基于GPU的雷达前视成像方法与流程
本发明属于雷达成像
技术领域:
,尤其涉及一种基于gpu((graphicsprocessingunit,图形处理单元)的雷达前视成像方法,具体为在cuda(computeunifieddevicearchitecture,计算统一的设备体系结构)架构中实现雷达前视成像的并行设计,用于提高雷达前视成像效率,达到实时处理雷达回波数据的目的。
背景技术:
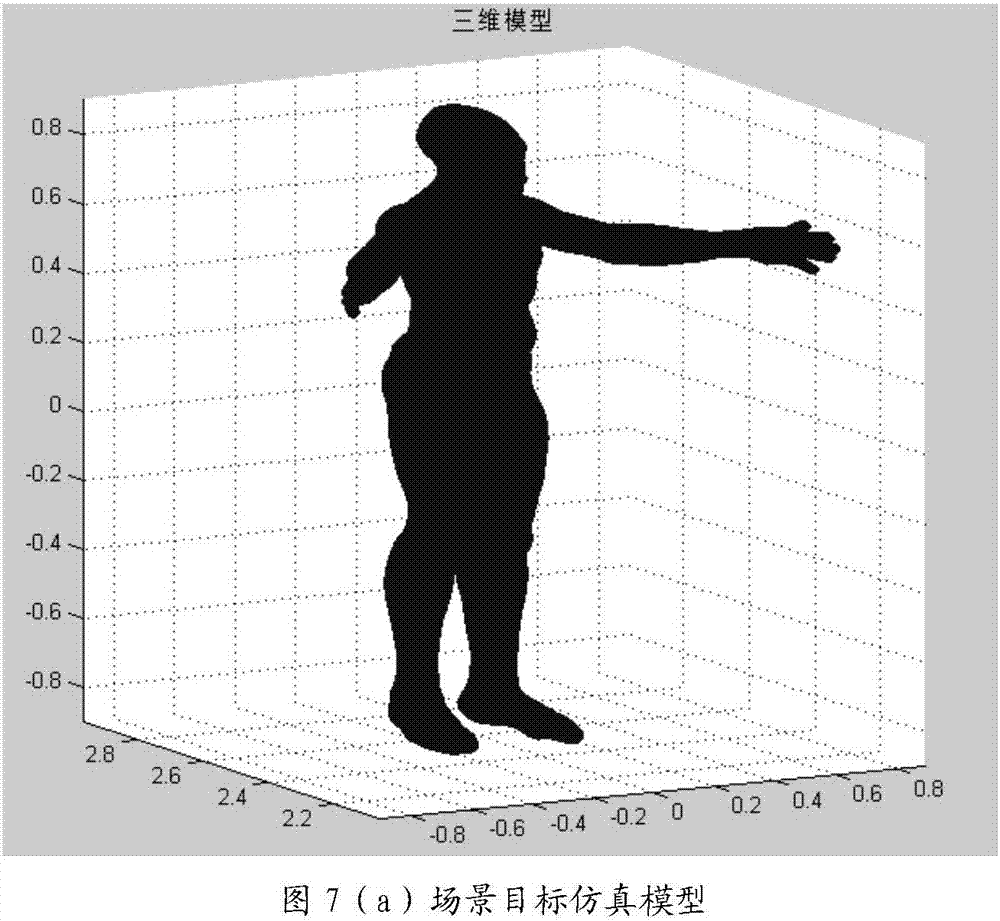
:雷达前视区域的三维场景具有分辨率高、数据多、场景维度大的特点,会增加信号估计的时间,同时压缩感知重构算法又包含大量的矩阵运算和迭代运算,计算复杂度高,仅采用传统的串行方式进行处理,存在运行时间过长问题,无法达到实时处理的要求;近年,gpu(图形处理器)从专业图形处理到科学计算的转型使gpu协处理器成为超级计算领域的新宠,其超强的浮点计算能力使其成为提高成像算法处理效率最有效方法之一。cuda是gpu广泛应用的一种编程模型,支持c/c++、fortan语言的扩展;提供了丰富的高性能数学函数库,比如cublas、cufft、cudnn等。技术实现要素:针对上述现有技术的缺点,本发明的目的在于提供一种基于gpu的雷达前视成像方法,以解决传统cpu(centralprocessingunit,中央处理单元)串行计算进行成像耗时较长且无法满足微波成像系统实时处理需求的问题。本发明实现的技术思路为:在对雷达前视区域三维场景目标进行压缩感知成像处理时,首先在cpu端按照串行的方式输入观测向量和超材料孔径天线的辐射场强度数据;利用超材料孔径天线产生频率捷变的辐射场对场景进行遍历,结合目标所处的场景位置先验信息,将成像场景按照一定的距离与方位分辨率进行离散网格化处理,再计算处在对应目标位置范围处所对应的测量矩阵;在gpu端构建基于压缩感知的雷达前视成像数学模型;采用cuda编程架构利用共轭梯度(cgsolve)算法对上述数学模型进行并行求解,估计出目标场景的散射系数分布。为达到上述目的,本发明采用如下技术方案予以实现。一种基于gpu的雷达前视成像方法,所述方法包括如下步骤:步骤1,在cpu端,获取接收天线对目标场景的观测向量;并对所述目标场景进行网格划分,获取目标所处网格范围对应的测量矩阵,建立从所述观测向量中恢复场景目标后向散射系数的优化模型;步骤2,在gpu端,从所述cpu端获取所述观测向量和所述测量矩阵,采用cuda架构并行实现从所述观测向量中恢复场景目标后向散射系数向量;步骤3,在cpu端,从所述gpu端获取所述场景目标后向散射系数向量,将所述场景目标后向散射系数向量对应到所述目标所处网格范围内,从而得到三维场景目标的估计模型,完成雷达前视成像。本发明与现有技术相比具有如下优点:1)本发明利用超材料孔径天线产生的频率捷变辐射场对场景进行观测,结合先进的压缩感知重构算法,实现对前视场景的三维计算成像。优点在于超材料孔径单通道成像雷达天线系统规模实现相对简单,可避免传统实孔径成像所需的复杂阵面天线设计;2)采用共轭梯度算法实现雷达前视三维场景目标成像,算法稳定性好,有利于大规模数据的成像处理;3)基于gpu平台,并行实现雷达前视场景目标成像处理,可以提高成像效率。