一种基于卷积神经网络的室内声源区域定位方法与流程
本发明的技术方案涉及应用声波确定信号源的位置的技术,具体地说是一种基于卷积神经网络的室内声源区域定位方法。
背景技术
基于麦克风阵列的声源定位技术是近几年国内外的一项研究热点,现有的基于麦克风阵列的声源定位方法大体上可分为三类:基于最大输出功率的可控波束形成技术、高分辨率谱估计技术和基于声达时间差的声源定位技术。这些现有的方法大多基于声音传播和能量衰减的几何模型,由于受环境影响大,模型依赖度高的问题,将其应用于非结构化的室内环境中还存在一定的局限性。
由于机器学习的快速发展,许多技术领域的现存问题逐渐可以使用机器学习算法来解决,声源定位技术也不例外。越来越多的研究者开始研究基于机器学习算法,通过分类的手段进行声源定位。这类方法可以将混响带来的影响同样看成是一种特征,能够在一定程度上减小混响的影响,在小信噪比的情况下定位性能不至于迅速下降,比现有的时延定位方法有更强的鲁棒能力。当麦克风无法收到声源发出的直达声时,比起现有的基于麦克风阵列的声源定位方法来说,通过分类的手段进行声源定位同样有更强的鲁棒能力。
卷积神经网络是一种典型的深度神经网络,它相比于其它机器学习算法,如svm,其优点是能够直接对图像像素进行卷积并提取特征,权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。由于这种网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性,可以达到更好的分类效果。
cn105976827a公开了一种基于集成学习的室内声源定位方法,利用集成学习的方法进行声源定位,集成学习是机器学习的一种,集成学习是将若干个分类器集合在一起的机器学习的方法,所以在信噪比较小的分类或回归问题上易产生过拟合,其声源定位的准确率在噪声较大时还不足60%。cn105512683a公开了基于卷积神经网络的目标定位方法及装置,是通过卷积神经网络进行目标定位,是一种目标检测的方式,跟声音信号处理无关,另外,由于cn105512683a的技术方案是采用对数据的特征提取和目标分类分步进行,并利用级联的svm分类器进行训练,存在增加了算法的复杂性和影响目标定位的准确率的缺陷。
总之,当人们所感兴趣的声源位置仅局限在某些预定义的区域内时,上述现有的声源定位技术就显现出在非结构化的室内环境中定位精度不足和适应性欠缺的缺陷。
技术实现要素:
本发明所要解决的技术问题是:提供一种基于卷积神经网络的室内声源区域定位方法,通过将声源信号转化成语谱图的形式并输入到卷积神经网络中,实现室内单声源的区域定位,克服了当人们所感兴趣的声源位置仅局限在某些预定义的区域内时,现有的声源定位技术就显现出在非结构化的室内环境中定位精度不足和适应性欠缺的缺陷。
本发明解决该技术问题所采用的技术方案是:一种基于卷积神经网络的室内声源区域定位方法,具体步骤如下:
第一步,建立信号模型:
建立信号模型的详细过程是,在非结构化的室内环境中,在二维空间内设置一个单一固定声源s(t),对于由m=4个麦克风组成的阵列,则第i个麦克风接收到的声音信号为如下公式(1)所示:
xi(t)=αis(t-τi)+ni(t)i=1,2,...,m(1),
