用至少一个其他模型参数作为待确定的自由参数。更优选地,至少使用中心洛伦兹的信号强度(h2)作为自由参数,并固定化学位移、宽度和扩散系数中的至少一个。当在曲面拟合中待估算的模型参数的数目高时,出现多个拟合解决方案,其中很多不具有生物学意义。有利地,通过在模型参数对之间建立关系来固定参数使得能够减少该问题的维数,并且避免出现无生物学相关性的解决方案。侧洛伦兹函数相对于中心洛伦兹函数的位移可在曲面拟合期间估算或者可取为给定值。类似地,侧洛伦兹函数的强度可在曲面拟合期间估算或者可取成与中心函数的强度相关,优选地取为中心洛伦兹函数之强度的一半。在一个优选实施方案中,基于脂蛋白颗粒尺寸并且基于回归模型确定用于曲面拟合的固定模型参数,所述回归模型使固定模型参数对联系起来和/或使模型参数和脂蛋白颗粒尺寸联系起来。在一个优选实施方案中,用于固定参数的回归模型由使用具有以强度、化学位移、宽度和扩散系数为自由模型参数的多个模型洛伦兹函数对多个NMR谱的甲基信号进行去卷积(deconvolution)获得,所述自由模型参数经估算以使NMR甲基信号和作为模型函数之线性组合而建立的模型信号之间的差异最小化,所述回归模型分别至少使(i)化学位移和脂蛋白颗粒尺寸联系起来,和/或使(ii)宽度和脂蛋白颗粒尺寸联系起来。在一个优选实施方案中,使模型参数对联系起来的回归模型根据以下步骤建立:-获得多份样品的2D扩散-排序1HNMR谱;-对于每份样品,使用多个模型函数进行对应于甲基信号的谱部分的曲面拟合,每个模型函数取决于待固定的模型参数,其中所述待固定的所有模型参数在所述曲面拟合期间作为模型函数组估算,为此使NMR信号和作为所述模型函数之线性组合而建立的模型信号之间的差异最小化,以及-使用在前述步骤中估算的所述模型参数来建立使模型参数对联系起来的回归模型。优选地,所述回归模型分别至少使(i)化学位移和脂蛋白颗粒尺寸联系起来,和/或使(ii)宽度和脂蛋白颗粒尺寸联系起来。用于建立回归模型的多份样品包含不同的脂质谱,并且所考虑样品数足够高以具有统计学意义。优选地,样品数等于或大于100,并且包括从健康对象取得的样品和对应于不同致动脉粥样化性血脂异常(atherogenicdyslipidaemia)谱的样品。更优选地,样品数等于或大于100并且包括从健康对象取得的样品,至少9%百分比的样品对应于具有糖尿病谱的个体并且这些患者中的至少25%具有动脉粥样化性血脂异常谱。优选地,用于建立回归模型的模型函数为以下形式的洛伦兹函数三元组:三元组j=洛伦兹(h1j,fj-f0j,wj,Dj)+洛伦兹(h2j,fj,wj,Dj)+洛伦兹(h3j,fj+f0j,wj,Dj),在一个优选实施方案中,h1=h3=h2/2。在一个优选实施方案中,用于建立回归模型的洛伦兹函数的三元组具有以下形式:或者,侧洛伦兹函数相对于中心洛伦兹函数的位移(f0)可在为建立回归模型而进行的拟合期间确定。位移(f0)的单一值可用于所有的脂蛋白尺寸。类似地,侧洛伦兹函数的强度可在为建立回归模型而进行的拟合期间估算。在一个优选实施方案中,通过爱因斯坦-斯托克斯方程(EinsteinStokesequation)由脂蛋白颗粒尺寸估算模型函数的扩散系数:k(JK-1)为玻耳兹曼常数,T(K)为温度,η(Pas)为粘度并且RH为脂蛋白颗粒尺寸。在一个优选实施方案中,本发明的方法还包括利用NMR面积和对数个样品稀释度获得的扩散系数之间的关系校正估算的扩散系数以将稀释效应考虑在内,其中所述样品之总胆固醇和甘油三酯的浓度之和高于300mg/dL。