一种土壤质地颗粒含量预测方法与流程
本发明涉及一种土壤质地颗粒含量预测方法,属于土壤预测技术领域。
背景技术:
土壤质地是土壤学最重要的物理属性之一。土壤质地指的是土壤粗细颗粒组成及含量。土壤质地的空间预测对于土壤水分模拟、土壤污染修复应用非常重要,是大气模型、水文模型、陆面过程模型等模型最重要的输入参数之一。在土壤质地分级方面,欧美国家已有不同规则的分级标准,土壤颗粒分级均采用粘粒、粉粒和砂粒三大类别。以国际制为例,土壤颗粒粒径小于0.002毫米时定义为粘粒,介于0.002与0.02毫米时定义为粉粒,介于0.02与2毫米时定义为砂粒。土壤质地的常规测定方法有比重计法、吸管法、流水冲洗法、筛分法等。吸管法过程较为复杂,精确度高,是目前采用较多的一种测定方式。近二十年来随着传感器的飞速发展,利用土壤光谱信息预测土壤质地技术也得到快速应用,重要的技术包括γ射线(美国GR320便携式伽玛能谱仪)、X射线(德国SOMATOM-PLUS螺旋式CT)、红外近红外波段(瑞士NIRFlexN-500光谱仪)、无线电频率(瑞典MALA探地雷达)和电磁感应(加拿大GeonicsEM38)。然而,无论哪一种测定方法,均只能测定点位尺度或坡面尺度的土壤质地信息,难以实时、快速、准确测定大区域的土壤质地。受地形、气候、母质等诸多成土因素的复合影响,土壤质地在空间分异方面表现出不同的结构性和规律性。大研究区域的土壤质地信息获取主要是使用土壤-景观模型进行空间预测。土壤-景观模型的本质是预测模型,主要是定量描述所观察到景观要素(与成土因素相关)、土壤类型/属性之间的相关性,进而用来预测未采样区域的土壤信息。基于该模型,常规的土壤制图技术包括线性回归模型、模糊聚类、决策树、地统计模型等方法。实际应用中,为便于管理常将土壤的颗粒组成划分为不同组合,该组合的重要表达方式是质地分类三角坐标图。在这种分类中,粘粒、粉粒与砂粒含量的总和为1,不同颗粒含量以百分制表示。由于土壤质地是种非常稳定的自然属性,土壤质地预测通常对土壤颗粒分级单独预测,分别预测土壤质地的粘粒、粉粒、砂粒含量。因此,如无特别说明,本说明书所描述的土壤质地预测均面向土壤颗粒含量的不同分级,如粘粒含量。土壤质地是土壤调查中关键土壤属性之一。在区域土壤调查与制图过程中,小样区采样代价往往较低,相对采样密度也比偏远地区高。因此,基于局部土壤-景观模型预测的土壤属性空间分布数据,能否用来补充完善其他区域的预测模型,是大研究区域尤其是涉及到偏远不发达地区土壤调查的技术瓶颈。换言之,利用高密度采样的局部研究区域的生产制图结果,提取具有代表性的结果土壤数据,进而重新构建面向更大区域的土壤质地预测模型,在弥补区域样点不足的现代土壤图生产中具有重大的应用意义。然而,尽管各类基于传感器反演的土壤质地获取手段不断更新,区域土壤调查工作的持续开展,现有土壤质地预测技术仍缺乏高效处理省级、流域级区域的生产模式。同时,众多大气模型、陆面过程模型等系统应用质量的不断提升也为土壤质地预测技术提出了新的挑战,区域级土壤质地专题图的生产与加工已经严重制约了土壤信息在各农业、林业、牧业部门的应用范围,归纳起来有以下几个局限性:(1)现有测定技术无法实时获取大规模调查区域的土壤质地信息。景观基于传感器的质地测定技术成本较低,然而,获取大规模区域不同深度的土壤质地数据仍面临重大挑战,且其精度也亟待进一步提升;传统的实验室分析技术较为完善,分析精度较高,但其分析时间较长、成本较高。