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明实施例提供的基于gpu的雷达前视成像方法的并行过程示意图;图2为本发明实施例提供的共轭梯度算法的流程示意图;图3为本发明实施例提供的基于cuda编程的程序流程示意图;图4为本发明实施例提供的共享存储优化的2维矩阵转置示意图;图5为本发明实施例提供的共享存储优化的矩阵向量乘法示意图;图6为本发明实施例提供的向量转化为对角矩阵的示意图;图7为本发明实施例提供的估计模型与仿真模型对比示意图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本发明实施例提供一种基于gpu的雷达前视成像方法,如图1所示,所述方法包括如下步骤:步骤1,在cpu端,获取接收天线对目标场景的观测向量;并对所述目标场景进行网格划分,获取目标所处网格范围对应的测量矩阵,建立从所述观测向量中恢复场景目标后向散射系数的优化模型。步骤1具体为:(1a)在cpu端,采用串行方式读入接收天线对目标场景的观测向量y以及目标所处网格范围对应的测量矩阵dic,且:y=dic·x+n其中,y∈cm×1是接收天线对目标场景散射场的观测信号,dic∈cm×n是由天线的辐射方向图组成的测量矩阵,x∈cn×1是场景目标后向散射系数,n为测量噪声项;(1b)对所述场景目标后向散射系数建立如下优化模型:其中,为场景目标后向散射系数的估计值,为范数的平方,||·||1为范数,ρ为正则化参数;(1c)所述接收天线为超材料孔径天线;对所述目标场景进行网格划分,满足如下要求:场景水平方位分辨率δcrx=λr/2dx;垂直俯仰分辨率δcry=λr/2dy;距离分辨率δr=c/2b;其中,λ为雷达发射信号波长,r为目标距超材料孔径天线平面的距离,dx天线面板的水平长度,dy为天线面板的垂直长度,c为光速,b为雷达发射信号的带宽。步骤2,在gpu端,从所述cpu端获取所述观测向量和所述测量矩阵,采用cuda架构并行实现从所述观测向量中恢复场景目标后向散射系数向量。步骤2具体为:(2a)在gpu端进行初始化:分配显存空间,将从所述cpu端获取所述观测向量和所述测量矩阵,并将其复制到gpu显存上;(2b)在gpu端,设计复数矩阵共轭转置的内核函数,实现复数矩阵共轭转置的并行实现,从而初始化场景目标后向散射系数的估计值xl=dich·y;l的初值为1,l≤l,符号(·)h表示复数矩阵的共轭转置;(2c)在gpu端,设计矩阵与向量相乘的内核函数,实现矩阵与向量相乘的并行实现,从而计算所述场景目标后向散射系数的估计值xl的共轭梯度其中,h(xl)为系数矩阵,且为对称正定矩阵;子步骤(2c)中,在gpu端,设计向量转化为对角阵的内核函数,实现向量对角化的并行实现,所述系数矩阵h(xl)的计算式表示为:h(xl)=2dich·dic+ρλ(xl)其中,λ(xl)为对角矩阵,且(2d)采用共轭梯度算法计算场景目标后向散射系数的估计值xl的残差值△xl+1,所述残差值△xl+1满足子步骤(2d)中,采用共轭梯度算法计算场景目标后向散射系数的估计值xl的残差值△xl+1,具体包括:(2d1)设置初始搜索点和允许误差ε,以及最大迭代步数k;(2d2)计算所述初始搜索点的梯度值(2d3)设置初始搜索方向p0=r0;(2d4)设置循环变量初值k=0,k∈(0,1,...,k-1);(a)计算搜索步长(b)在搜索点处沿着搜索方向pk进行一维搜索,得到精确搜索点(c)计算精确搜索点的梯度值rk+1=rk-αkh(xl)pk;(d)判断精确搜索点的梯度值以及循环变量是否满足如下条件:(rk+1≤ε)||(k>k);(e)若不满足,在所述精确搜索点的梯度值rk+1和搜索方向pk张成的正交锥中找到一个向量pk+1=rk+1+βkpk,使得向量pk+1与pk共轭,即(pk+1)th(xl)pk=