有利地,使用将稀释效应考虑在内的经校正扩散系数导致更精确的曲面拟合。在一个优选实施方案中,校正与脂蛋白函数相关联的NMR面积以只考虑脂蛋白颗粒核心中包含的脂质的贡献。在一个优选实施方案中,使用以下表达式确定所述校正NMR面积(A’):其中A(au)和分别为与每个模型函数相关联的所述面积和脂蛋白颗粒尺寸,为脂蛋白颗粒的壳厚度并且p为所述颗粒壳中每单位体积的脱辅基蛋白质量(mg/ml)相对于所述颗粒壳中每单位体积的总质量(mg/ml)(蛋白质、游离胆固醇和磷脂)的比。将在脂蛋白颗粒壳中的蛋白质称为载脂蛋白。比p取决于脂蛋白级分。对于HDL,p为约0.5。对于其他脂蛋白级分,p更小。一般来说,脂蛋白颗粒核心的厚度估算为本文中使用的术语“载脂蛋白”或“脱辅基蛋白”(即,在脂蛋白颗粒的壳中的蛋白质)指与脂质结合以形成脂蛋白并且将脂质运输通过循环系统的蛋白质。载脂蛋白是可包围脂质产生脂蛋白颗粒的两亲性分子,所述脂蛋白颗粒自身是水溶性的并且因此可被运载通过基于水的循环(即,血液)。有六类载脂蛋白(A-H)和数个亚类;特别地,ApoA-I(或ApoA1)是HDL颗粒的主要蛋白质组分,其中还存在微浓度的ApoA-II(或ApoA2)。用于确定载脂蛋白浓度的说明性的非限制性方法包括但不限于比色法、Western印迹或ELISA。如果在脂蛋白的分离级分中确定载脂蛋白浓度,则可使用本领域中用于确定蛋白质浓度的任何公知方法,例如酶促发、比色法(Biuret、Lowry、Bradford等)或免疫化学技术(Western印迹、ELISA等)。如果在血浆或血清样品中确定载脂蛋白浓度,则使用免疫化学技术以获得载脂蛋白的特异性检测。用于载脂蛋白检测的说明性的非限制性免疫化学技术包括免疫比浊技术、免疫浊度技术(immunonefelometrictechnique)、放射性免疫扩散(radialimmunodiffusion)、ELISA、电免疫分析和放射免疫分析。随着脂蛋白颗粒尺寸的减小,面积的校正愈加重要,即由于HDL颗粒的尺寸更小,对HDL颗粒的校正大于对LDL或VLDL颗粒的校正。在一个优选实施方案中,所述方法另外包括确定选自以下的至少一个脂蛋白参数:脂蛋白级分的平均颗粒尺寸、脂蛋白亚类的平均颗粒尺寸、级分脂蛋白颗粒浓度、亚类脂蛋白颗粒浓度以及至少一个脂蛋白颗粒亚类的脂质浓度和/或至少一个脂蛋白颗粒级分的脂质浓度。在一个优选实施方案中,脂蛋白颗粒级分的平均尺寸如下确定:n为脂蛋白颗粒级分中包含的脂蛋白颗粒亚类的数目,为脂蛋白颗粒尺寸并且PNj为所述脂蛋白颗粒尺寸的颗粒数。在一个优选实施方案中,脂蛋白的颗粒数(PN)如下确定:其中A(au)和分别为与模型函数j相关联的面积和脂蛋白颗粒尺寸。在本文件通篇,脂蛋白颗粒的尺寸应理解为以埃表示的脂蛋白颗粒半径。特定尺寸之脂蛋白颗粒的数目与以下比成比例:与对应于所述脂蛋白之模型函数相关联的面积和与所述脂蛋白相关联的体积之间的比,该比例因子为所使用设备的校准参数。优选地,根据本发明的一个实施方案,在确定颗粒数中,与脂蛋白函数相关联的面积为校正面积A'以只考虑脂蛋白颗粒核心中包含之脂质的贡献。本文中使用的脂蛋白颗粒级分的平均尺寸指形成特定脂蛋白颗粒级分之一部分的脂蛋白半径的平均尺寸。在一个优选实施方案中,通过将脂质体积除以脂蛋白颗粒体积计算脂蛋白颗粒级分的脂蛋白颗粒浓度。通过使用常用的换算因子将浓度单位换算成体积单位确定脂质体积。通过计算对应脂蛋白颗粒亚类的浓度之和获得每个主要脂蛋白颗粒级分的总脂蛋白颗粒浓度。在一个优选实施方案中,所述方法包括确定至少一个脂蛋白颗粒级分和/或至少一个脂蛋白颗粒亚类的脂质浓度。