另外,以上分析技术均是面向点位尺度的质地分析,无法实现区域级别土壤信息的批量获取与生产。因此,现代土壤制图技术仍是土壤信息空间表征的主要技术手段。(2)偏远地区进行大规模土壤调查代价较高。给定足够的土壤数据(具体包括位置、深度与化验测定的土壤数据)与环境变量信息(具体包括影响土壤形成、发育与演化的环境变量,如地形、成土母质、气候等),借助现代数字土壤制图技术可以预测其他区域的土壤信息,并可追踪预测过程,给出精度评价。然而,由于交通、时间与成本问题,存在大量的不可达区域,如戈壁、山地等。无法获取这些区域的土壤数据直接制约了数字土壤制图技术的应用。如何借助土壤学的理论指导,将土壤信息的影响因素外推至难以到达的区域,进而提升总体的预测精度,仍是技术人员广泛关注的生产难题。(3)基于外推法制图技术亟待改进,尤其关注局部景观在全局景观中的代表性问题。目前,基于外推法的土壤信息获取主要是集中于历史土壤信息更新方面,尚未涉及到局部土壤-景观模型的外推性问题。外推法制图技术的不足,导致现有土壤调查工作缺乏宏观的技术指导,更加费时费力。因此,如何利用有限的土壤数据,借助土壤-景观模型与近似计算技术(外推法)相结合的技术手段,进行大区域数字土壤质地制图是一种潜在有希望的技术手段。
技术实现要素:
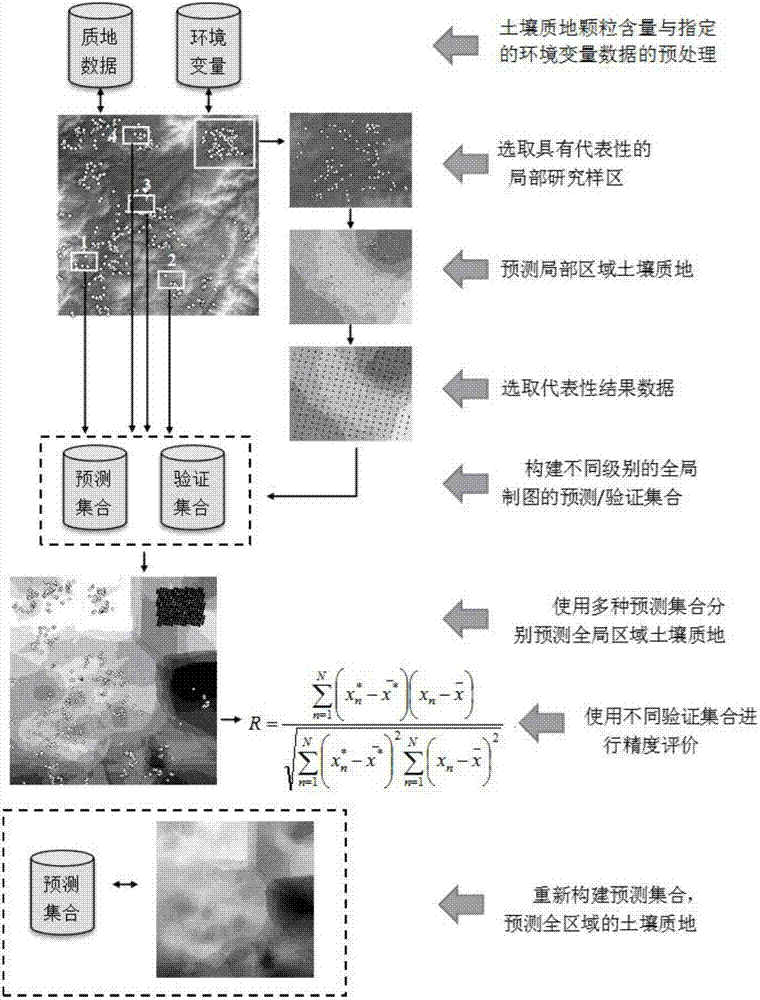
本发明所要解决的技术问题是提供一种基于局部土壤-景观模型的外推土壤制图方法,能够解决现有偏远地区土壤调查样点稀疏与部分区域土壤图生产精度不高问题的土壤质地颗粒含量预测方法。本发明为了解决上述技术问题采用以下技术方案:本发明设计了一种土壤质地颗粒含量预测方法,其特征在于,包括如下步骤:步骤001.由目标土壤区域中所有预设样点位置构成全局样点集合Po,并获得全局样点集合Po中各个样点位置所对应的观测土壤质地颗粒含量,以及指定的环境变量数据,然后初始化k=1,并进入步骤002;步骤002.根据土壤采样密度、土壤类型和地形起伏,在目标土壤区域中选取局部区域,并由局部区域中的各个样点位置,构成局部区域样点集合Poi,再根据全局样点集合Po与局部区域样点集合Poi之差,获得非局部区域样点集合Por,然后进入步骤003;步骤003.获得目标土壤区域中土壤种类数ks,以及全局样点集合Po中样点位置的数量np,同时,在目标土壤区域中,分别获得各个土壤种类所对应土壤区域中样点位置的数量npi,然后进入步骤004;步骤004.分别针对目标土壤区域中的各个土壤种类,判断土壤种类所对应土壤区域中样点位置的数量npi是否小于是则在目标土壤区域中,该土壤种类所对应土壤区域中的各个样点位置中,随机选择A·npi个样点位置;否则在目标土壤区域中,该土壤种类所对应土壤区域中的各个样点位置中,随机选择个样点位置;由此,在目标土壤区域中,获得分别对应各个土壤种类、经上述选择的各个样点位置,并构成独立验证样点集合Po_vk,然后进入步骤005;其中,A为预设小于0.5的比例参数;步骤005.分别针对全局样点集合Po中的各个样点位置、局部区域样点集合Poi中的各个样点位置、独立验证样点集合Po_vk中的各个样点位置,根据样点位置所对应的观测土壤质地颗粒含量,获得分别对应各集合的散点图,然后进入步骤006;步骤006.将分别对应全局样点集合Po、局部区域样点集合Poi、独立验证样点集合Po_vk的三幅散点图进行重叠,并判断三幅散点图两两重合的阴影面积占三幅散点图中最小阴影面积的比例是否超过预设重叠比例阈值,是则进入步骤007;否则返回步骤002;步骤007.