一种基于SMP的足球机器人超大点数FFT算法的制作方法
本发明涉及一种适合SMP的超大点数快速傅里叶变换算法。
背景技术:
快速傅里叶变换(FFT)是足球机器人雷达成像信号处理的关键技术,FFT的执行效率直接影响成像系统的性能。近年来高分辨、大测绘带宽的SAR成像系统的快速发展,使得FFT计算点数较大幅度的增加,带来了FFT计算面临处理器资源有限和执行效率降低两大问题,直接影响了SAR成像系统的研制进度。
现有FFT算法大都基于单核处理器进行研究,很少有文献涉及针对适用于对称多处理器(Symmetric Multiprocessor,SMP)的超大点数FFT算法研究。可以搜索到的有以下方法:
1)SingLeton算法,通过对蝶形进行重排,保证了处理器对内存的顺序操作,从而提升了处理速度,但是该重排的蝶形结构无法适用于SMP系统。
2)基于GPU分块的FFT算法,解决了图像容量较大引起的内存溢出问题,对于SAR成像中采用SMP计算FFT具有一定借鉴意义,但该算法很难移植到其它多核处理器平台。
3)将一维大点数FFT拆分成二维行列小点数来处理,在有限的资源下,为实现更大点数的FFT提供了解决方法,且在大点数时对性能有很大提升,但是该方法基于单核处理器来设计,并没有涉及多核处理器并行优化的研究。
随着FFT处理点数的增加,单核处理器的FFT算法不仅存在处理器资源受限的问题,而且其性能也很难满足现有应用系统对强实时性的要求。目前芯片技术的发展已经不能够适应摩尔定律和突破功率墙的限定,单核处理器性能已接近极限值,为了追求更高的处理性能,各芯片厂商采取在相同的面积上集成更多的处理器核。SMP汇集了一组处理器,它是应用十分广泛的并行技术,且越来越多的雷达信号处理系统开始采用SMP作为主要处理芯片。
技术实现要素:
本发明的目的是提出一种适合SMP的超大点数FFT算法,以提升SAR成像信号处理性能。
为了达到上述目的,本发明的技术方案是提供了一种基于SMP的足球机器人超大点数FFT算法,设SMP的核处理个数为Q,待处理的一维大点数序列的长度为L=2n,其特征在于,所述算法包括以下步骤:
步骤1、将一维大点数序列L拆分成M×N的二维矩阵,且行方向顺序存储在片外存储空间,M与N的值根据式(1)得到:
步骤2、由SMP的主核读取片外存储空间中Q列M长度的数据到片内共享空间,并转置成列方向连续;
步骤3、SMP的每个核分别计算一列M点FFT,FFT结果乘以铰链因子,其值Z(n0,k0)如式(2)所示,并将结果存储到片内共享空间,由SMP的主核原位写回片外存储空间:
式(2)中,n0=0,1,…,M-1,k0=0,1,…,N-1;
步骤4、重复步骤1~步骤3,完成列FFT和乘铰链因子计算,铰链因子只存储第1行数据,其他行的铰链因子由第1行的铰链因子重复计算得出;
步骤5、由SMP的主核读取片外存储空间中Q行N长度的数据到片内共享空间;
步骤6、SMP每个核分别计算一行N点FFT,并将结果转置存储到片内共享空间,由SMP的主核按照列顺序写回片外存储空间;
步骤7、重复步骤5~步骤6,完成行FFT计算,得到FFT计算结果。
