一种基于频域特征提取的快速气体识别算法的制作方法
[技术领域]
本发明涉及电子鼻气体检测技术,具体是涉及一种基于频域特征提取的快速气体识别算法。
[
背景技术:
]
电子鼻是模仿人和动物的鼻子,用于分析、识别、检测复杂气味和挥发性成分的新型仪器,与常用的分析仪器(如色谱仪、光谱仪等)相比,电子鼻具有客观、准确、快捷地评价气味,并且重复性好的特点,其应用越来越广泛,它利用气体传感器来识别样品的挥发性气味。在一些环境恶劣情况下不适合人工监测,为了实现对气体的实时监测,设置电子鼻装置十分必要。
目前气体传感器对气体特征的提取方法有所不同,普遍使用的是稳态特征提取以及瞬态特征但其主要针对如何去除特征中的冗余信息或者是如何提高识别率为目,而在减少气体识别时间上著名的方法为ema算法特征提取。大多数气体检测装置所采用的气体特征是稳态特征,这是由于稳态特征在识别被分析物上拥有超高的识别率,反映出其携带的识别物信息丰富,然而稳态特征的提取通常要等到传感器反应进入一定稳定状态,对于一般的氧化物半导体传感器来说这通常要花费几分钟的时间,这种时间上的延后缺陷极大的限制了气体识别的应用场合,比如潜在的剧毒物品的快速检测,因此,对气体识别能够迅速做出响应的时间越短越好。稳态特征提取:稳态特征是反应结束时的响应值与反应初的值之差再比上反应之初的响应值:
ft+1=αyt+(1-α)ft
ft+1为第t+1个值的指数平滑趋势预测值;
ft为第t个值的指数平滑趋势预测值;
yt为第t个值的实际观察值;
α为权重系数。
ema算法提取特征的过程是将从传感器获得的响应序列经一次指数平滑公式计算得到一新的序列,并以此新序列的极值点作为此次响应序列的特征,该极值点出现的位置相比于稳态特征等待反应基本完全要前移许多,而且在不同的权重系数下极值出现的时间也不同。
稳态特征提取方法需要花费大量的时间,且识别的准确率不及本发明。产生原因:稳态特征提取需要花费大量的时间来等待气体与传感器反应接近结束。
ema算法可以有效的缩短气体识别的等待时间,但本发明缩短的时间更多,而且在识别率上更高,能够更快速对气体做出检测。
[
技术实现要素:
]
为了能够快速对气体做出识别,减少等待时间,本发明提供了一种基于频域特征提取的快速气体识别算法,具体技术方案如下:
步骤1、将恒温条件下的某种气体通入气体传感器阵列(电子鼻)进行数据采集;
步骤2、将每一路传感器采集到的数据用矩形窗从反应开始时刻进行截取,实际操作中相当于测量时气体与传感器阵列反应的时间为窗长时间;
步骤3、将截取出的数据进行傅里叶变换得到截取段序列在频域的分布;
步骤4、在频域分布中取去掉0hz位置的前20个数据值作为该路传感器的特征;
步骤5、将该传感器阵列的所有路传感器的特征按一定顺序组合拼接成一长度为20*n的向量(n为传感器阵列上气体传感器的数量),该向量即为本发明所使用的气体测量的频域特征,并对该向量附上对应气体种类的标签;
步骤6、对大量的气体分别实施步骤1至步骤5得到每一次测量的20*n向量并对每个向量做上对应气体种类的标签;
步骤7、将以上得到的大量向量及其对应的标签利用lda(lineardiscriminantanalysis线性判别分析)算法映射至lda的三维空间下,将该空间下的每次测量数据对应的三维向量作为气体传感器阵列该次测量的频域特征利用lda降维的向量,所有测量的特征降维后的向量和标签组合在一起作为训练集,并且在进行lda算法时会生成20*n维向量向lda的三维空间映射的矩阵;
步骤8、将以上得到的所有降维向量及标签数据输入svm(supportvectormachine支持向量机)分类器进行分类器的模型建立;