根据局部区域样点集合Poi中各个样点位置所对应的观测土壤质地颗粒含量,以及指定的环境变量数据,训练获得环境变量数据与观测土壤质地颗粒含量之间的定量关系,并进入步骤008;步骤008.采用步骤007所获定量关系,针对局部区域中的非样点位置区域进行预测,进而获得局部区域所对应的预测土壤质地颗粒含量,然后进入步骤009;步骤009.基于局部区域所对应的预测土壤质地颗粒含量,根据目标土壤区域中局部区域的指定属性,针对局部区域进行预设等级划分,获得局部区域所对应的分级矢量图,并将该分级矢量图与局部区域所对应的土壤类型图进行叠加,获得叠加后的叠加矢量图,接着在该叠加矢量图各个图斑上的样点位置中,分别随机选择预设比例的样点位置,构成局部区域再选样点集合Pek,然后进入步骤010;步骤010.获得非局部区域样点集合Por中,除独立验证样点集合Po_vk中样点位置外的其余样点位置,构成非局部区域再选预测样点集合Por_pk;同时,获得全局样点集合Po中,除独立验证样点集合Po_vk中样点位置外的其余样点位置,构成非独立验证验证样点集合Po_pk;然后进入步骤011;步骤011.在局部区域再选样点集合Pek中,按预设比例划分为局部区域再选第一预测样点集合Pe_pk和局部区域再选第二验证样点集合Pe_vk,然后进入步骤012;步骤012.基于局部区域再选样点集合Pek、局部区域再选第一预测样点集合Pe_pk和局部区域再选第二验证样点集合Pe_vk、独立验证样点集合Po_vk、非独立验证预测样点集合Po_pk和非局部区域再选预测样点集合Por_pk,建立三种预测/验证样点集合P1k、P2k、P3k如下,然后进入步骤013;预测/验证样点集合P1k:预测样点集合{Pek,Por_pk},验证样点集合{Po_vk};预测/验证样点集合P2k:预测样点集合{Po_pk},验证样点集合{Po_vk};预测/验证样点集合P3k:预测样点集合{Pe_pk,Por_pk},验证样点集合{Po_vk,Pe_vk};步骤013.分别针对P1k、P2k、P3k中的预测样点集合,根据预测样点集合中各个样点位置所对应的观测土壤质地颗粒含量,以及指定的环境变量数据,训练获得环境变量数据与观测土壤质地颗粒含量之间的定量关系,即获得分别对应P1k、P2k、P3k的定量关系,然后进入步骤014;步骤014.分别采用P1k、P2k、P3k的定量关系,分别针对P1k、P2k、P3k中的验证样点集合,根据验证样点集合中各个样点位置所对应的环境变量数据,针对验证样点集合中各个样点位置进行预测,获得验证样点集合中各个样点位置所对应的预测土壤质地颗粒含量,即分别获得P1k、P2k、P3k中验证样点集合中各个样点位置所对应的预测土壤质地颗粒含量,然后进入步骤015;步骤015.针对P1k、P2k、P3k中验证样点集合中各个样点位置所对应的预测土壤质地颗粒含量,按P1k、P2k、P3k分别进行精度检测,获得P1k、P2k、P3k分别所对应的精度结果R1k、R2k、R3k,然后进入步骤016;步骤016.判断k是否等于预设循环次数K,是则获得{R11、…、R1k、…、R1K}、{R21、…、R2k、…、R2K}、{R31、…、R3k、…、R3K}三个集合,并进入步骤017;否则用k的值加1的结果针对k进行赋值,并返回步骤003;步骤017.