本发明通过分析SMP并行处理系统架构特点,得出一种适用于SMP的超大点数FFT算法。该算法采取限定一维序列划分规则最大限度降低复数乘加运算量,并改变乘铰链因子方法减少了对存储资源的依赖,同时优化数据分布和存储访问来隐藏显性转置。实测结果表明,该算法适用于SMP平台,能够解决单核处理器较难实现超大点数FFT的问题,并在FFT存储资源利用和执行性能上均有明显提升。
附图说明
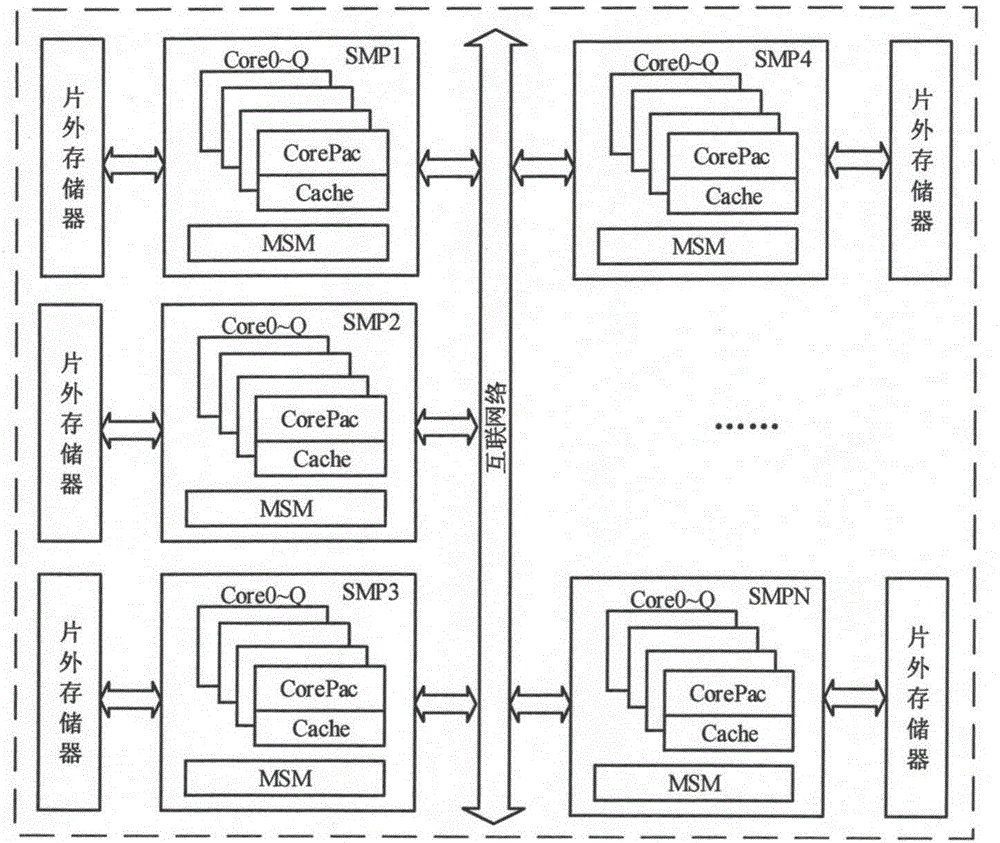
图1为基于SMP的分布式存储结构并行处理系统示意图;
图2为随FFT处理点数增加D的曲线图;
图3为单片SMP并行FFT处理流程及中间数据分布;
图4为基于TMS320C6678的1024k浮点数FFT实现流程图。
具体实施方式
为使本发明更明显易懂,兹以优选实施例,并配合附图作详细说明如下。
目前,多核处理器已成为市场主流,SMP是一种应用广泛的多处理器系统。SMP的多个处理器之间没有区别,可以平等地访问内存、I/O、外设和中断等系统资源,能够使任务或数据对称地分布于多个处理器核之上进行处理。由于核之间的距离更近,它们之间通信的带宽更大,时延更小,性能更佳。图1为基于SMP的分布式存储结构并行处理系统示意图。
由图1可以看出,SMP系统处理的最小单位是一片SMP,每片SMP都有各自的片内共享内存(MSM)和片外存储器,它们可以被处理器核均等的访问,每片SMP通过互联网络相连,实现SMP之间的数据交互和通信功能。现有算法具体工程实现大都基于单核处理器来完成,一般无法直接适用于SMP处理平台。例如,在SAR成像处理系统中,为了最大限度提升FFT算法实现效率,FFT的实现过程均要结合处理器的特性,针对特有平台来编写实现。因此,研究适用于SMP并行处理系统的处理算法具有十分迫切的需求。
对于大点数FFT计算,将一维大点数序列FFT拆分成二维小点数来运算,该方法能够将FFT运算划分成更小的粒度来进行处理。其实现的主要流程为:(1)将1维序列拆分成2维矩阵并转置;(2)行方向FFT处理;(3)乘以铰链因子;(4)对(3)的结果转置存储;(5)列方向FFT处理;(6)将处理结果转置存储,得到序列的FFT结果。但是,针对SMP系统,该算法在实现过程中存在三个问题:一是一维序列行列如何拆分才能得到最优化的运算性能;二是如何均衡乘以铰链因子引入额外的存储空间和增加的乘法运算次数;三是三次显性转置需要较多额外的内存空间,且点数较大时因无法在片内存储空间计算导致性能大幅降低。针对上述三个问题,本发明分别给出具体的优化方法。
1)序列划分规则优化
设FFT一维序列长度为L,划分成为二维序列L=M×N,细粒度行列FFT运算采取基2-FFT算法,依据其计算量公式,可以得出实现FFT运算所需运算量为:
式(3)中,Cf为额外引入的铰链因子复数乘法次数,为固定值;Cmul为乘法运算数;Csum为加法运算数。
由柯西不等式可得式(4):
