一种基于激光诱导击穿光谱和线性判别的矿物识别方法与流程
本发明属于地质勘探领域,具体涉及一种基于激光诱导击穿光谱和线性判别的矿物识别方法。
背景技术:
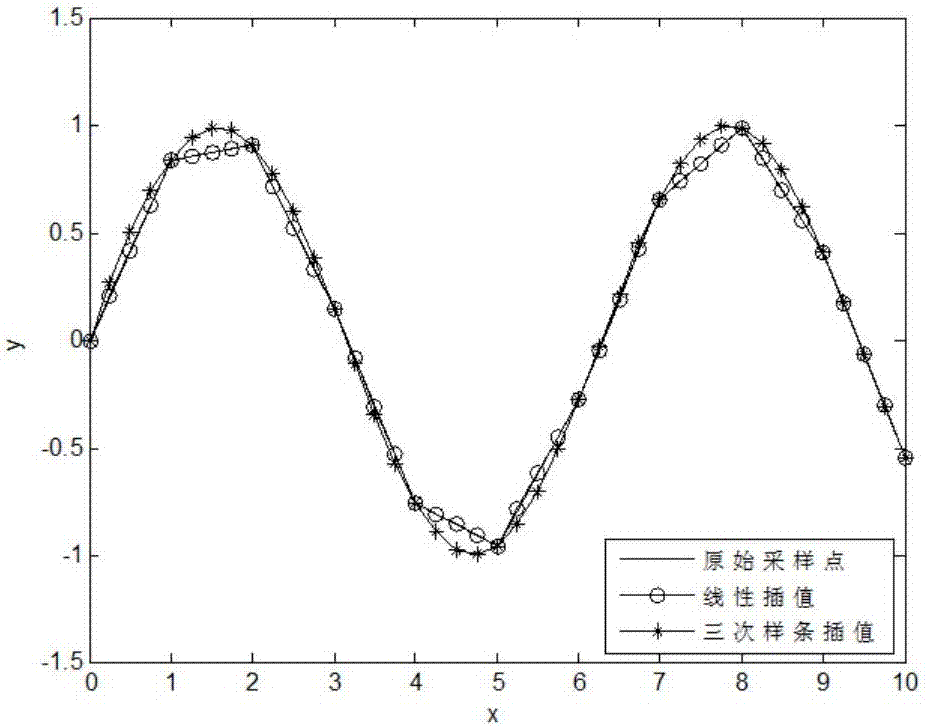
:传统矿物识别一般通过观察矿物的物理性质(硬度、颜色、纹路、光泽、裂缝方向和特征、形态、磁性、与盐酸作用等现象),辅助偏振光人工识别矿物切片的光学性质等方法,但这些检测需要分析人员具有丰富的知识和经验。同时由于人的主观性,很难保证识别结果的准确性。因此更多的精密分析技术被用于细小的矿物或具有相似物理性质的矿物识别。常用岩石矿物微区特征信息获取的主要仪器方法有微x射线衍射分析(xrd)、电子探针分析(empa)、扫描电子显微分析(sem)、激光诱导-电感耦合等离子体质谱分析(la-icp-ms)、二次离子质谱分析(sims)等。这些技术都提供了独特、有用的信息,但这些技术需要经验比较丰富人员操作,有的定量分析精度不高或对大区域内的元素分析效果不好,有的仪器设备昂贵,前处理时间长,对样品具有破坏性。目前对于矿物的快速识别方法主要是指纹区识别法,该方法通过选取重要峰位点或一段感兴趣区域获得样品的定性结果,该方法需要准确判断指纹区,同时每一种矿物样品的指纹区又不尽相同,这给实际操作方法带来了困难。技术实现要素:本发明要解决的技术问题是提供一种基于激光诱导击穿光谱(laserinducedbreakdownspectroscopy:libs)和线性判别的矿物识别方法,该方法通过采集一定数量的分析样品构成训练样本,通过统计模式算法获取样品内在空间结构 信息,实现矿物样品的快速、准确分析和区别。为解决上述技术问题,本发明一种基于激光诱导击穿光谱和线性判别的矿物识别方法,包括以下步骤:步骤一、基于libs光学系统进行数据采集;步骤二、对采集的数据,通过三次样条插值算法修正各种谱图波长,使其一致;步骤三、对平滑后的光谱数据进行标准正态变量校正,得到标准正态变量校准后的光谱;步骤四、利用线性判别分析方法对经过标准正态变量校正后的光谱数据进行特征提取和聚类分析。所述的步骤三中,进行标准正态变量校正利用如下公式:其中xi为第i个矿物样品光谱变量的平均值,k=1,2,...,m,m为波长点数,xi,snv为经过标准正态变量校准后的光谱,xi,k为第i个样品中,第k个波长处的计数。本发明的有益技术效果在于:本发明是一种简单、快捷的光谱测试和分析手段;本发明可实现实时测量和同时对多种矿物样品进行分析;本发明无须烦琐的样品前处理过程;本发明对样品尺寸、形状及物理性质要求不严格,可分析不规则样品;本发明具有高灵敏度与高分辨率,线性判别分析算法可以有效提高识别精度。本发明通过搭建的libs系统对五类贺兰石样品进行光谱采集,利用三次样条插值及标准正态变量校正等方法对光谱数据进行预处理,通过线性判别分析 方法对上述采集数据进行聚类分析,实现了五类贺兰石样品的快速、准确识别。说明了基于激光诱导击穿光谱技术结合线性判别分析方法用于矿物识别的有效性和正确性。