公式(1)中,xi(t)表示第i个麦克风接收到的声音信号,i表示第i个麦克风,αi和τi分别表示接收到声源的声音信号的幅度衰减因子和相对时延,ni(t)则是各种噪声信号的总和,设定声音信号与各麦克风接收到的噪声信号互不相关,各麦克风的噪声信号也不相关,实验数据在matlab环境下产生,模拟的是室内环境,各个麦克风之间与声源的距离不同,接收到的声音信号不仅存在相位差异,还存在声波在空气中传播造成的幅度衰减,这样通过如下公式(2)给各个麦克风接收到的声音信号一个5000点的随机延迟,
t′=(rand×2-1)×5000(2),
上述公式(2)中,t′表示随机延迟时间,rand表示产生(0~1)之间的均匀随机数,通过如下信噪比公式(3)对声音信号增加高斯白噪声,
上述公式(3)中,snr表示声音信号的信噪比,
上述公式(4)中,s表示距离d处麦克风接收到声音信号的能量,s0表示点声源处声音信号的能量,d是声源到接收点的距离,由此完成建立信号模型;
第二步,在建立信号模型的基础上,选取数据样本:
(2.1)测定待定位区域的面积,在二维空间下均匀布置1089个定位参考点;
(2.2)在上述第二步的步骤(2.1)的待定位区域内设定四个声音采集点,分别放置麦克风m0、麦克风m1、麦克风m2和麦克风m3,设置为在二维坐标系下的麦克风阵列m0,m1,m2,m3,相邻麦克风的间距均为l=10.2m,麦克风m0为坐标原点,在麦克风阵列m0,m1,m2,m3所构成的方阵中均匀布置1089个参考点,在上述第一步中的在二维空间内设置的一个单一固定声源s(t)在任意位置处的参考点的坐标为(xi,yi)能够得到1089个数据样本,由此完成选取数据样本;
第三步,将麦克风m0、麦克风m1、麦克风m2和麦克风m3所采集到的声音信号进行时频分析,并建立定位数据库:
(3.1)对上述第二步的步骤(2.2)放置的麦克风m0、麦克风m1、麦克风m2和麦克风m3所采集到的声音信号进行时频分析,得到上述第二步中所布置的各个参考点的声音信号的语谱图样本,生成语谱图的操作如下:
ⅰ.由麦克风接收声音信号得到采样频率,
ⅱ.将这些声音信号放在数组中并计算长度,
ⅲ.对这些声音信号进行分帧加窗处理得到分帧数据,
ⅳ.对上述得到的分帧数据进行短时傅里叶变换,
ⅴ.生成语谱图;
(3.2)将上述第二步的步骤(2.1)中的待定位区域分成九块子区域,并为上述第三步的步骤(3.1)得到的每块子区域的声音信号的语谱图样本制作标签,随机选取声音信号的语谱图样本的90%作为训练样本,在训练样本选定之后剩余的声音信号的语谱图样本的10%作为测试样本;
由此完成定位数据库的建立;
第四步,将构建好的定位数据库进行卷积神经网络的训练和实现基于卷积神经网络的室内声源区域定位:
将上述第三步中构建好的定位数据库进行卷积神经网络的训练和实现基于卷积神经网络的室内声源区域定位,具体方法如下:
(4.1)在ubuntu上搭建tensorflow深度学习框架;
(4.2)建立卷积神经网络模型,具体方法如下:
卷积神经网络模型有四个卷积层和四个池化层,最后通过softmax分类器和三个全连接层输出结果,该卷积神经网络的网络结构为:
conv1(5×5,32)+p1+conv2(5×5,64)+p2+conv3(3×3,128)+p3+conv4(3×3,128)+p4+fc1(1024)+fc2(512)+fc3(9),其中conv表示卷积层,p表示池化层,fc表示全连接层,括号内分别表示卷积核的大小和个数,全连接层括号内为神经元的个数,多个卷积层和池化层交替组合构成了特征提取阶段,卷积层各平面由公式(5)决定:
公式(5)中,
采样层对上一层的特征图进行局部平均和二次特征提取,其各平面由公式(6)决定,
公式(6)中,
由此完成建立卷积神经网络模型,并将上述第三步中的步骤(3.1)得到的90%作为训练样本的每块子区域的声音信号的语谱图样本作为该建立的卷积神经网络的输入,得到训练样本训练初始化的卷积神经网络模型;
(4.3)卷积神经网络的训练及测试:
用上述第四步的步骤(4.2)的训练样本训练初始化的卷积神经网络模型进行卷积神经网络的训练,得到训练好的卷积神经网络模型;
用上述第四步的步骤(4.3)训练好的卷积神经网络模型对上述第三步中的步骤(3.2)中的测试样本进行预测,进行卷积神经网络的测试,得到分类结果即室内待定位区域内的声源所属的区域位置,并通过tensorboard工具对最终的测试结果可视化;
由此完成构建好的定位数据库进行卷积神经网络的训练和实现基于卷积神经网络的室内声源区域定位;
由此最终实现基于卷积神经网络的室内声源区域定位。
上述一种基于卷积神经网络的室内声源区域定位方法,所述第三步的步骤(3.1)中提及的进行时频分析的具体方法如下:
声音信号的采样频率为100khz,在麦克风阵列m0,m1,m2,m3所构成的方阵中均匀布置1089个参考点中的每个参考点位置处生成四个语谱图,这些语谱图分别由麦克风m0,m1,m2,m3接收到的声音信号得到,将四个语谱图合并为一幅图,这样在一个语谱图中可以看到信号幅值的大小所对应的语谱图中颜色的强弱,其生成语谱图的数学表达式如下公式(7)式所示:
公式(7)中,ω表示角频率,j为虚数,x(ω,τ)是一个二维函数,表示中心点位于τ的加窗声音的傅里叶变换,ω(k,τ)是一个长度为n的窗函数,x(k)表示谐波分量序号k=0,1,…,n-1的声音信号。
上述一种基于卷积神经网络的室内声源区域定位方法,所述第三步中的步骤(3.2)中声音信号的语谱图样本为100×100大小的彩色语谱图。
上述一种基于卷积神经网络的室内声源区域定位方法,所述分帧加窗处理、短时傅里叶变换、ubuntu、tensorflow是本领域公知的方法。
本发明的有益效果是:与现有技术相比,本发明具有的突出性质特点如下:
(1)cn105976827a公开了一种基于集成学习的室内声源定位方法是利用集成学习的方法进行声源定位,集成学习是机器学习的一种,集成学习是将若干个分类器集合在一起的机器学习的方法,所以在信噪比较小的分类或回归问题上易产生过拟合,其声源定位的准确率在噪声较大时还不足60%。本发明的技术方案是基于卷积神经网络进行声源区域定位,卷积神经网络属于深度学习的一种。两者有实质性的区别。
(2)cn105512683a公开了基于卷积神经网络的目标定位方法及装置,是通过卷积神经网络进行目标定位,是一种目标检测的方式,跟声音信号处理无关,另外,由于cn105512683a的技术方案是采用对数据的特征提取和目标分类分步进行,并利用级联的svm分类器进行训练,存在增加了算法的复杂性和影响目标定位的准确率的缺陷。本发明的技术方案则是基于卷积神经网络进行声源定位。目标定位与声源定位有实质性的区别。
