一种基于TegraX1雷达数据的无人车障碍物检测方法与流程
本发明属于无人驾驶领域,尤其涉及一种基于Tegra X1雷达数据的无人车障碍物检测方法。
背景技术:
近年来,随着传感器技术、控制系统、人工智能的不断发展,地面移动机器人取得了很大的进步。在现实动态环境中,自主机器人在环境感知中能够稳定准确的检测障碍物和识别障碍物类型,对于路径规划建立运动模型可以起到很大帮助,从而做出智能决策行为。通常自主机器人在环境中主要有两大类动态物体:车辆和行人。对于车辆,在交通中是主要的交互对象,速度比较快,需要保持一定的安全距离,在交通规则允许的情况下需要选择是跟车还是超车.对于行人,由于行人的运动具有很大的随意性,需要保持较大的横向距离,以确保行人安全。
利用安装在智能车上的多传感器系统,比如摄像机、激光、毫米波雷达、GPS、惯导等获取车辆前方的障碍物信息及本车的位置和姿态信息,然后在车载计算机上根据己建立的驾驶行为专家系统对这些信息进行处理,当本车与前方障碍物的相对距离小于安全距离时,有碰撞危险发生,则计算机会直接发出相应指令控制汽车减速甚至是刹车等动作。同时,通过传感器系统,智能车也能够识别道路中的各种交通标志牌,车道边缘线等,并利用决策层的指令实现超车,汇入车流等本车动作。因此,智能车大大提高了交通系统的安全性和效率。在可使用的传感器中,Velodyne激光雷达由于其高精度测距、探测范围大、抗干扰能力强等优点,近年来在移动机器人上的应用越来越广泛。但由于该雷达数据过大,处理算法的运算量极大,所以实时性较差,因此在复杂环境下,并不能及时将障碍物信息发送到决策。
技术实现要素:
针对激光雷达工程应用中实时性需求问题,本发明提供一种基于Tegra X1雷达数据的无人车障碍物检测加速方法。
本发明的基本思想为根据Tegra X1计算平台的特点,采用CPU+GPU协调工作的方法来进行雷达数据的加速处理。本发明结合激光雷达在智能车实际应用情况,将道路环境分为简单道路环境和复杂道路环境。并在此基础上,针对不同情况,对相应的算法进行优化,实现雷达数据处理加速,提高了智能车雷达数据处理的实时性。
为现实上述目的,本发明采用如下的技术方案:
一种基于Tegra X1雷达数据的无人车障碍物检测方法,包括以下步骤:
步骤1、采用velodyne激光雷达作为传感器采集环境信息,通过NVIDIA Tegra X1移动处理器进行三维雷达数据转换;
步骤2、基于栅格的障碍物检测,采用GPU处理栅格数据,包括三个步骤:
将三维数据点投影到栅格地图上;
将所有栅格相对高度大于某个阈值的栅格设定为障碍物点;
滤去所有因栅格内存在悬空点而导致属性为障碍物的栅格。
作为优选,采用向量化的方法将雷达点云数据投影到栅格地图上,通过三维雷达数据转换过程中,将转换后的点云数据以float4的数据格式保存,以warp为处理单位并行获取障碍信息。
本发明的方法与现有技术相比,有效的提高无人车障碍物检测的实时性,有如下特点:
1、根据Tegra X1 arm和GPU之间访存带宽,我们利用pinned memory来降低了CPU与GPU之间的传输消耗。
2、在简单道路环境的障碍物检测上,我们采用一个线程处理一个栅格的方法来处理雷达数据,对比工控机的雷达处理性能有了6~7倍的提升。
3、在复杂道路环境的障碍物检测上,我们采用一个线程束处理一个栅格的方法来处理雷达数据,对比工控机的雷达处理性能有了5~6倍的提升。
附图说明
图1为本发明无人车障碍物检测方法的流程图;
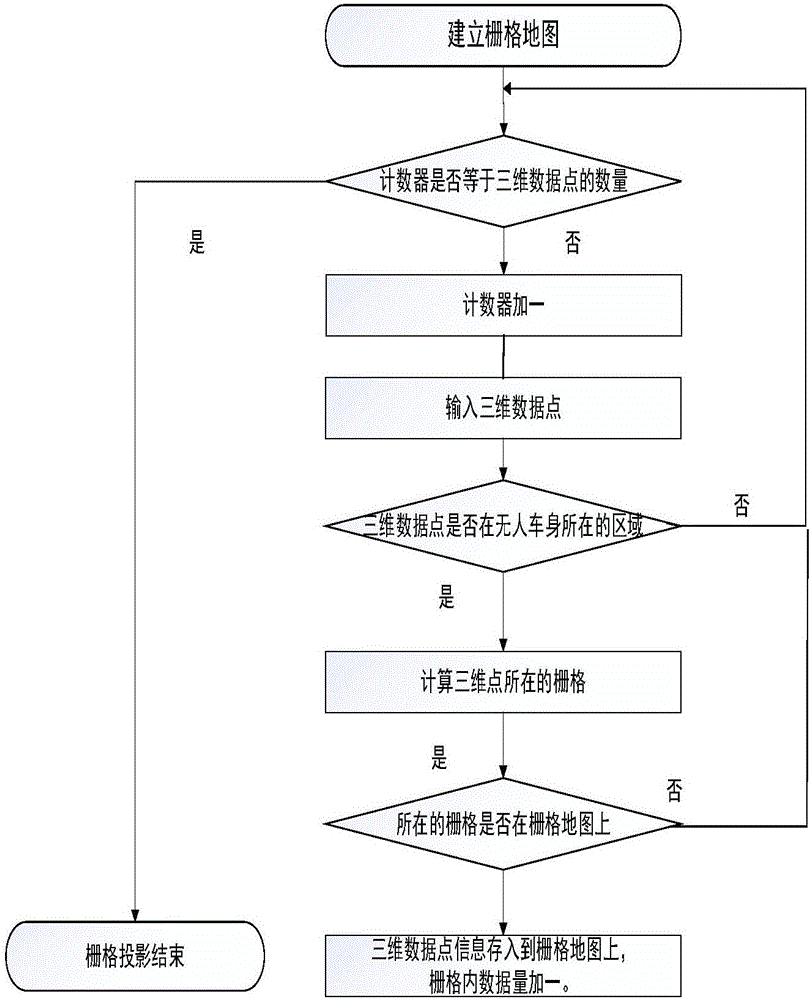
图2为栅格投影流程图;
图3为pinned memory和pageable memory带宽对比图;
图4为栅格属性判断流程图;
图5为thread处理栅格流程图;
图6为warp处理栅格流程图。
具体实施方式
本发明提供一种基于Tegra X1雷达数据的无人车障碍物检测方法,采用velodyne激光雷达作为传感器采集环境信息,搭载NVIDIA Tegra X1移动处理器,实现无人车障碍物检测。为更进一步说明本发明在技术内容,创新点效果好,以下结合实施方式并配合附图详细说明。
如图1所示,本发明方法分为两个步骤:1、三维雷达数据转换2、障碍物检测
由于三维雷达数据转换过程中,拥有着较多的复杂逻辑处理和事务管理,因此该过程不适合放入GPU中进行运算。因此本发明通过使用NVIDIA Tegra X1 arm处理器来处理该过程。
由于雷达点云数据量非常大(约130万个点/秒),不太适合直接在原始数据上进行处理。因此采用在国内外无人自主车系统中广泛采用的栅格处理方法来处理雷达点云数据。
基于栅格的障碍物检测分为三个步骤:
1、栅格投影
2、栅格属性判断
3、栅格滤波
栅格投影是将三维数据点投影到栅格地图上,其具体算法流程如图2所示。本发明采用向量化的方法将雷达点云数据投影到栅格地图上。通过三维雷达数据转换过程中,将转换后的点云数据以float4的数据格式保存。从而可以通过单指令多数据的方法将雷达点云数据投影到栅格地图上,提高arm处理器的处理性能。通过分析栅格数据,可知栅格之间毫无依赖关系,即有良好的并行性,因此采用GPU处理栅格数据。
在写内核函数之前,需要考虑GPU与CPU之间的传输效率的问题。host内存分为pageable memory和pinned memory两种。pageable memory是通过操作系统API(malloc(),new())分配的存储器空间;pinned memory始终存在于物理内存中,不会被分配到低速的虚拟内存中,能够通过DMA加速与设备端进行通信。相比于pageable memory,在pinned memory上主机端-设备端的数据传输带宽高。如图3所示,在Tegra X1上,传输32MB的数据,在pinned memory上GPU与CPU的传输是pageable memory上GPU与CPU的传输的5~6倍。而且Tegra X1还支持zero-copy功能,通过该方法将主机端内存映射到设备地址空间,从GPU直接访问,省掉主存与显存间进行数据拷贝的工作。因此,本发明与传统的方法所不同的是,我们结合Tegra X1的特性,将栅格地图建立在pinned memory上,来降低传输消耗。