分别获得{R11、…、R1k、…、R1K}、{R21、…、R2k、…、R2K}、{R31、…、R3k、…、R3K}三个集合的平均值然后进入步骤018;步骤018.判断之间的大小关系,若或则基于步骤002至步骤011中的{Por,Pek}集合,通过其各个样本点位置的环境变量数据、观测土壤质地颗粒含量,获得定量关系,再采用该定量关系针对目标土壤区域进行土壤质地颗粒含量预测;若之间满足其它大小关系,则基于全局样点集合Po,通过其各个样本点位置的环境变量数据、观测土壤质地颗粒含量,获得定量关系,再采用该定量关系针对目标土壤区域进行土壤质地颗粒含量预测。作为本发明的一种优选技术方案:所述步骤001中,由目标土壤区域中所有预设样点位置构成全局样点集合Po,并获得全局样点集合Po中各个样点位置所对应的观测土壤质地颗粒含量;然后基于全局样点集合Po中各个样点位置所对应的观测土壤质地颗粒含量,针对环境变量数据的类型进行拟合,根据环境变量的显著性大小优化环境变量数据的类型,获得指定的环境变量数据,获得全局样点集合Po中各个样点位置所对应的指定的环境变量数据。作为本发明的一种优选技术方案:所述步骤001中,针对所述观测土壤质地颗粒含量,采用拉依达准则法,通过如下准则,进行异常点赋值操作,进而获得全局样点集合Po中各个样点位置所对应的观测土壤质地颗粒含量pi;若pi>μ+3σ,则pi=μ+3σ;若pi<μ-3σ,则pi=μ-3σ;其中,pi表示观测土壤质地颗粒含量,μ和σ分别表示所有观测土壤质地颗粒含量的期望和标准差。作为本发明的一种优选技术方案:土壤质地颗粒含量包括粘粒、粉粒、砂粒三种百分比含量,其总和为100%。作为本发明的一种优选技术方案:所述指定的环境变量数据包括高程、坡度、坡向、地形湿度指数、叶面积指数、植被覆盖指数、年均降雨、年均气温、土地利用、土壤类型、日照时间。作为本发明的一种优选技术方案:所述步骤002中,所述局部区域的选取满足如下三个条件:条件1.局部区域的采样密度为目标土壤区域平均采样密度的预设倍数以上;条件2.局部区域中土壤类型在目标土壤区域所对应的土壤面积占目标土壤区域百分比大于预设面积比例阈值;条件3.局部区域对应指定环境变量类型的数据,包括目标土壤区域对应该指定环境变量类型的平均数据。作为本发明的一种优选技术方案:所述步骤005中,在获得分别对应各集合的散点图后,分别针对各幅散点图,采用局部多项式回归方法进行平滑处理,更新各幅散点图。作为本发明的一种优选技术方案:所述步骤009中,针对局部区域进行预设等级划分,获得局部区域所对应的分级矢量图,具体包括如下步骤:步骤A01.选择局部区域中地形的平坦情况进行分析,判断局部区域中地形的平均坡度是否大于预设坡度阈值,是则进入步骤A02;否则进入步骤A03;步骤A02.基于局部区域中地形的最大坡度和最小坡度,针对局部区域进行预设等级划分,获得局部区域所对应的分级矢量图,且每个等级所对应最大坡度与最小坡度之间的差值相等;步骤A03.采用网格提取法,针对局部区域,按横向、纵向间隔相等距离,进行预设等级划分,获得局部区域所对应的分级矢量图。作为本发明的一种优选技术方案:所述步骤015中,针对P1k、P2k、P3k中验证样点集合中各个样点位置所对应的预测土壤质地颗粒含量,通过如下公式,按P1k、P2k、P3k分别进行精度检测,获得P1k、P2k、P3k分别所对应的精度结果R1k、R2k、R3k;其中,R分别指代了R1k、R2k、R3k,n={1,…,N},N表示对应验证样点集合中样本点位置的数量,xn表示样本点位置所对应的观测土壤质地颗粒含量,表示对应验证样点集合中所有样本点位置所对应观测土壤质地颗粒含量的平均值,表示样本点位置所对应的预测土壤质地颗粒含量,表示对应验证样点集合中所有样本点位置所对应预测土壤质地颗粒含量的平均值。