(3)本发明发明人团队早先的专利技术cn104865555b一种基于声音位置指纹的室内声源定位方法存在需要借助信号处理的多种方法完成特征提取,运算量较大,耗费时间长的缺陷。为了克服cn104865555b所存在的缺陷,使声源定位技术有一个质的飞跃,本发明发明人团队研发了全新的“一种基于卷积神经网络的室内声源区域定位方法”,利用卷积神经网络权值共享的网络结构,将声音信号的语谱图直接作为网络的输入,避免了复杂的特征提取和数据重建过程,克服了cn104865555b技术方案中在构建位置指纹库之前对于声源信号特征提取的复杂的过程。在此,需要阐明的是:在cn104865555b的基础上获得本发明一种基于卷积神经网络的室内声源区域定位方法所要求保护的技术方案不是本领域技术人员轻而易举就能得到的,经过三年时间的辛勤研究,本发明人将深度学习领域与声源定位突破性的结合在一起,选择了在声音信号处理中应用广泛的卷积神经网络。由于卷积神经网络权值共享的优点在处理多维图像时表现的更为明显,所以经查阅大量文献及相关书籍,本发明人发现语谱图是声音信号的可视化表示,其中包含了大量的声纹信息,将这种含有深层特征的三维频谱作为输入正好符合卷积神经网络独有的性质特点。本发明人通过对卷积神经网络的结构特点详细的研究,经过反复训练和验证选取了最合适的网络结构,提高了声源区域定位的准确率。
与现有技术相比,本发明具有的显著进步如下:
(1)卷积神经网络是一种典型的深度神经网络,它相比于其它机器学习算法,如svm,其优点是能够直接对图像像素进行卷积并提取特征,权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。由于这种网络结构对平移、比例缩放、倾斜或者共他形式的变形具有高度不变性,可以达到更好的分类效果。
(2)本发明一种基于卷积神经网络的室内声源区域定位方法,通过将声源信号转化成语谱图的形式并输入到卷积神经网络中,实现室内单声源的区域定位,克服了当人们所感兴趣的声源位置仅局限在某些预定义的区域内时,现有的声源定位技术就显现出在非结构化的室内环境中定位精度不足和适应性欠缺的缺陷。
(3)本发明通过将声源信号转换成语谱图的形式并输入到卷积神经网络中,实现了室内声源的区域定位,提高了在一些小信噪比或者恶劣的环境下的鲁棒能力。
附图说明
下面结合附图和实施例对本发明进一步说明。
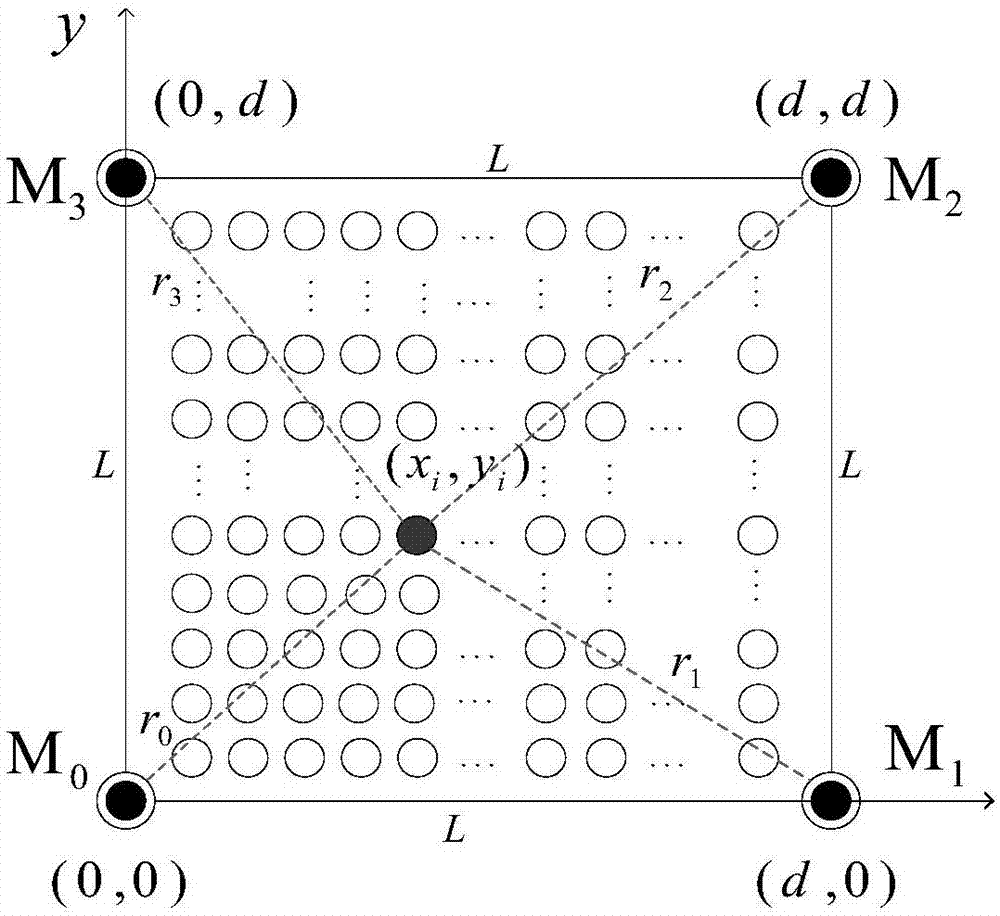
图1为本发明设置的在二维坐标系下的麦克风阵列模型示意图。
图2为本发明的语谱图的实现过程示意图。
图3为本发明四路麦克风合并后的语谱图。
图4为本发明的待定位区域分区示意图。
图5为本发明的卷积神经网络的结构示意图。
图6为本发明的卷积神经网络的训练的准确率和损失函数的变化曲线图,其中,
图6(a)为本发明的卷积神经网络的训练的准确率的变化曲线图。
图6(b)为本发明的卷积神经网络的训练的损失函数的变化曲线图。
图7为本发明的卷积神经网络的测试准确率和损失函数的变化曲线图,其中,
图7(a)为本发明的卷积神经网络的测试准确率的变化曲线图。
图7(b)为本发明的卷积神经网络的测试损失函数的变化曲线图。
具体实施方式
图1所示实施例表明,定位区域内设定四个声音采集点为:(0,0)、(d,0)、(d,d)、(0,d),四个声音采集点上分别放置麦克风m0、麦克风m1、麦克风m2和麦克风m3,设置为在二维坐标系下的麦克风阵列m0,m1,m2,m3,相邻麦克风的间距均为l=10.2m,麦克风m0为坐标原点,在麦克风阵列m0,m1,m2,m3所构成的方阵中均匀布置1089个参考点,得到1089个数据样本,声源在任意位置处的参考点的坐标为(xi,yi),分别距m0,m1,m2,m3的距离为r0,r1,r2,r3。
