一种物质含量分析方法与流程
本发明涉及物质成分、含量的定量分析方法的技术领域,具体地说是一种利用样本中的多种化学信号建立定量分析模型进行分析的方法。
背景技术:
物质的定量分析是研究物质性质的重要手段。通常是单独利用色谱或光谱建立偏最小二乘回归定量分析模型。但是仅仅利用一种化学信号并不能完整的反映物质的特性,因此偏最小二乘回归定量分析模型的误差就较大。
但是传统的偏最小二乘模型及其改进的方法包括方差约束的偏最小二乘,正交信号校正偏最小二乘,只能针对单独信号进行建模,并不能有效、综合地利用样本的多种化学信息建立模型。针对上述问题我们提出一种新的偏最小二乘回归模型对样本进行定量分析。不同类型的化学信号都是从同一个样本获取的,因此具有内在的相关性。比如对于液体物质由于有水的存在中红外3300cm-1就会出现吸收峰,气相色谱质谱中也会检测到水的存在。该模型利用同一个样本的不同类型的化学信号进行建模,提高了定量分析的精度。
中国专利申请号为CN200710307532.X,该发明提供了一种物质定量分析方法,包括以下步骤,用质谱分析装置对至少两份标定物质进行分析已得到分析结果,每一标定物质含有第一物质成分和第二物质成分,每一标定物质所含有的第一物质成分和第二物质成分的浓度是已知的,以所述质谱分析装置分析含有第一物质成分和第二物质成分的被测物质,该被测物质中第一物质成分的浓度为已知,然后根据被测物质中第一物质成分的浓度及所述分析结果计算出该被测物质中第二物质成分的浓度。
技术实现要素:
本发明的目的是:建立一种能综合利用各种化学信号的模型;相比以往的模型定量分析精度更高。
为了实现本发明以上发明目的,本发明是通过以下技术方案实现的:
一种物质含量分析方法,包括以下步骤:
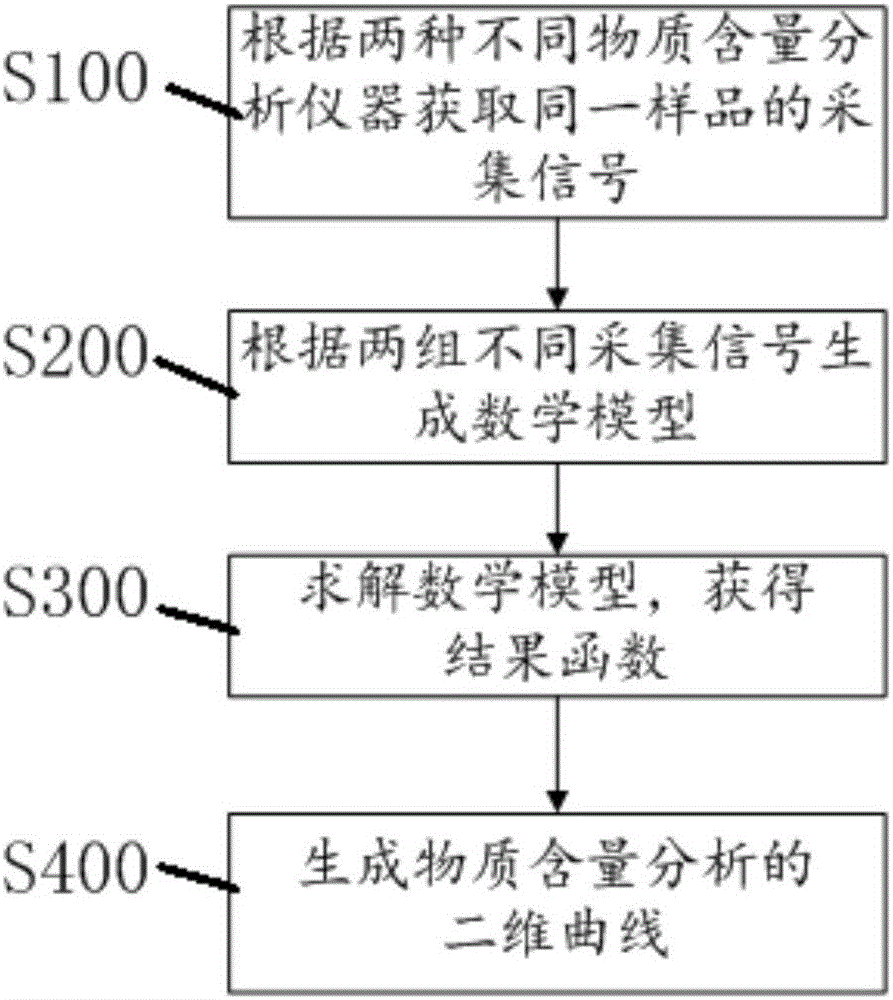
S100:根据两种不同物质含量分析仪器获取同一样品的采集信号;
S200:根据两组不同所述采集信号生成数学模型:
arg max<Y,α1X1w1+α2X2w2>+λ<X1w1,X2w2>
s.t||w1||2=1,||w2||2=1,
其中,符号“<·>”表示求内积运算,λ是正则化常数,符号s.t表示约束条件,||·||2表示求2范数;
S300:求解所述数学模型,获得结果函数:
β=(α1X1W1+α2X2W2)+Y,其中,β为回归系数,(.)+表示广义逆。
进一步,所述的物质含量分析方法,所述S100步骤包括如下步骤:
S101:第一物质含量分析仪器对所述样品的n个样本采集n个所述信号:每个所述信号的长度是p1,组成n×p1矩阵X1;
S102:第二物质含量分析仪器对所述样品的n个所述样本采集n个所述信号:每个所述信号的长度是p1,组成n×p2矩阵X2;
S103:每个所述样本对应的物质浓度数值组成n×1矩阵Y。
进一步,所述的物质含量分析方法,所述S200步骤包括如下步骤:
S201:引入方向向量w1、w2,使得w1、w2分别能提取到所述矩阵X1、X2的最大信息,即X1、X2在w1、w2上的投影t1=X1w1、t2=X2w2方差最大;
S202:引入线性组合的系数α1,α2,使得α1X1w1+α2X2w2与Y的相关性达到最大;
S203:同时,使得X1w1,X2w2之间的相关性达到最大。
进一步,所述的物质含量分析方法,所述S300步骤包括如下步骤:
S310:对所述数学模型,根据拉格朗日乘数法得拉格朗日函数为:
其中,α1,α2是线性组合的系数,λ是正则化常数,参数γ1,γ2又称作拉格朗日乘子;
其中,分别表示对w1,w2,γ1,γ2求偏导数,式③和式④表示w1,w2的长度归一化为1。
进一步,所述的物质含量分析方法,所述S310步骤包括如下步骤:
S301:初始化迭代次数k,