本发明所述一种土壤质地颗粒含量预测方法采用以上技术方案与现有技术相比,具有以下技术效果:(1)本发明所设计的土壤质地颗粒含量预测方法,提出了一套完整的基于外推技术的土壤属性预测技术方案,运用了局部土壤-景观模型的外推技术,通过结合交叉验证机制实现了最优预测数据集的选取,采用了“外推土壤专家知识,定量评价预测精度”技术,实现了“不同研究样区,通用外推框架;不同数据属性,最优外推区域;局部模型评价,不确定性分析”的通用数字土壤制图技术方案,具有广阔的工业化应用前景;(2)本发明所设计的土壤质地颗粒含量预测方法,具有一定的区域、土壤属性普适性,所提出技术方案不仅面向于偏远地区调查密度变化较大的土壤调查工作,也适宜于发达地区的土壤更新调查工作;同样,类似于土壤质地信息,其它土壤属性,如有机质、pH与全氮等信息在土壤属性预测过程中也会涉及土壤-景观模型的外推性问题;本发明所设计方法提出的不同预测集合的代表性选取、动态构建与定量化评价,提升了土壤专题图的生产质量,该方法还具有较好的稳定性,动态构建的预测点集合有望在保证生产精度的前提下,有效地规避了外推性数字土壤制图过程会涉及到的不确定性问题;(3)本发明所设计的土壤质地颗粒含量预测方法,提出了独立验证技术与代表性局部区域选择策略相辅相成,即可单独使用,也可以集成至一整套土壤制图技术流程;独立验证技术能够保证预测结果具有客观的评价结果,代表性局部区域选取是外推土壤制图的核心环节,决定了外推法能够提升预测精度,二者具有较高的可移植性,为不同过程的土壤制图体系提供了参考,在未来土壤信息膨胀的高精度计算环境下,可用于制图结果的客观评价与精度提升,从而优化了传统土壤制图技术体系的计算精度与可移植性。附图说明图1是实施案例中全局研究区域与局部外推区域样点分布图;图2是本发明设计的土壤质地颗粒含量预测方法的流程示意图;图3a是实施案例中全局样点集合Po中的各个样点位置土壤质地数据集的散点图分布;图3b是实施案例中局部区域样点集合Poi中的各个样点位置土壤质地数据集的散点图分布;图3c是实施案例中独立验证样点集合Po_vk中的各个样点位置土壤质地数据集的散点图分布;图4是实施案例中局部外推区域粘粒含量的预测分布图;图5是全局研究区域粘粒含量的预测分布图。具体实施方式下面结合说明书附图对本发明的具体实施方式作进一步详细的说明。本发明的基本思想是在数字土壤制图过程中,针对局部区域采样密度相对较高的现象,遴选局部外推区域(以下简称局部区域)。以局部区域为研究目标,预测土壤质地信息空间分布,并从中选取具有代表性的预测结果作为全局土壤质地(包含粘粒、粉粒、砂粒含量)预测的输入数据。进而,构建不同级别的全局预测点集合与验证点集合,试预测全局土壤质地信息并评价外推技术的可用性,最终提升数字土壤图的生产精度。以青海省祁连县研究样区的土壤粘粒含量预测为例,青海省祁连县东部区域人口密度较低、交通条件较差,给野外调查采样带来诸多困难。该区域的样点密度较为分散,部分可达性较高的区域采样密度较高,其他区域密度相对较低,如图1所示。同时,该区域的景观特征以高山为主,土壤类型变异性不大,植被类型较为单一。实施案例以该区域的土壤粘粒预测为例,针对该区域的土壤质地颗粒含量进行预测。