更优选地,使用回归模型确定脂质浓度。在一个优选实施方案中,用通过在以下区域内超速离心获得的脂蛋白级分中测量的脂质浓度来校准回归模型:5.4至5.15ppm、3.28至3.14ppm、2.15至1.85ppm、1.45至1ppm和1至0.7ppm。可使用其他方法来进行校准,例如ELISA、色谱法、NMR或酶促法。确定脂蛋白颗粒级分或亚类的脂质浓度包括确定选自以下的至少一种脂质:三酰甘油、胆固醇酯、游离胆固醇和磷脂。除此类相互排斥的特征和/或步骤的组合之外,本文件(包括权利要求书、说明书和附图)中所述的所有特征和/或所述方法的所有步骤均可以以任意组合进行组合。附图简述为了更好地理解本发明、其目的和优势,本说明书附有以下附图,其中如下所示:图1示出了根据本发明方法的甲基信号的去卷积,其中用于拟合的模型函数示于图1A中,并且根据其脂蛋白级分而分组的模型函数示于图1B中。图2示出了两个回归模型,其分别使(a)尺寸和化学位移联系起来以及使(b)宽度和化学位移联系起来。图3示出了甲基信号的NMR面积和扩散系数之间的关系。图4示出了在本发明方法的一个实施方案中用于校准脂质确定的回归模型的谱区。图5示出了三种样品的甲基信号的去卷积。发明详述在根据本发明的用于表征脂蛋白颗粒的体外方法中,通过2D扩散-排序1HNMR光谱学来分析样品。一旦已经获得2D扩散-排序1HNMR谱,则进行对应于甲基信号之谱部分的曲面拟合。使用多个模型函数,每个模型函数对应于具有特定脂蛋白颗粒尺寸的脂蛋白并且包括多个在拟合期间待估算的模型参数。与每个特定脂蛋白颗粒尺寸相关联的模型函数为具有以下形式的洛伦兹函数的三元组:三元组=洛伦兹(h1,f-f0,w,D)+洛伦兹(h2,f,w,D)+洛伦兹(h3,f+f0,w,D),其中h(au)、f(ppm)、w(ppm)和D(cm2s-1)为待确定的模型参数并且分别是与脂蛋白信号相关联的强度、化学位移、宽度和扩散系数。模型参数在拟合期间作为模型参数组来估算,为此使实验NMR信号和作为模型函数之线性组合而建立的模型信号之间的差异最小化。图1示出了对应于2D扩散-排序1HNMR实验之单一梯度的血清样品的甲基信号的谱部分及其拟合。在此情况下,即使对多个扩散梯度进行了曲面拟合,但是为了提高清晰度已描绘针对单一梯度的拟合。图1A以细迹线示出了用于拟合实验NMR谱的多个模型函数,所述实验NMR谱也以粗迹线示出。由用模型函数拟合建立的理论模型信号以点线示出。每个模型函数根据其脂蛋白颗粒尺寸可与给定的脂蛋白颗粒级分相关联。在图1B中,细线对应于与每种对应脂蛋白级分(在该实施例中:VLDL、LDL、HDL)相关联的模型信号之和。在该实施例中,如下进行曲面拟合:固定除信号强度之外的所有参数(化学位移、宽度和扩散系数),而非估算每个洛伦兹函数之三元组的所有参数。三元组洛伦兹函数使用以下形式:中心信号周围的两个信号相对于中心信号位移0.01ppm。为了固定与每个模型函数相关联的化学位移和宽度,预先使用其所有参数自由的三个三元组洛伦兹函数对300个谱进行去卷积。一旦已获得最佳拟合这300个实验谱的参数组,则将其用于拟合待用作固定参数的预示的两个回归模型,第一回归模型使化学位移和尺寸联系起来(图2a),而第二回归模型使宽度和化学位移联系起来(图2b)。图2a和图2b分别示出了经估算参数之作为尺寸的函数绘图的化学位移和作为化学位移的函数绘图的宽度,由其可确定使这两个参数对联系起来的对应关系。因此,以固定的脂蛋白颗粒尺寸,可使用建立的回归模型估算其NMR化学位移和宽度。