图2所示实施例表明,本发明的语谱图的实现过程示是:首先对声音信号进行分帧加窗,然后进行短时傅里叶变换,其次对得到的能量谱密度进行伪彩色映射,从而完成语谱图的生成。
图3显示了本发明四路麦克风合并后的语谱图,该图表明:四路麦克风接收到的四组声音信号为一个数据样本,故将四个语谱图合并为一幅图,这样在一个语谱图中就看到声音信号幅值的大小所对应的语谱图中颜色的强弱。
图4所示实施例表明,定位区域内设定四个声音采集点为:(0,0)、(d,0)、(d,d)、(0,d),四个声音采集点上分别放置麦克风m0、麦克风m1、麦克风m2和麦克风m3,设置为在二维坐标系下的麦克风阵列m0,m1,m2,m3,相邻麦克风的间距均为l=10.2m,横坐标选取(
图5所示实施例表明,卷积神经网络的结构是一种典型的深度神经网络,该图形显示,本发明的卷积神经网络的结构具有权值共享以及高度不变性的特征,卷积神经网络的输入为100×100的语谱图,该模型有四个卷积层即卷积层1、卷积层2、卷积层3和卷积层4,有四个池化层即池化层1、池化层2、池化层3和池化层4,最后通过softmax分类器和三个全连接层输出结果,该卷积神经网络的网络结构为:
conv1(5×5,32)+p1+conv2(5×5,64)+p2+conv3(3×3,128)+p3+conv4(3×3,128)+p4+fc1(1024)+fc2(512)+fc3(9),其中conv表示卷积层,p表示池化层,fc表示全连接层,括号内分别表示卷积核的大小和个数,全连接层括号内为神经元的个数。
图6(a)显示了本发明的卷积神经网络的训练的准确率的变化曲线图,该曲线表明,通过tensorboard工具对最终的测试结果可视化,训练集准确率随着迭代而上升,在500次迭代的过程中,本发明的卷积神经网络模型在训练数据上的准确率最高达到1。
图6(b)显示了本发明的卷积神经网络的损失函数的变化曲线,该曲线表明,通过tensorboard工具对最终的测试结果可视化,训练集的损失函数随着迭代而下降,在500次迭代的过程中,本发明的卷积神经网络模型的损失函数逐渐接近于0。
图7(a)显示了本发明的卷积神经网络的测试准确率的变化曲线,该曲线表明,通过tensorboard工具对最终的测试结果可视化,测试集准确率随着迭代而上升,在500次迭代的过程中,本发明的卷积神经网络模型在测试数据上的准确趋于93%。
图7(b)显示了本发明的卷积神经网络的测试损失函数的变化曲线,该曲线表明,通过tensorboard工具对最终的测试结果可视化,测试集的损失函数随着迭代而下降,在500次迭代的过程中,本发明的卷积神经网络模型的损失函数逐渐接近于0。
综上说明书附图所述,进一步证明,本发明的基于卷积神经网络的室内声源区域定位方法,通过将声源信号转化为语谱图,进而通过神经网络得到分类结果,从而达到定位的效果,克服了传统的定位方法计算量大定位精度不足等缺点,而从机器学习的角度处理声源定位问题。因此确认本发明有非常高的应用价值。
实施例1
本实施例的一种基于卷积神经网络的室内声源区域定位方法,具体步骤如下:
第一步,建立信号模型:
建立信号模型的详细过程是,在非结构化的室内环境中,在二维空间内设置一个单一固定声源s(t),对于由m=4个麦克风组成的阵列,则第i个麦克风接收到的声音信号为如下公式(1)所示:
xi(t)=αis(t-τi)+ni(t)i=1,2,...,m(1),
公式(1)中,xi(t)表示第i个麦克风接收到的声音信号,i表示第i个麦克风,αi和τi分别表示接收到声源的声音信号的幅度衰减因子和相对时延,ni(t)则是各种噪声信号的总和,设定声音信号与各麦克风接收到的噪声信号互不相关,各麦克风的噪声信号也不相关,实验数据在matlab环境下产生,模拟的是室内环境,各个麦克风之间与声源的距离不同,接收到的声音信号不仅存在相位差异,还存在声波在空气中传播造成的幅度衰减,这样通过如下公式(2)给各个麦克风接收到的声音信号一个5000点的随机延迟,
t′=(rand×2-1)×5000(2),
上述公式(2)中,t′表示随机延迟时间,rand表示产生(0~1)之间的均匀随机数,通过如下信噪比公式(3)对声音信号增加高斯白噪声,
上述公式(3)中,snr表示声音信号的信噪比,
上述公式(4)中,s表示距离d处麦克风接收到声音信号的能量,s0表示点声源处声音信号的能量,d是声源到接收点的距离,由此完成建立信号模型;
第二步,在建立信号模型的基础上,选取数据样本:
(2.1)测定待定位区域的面积,在二维空间下均匀布置1089个定位参考点;
(2.2)在上述第二步的步骤(2.1)的待定位区域内设定四个声音采集点,分别放置麦克风m0、麦克风m1、麦克风m2和麦克风m3,设置为在二维坐标系下的麦克风阵列m0,m1,m2,m3,相邻麦克风的间距均为l=10.2m,麦克风m0为坐标原点,在麦克风阵列m0,m1,m2,m3所构成的方阵中均匀布置1089个参考点,在上述第一步中的在二维空间内设置的一个单一固定声源s(t)在任意位置处的参考点的坐标为(xi,yi)能够得到1089个数据样本,由此完成选取数据样本;
第三步,将麦克风m0、麦克风m1、麦克风m2和麦克风m3所采集到的声音信号进行时频分析,并建立定位数据库:
(3.1)对上述第二步的步骤(2.2)放置的麦克风m0、麦克风m1、麦克风m2和麦克风m3所采集到的声音信号进行时频分析,得到上述第二步中所布置的各个参考点的声音信号的语谱图样本,生成语谱图的操作如下:
ⅰ.由麦克风接收声音信号得到采样频率,
ⅱ.将这些声音信号放在数组中并计算长度,
ⅲ.对这些声音信号进行分帧加窗处理得到分帧数据,
ⅳ.对上述得到的分帧数据进行短时傅里叶变换,
ⅴ.生成语谱图;
上述提及的进行时频分析的具体方法如下:
声音信号的采样频率为100khz,在麦克风阵列m0,m1,m2,m3所构成的方阵中均匀布置1089个参考点中的每个参考点位置处生成四个语谱图,这些语谱图分别由麦克风m0,m1,m2,m3接收到的声音信号得到,将四个语谱图合并为一幅图,这样在一个语谱图中可以看到信号幅值的大小所对应的语谱图中颜色的强弱,其生成语谱图的数学表达式如下公式(7)式所示:
公式(7)中,ω表示角频率,j为虚数,x(ω,τ)是一个二维函数,表示中心点位于τ的加窗声音的傅里叶变换,ω(k,τ)是一个长度为n的窗函数,x(k)表示谐波分量序号k=0,1,…,n-1的声音信号。
(3.2)将上述第二步的步骤(2.1)中的待定位区域分成九块子区域,并为上述第三步的步骤(3.1)得到的每块子区域的声音信号的语谱图样本制作标签,随机选取声音信号的语谱图样本的90%作为训练样本,在训练样本选定之后剩余的声音信号的语谱图样本的10%作为测试样本,上述声音信号的语谱图样本为100×100大小的彩色语谱图;