在完成栅格投影之后,需要进行的是栅格属性判断、栅格滤波两个步骤。栅格属性判断是将所有栅格现对高度(栅格最高点减去最低点)大于某个阈值的栅格设定为障碍物点。其具体算法流程如图4所示。栅格滤波是滤去所有因栅格内存在悬空点而导致属性为障碍物的栅格。传统的方法是先完成所有栅格完成属性判断后,再进行栅格滤波的任务。本发明对其进行了改进,去掉了传统方法中存在的排序过程,将其改为求极值的问题。其次本发明将采用的是将栅格判断和栅格滤波合并为一项任务,在结合GPU运算的特点,使得栅格不需要等待所以栅格都完成栅格判断后再进行栅格滤波,从而提高处理性能。
GPU采用SIMT(Signal Instruction Multiple Thread,单指令多数据)编程模型,其调度和执行的基本单位是warp。其最终执行时间由执行时间最长的线程决定。因此本发明将道路环境分为两种即简单道路环境和复杂道路环境。
在简单的道路环境中,由于道路障碍物数量少,所以三维点投影在栅格地图的个数比较均衡。所以当采用一个线程处理一个栅格的方法来处理栅格数据,warp内线程的负载较为均衡,处理性能较高。其次本发明在求极值的过程中,通过减少条件分支,来减少动态指令,从而提高处理性能。使用?:语句代替if...else...语句是减少动态指令的主要方式。其具体算法流程如图5所示。在该道路环境上,本发明的处理方法对比工控机的雷达处理方法的性能有了6~7倍的提升。
在复杂的道路环境中,由于障碍物数量多,所以三维点投影在栅格地图的个数极度不均衡,因此当采用一个线程处理一个栅格的方法来处理栅格数据,warp内线程的负载极度不均衡,处理性能不高。针对这种情况,本发明采用了粗粒度并行的方法,选择warp作为基本并行执行单元和任务分配单位即一个warp处理一个栅格。warp内的所有线程将协同完成分配给warp的计算任务。在求栅格的极值时,本发明通过使用Shuffle技术,取代一个线程处理一个栅格所需的单指令序列,增加有效带宽和减少延迟。其次将处理完的数据放入共享内存中,用一个warp来存放结果,能有效的减少对全局内存的访问。其具体算法流程如图6所示。在该道路环境上,本发明的处理方法对比工控机的雷达处理方法的性能有了6~7倍的提升。
本发明通过CPU与GPU的协同工作实现了雷达数据在NVIDIA Tegra TX1移动处理器上的加速处理。算法加速的过程需要根据算法特点,设计实现到底层硬件架构特征的高效映射。Tegra X1整合了四颗Cortex-A57核心和四颗Cortex-A53核心,同时Tegra X1拥有256采用Maxwell架构的GPU,这就需要在程序优化过程中,不仅要考虑算法特性,而且还要考虑底层硬件架构的特征,最终还需要完成这两种特征的高效映射,才能实现基于Tegra X1雷达数据处理的加速。
- 还没有人留言评论。精彩留言会获得点赞!