可建立第三回归模型以使扩散系数与另一参数联系起来。或者,可使用爱因斯坦-斯托克斯方程由脂蛋白颗粒尺寸获得扩散系数:优选地,基于实验并且对应于多个不同的脂蛋白颗粒亚类来选择脂蛋白颗粒尺寸,这使得能够获得更加完整且可靠的脂蛋白谱。优选地,对已确定的扩散系数进行校正以将可能的稀释效应考虑在内。为了研究所需的校正程度,在本发明的一个优选实施方案中,对具有高甘油三酯水平(16mmol/L)的血清样品和不同稀释度的相同样品(1∶2、1∶4、1∶8和1∶16)进行分析(图3)。然后,利用NMR面积和扩散系数之间的关系预测每个NMR信号所需的校正:其中D0为在稀释条件下的平均扩散系数,D和A(au)分别为甲基峰的平均扩散系数和总面积,并且kS1、kS2为回归系数。为了确定平均扩散系数,对每份样品获得多个谱,在不同的梯度强度下获得每个谱。作为梯度之函数绘图的甲基曲线下面积随梯度的增加呈指数衰减。因此,平均扩散系数与将信号衰减(A/A0)之对数相对于梯度之平方绘图时获得的线的斜率成比例:log(A/A0)=-kDG2其中A为甲基信号面积,A0为零梯度下的甲基信号面积,k为恒定参数,并且G为梯度强度。在所选脂蛋白颗粒尺寸以及针对每个脂蛋白颗粒尺寸待确定的化学位移、宽度和扩散系数下,确定每个模型函数的信号强度以使实验NMR信号和由所考虑的多个模型信号建立的模型信号之间的差异最小化。可使用以下方程通过使归一化均方根误差(normalizedrootmeansquarederror,NRMSE)最小化进行拟合:其中Sexp和Sest分别为实验和估算的表面积(surface),n为所考虑数据点的数目,并且m为所使用梯度的数目。一旦已确定模型参数,则可通过将与每个模型函数相关联的NMR面积除以其相关联体积来获得颗粒加权的脂蛋白尺寸:其中Aj、和PNj为给定脂蛋白颗粒j的面积(au)、体积和颗粒数使颗粒数与面积和体积之间的比联系起来的比例因子可容易地通过使NMR面积和脂质浓度直接联系起来的已知校准标准来获得。然后,可通过将NMR脂蛋白颗粒尺寸乘以其相对于给定级分之总颗粒浓度的级分颗粒浓度来获得每个脂蛋白颗粒级分的平均颗粒尺寸:其中Z对应于给定脂蛋白颗粒级分的平均脂蛋白颗粒尺寸。校准PLS回归模型以预测主要脂蛋白颗粒级分(VLDL、LDL和HDL)的胆固醇和甘油三酯浓度。使用5.4至5.15ppm、3.28至3.14ppm、2.15至1.85ppm、1.45至1ppm和1至0.7ppm(示于图4)的区域作为X-块(block),并且使用胆固醇和甘油三酯的浓度作为Y-块。这两个块都是均值中心化的。使用将数据拆分10次的百叶窗交互验证(venetianblindscross-validation)评估潜在变量(latentvariable,LV)的最佳数目和PLS模型的验证性能。预测浓度和参照浓度之间的决定系数在校准步骤中为0.79至0.98。验证步骤的决定系数为0.81至0.98。确定脂蛋白颗粒级分或亚类的脂质浓度包括确定选自以下的至少一种脂质:三酰甘油、胆固醇酯、游离胆固醇和磷脂。甘油三酯(或三酰甘油)是由甘油和3个脂肪酸衍生的脂,其可见于脂蛋白颗粒中。可见于脂蛋白甘油三酯中的说明性的非限制性脂肪酸是棕榈酸、硬脂酸(estearicacid)、油酸、亚油酸和花生四烯酸(araquidonicacid)。甘油三酯是有助于实现来自肝的血糖和脂肪的双向转移的血脂。用于确定甘油三酯浓度的说明性的非限制性方法包括酶促测定。甘油三酯的酶促测定由于其具有特异性和灵敏性也是可能的。反应原理如下:甘油三酯被脂肪酶水解成甘油和游离脂肪酸。