一种装载机铲装过程的作业斗数识别方法与识别装置与流程
本发明涉及工程车辆铲装过程的作业斗数识别技术,更具体地说,涉及一种装载机铲装过程的作业斗数识别方法,以及一种装载机铲装过程的作业斗数识别装置。
背景技术:
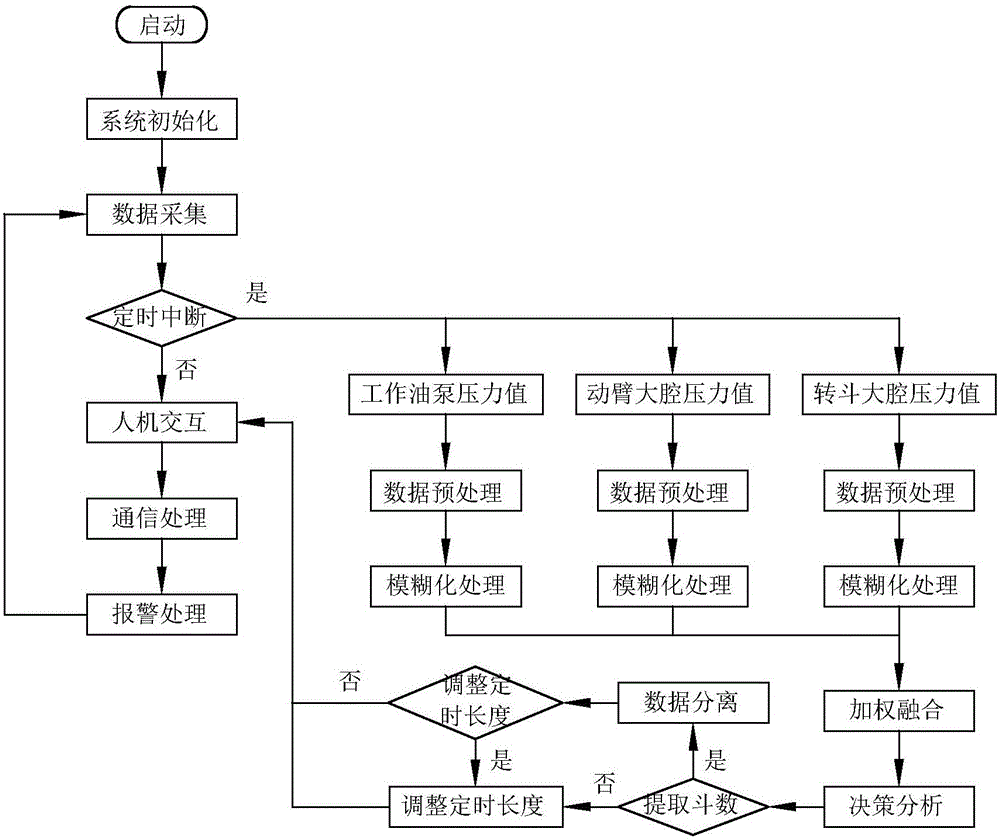
:随着我国采矿、建筑、水利水电、高速铁路网、公路网、南水北调等大型国家工程建设的快速推进,工程车辆的产、销量和保有量快速提高,工程机械发展异常迅速。2009年中国装载机以15万台的产销量占到世界的75%左右,2011年销量甚至达到23万台左右,至今为止,我国已成为工程机械制造大国。近年来,随着建筑施工和资源开发规模的扩大,对工程机械需求量迅速增加的同时,对其可靠性、维修性、安全性、燃油经济性、智能化等也提出了更高的要求,因此需要开展大量的实验研究,采集大量的作业谱数据。装载机作为工程机械中最大的家族成员之一,不仅在工程机械中占有量最大,而且销量也最大,我国是世界上装载机产量最多、销量最大的国家,随着对装载机可靠性、维修性、安全性、燃油经济性、智能化的要求越来越高,需要进行的试验研究也越来越多,如何实现试验过程的试验样本数智能统计将是一个越来越受关注的问题,而且对于铲装斗数(作业周期)的识别,对于装载机过程控制具有重要的意义,是装载机进行过程控制的基础。作业谱采集实验中,样本数是一个至关重要的参数,决定着获得的作业数据是否能用。原始的装载机载荷是一种随机变化的载荷,通常情况下都是运用概率统计、样本估计等方法,从有限样本长度的随机载荷中提取载荷特征值,不同样本长度的载荷获取得到的载荷特征值的准确度随样本大小而异。特征值的准确度随样本长度的增长而提升,但随着样本长度的增长,将导致样本提取的工作量、工作难度等增大,且当样本长度增加到一定程度,准确度增加值有限。因此,需要准确的计量样本长度,在满足准确度的前提下,使样本数最少。所述的样本数对于装载机而言,就是铲装过程的作业斗数,传统的作业斗数计量都是采用定时估量法或人工计数法,往往造成样本数不足或样本数够多,导致实验准确度低或提取工作量大、工作难度高。由于装载机的作业工况复杂,导致作业周期时间长短不一、样本幅值变化大。技术实现要素:本发明的目的在于克服现有技术的不足,提供一种能够准确获得所需的样本数、可直接应用于装载机的装载机铲装过程的作业斗数识别方法,以及装载机铲装过程的作业斗数识别装置。本发明的技术方案如下:一种装载机铲装过程的作业斗数识别方法,步骤如下:1)采集工作油泵压力值、动臂大腔压力值和转斗大腔压力值;2)对采集得到的压力值进行模糊化处理,将压力值转变成非作业、状态待定、作业三种模糊量;3)对得到的模糊量采用加权融合的方法,得到融合值;4)将融合值进行决策分析,得到作业周期的划分依据,并由此得到铲装斗数。作为优选,步骤1)中,对采集的工作油泵压力值、动臂大腔压力值和转斗大腔压力值进行预处理,包括数值归一化、数据滤波。作为优选,数值归一化具体为:将数据序列D的一个原始值x通过Min-max标准化映射成在区间[0,1]中的值x*,公式为:x*=x-DminDmax-Dmin;]]>其中,Dmin和Dmax分别为数据序列D的最小值和最大值。作为优选,对经数值归一化处理后得到的数据进行阀值滤波,阈值函数为:w^j,k=wj,k(1-u)+u*sign(wj,k)(|wj,k|-λ1+exp(|wj,kλ|n-1)),|wj,k|≥λwj,k(1-u),|wj,k|<λ;]]>其中,u、n为调节系数,u的取值范围为[0,1],n为非0自然数;λ为阈值,根据实际需要进行选择;wj,k为原始小波系数,为估计小波系数。