如图2所示,本发明所设计土壤质地颗粒含量预测方法在实际应用过程当中,具体包括如下步骤:步骤001.由目标土壤区域中所有预设样点位置构成全局样点集合Po,并获得全局样点集合Po中各个样点位置所对应的观测土壤质地颗粒含量,其中,针对所述观测土壤质地颗粒含量,采用拉依达准则法,通过如下准则,进行异常点赋值操作,进而获得全局样点集合Po中各个样点位置所对应的观测土壤质地颗粒含量pi,土壤质地颗粒含量包括粘粒、粉粒、砂粒三种百分比含量,其总和为100%。若pi>μ+3σ,则pi=μ+3σ;若pi<μ-3σ,则pi=μ-3σ;其中,pi表示观测土壤质地颗粒含量,μ和σ分别表示所有观测土壤质地颗粒含量的期望和标准差。根据土壤-景观模型定义,对于土壤属性影响最为显著的五大要素分别是:地形、母质、生物、气候、时间。根据环境变量选取的难度与代价,选取数字高程模型、地质图、遥感图像、年均气候、年均降雨、土地利用与土壤类型系列数据作为环境变量的提取源数据,所提取的环境变量数据包括高程、坡度、坡向、地形湿度指数、叶面积指数、植被覆盖指数、年均降雨、年均气温、土地利用、土壤类型、日照时间,然后基于全局样点集合Po中各个样点位置所对应的观测土壤质地颗粒含量,针对环境变量数据的类型进行拟合,根据环境变量的显著性大小优化环境变量数据的类型,获得指定的环境变量数据,获得全局样点集合Po中各个样点位置所对应的指定的环境变量数据,指定的环境变量数据为{土地利用,NDVI,高程,坡度,年均降雨};然后初始化k=1,并进入步骤002。步骤002.当研究区域较大时,其面积可能大于上万平方公里,由于交通、可达性与食宿等问题,部分区域往往采样密度较高,这里的采样密度较高指的是相对概念,如图2所示,以系统生成的采样点为例,将这些区域设定为局部区域,即根据土壤采样密度、土壤类型和地形起伏,根据满足如下三个条件,在目标土壤区域中选取局部区域。在这里以青海省祁连县研究样区为实施例,即选取葫芦沟小流域作为其中一个局部区域,其局部区域中样点位置总数为71个。条件1.局部区域的采样密度(个/平方公里)为目标土壤区域平均采样密度的三倍数以上;条件2.局部区域中土壤类型在目标土壤区域所对应的土壤面积占目标土壤区域百分比大于预设面积比例阈值;条件3.局部区域对应指定环境变量类型的数据,包括目标土壤区域对应该指定环境变量类型的平均数据。诸如这里的指定环境变量类型为坡度,实际中可设定局部区域对应坡度的数据范围是目标土壤区域对应平均坡度的±20%,例如目标土壤区域对应平均坡度是15°,则局部区域对应坡度的数据范围是[12°,18°]。并由局部区域中的各个样点位置,构成局部区域样点集合Poi,再根据全局样点集合Po与局部区域样点集合Poi之差,获得非局部区域样点集合Por,然后进入步骤003。步骤003.获得目标土壤区域中土壤种类数ks,以及全局样点集合Po中样点位置的数量np,同时,在目标土壤区域中,分别获得各个土壤种类所对应土壤区域中样点位置的数量npi,然后进入步骤004。步骤004.分别针对目标土壤区域中的各个土壤种类,判断土壤种类所对应土壤区域中样点位置的数量npi是否小于是则在目标土壤区域中,该土壤种类所对应土壤区域中的各个样点位置中,随机选择A·npi个样点位置;否则在目标土壤区域中,该土壤种类所对应土壤区域中的各个样点位置中,随机选择个样点位置;由此,在目标土壤区域中,获得分别对应各个土壤种类、经上述选择的各个样点位置,并构成独立验证样点集合Po_vk,然后进入步骤005;其中,A为预设小于0.5的比例参数,实际应用中,A可以选取0.25。