在甘油激酶存在的情况下,甘油被磷酸化成甘油-3-磷酸,其然后经磷酸甘油氧化酶氧化,伴随着形成过氧化氢。在过氧化物酶存在的情况下,4-氯苯酚和4-氨基安替比林与过氧化氢产生红色产物,醌亚胺。染色强度与甘油三酯的样品浓度直接成比例。胆固醇是一种两亲性脂质。胆固醇酯是胆固醇的脂,其中在脂肪酸的羧酸基团和胆固醇的羟基之间形成酯键。存在于脂蛋白颗粒中的胆固醇酯的说明性的非限制性实例是胆固醇棕榈酸酯、胆固醇硬脂酸酯、胆固醇油酸酯、胆固醇亚油酸酯和胆固醇花生四烯酸酯(Skipski,V.P.In:BloodLipidsandLipoproteins.Quantitation,CompositionandMetabolism.第471-483页(编辑G.J.Nelson,Wiley-Interscience,NewYork)(1972))。与胆固醇相比,胆固醇酯在水中具有更低的溶解度并且更疏水。多种方法可用于确定胆固醇浓度,例如重量分析法、浊度测定法、比浊法或光度测定法等。可使用用于定量比色/荧光胆固醇和胆固醇酯测定的市售试剂盒。通常来说,确定总的和游离的胆固醇(酯化的胆固醇预先通过例如毛地黄皂苷沉淀)的浓度,而胆固醇酯(酯化的胆固醇)的浓度由这两个浓度之间的差异计算。胆固醇浓度的酶促测定是特异性且灵敏的。反应原理如下:胆固醇酯酶催化胆固醇酯水解为游离胆固醇和游离脂肪酸。在胆固醇氧化酶存在的情况下,胆固醇被氧化为δ-4-胆固烷三醇以形成过氧化氢。在过氧化物酶存在的情况下,苯酚和4-氨基安替比林与过氧化氢产生红色产物,醌亚胺。染色强度与总胆固醇的样品浓度直接成比例。磷脂是这样的一类脂质,其存在于脂蛋白颗粒的壳中并且由于其可形成脂质双层而是所有细胞膜的主要组分。大部分的磷脂包含甘油二酯、磷酸基团和简单的有机分子,例如胆碱。磷脂分子的结构一般由疏水尾和亲水头组成。存在于脂蛋白颗粒中的磷脂的说明性的非限制性实例是磷脂酰胆碱、神经鞘氨醇磷脂(例如鞘磷脂)、磷脂酰乙醇胺、磷脂酰肌醇和磷脂酰丝氨酸。用于确定磷脂浓度的说明性的非限制性方法包括用于定量比色/荧光磷脂测定的市售测定试剂盒。反应原理如下:磷脂(例如卵磷脂、溶血卵磷脂和鞘磷脂)被酶促水解成胆碱,使用胆碱氧化酶和H2O2特异性染料来对其进行确定。粉红色产物在570nm下的光密度或者荧光强度(530/585nm)与样品中的磷脂浓度直接成比例。实施例2D扩散-排序1HNMR光谱学(DOSY):通过NMR光谱学在BrukerAvanceIII光谱仪上于310K下记录1HNMR谱来分析血清样品。将双重刺激回声(doublestimulatedecho,DSTE)脉冲程序与双极梯度脉冲和纵向涡电流延迟(longitudinaleddycurrentdelay,LED)一起使用。弛豫延迟(relaxationdelay)为2秒,将自由感应衰减采集成64K复数数据点(complexdatapoint),并且要求对每份样品进行32次扫描。在32个步骤中将梯度脉冲强度从最大强度53.5高斯cm-1的5%提高至95%,在此平方梯度脉冲强度呈线性分布。曲面拟合:在本实施例中,将脂蛋白NMR信号建模为以下洛伦兹函数的三元组,其中中心信号周围的两个信号位移0.01ppm:其中h(au)、f(ppm)、w(ppm)和D(cm2s-1)为给定脂蛋白信号的强度、化学位移、宽度和扩散系数,每个脂蛋白信号与脂蛋白颗粒尺寸相对应。基于通过HPLC获得的脂蛋白颗粒尺寸,使用9个脂蛋白颗粒尺寸并且因此也使用9个模型函数。这9个模型函数根据其NMR大小与给定的脂蛋白颗粒级分(VLDL、LDL或HDL)相关联。