作为优选,步骤2)中,模糊化处理中采用的模糊隶属度函数为s型,公式如下:A(x;a,b,c)=0,x≤a2(x-ac-a),a<x≤b1-2(x-cc-a),b<x≤c1,x>c;]]>其中,根据模糊隶属度函数与实际采集的压力曲线,确定a、b、c取值,且a<c,其中A(x;a,b,c)为模糊处理公式,x为初始化值,a,b,c为变量参数,用于划定模糊区间。作为优选,步骤3)中,为工作油泵压力值、动臂大腔压力值和转斗大腔压力值定制加权因子,得到对应工作油泵压力值、动臂大腔压力值和转斗大腔压力值的局部估计,加权综合所有的局部估计,得到全局估计。作为优选,融合后的融合压力值和加权因子满足如下规则:x^=Σi=13WixiΣi=13Wi=1;]]>其中,Wi为工作油泵压力值、动臂大腔压力值和转斗大腔压力值的加权因子。作为优选,采用平均方式确定加权因子,得到的融合压力值为:x^=13Σi=13xi.]]>作为优选,步骤4)中,采用模糊逻辑C均值聚类算法进行决策分析,得到聚类中心值,取最低的两个聚类中心值求平均值;在作业周期内,低于平均值的连续线段的时间清零,高于平均值的连续线段的时间即为各个作业周期中确定的作业与非作业的时间长度,然后统计作业周期的个数,即为作业斗数。一种装载机铲装过程的作业斗数识别装置,包括微处理器、与微处理器连接的工作油泵压力传感器、动臂大腔压力传感器和转斗大腔压力传感器、通信模块、斗数警报模块和人机交互模块;工作油泵压力传感器、动臂大腔压力传感器和转斗大腔压力传感器分别用于采集工作油泵压力值、动臂大腔压力值和转斗大腔压力值;通信模块用于远程读取和设置铲装斗数及斗数报警阈值;斗数警报模块用于提醒驾驶员已经完成相应斗数的铲装操作;人机交互模块用于驾驶员或试验员设置铲装斗数及斗数报警阈值;微处理器执行所述的装载机铲装过程的作业斗数识别方法。本发明的有益效果如下:本发明所述的方法,本发明所述的方法与装置,通过对装载机铲装过程中三种压力传感器采用多传感器融合技术,实现对铲装过程作业斗数的自动辨识,有效提高与保证试验数据的准确性,同时有效避免驾驶员超额作业。该发明还有利于装载机作业阶段的识别,为准确识别作业阶段、实现作业过程动态预测与控制提供良好基础。本发明中,作业斗数(也可称为作业周期)识别方法,不仅对性能试验过程样本数的准确计量有重大意义,而且对于后期的样本统计也具有重要意义,它实现了作业周期的阶段划分,为后期的统计提供便利。本发明的实施,使试验人员准确的获得所需的样本数,提高与保证试验的准确度,同时避免驾驶员因所采集样本数够多而浪费时间与体力。附图说明图1是本发明的识别装置的原理框图;图2是本发明的识别方法的程序设计流程图。具体实施方式以下结合附图及实施例对本发明进行进一步的详细说明。本发明为了解决现有技术中工程车辆作业斗数智能识别难的问题,提供一种可直接应用于装载机的动态在线作业斗数识别方法及装置,使试验人员准确的获得所需的样本数,提高与保证试验的准确度,同时避免驾驶员因所采集样本数够多而浪费时间与体力。