0;其中,并令循环变量k的值加1,重复执行子步骤(a)至子步骤(d);若满足,则场景目标后向散射系数的估计值xl的残差值(2d5)输出场景目标后向散射系数的估计值xl的残差值(2e)计算所述残差值△xl+1与场景目标后向散射系数的估计值xl的二范数比值(2f)判断迭代次数l和二范数比值threshold是否满足如下条件:(l+1≤l)||(threshold>δ)若满足,则更新场景目标后向散射系数的估计值xl+1=xl-μ×△xl+1;且令的值加1,并重复执行子步骤(2c)至(2e);其中,δ为迭代阈值,μ为迭代步长,l为最大迭代次数;否则,得到场景目标后向散射系数的估计值作为从所述观测向量中恢复的场景目标后向散射系数向量。步骤3,在cpu端,从所述gpu端获取所述场景目标后向散射系数向量,将所述场景目标后向散射系数向量对应到所述目标所处网格范围内,从而得到三维场景目标的估计模型,完成雷达前视成像。为提高成像效率,本发明利用gpu的并行特性,采用cuda编程模型等技术手段实现压缩感知算法在gpu平台上并行实现。将成像算法并行化,首先需对cgsolve串行算法进行热点分析,找出算法耗时步骤。经分析可知,该成像算法的热点集中在两层循环迭代过程,而两层循环中的耗时步骤主要体现在内层循环。由于本发明中待估计的场景目标是三维模型,数据规模大,cgsolve算法包含大量迭代运算,在信号估计的外层循环过程中每次迭代均与上一次的计算结果息息相关,具有数据依赖性,如果根据热点分析仅将内层循环在gpu端执行,其它步骤在cpu端执行,需要将数据在内存(cpu)和显存(gpu)之间进行频繁传输,会耗用大量的时间进行数据交互,综上,本发明将重构算法的外层循环和内层循环均放在gpu实现,减少数据交互时间,进一步提升程序性能。共轭梯度算法包含大量的矩阵向量之间的运算,而cuda函数库提供了简单高效的常用函数,其中cublas库是一个基本的矩阵与向量的运算库,提供了与blas相似的接口,调用库函数,无需按照硬件特性设计复杂的内核函数就能获得很高的性能,因此本发明中以调用cublas库函数为主,设计编写cuda内核函数为辅,进行雷达前视场景目标成像并行算法的实现。上述步骤2中,主要采用cuda编程模型,结合cublas库函数和设计的内核函数实现了共轭梯度算法(共轭梯度算法流程图如图2所示)的并行编程,完成了压缩感知成像算法的并行化。cuda编程模型的程序流程如图3所示,主体包含以下五个步骤:1.gpu初始化,分配显存空间2.数据传输:将数据从主机复制到设备中3.线程分配、设计内核函数并调用,实现算法并行处理4.数据传输:将计算结果从设备拷贝回主机5.释放显存数据存储空间本发明中主要调用的cublas库函数有:cublaszaxpy(复数向量加法),cublaszcopy(复数向量复制),cublaszdotc(复数向量内积),cublaszscal(复数向量与常数的乘法)。虽然使用cublas函数可以使计算性能达到及优,但是针对表达式复杂的部分则不适合直接调用cublas函数。因此需对上述算法的一些步骤进行内核设计,其内核设计的性能好坏是并行化设计的关键所在,内核函数设计如下:矩阵转置并行实现:由于步骤(2b)需要计算矩阵转置,如果仅在cpu串行实现,时间算法复杂度较高,又因为本发明中测量矩阵的规模大,做转置运算耗时较长,因此需在gpu上并行实现。gpu内存中,全局内存没有缓存,访问时延非常长,共享内存是gpu片内的高速存储器,同一块内的所有线程访问速度快于全局内存;只有共享存储同时兼备可读、可写和线程间共享的功能,才可以减少较大的访存开销,因此这里采用共享存储的方式使用2d线程维度做矩阵转置。