附图说明图1为:光谱仪获取贺兰石信号;图2为:各种插值方法比较;图3为:技术方案流程图;图4为:125444样本均值谱图;图5为:125445样本均值谱图;图6为:125446样本均值谱图;图7为:125447样本均值谱图;图8为:125448样本均值谱图;图9为:snv后五类样本均值谱图;图10为:五类贺兰石样品lda聚类分析(2d表示);图11为:五类贺兰石样品测试结果。具体实施方式下面结合附图和实施例对本发明作进一步详细说明。本发明一种基于激光诱导击穿光谱和线性判别的矿物识别方法,包括以下步骤:步骤一、基于libs光学系统进行数据采集,采用国产激光器搭建一套微区特征libs快速识别技术实验系统,该系统的组成为光谱仪探头,8mm聚焦透镜,样品池,激光器的组成为:紫外固体激光器(nd-yag,有效输出能量为8mj,光导纤维ccd光谱仪:avaspec-2048ft-4-dt四通道)以及控制计算 机一台。为了产生击穿等离子体光谱,相应参数调节可以为:●充电电压:600v-900v●调q延时:130us–160us●放电频率:7hz-10hz●输出能量:3mj-5mj●旋转角度:80%-100%该调q高功率脉冲激光器的工作波长选择为1064nm,脉冲激光通过随后的光束衰减器衰减以及倍频分析器等将激光光束汇聚至待测样品表面,由高功率激光击穿合样品面产生的等离子体光谱向四周出射后,利用一根光纤探头探测,将光谱信号输人至光谱仪中;步骤二、对光谱仪采集的数据,为了使采集的不同类别谱图有相同波长(247nm–757nm),通过三次样条插值算法修正各种谱图波长,使其一致;三次样条插值定义:函数s(x)∈c2[a,b](二阶连续可导),并且在每个小区间[xj,xj+1]上是三次多项式,其中a=x0<x1<...<xn=b是给定节点,则称s(x)是节点x0,x1,...,xn上的三次样条函数。若在节点xj上给定函数值yj=f(xj),并成立yj=s(xj),其中j=0,1,2,...,n,则称s(x)为三次样条插值函数。实际计算时还需要引入边界条件才能完成计算。边界通常有自然边界(边界点的二阶导为0),夹持边界(边界点导数给定),非扭结边界(使两端点的三阶导与这两端点的邻近点的三阶导相等)。在下面算法中,我们选用非扭结边界条件。三次样条插值与其它插值方法比较见图2所示:应用三次样条插值获得的信号更加平滑,便于后续矿物样品识别分析;步骤三、为了校正矿物样品因颗粒散射而引起的光谱能量误差,我们对平滑后的光谱数据进行标准正态变量校正;该方法假设光谱中各波长点的计数满 