由以上推导分析可得,当一维序列按照行和列相等的原则来划分时,理论上可以保证FFT的复数乘法和加法的运算量达到最小值,使其拆分性能达到最优。一般对FFT计算来说序列的长度为2n,所以实际操作中,可以按式(5)取M与N的值:
2)铰链因子计算优化
在第(3)步时对行方向FFT的处理结果乘以铰链因子,其值Z(n0,k0)如式(6)所示:
式(6)中,n0=0,1,…,M-1,k0=0,1,…,N-1。铰链因子可以只存储第1行数据,其它行的铰链因子可由第1行的铰链因子重复计算得出。该处理方法可以大大节省内存资源,这对在有限的处理器资源下实现超大点数FFT十分重要。但是,该处理方法会引入新的额外复数乘法运算。为了得出新引入的额外复数乘法运算对超大点数FFT执行效率的影响,下面对该复数乘法运算对整个计算量的影响作进一步分析。
假设只考虑采用复数乘法来衡量FFT的运算时间,按照1)节中的划分原则,新引入的额外复数乘法占总复数乘法的比重D如式(7)所示:
取则式(7)推导为式(8):
式(8)和图2可以看出,新引入的额外复数乘法在FFT总复数乘法所占比重随着点数增加而逐渐减小,当FFT点数大于256K时,所占复数乘法比重系数D趋于0。因此,对于超大点数FFT而言,通过优化铰链因子计算方法,使得新引入的额外复数乘法运算量可以忽略不计,但是能够较大程度地节省处理器片内存储资源。
3)数据分布和存储访问优化
由于超大点数FFT点数较大,且三次显性转置需要至少一倍于序列长度的缓冲空间,导致无法将FFT的原始数据、中间缓冲转置数据和FFT处理结果数据全部放在处理器的片内存储空间,所以必须选择片外存储器(DDR)作为大数据的存储空间,但由处理器直接访问DDR将大大降低执行效率。因此,需要对均衡FFT数据分布和存储访问性能两者之间的关系进行说明。
根据SMP并行处理系统的特点,单片SMP作为一个基本处理单元,由多个处理器核共同完成一个超大序列的FFT运算。如果直接将原始数据、中间转换数据、结果数据分布在片外存储空间进行访问计算,势必引起处理性能的极大下降;又因为FFT被拆分成二维序列来处理,行或列FFT的处理点数变得很小,完全可以读到片内存储空间进行计算,所以可以采取将原始序列数据存储在DDR,然后将数据搬移到片内存储空间进行行或列FFT计算,最终再将结果写回DDR。设SMP的核处理器个数为Q,序列长度为,则单片SMP共同处理一个超大序列的FFT流程如图3所示。
采取数据分布和矩阵访问优化,将占用存储空间较大的原始数据放在片外存储空间DDR,按照Q为访问粒度来读取相应的行或列数据到MSM,由SMP处理器核1~Q分别完成各自对应行或列的FFT计算;矩阵转置可以隐藏在处理流程中,而不需要额外的DDR存储空间来进行显性转置,不仅节省了存储空间,而且提升了矩阵转置效率。表1给出了本发明和原方法对存储资源需求对比。
表1 本发明方法实现FFT对资源的需求
由图3和表1可以看出,通过对超大点数FFT运算的数据分布和矩阵存储访问进行优化,以SMP处理器核Q为数据访问粒度,采用片内临时乒乓缓冲空间,使得FFT计算存取速度比直接访问DDR更加快,进而减少超大点数FFT处理延时。同时,该方法大幅节省内存存储资源,使本发明存储资源大约只占到原方法的25%。因此,通过优化数据分布和矩阵访问,在有限的处理器资源下,为高效地实现更大点数的FFT提供了可行方法。