如图4所示,展示了共享存储2d矩阵转置过程。首先静态分配共享内存,图中小方格代表block的大小,也代表将矩阵分成的子块。在共享内存2d转置过程中,block内线程将矩阵子块的数据读取到共享存储中,保证内存访问不超过边界,经过同步后,每个线程与和按对角线对称的线程交换操作的数据,再按照合并访问方式将结果写到显存中。这种规划方式很好地说明了cuda的两层并行:在同一个block中实现需要进行数据交互的细粒度并行,而在各个block间实现不需要进行数据交换的粗粒度并行。矩阵向量乘法并行化实现过程:由于本发明中多数步骤均涉及到矩阵向量的乘法运算(图子步骤(2b)中系数矩阵的计算),因此采用并行的方式实现可以减少程序的运行时间。如图5所示,采用棋盘阵列分块思想声明一个共享存储矩阵和一个共享存储向量,用于存放a矩阵中小窗口的数据和x向量中子向量的数据。为保证程序的正确性,共享存储数据的加载和读出都要同步。具体实现过程如下:利用二维block和二维thread的概念,将矩阵a划分为a×b个block2d块(a和b的大小根据矩阵的维度和设计的共享内存的大小有关,这里每个block2d维度为32×32),每个二维block2d对应矩阵a的一个子矩阵;将列向量转置成行向量,按照行共享存储优化进行划分b个一维block1d,每个block1d对应一个子向量。每个block1d内所有thread完成与a矩阵行号相同的子矩阵的计算。外层循环实现小窗口的向右移动和子向量向下移动,将子矩阵和子向量写入各自的sharememory,内层循环实现小窗口内数据与子向量数据的计算,即将sharememory中的数据读出,其中与a中子矩阵计算时需要的数据是与a矩阵的整行的子矩阵列号相同的x向量的子向量的整列数据,将计算的对应位置的数据累加,将最终的结果放置在结果向量的相应位置,完成矩阵向量乘法计算。向量转化为对角矩阵的并行实现:在步骤(2c)中需要实现向量对角化过程,如图6所示,根据cuda的编程模型,采用block内循环的方法实现向量对角化gpu的映射,由于线程数量的限制,采用固定跳步的方式循环处理,实现过程中首先找到线程索引,然后将线程索引定位数据单元,然后复制赋值即可。难点在于矩阵对角线处线程索引的寻找,首先设计线程分配,这里采用多block和多thread并行运算,然后根据分配的线程,对线程索引tid和跳步步长step进行构造,线程行索引tidx可利用公式tidx=blockidx.x×blockdim.x+threadidx.x计算,线程列索引tidy可利用公式tidy=blockidx.y×blockdim.x+threadidx.y计算,跳步步长step可利用公式step=griddim.x×blockdim.x计算,即grid内所有线程的数量。向量对应到矩阵对角线的全局线程索引可利用公式tid_a=(tidy×t_n+tidx)×size+tidy×step+tidx计算,其中size为向量的长度,向量的全局线程索引可利用公式tid_x=tidy×t_n+tidx计算。根据全局线程索引分别定位矩阵和向量的数据单元,然后复制赋值完成向量转化为对角矩阵的并行实现。在内核设计过程中采用的优化方法:优化显存访问:优化显存访问,避免显存带宽成为并行算法的性能瓶颈。为满足合并访问,主要采用以下几种方式:1)对数据类型进行对齐;2)保证数据访问的首地址从16的整数倍开始,让每一个线程一次读32bit。