步骤005.分别针对全局样点集合Po中的各个样点位置、局部区域样点集合Poi中的各个样点位置、独立验证样点集合Po_vk中的各个样点位置,根据样点位置所对应的观测土壤质地颗粒含量,获得分别对应各集合的散点图,如图3a、图3b、图3c所示,再分别针对各幅散点图,采用局部多项式回归方法进行平滑处理,更新各幅散点图,然后进入步骤006。步骤006.将分别对应全局样点集合Po、局部区域样点集合Poi、独立验证样点集合Po_vk的三幅散点图进行重叠,并判断三幅散点图两两重合的阴影面积占三幅散点图中最小阴影面积的比例是否超过预设重叠比例阈值50%,是则进入步骤007;否则返回步骤002。步骤007.根据局部区域样点集合Poi中各个样点位置所对应的观测土壤质地颗粒含量,以及指定的环境变量数据,训练获得环境变量数据与观测土壤质地颗粒含量之间的定量关系,并进入步骤008。步骤008.采用步骤007所获定量关系,针对局部区域中的非样点位置区域进行预测,进而获得局部区域所对应的预测土壤质地颗粒含量,如图4所示,然后进入步骤009。步骤009.基于局部区域所对应的预测土壤质地颗粒含量,根据目标土壤区域中局部区域的指定属性,针对局部区域进行预设等级划分,获得局部区域所对应的分级矢量图,实际应用中,这里的指定属性选择选择地形的平坦情况,具体包括如下步骤:步骤A01.选择局部区域中地形的平坦情况进行分析,判断局部区域中地形的平均坡度是否大于预设坡度阈值5°,是则进入步骤A02;否则进入步骤A03;步骤A02.基于局部区域中地形的最大坡度和最小坡度,针对局部区域进行十个等级划分,获得局部区域所对应的分级矢量图,且每个等级所对应最大坡度与最小坡度之间的差值相等;步骤A03.采用网格提取法,针对局部区域,按横向、纵向间隔相等距离,进行十个等级划分,获得局部区域所对应的分级矢量图。然后将该分级矢量图与局部区域所对应的土壤类型图进行叠加,获得叠加后的叠加矢量图,接着在该叠加矢量图各个图斑上的样点位置中,分别随机选择30%-50%的样点位置,构成局部区域再选样点集合Pek,然后进入步骤010。这里需要注意的是,从图斑中选取样点位置的比例需要视全局预测方法而定。例如,使用传统的线性回归模型(如多元线性回归)进行预测,则局部区域的选择样点位置数不宜过多,比例设置为25%;如果使用基于大量数据的机器学习算法(如随机森林)进行预测,可以将局部区域的选择样点位置数选择比例设置为40%。步骤010.获得非局部区域样点集合Por中,除独立验证样点集合Po_vk中样点位置外的其余样点位置,构成非局部区域再选预测样点集合Por_pk;同时,获得全局样点集合Po中,除独立验证样点集合Po_vk中样点位置外的其余样点位置,构成非独立验证验证样点集合Po_pk;然后进入步骤011。步骤011.在局部区域再选样点集合Pek中,按预设比例划分为局部区域再选第一预测样点集合Pe_pk和局部区域再选第二验证样点集合Pe_vk,诸如第一预测样点集合Pe_pk中样点位置的数量为局部区域再选样点集合Pek的75%,第二验证样点集合Pe_vk中样点位置的数量为局部区域再选样点集合Pek的25%,然后进入步骤012。步骤012.