其中,w1和w2上标(0)表示w1和w2初始值,以此类推表示第一次迭代值,表示第二次迭代值,....表示第k次迭代值;
S302:利用w2第i次迭代的值和式①更新得到利用和式②更新得到计算将和的长度归一化到1,迭代k次,得到最终的w1,w2;
S303:更新X1,X2分别为
其中,t1=X1w1,t2=X2w2,
再进一步,所述的物质含量分析方法,所述S400步骤包括步骤S401:
重复S301、S302、S303,h次,得到的h个向量w1,w2,组成矩阵W1,W2。
进一步,所述的物质含量分析方法,所述结果函数为α1X1W1+α2X2W2与Y之间的最小二乘法回归模型。
进一步,所述的物质含量分析方法,所述S300步骤包括如下步骤:S400:生成所述物质含量分析的二维曲线,其中,纵坐标为“误差”,横坐标为向量w1或w2的个数。
进一步,所述的物质含量分析方法,所述物质含量分析仪器为红外光谱仪、光谱分析仪、气相色谱质谱仪、液相色谱质谱仪或者核磁共振谱仪。
进一步,所述的物质含量分析方法,所述样品为固体、液体或者气体。
本发明与国内外现有同类产品的相比,其有益效果在于以下几点:
1、该模型能综合利用多种化学信号的模型,而传统的偏最小二乘法回归却不具备这种性能;
2、相比以往的模型定量分析精度更高;
3、计算复杂度较低。
附图说明
下面结合附图和具体实施方式对本发明作进一步详细说明:
图1为本发明第一实施例模型原理示意图;
图2为本发明第一实施例流程示意图;
图3为本发明第三实施例药片活性物质含量分析结果示意图(横坐标表示向量w1或w2的个数);
图4为本发明第三实施例红酒乙酸乙酯含量分析结果示意图(横坐标表示向量w1或w2的个数);
图5为本发明第三实施例红酒乙醇含量分析结果示意图(横坐标表示向量w1或w2的个数)。
具体实施方式
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,以下说明和附图对于本发明是示例性的,并且不应被理解为限制本发明。以下说明描述了众多具体细节以方便对本发明理解。然而,在某些实例中,熟知的或常规的细节并未说明,以满足说明书简洁的要求。
在本申请一个典型的配置中,用于模型计算和图形曲线生成的运算终端包括一个或多个处理器(CPU)、输入/输出接口、网络接口和内存。
本发明中的用于模型计算和图形曲线生成的运算终端包括处理器,含单核处理器或多核处理器。处理器也可称为一个或多个微处理器、中央处理单元(CPU)等等。更具体地,处理器可为复杂的指令集计算(CISC)微处理器、精简指令集计算(RISC)微处理器、超长指令字(VLIW)微处理器、实现其他指令集的处理器,或实现指令集组合的处理器。处理器还可为一个或多个专用处理器,诸如专用集成电路(ASIC)、现场可编程门阵列(FPGA)、数字信号处理器(DSP)、网络处理器、图形处理器、网络处理器、通信处理器、密码处理器、协处理器、嵌入式处理器、或能够处理指令的任何其他类型的逻辑部件。处理器用于执行本发明所讨论的操作和步骤的指令。
本发明中的用于模型计算和图形曲线生成的运算终端包括存储器,可包括一个或多个易失性存储设备,如随机存取存储器(RAM)、动态RAM(DRAM)、同步DRAM(SDRAM)、静态RAM(SRAM)或其他类型的存储设备。存储器可存储包括由处理器或任何其他设备执行的指令序列的信息。例如,多种操作系统、设备驱动程序、固件(例如,输入输出基本系统或BIOS)和/或应用程序的可执行代码和/或数据可被加载在存储器中并且由处理器执行。
本发明中的用于模型计算和图形曲线生成的运算终端的操作系统可为任何类型的操作系统,例如微软公司的Windows、Windows Phone,苹果公司IOS,谷歌公司的Android,以及Linux、Unix操作系统或其他实时或嵌入式操作系统诸如VxWorks等。