因此,函数F1至F3与VLDL相关联,函数F4至F6与LDL相关联,并且函数F7至F9与HDL相关联(表1)。将主要脂蛋白颗粒级分限定为VLDLLDL和HDL使用具有固定除信号强度(h)之外的所有参数(化学位移、宽度和扩散系数)的9个模型函数来进行甲基信号的曲面拟合。每份样品的拟合平均耗时29.47±4.42秒。因此,将甲基信号分解成单个脂蛋白信号以获得具有固定NMR尺寸之9种脂蛋白的贡献。图5A至C示出了三个对象的曲面拟合的结果,其也总结于表1中。必须指出的是,即使使用9个模型函数来拟合谱,但是并非其所有均用于找到最终解决方案。图5D至F示出了模型函数根据其相关联的脂蛋白颗粒主要级分的分组。对象1示出明显的HDL面积(在图5D中以深灰色示出),对象2具有增加的LDL面积(在图5E中以浅灰色示出)并且对象3以非常高的VLDL面积为特征(在图5F中以中等灰色示出)。通过用随机选择的初始信号强度值拟合每份样品10次来研究解决方案的唯一性。由于信号强度的动态范围可非常高,因此使用下式来评估每个模型函数和样品在10次不同拟合之间的变异系数(CV):其中h代表给定模型函数的信号强度。最大(Max)、最小(Min)和标准偏差(SD)值由在每份样品中的10次拟合来评估。结果,在10轮之后获得对所有样品的唯一解决方案。在此情况下,确定中心洛伦兹的信号强度的变异系数(CV),因为其他模型函数已在拟合期间固定。用于计算变异系数的上述表达式可通用于其中在拟合中使用一个以上自由模型参数的情况。拟合的归一化均方根误差(NRMSE)使用以下方程来计算:其中Sexp和Sest分别为实验和估算的表面积,n为在间隔长度(0.7至1ppm)内所考虑的数据点的数目,并且m为所使用梯度的数目。在该实施例中,n和m对每份样品而言具有相同值。获得的平均NRMSE小于1.5%。为了获得颗粒加权的脂蛋白尺寸,我们首先将每个NMR面积除以其相关联的体积:其中Aj、和PNj为给定脂蛋白颗粒j的面积(au)、体积和颗粒数然后,如下获得每个脂蛋白颗粒级分的平均颗粒尺寸:将脂蛋白颗粒尺寸乘以其相对于给定颗粒级分的总颗粒浓度的级分颗粒浓度。通过将脂质体积除以颗粒体积计算每个脂蛋白颗粒亚类的颗粒浓度。通过使用常用的换算因子将浓度单位换算成体积单位来确定脂质体积。通过计算对应颗粒亚类的浓度之和获得每个主要颗粒级分的总颗粒浓度。使用在图4中所示的区域内校准的PLS模型来确定脂质浓度,即:5.4至5.15ppm、3.28至3.14ppm、2.15至1.85ppm、1.45至1ppm和1至0.7ppm。通过顺序超速离心获得参照脂质并且其对应于3种脂蛋白颗粒级分(VLDL、LDL和HDL)的胆固醇和甘油三酯。本发明的方法允许获得高级脂蛋白谱,如表1中所示。来自全组之3个代表性对象的ALT报道出于举例说明的目的而总结于表1中。对象1血脂正常,对象2显示具有高LDL胆固醇水平(血胆固醇过多),并且对象3显示高甘油三酯和低HDL胆固醇水平(致动脉粥样化性血脂异常)。本发明的方法提供了主要脂蛋白级分及其亚类的总胆固醇(C)、甘油三酯(TG)和颗粒浓度(P)。另外,本发明的方法提供了主要脂蛋白级分的尺寸。对象1表现出正常脂质水平(限定为VLDL-TG<150mg/dL、LDL-C<160mg/dL且HDL-C>40mg/dL),对象2表现出升高的LDL-C水平以及正常的VLDL-TG和HDL-C水平,并且对象3表现出升高的VLDL-TG水平、降低的HDL-C水平和正常LDL-C水平。