基于局部区域再选样点集合Pek、局部区域再选第一预测样点集合Pe_pk和局部区域再选第二验证样点集合Pe_vk、独立验证样点集合Po_vk、非独立验证预测样点集合Po_pk和非局部区域再选预测样点集合Por_pk,建立三种预测/验证样点集合P1k、P2k、P3k如下,然后进入步骤013。预测/验证样点集合P1k:预测样点集合{Pek,Por_pk},验证样点集合{Po_vk};预测/验证样点集合P2k:预测样点集合{Po_pk},验证样点集合{Po_vk};预测/验证样点集合P3k:预测样点集合{Pe_pk,Por_pk},验证样点集合{Po_vk,Pe_vk}。步骤013.分别针对P1k、P2k、P3k中的预测样点集合,根据预测样点集合中各个样点位置所对应的观测土壤质地颗粒含量,以及指定的环境变量数据,训练获得环境变量数据与观测土壤质地颗粒含量之间的定量关系,即获得分别对应P1k、P2k、P3k的定量关系,然后进入步骤014。步骤014.分别采用P1k、P2k、P3k的定量关系,分别针对P1k、P2k、P3k中的验证样点集合,根据验证样点集合中各个样点位置所对应的环境变量数据,针对验证样点集合中各个样点位置进行预测,获得验证样点集合中各个样点位置所对应的预测土壤质地颗粒含量,即分别获得P1k、P2k、P3k中验证样点集合中各个样点位置所对应的预测土壤质地颗粒含量,然后进入步骤015。步骤015.针对P1k、P2k、P3k中验证样点集合中各个样点位置所对应的预测土壤质地颗粒含量,通过如下公式,按P1k、P2k、P3k分别进行精度检测,获得P1k、P2k、P3k分别所对应的精度结果R1k、R2k、R3k,然后进入步骤016。其中,R分别指代了R1k、R2k、R3k,n={1,…,N},N表示对应验证样点集合中样本点位置的数量,xn表示样本点位置所对应的观测土壤质地颗粒含量,表示对应验证样点集合中所有样本点位置所对应观测土壤质地颗粒含量的平均值,表示样本点位置所对应的预测土壤质地颗粒含量,表示对应验证样点集合中所有样本点位置所对应预测土壤质地颗粒含量的平均值。步骤016.判断k是否等于预设循环次数K,是则获得{R11、…、R1k、…、R1K}、{R21、…、R2k、…、R2K}、{R31、…、R3k、…、R3K}三个集合,并进入步骤017;否则用k的值加1的结果针对k进行赋值,并返回步骤003。步骤017.分别获得{R11、…、R1k、…、R1K}、{R21、…、R2k、…、R2K}、{R31、…、R3k、…、R3K}三个集合的平均值然后进入步骤018。步骤018.判断之间的大小关系,若或则基于步骤002至步骤011中的{Por,Pek}集合,通过其各个样本点位置的环境变量数据、观测土壤质地颗粒含量,获得定量关系,再采用该定量关系针对目标土壤区域进行土壤质地颗粒含量预测;若之间满足其它大小关系,则基于全局样点集合Po,通过其各个样本点位置的环境变量数据、观测土壤质地颗粒含量,获得定量关系,再采用该定量关系针对目标土壤区域进行土壤质地颗粒含量预测,如图5所示。本发明所设计土壤质地颗粒含量预测方法,在常规数字土壤制图技术过程中考虑了外推局部土壤-景观模型,以及外推法适宜性评价、独立验证点集合的构建与使用,避免外推法可能引入的潜在不确定性,有效地缓解了部分区域土壤样点数量较少而导致预测精度低的技术瓶颈;本方法具有良好的可行性与移植性,动态验证点集合可望取得较为理想的计算精度。上面结合附图对本发明的实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1