优化指令流:本发明实施例采用的是控制流语句方式进行优化。对于控制流指令,如if、switch等,这种条件判断语句给并行计算的性能带来一定的影响。因为在同一block块中的所有线程必须在同一时刻执行一样的命令,若存在判断分支,则会在block中存在线程等待,从而影响函数的性能。对于并行算法中的if分支语句,使用条件表达式(?:)来替代。本发明的效果可以通过以下仿真实验说明:1.仿真内容为了验证本发明在cuda架构下并行计算的优越性,通过一组仿真实验对本发明所需的时间与cpu串行所需的时间定量分析,仿真测试硬件平台参数如表1所示,软件平台参数如表2所示:表1硬件平台参数cpuintel(r)i7-6700内存16gb显卡nvidiageforcegtx1060显卡显存6gb计算能力6.1表2软件平台参数2.仿真结果及分析仿真场景目标的散射系数分布如图7a所示,实验用到两组数据,数据为双精度复数类型。第一组的hessian矩阵数据个数为11160×11160,大小为1.8558gb,将三维目标场景按照对应的距离与方位分辨率进行离散网格化处理,划分为2个距离维的空间位置,对应每个距离切面的场景维度为31×180;第二组的hessian矩阵数据个数为16740×16740,大小为4.1757g,同样做离散化处理,如图7b所示,每个距离切面维度同样为31×180;成像算法的迭代次数设为50次(外层循环),共轭梯度算法求解信号残差值的迭代次数设为200次(内层循环),第二组实验得到的估计信号与仿真的雷达前视场景目标散射系数分布信号对比如图7c、7b所示,估计场景与仿真场景对比如图7d、7a所示。图7表明,虽然数据规模大,点目标个数较多,但是基于gpu在cuda编程架构下采用共轭梯度算法重建出的估计信号与仿真信号在主观上评价基本一致,如图7c所示,其中最后一个位置图像是前面三张图像的沿视场方向的投影,点目标的位置与采用cpu串行方式估计的信号位置完全一致,估计场景与仿真场景目标的散射系数分布吻合,达到了成像要求。将cuda架构下gpu并行计算时间与cpu串行时间进行对比,如表3和表4所示:表3场景划分为两个距离维空间,hessian矩阵:1.8558gb,重建时间:表4场景划分为三个距离维空间,hessian矩阵:4.1757g,重建时间:从表3、表4可看出,本发明采用的方法对雷达前视场景目标的成像速率有明显提升,基本解决了压缩感知框架下处理大规模矩阵耗时较长的问题,实现了准实时性。综上,本发明能带来的有益效果是:1.通过调用cublas函数对算法进行并行实现,加快了压缩感知重构处理的处理速度;2.在内核函数设计过程中采用共享存储的方式减小显存开销,同时采用优化指令流的方式,使程序性能获得提升;3.雷达前视区域的场景目标散射系数规模大、共轭梯度算法适合大规模无约束优化问题的求解,可获取相对较好的估计效果。4.将耗时较长的共轭梯度算法基于gpu平台并行化,实现雷达前视场景目标散射系数分布的估计,进而缩短成像处理时间,提高成像效率。本领域普通技术人员可以理解:实现上述方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成,前述的程序可以存储于计算机可读取存储介质中,该程序在执行时,执行包括上述方法实施例的步骤;而前述的存储介质包括:rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应以所述权利要求的保护范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1