还应指出的是,对象3尽管LDL-C水平正常,但具有提高的LDL-水平P,并且其小LDL-P浓度高于对象2中的浓度。因此,甘油三酯水平升高的对象与增加的LDL-P值相关,这是因为甘油三酯浓度增加导致形成较大浓度的较小LDL颗粒。高级脂蛋白测试已示出,这些脂蛋白参数和心血管疾病的风险之间具有统计学关联(Sniderman,A.和P.O.Kwiterovich.2013.Updateonthedetectionandtreatmentofatherogeniclow-densitylipoproteins.Currentopinioninendocrinology,diabetes,andobesity20:140-147)。例如,在一项研究中,在调整协变量之后,HDL颗粒(HDL-P)的数目而非高密度脂蛋白胆固醇(HDL-C)浓度独立地与颈动脉内膜中层厚度相关联(Mackey,R.H.,P.Greenland,D.C.Goff,Jr.,D.Lloyd-Jones,C.T.Sibley和S.Mora.2012.High-densitylipoproteincholesterolandparticleconcentrations,carotidatherosclerosis,andcoronaryevents:MESA(动脉粥样硬化的多种族研究).JAmCollCardiol60:508-516)。最后,与使用Framingham风险评分之风险因素的预测模型中的常规脂质测量相比,使用脂蛋白颗粒亚类改善了对亚临床动脉粥样硬化之NMR得出的风险分级(Wurtz,P.,J.R.Raiko,C.G.Magnussen,P.Soininen,A.J.Kangas,T.Tynkkynen,R.Thomson,R.Laatikainen,M.J.Savolainen,J.Laurikka,P.Kuukasjarvi,M.Tarkka,P.J.Karhunen,A.Jula,J.S.Viikari,M.Kahonen,T.Lehtimaki,M.Juonala,M.Ala-Korpela和O.T.Raitakari.2012.High-throughputquantificationofcirculatingmetabolitesimprovespredictionofsubclinicalatherosclerosis.EuropeanHeartJournal33:2307-2316)。表1.使用本发明方法获得的脂蛋白参数的总结对象1对象2对象3脂质(mg/dL)VLDL-TG13.722.6150.3LDL-C105.4161.8127.0LDL-TG14.920.918.4HDL-C66.549.534.4HDL-TG7.16.611.0颗粒浓度*VLDL-P12.422.0106.3大VLDL-P0.20.35.9中等VLDL-P1.01.921.6小VLDL-P11.119.778.8LDL-P980.61399.11230.4大LDL-P80.0184.323.7中等LDL-P212.4406.8310.5小LDL-P688.2808.0896.1HDL-P32.227.125.9大HDL-P2.41.30.3中等HDL-P10.06.83.6小HDL-P19.819.022.0尺寸(nm)VLDL39.038.942.2LDL19.720.119.5HDL8.28.07.8*VLDL/LDL:nmol/L;HDL:μmol/L当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1