以上主要对超大点数FFT算法存在三个问题进行改进,下面给出基于SMP的改进型的超大点数FFT算法实现流程:
(1)将一维序列L按照式(5)的原则拆分成M*N的二维矩阵,且行方向顺序存储在片外存储空间;
(2)由SMP的主核读取Q列M长度的数据到片内共享空间,并转置成列方向连续;
(3)SMP每个核分别计算一列M点FFT,FFT结果乘以铰链因子,并将结果存储到片内共享空间,由主核原位写回片外存储空间;
(4)重复(1)~(3)步骤,完成列FFT和乘铰链因子计算;
(5)由SMP的主核读取Q行N长度的数据到片内共享空间;
(6)SMP每个核分别计算一行N点FFT,并将结果转置存储到片内共享空间,由主核按照列顺序写回片外存储空间;
(7)重复(5)~(6)步骤,完成行FFT计算,得到FFT计算结果。
改进后的超大点数FFT算法通过限定序列行列划分规则降低了复数乘加运算量,并改变了乘铰链因子计算方法,同时采取优化数据分布和存储访问使得FFT计算更加适合SMP架构,从而节省了存储资源,提升了超大点数FFT算法实现速度。下面通过算法映射来具体说明基于SMP的超大点数FFT算法实现流程。
本发明以1024K复数点FFT算法映射到TMS320C6678处理器为例。TMS320C6678是TI公司新一代浮点DSP,由八个同构处理器核共同组成SMP系统结构;每个处理器核最高支持1.4GHz的内核时钟,内部集成512KB的L2存储空间,八个核共享4MB片内存储空间,并且拥有强大处理能力和系统互联能力。根据第3节分析,可以将序列划分为1024×1024的二维序列进行处理,行列处理粒度Q为8,其算法映射与实现流程如图4所示。
实验验证与性能对比
本实验结果是在北京理工雷科公司研发的一款基于OpenVPX标准的通用型多DSP高速雷达信号板卡上测试得到。该板卡由一片Virtex7 FPGA和4片TMS320C6678的组成,每片DSP最大支持外挂8GB的DDR3片外存储器,DSP之间通过高速串行总线Rapid IO互联形成SMP系统架构。实验验证条件和测试方法:(1)DSP内核工作主频为1GHz;(2)通过读取超大点数FFT函数执行前后时钟计数周期之差来得到执行时间。基于SMP的超大点数FFT实测结果如表2所示:
表2 浮点FFT实测结果对比(us)
本发明针对现有FFT算法不适用SMP并行处理平台的问题进行深入分析,提出了改进型超大点数FFT算法。通过优化行列划分规则来最大程度的减少了复数乘加运算量,并改变铰链因子计算方法,降低了存储资源开销;同时给出了算法映射及1024K点复数浮点FFT在TMS320C6678上的实现流程。实验对比结果表明,本映射算法适用于SMP系统,能够节省近3/4的存储资源,且明显提升了大点数FFT处理速度,可用于改善高分辨率大测绘带宽SAR成像雷达系统的实时性。
- 还没有人留言评论。精彩留言会获得点赞!