步骤9、当识别未知气体的数据时经过步骤1至5得到该气体的频域中20*n向量,然后将该向量与步骤7中的映射矩阵相乘得到该数据在lda的三维空间下的向量;
步骤10、将步骤9得到的三维向量输入至步骤8建立的分类器模型中进行该次测量的气体种类的预测。
其中,步骤4所述去掉0hz位置的数据相当于对截取出的数据进行了去0频滤波,考虑到反应初的响应值会受到传感器漂移的影响,去0频将在一定程度上减少传感器漂移的影响。
通过以上步骤,用矩形窗对整个响应序列进行截取前窗长所对应长度,相当于在采集数据时只采集窗长所对应时间长度的数据,而该窗长实际可以很短(相对于传统特征提取方法),故而可以大大缩短气体检测的时间,实现快速检测识别的目的。
[附图说明]
图1为对uci数据库中的气体数据分别用稳态特征、ema提取特征以及本发明的频域特征用svm分类器进行气体识别的各种性能得比较。
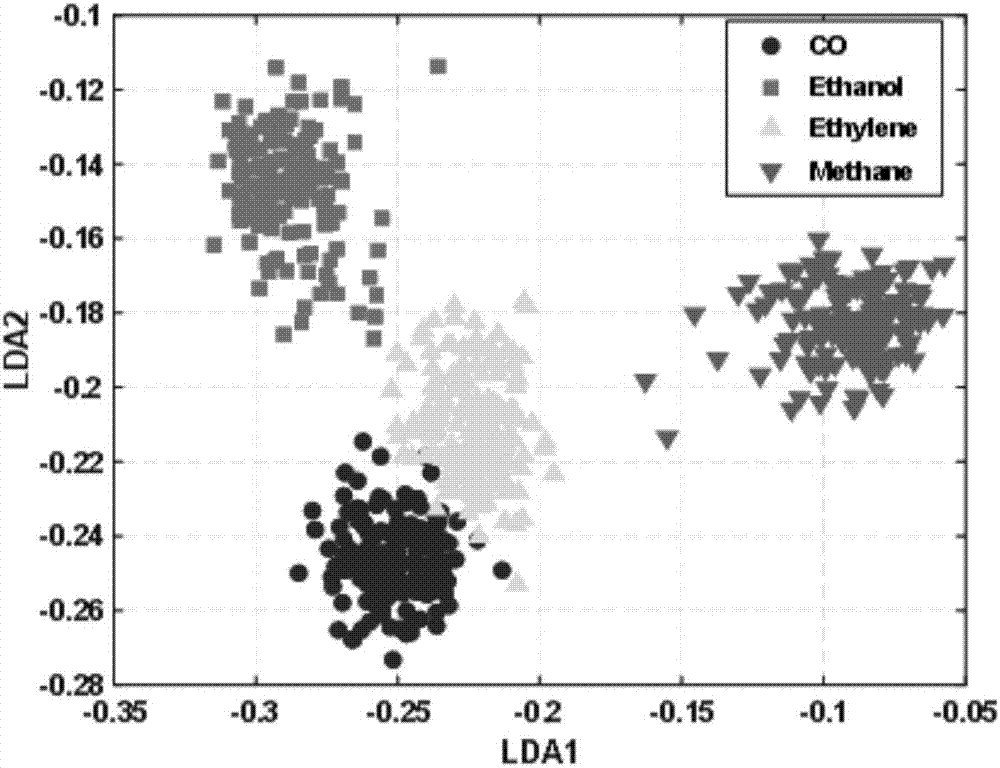
图2为所用数据的频域特征空间去掉0hz频率成分后经lda投影至2维特征空间的分布。
图3为所用数据的频域特征空间去掉0hz频率成分后经lda投影至3维特征空间的分布。
[具体实施方式]
为了使本发明实现的技术手段清晰明了,下面通过实施例进一步阐述本发明。
测试数据(原材料):5个相同的8路传感器阵列测试4种气体,每种气体以10ppm为浓度阶梯从10ppm到100ppm分成10个浓度等级,共做了640次测量。为了将漂移考虑进去,每一个测量组的测量分布在不同的日期进行,数据的采集是频率是100hz,每次测量时间为600s,这就意味着信号序列拥有足够的细节。
步骤:将每次测量的数据的每一路从反应初开始用一长为n的矩形窗对原始数据进行截取,即每次测量的数据都会截取出8段长为n的数据;之后对截取出的每一段数据进行快速傅里叶变换得到每一段数据在频域的分布,再将去除0hz位置的频域数据的前20个数据提取出,对于每一次的测量数据将会得到8个长为20的从频域数据中提取的数据,将这8段长为20的数据拼接成一个长为160的向量,即该次测量的频域特征,并依据该次测量对应的气体种类将此向量做上对应气体的标签。对于640次测量便可得到640个160维的向量及对应标签,将得到的640个160维向量及标签利用lda算法将其投影到lda的三维空间,如图3所示,得到每次测量的频域特征降维后的向量。由于数据有限,取其中的340个降维后的向量及标签作为训练集用于svm分类器的模型建立,剩余300个特征利用建好的svm分类器模型进行预测识别,此300个数据相当于实际应用中对未知气体测量窗长时间后经快速傅里叶变换、取去0hz后前20个数据,拼接、经lda映射后的未知气体的降维后的向量。从图3中可以看出,在3维的lda空间中不同种类的气体数据是可以完全分开的,故而可以使用svm分类器对其分类。
步骤中关于窗长的选择:对于本例子使用的窗长为4s,即实际检测气体时只需花费4s的时间就可以获得足够的信息进行气体的识别。
本发明与传统的ema特征提取方法以及稳态特征提取方法相比功能上都是对测量的气体数据进行特征提取,但区别是检测所消耗的时间更少,具有很大的现实意义,附图1是对uci数据库中的气体数据分别用稳态特征、ema提取特征以及本发明的频域特征用svm分类器进行气体识别的各种性能得比较。根据本实施例,同样的检测实验,基于频域特征提取的用时最短,平均准确率、预测准确率与其他两种检测方法相比也是最高的。
以上所述仅为本发明的实施方式之一,本发明的保护范围并不仅限于上述实施方式,凡是属于本发明原理的技术方案均属于本发明的保护范围。对于本领域的技术人员而言,在不脱离本发明的原理的前提下进行的若干改进,这些改进也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!