足正态分布,利用这一假设对每条光谱进行校正,即从原光谱中减去该条光谱的平均值后,再除以标准偏差:其中xi为第i个矿物样品光谱变量的平均值,k=1,2,...,m,m为波长点数,xi,snv为经过标准正态变量校准后的光谱,xi,k为第i个样品中,第k个波长处的计数;步骤四、最后基于统计模式识别策略,利用线性判别分析(lineardiscriminateanalysis:lda)方法对经过标准正态变量校正后的光谱数据进行特征提取和聚类分析;lda的基本思想:通过寻找一个投影方向w(线性变换,线性组合),将高维问题降低到低维问题来解决,并且要求变换后的低维数据具有如下性质:同类样本尽可能聚集在一起,不同类的样本尽可能地远,其基本原理如下:假设训练样本集数据包含两类样本:xi,i=1,2,其中每一类中含有ni个样本,计算各类样本均值向量mi:计算矿物样本类内离散度矩阵si,i=1,2和总类内离散度矩阵ss=s1+s2计算样本类间离散度矩阵sbsb=(m1-m2)(m1-m2)t在投影后的低维空间中,各类样本均值mi′,样本类内离散度和总类内离散 度为si′=wtsiw,i=1,2s′=wtsw样本类间离散度为sb′=wtsbwlda要求原始矿物样本投影后,不同类样本尽可能离得远,同类样本尽可能聚集在一起,即样本类间离散度越大越好,根据这个性质确定fisher准则函数根据该准则函数取得最大值,可求出w=s-1(m1-m2)。通过lda方法,使采集的不同类样本可以有效区分开。通过本方法对五类贺兰石矿物样品进行快速识别。该五类样本分别标记为“125444”、“125445”、“125446”、“125447”、“125448”。对待识别五类贺兰石进行光谱数据预处理(三次样条插值平滑及标准正态变量校正)、特征提取、自动聚类等实现矿物的智能、自动分析。利用实验室搭建的libs系统采集五类贺兰石样品,其统计特征见表1。表1实验样本统计样本类型样本性质(个数*特征数)125444105*488125445103*488125446109*488125447106*488125448103*488五类贺兰石样本均值谱图如图4--图8所示。从上图可以看出,由于仪器能量变化以及样品散射的影响,五类样本光谱计数最大值相差较大(从1400到14000)。为了克服该变化对分析结果影响,对原始谱图进行snv校正,结果如图9 所示:通过snv预处理,五类光谱均值能量差别有所减小。接下来通过lda算法对预处理后的五类光谱数据进行聚类分析,如图10所示,从该图中可以看出:经过lda聚类后,五类贺兰石区分效果明显,其中125448类样品f2特征在0.45到0.6之间,与其它四类样品明显相差比较大。125444类样品f2特征在0到0.1之间,该类样品与125445(f2<0)、125446(f2<0)、125447(f2<0)可以分开。125447(f1<0)、125445(0.05<f1<0.2)、125446(0.3<f1<0.4)之间可以通过f1特征完全分开。为了实现对未知贺兰石样品类型的识别,我们利用libs方法采集测试样品光谱,采取上述相同的光谱预处理方法,分析结果如图11所示,从该图中可以看出,每一类测试样本都基本落入训练样本区域(如图11中圈),实现了五类贺兰石样品快速鉴别。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1