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,以下说明和附图对于本发明是示例性的,并且不应被理解为限制本发明。以下说明描述了众多具体细节以方便对本发明理解。然而,在某些实例中,熟知的或常规的细节并未说明,以满足说明书简洁的要求。本发明的具体判断系统及方法参见下述实施例:
第一实施例
如图1第一实施例流程示意图所示:
一种物质含量分析方法,包括以下步骤:
S100:根据两种不同物质含量分析仪器获取同一样品的采集信号;
S200:根据两组不同所述采集信号生成数学模型:
arg max<Y,α1X1w1+α2X2w2+λ<X1w1,X2w2>
s.t||w1||2=1,||w2||2=1,
其中,符号“<·>”表示求内积运算,λ是正则化常数,符号s.t表示约束条件,||·||2表示求2范数;
S300:求解所述数学模型,获得结果函数:
β=(α1X1W1+α2X2W2)+Y,其中,β为回归系数,(.)+表示广义逆。
优选地,所述的物质含量分析方法,所述S100步骤包括如下步骤:
S101:第一物质含量分析仪器对所述样品的n个样本采集n个所述信号:每个所述信号的长度是p1,组成n×p1矩阵X1;
S102:第二物质含量分析仪器对所述样品的n个所述样本采集n个所述信号:每个所述信号的长度是p1,组成n×p2矩阵X2;
S103:每个所述样本对应的物质浓度数值组成n×1矩阵Y。
优选地,所述的物质含量分析方法,所述S200步骤包括如下步骤:
S201:引入方向向量w1、w2,使得w1、w2分别能提取到所述矩阵X1、X2的最大信息,即X1、X2在w1、w2上的投影t1=X1w1、t2=X2w2方差最大;
S202:引入线性组合的系数α1,α2,使得α1X1w1+α2X2w2与Y的相关性达到最大;
S203:同时,使得X1w1,X2w2之间的相关性达到最大。
优选地,所述的物质含量分析方法,所述S300步骤包括如下步骤:
S310:对所述数学模型,根据拉格朗日乘数法有:
其中,α1,α2是线性组合的系数,λ是正则化常数,参数γ1,γ2又称作拉格朗日乘子;
其中,分别表示对w1,w2,γ1,γ2求偏导数,式③和式④表示w1,w2的长度归一化为1。
优选地,所述的物质含量分析方法,所述S310步骤包括如下步骤:
S301:初始化迭代次数k,
其中,w1和w2上标(0)表示w1和w2初始值,以此类推表示第一次迭代值,表示第二次迭代值,....表示第k次迭代值;
S302:利用w2第i次迭代的值和式①更新得到利用和式②更新得到计算将和的长度归一化到1,迭代k次,得到最终的w1,w2;
S303:更新X1,X2分别为
其中,t1=X1w1,t2=X2w2,
再进一步优选地,所述的物质含量分析方法,所述S300步骤包括步骤S320:
重复S301、S302、S303,h次,得到的h个向量w1,w2,组成矩阵W1,W2。
优选地,所述的物质含量分析方法,所述结果函数为α1X1W1+α2X2W2与Y之间的最小二乘法回归模型。
优选地,所述的物质含量分析方法,所述S300步骤后还有如下步骤:S400:生成所述物质含量分析的二维曲线,其中,纵坐标为“误差”,横坐标为向量w1或w2的个数。
进一步可选地,所述的物质含量分析方法,所述物质含量分析仪器为红外光谱仪、光谱分析仪、气相色谱质谱仪、液相色谱质谱仪或者核磁共振谱仪。
进一步可选地,所述的物质含量分析方法,所述样品为固体、液体或者气体。
第二实施
本实施例的实现步骤如下:
(1)用第一种仪器对n个样本采集信号得到其中上标1表示的是第一种仪器采集的信号。每一个信号的长度是p1,将组成大小为n×p1矩阵X1;用第二种仪器对n个样本采集信号得到其中上标2表示的是第二种仪器采集的信号。每一个信号的长度是p2,将组成大小为n×p2矩阵X2;每个样本都对应的物质浓度数值组成一个n×1矩阵的矩阵Y;
(2)寻找方向向量w1,w2使得w1,w2分别能提取到X1,X2的最大信息,即X1,X2在w1,w2上的投影t1=X1w1,t2=X2w2方差最大;
(3)为了定量分析的需要α1X1w1+α2X2w2与u的相关性达到最大,其中α1,α2是线性组合的系数;
(4)同时X1w1,X2w2之的相关性达到最大;
(5)上述(2)-(4)步骤归结起来就是求解如下模型:
arg max<Y,α1X1w1+α2X2w2>+λ<X1w1,X2w2>
s.t||w1||2=1,||w2||2=1
其中符号<·>表示求内积运算,λ是正则化常数,符号s.t表示约束条件,||·||2表示求2范数。
(6)求解步骤(5)中所表示的模型,具体过程是这样的,根据拉格朗日乘数法有:
其中α1,α2是线性组合的系数,λ是正则化常数,参数γ1,γ2又称作拉格朗日乘子。
其中,分别表示对w1,w2,γ1,γ2求偏导数,式③和式④表示w1,w2的长度归一化为1。
(a)初始化迭代次数k,其中w1和w2上标(0)表示w1和w2初始值,以此类推表示第一次迭代值,表示第二次迭代值,....表示第k次迭代值.
(b)利用w2第i次迭代的值和式(1)更新得到利用和式(2)更新得到计算将和的长度归一化到1,迭代k次,得到最终的w1,w2
(c)t1=X1w1,t2=X2w2,更新X1,X2分别为
(a)-(c)重复h次,将h次得到的各h个向量w1,w2组成矩阵W1,W2
(d)建立α1X1W1+α2X2W2与Y之间的最小二乘回归模型,定义β为回归系数,β=(α1X1W1+α2X2W2)+Y,(.)+表示广义逆;
对新的样本X1test,X2test,预测的结果R为:
R=(α1X1testW1+α2X2testW2)(α1X1W1+α2X2W2)+Y
第三实施例
基于上述分析方法,三次具体实验分析对比结果如下:
1、药片光谱分析,数据集由320个近红外光谱和120个拉曼光谱组成,分析指标是活性成分的含量,选出116个具有相同活性成分的近红外光谱和拉曼光谱,设116个近红外光谱组成的矩阵为X1,116个拉曼光谱组成的矩阵为X2,参数α1=0.5,α2=100,λ1=10,γ1=100,γ2=150,
k=20,h=15对比本文方法和其他三种方法的误差如图3为本发明第三实施例药片活性物质含量分析结果示意图所示,从图3中可以看出,本文提供的具体算法方案的误差最小。
2、红酒光谱分析,数据集由44个近红外光谱和44气相色谱组成,分析指标是乙酸乙酯的含量,设44个近红外光谱组成的矩阵为X1,44个气相色谱组成的矩阵为X2,参数α1=0.5,α2=100,λ1=10,γ1=100,γ2=150,k=20,h=15对比本文方法和其他三种方法的误差如图4为本发明第三实施例红酒乙酸乙酯含量分析结果示意图所示,从图4中可以看出,本文算法的误差最小。
3、数据集和参数和实验2中一样,本实验3分析乙醇含量,结果如图5为本发明第三实施例红酒乙醇含量分析结果示意图所示,从图5中可以看出,本文算法的误差最小。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化涵括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。此外,显然“包括”一词不排除其他单元或步骤,单数不排除复数。装置权利要求中陈述的多个单元或装置也可以由一个单元或装置通过软件或者硬件来实现。第一,第二等词语用来表示名称,而并不表示任何特定的顺序。
- 还没有人留言评论。精彩留言会获得点赞!