由此完成定位数据库的建立;
第四步,将构建好的定位数据库进行卷积神经网络的训练和实现基于卷积神经网络的室内声源区域定位:
将上述第三步中构建好的定位数据库进行卷积神经网络的训练和实现基于卷积神经网络的室内声源区域定位,具体方法如下:
(4.1)在ubuntu上搭建tensorflow深度学习框架;
(4.2)建立卷积神经网络模型,具体方法如下:
卷积神经网络模型有四个卷积层和四个池化层,最后通过softmax分类器和三个全连接层输出结果,该卷积神经网络的网络结构为:
conv1(5×5,32)+p1+conv2(5×5,64)+p2+conv3(3×3,128)+p3+conv4(3×3,128)+p4+fc1(1024)+fc2(512)+fc3(9),其中conv表示卷积层,p表示池化层,fc表示全连接层,括号内分别表示卷积核的大小和个数,全连接层括号内为神经元的个数,多个卷积层和池化层交替组合构成了特征提取阶段,卷积层各平面由公式(5)决定:
公式(5)中,
采样层对上一层的特征图进行局部平均和二次特征提取,其各平面由公式(6)决定,
公式(6)中,
由此完成建立卷积神经网络模型,并将上述第三步中的步骤(3.1)得到的90%作为训练样本的每块子区域的声音信号的语谱图样本作为该建立的卷积神经网络的输入,得到训练样本训练初始化的卷积神经网络模型;
(4.3)卷积神经网络的训练及测试:
用上述第四步的步骤(4.2)的训练样本训练初始化的卷积神经网络模型进行卷积神经网络的训练,得到训练好的卷积神经网络模型;
用上述第四步的步骤(4.3)训练好的卷积神经网络模型对上述第三步中的步骤(3.2)中的测试样本进行预测,进行卷积神经网络的测试,得到分类结果即室内待定位区域内的声源所属的区域位置,并通过tensorboard工具对最终的测试结果可视化;
由此完成构建好的定位数据库进行卷积神经网络的训练和实现基于卷积神经网络的室内声源区域定位;
由此最终实现基于卷积神经网络的室内声源区域定位。
实施例2
本实施例是为了说明设计的卷积神经网络框架的可行性和有效性,本发明通过实验仿真进行测试利用训练好的卷积神经网络模型对测试样本进行预测,得到分类结果即声源所属的区域位置,并通过tensorboard工具对最终的测试结果可视化,是用训练好的网络模型对10%的语谱图测试样本进行预测,得到分类结果即声源所属的区域位置的准确率。为了说明设计的卷积神经网络框架的可行性和有效性,本发明通过实验仿真进行测试,选取信噪比为5db,10db,15db,分别进行测试,分别训练五次,训练时采用相同的参数配置:n_epoch=500,学习率为0.0001,batch_size=64,得到的定位准确率如表1所示:
根据表1可知,卷积神经网路具有较强的鲁棒性,给声音信号加上不同的信噪比,其最终的定位准确率在93%左右,最后通过tensorboard工具对最终的测试结果可视化,训练集和测试集的分类准确率随着迭代而上升,损失函数随着迭代而下降,最终两者的变化都趋于平稳。在500次迭代的过程中,该训练好的卷积神经网络模型在训练数据上的准确率最高达到1,在测试数据上的准确率最终趋于93%,迭代后的损失函数都逐渐接近于0。
上述实施例中所述分帧加窗处理、短时傅里叶变换、ubuntu、tensorflow是本领域公知的方法。
- 还没有人留言评论。精彩留言会获得点赞!