由于工程车辆作业过程中,工作油泵压力、动臂大腔压力和转斗大腔压力的变化与作业阶段关系紧密又各有特点,另由于工作环境、作业工况复杂以及驾驶风格不同,导致相同阶段的压力曲线变化不同,无法通过单一量来确定各作业段的时间范围,为了克服这一问题,本发明基于模糊逻辑的多传感器数据融合方法,提出一种装载机铲装过程的作业斗数识别方法,步骤如下:1)采集工作油泵压力值、动臂大腔压力值和转斗大腔压力值;为了得到更准确的数据,对采集的工作油泵压力值、动臂大腔压力值和转斗大腔压力值进行预处理,包括数值归一化、数据滤波(如小波滤波)等;2)对采集得到的压力值进行模糊化处理,将压力值转变成非作业、状态待定、作业三种模糊量;3)对得到的模糊量采用加权融合的方法,得到融合值;4)将融合值进行决策分析,采用模糊逻辑C均值聚类算法进行分析,得到作业周期的划分依据,并由此得到铲装斗数。基于所述的识别方法,本发明还提供一种装载机铲装过程的作业斗数识别装置,如图1所示,包括微处理器、与微处理器连接的工作油泵压力传感器、动臂大腔压力传感器和转斗大腔压力传感器、通信模块、斗数警报模块和人机交互模块。工作油泵压力传感器、动臂大腔压力传感器和转斗大腔压力传感器分别用于采集工作油泵压力值、动臂大腔压力值和转斗大腔压力值;所用传感器根据应用场合要求,可以选择电流型输出或电压输出。通信模块包括RS232、RS485与CAN等3种通信方式,用于微处理器与其他设备的通信,主要功能是将作业斗数信息送出和远程参数设置与控制,如远程读取和设置铲装斗数及斗数报警阈值。斗数警报模块用于输出报警,提醒驾驶员已完成的作业斗数或完成所有作业斗数的铲装操作时的报警。人机交互模块用于现场操作人员对识别装置的人工设置及识别装置的状态显示,驾驶员或试验员通过人机交互模块设置铲装斗数及斗数报警阈值。人机交互模块可以包括一个显示器与键盘,键盘用于信息输入,显示器用于信息的显示。微处理器为整个识别装置的控制核心,可以选用STM、PIC、ARM等系列的处理器芯片,其主要作用包括交互、控制及识别算法的实现,并执行所述的装载机铲装过程的作业斗数识别方法。如图2所示,本发明识别的方法内嵌于微处理器中执行。微处理器上电启动后,程序开始执行,首先微处理器会先进行系统初始化,包括采集口的AD初始化、定时判断初始化、通信模块初始化、斗数警报模块初始化和人机交互模块初始化。系统初始化完成以后,便会启动数据采集,此时微处理器通过AD采集口等采集来自工作油泵压力传感器、动臂大腔压力传感器和转斗大腔压力传感器的数值,并进行记录,由于压力变化缓慢,数据采集的采样率为20Hz,并将得到的数据进行中位均值平滑滤波处理,得到10Hz的信号。接下来所述的装置检测是否产生定时中断,定时器初始设置的中断间隔时间为30秒,该时间为试验场地完成1次作业斗数的基本时间。如果未产生定时中断则进入人机交互模块的处理程序,检测是否有人机交互操作,如果有则响应操作,如果没有则进入通信模块的处理程序,检测是否有设备连接,如果有设备连接则送出装置的状态信息和斗数等,处理完成后进入报警模块的处理程序,输出相关报警信息。如果产生定时中断到则开始进行数据处理,将微处理器采集得到的10Hz压力信号进行数据预处理和模糊化处理,最后得到的模糊化数值进行加权融合,并将加权融合得到的值进行决策分析,本发明的识别方法核心在于模糊化处理与决策分析。所述的识别方法具体如下:1、数据预处理,包括数值归一化与小波滤波。作为优选,数值归一化具体为:将数据序列D的一个原始值x通过Min-max标准化映射成在区间[0,1]中的值x*,公式为:x*=x-DminDmax-Dmin;]]>其中,Dmin和Dmax分别为数据序列D的最小值和最大值。通过数值归一化处理,将压力数值转换为[0,1]之间的值,有利于降低数据运算量与避免数据的溢出。对经数值归一化处理后得到的数据进行阀值滤波,阈值函数为:w^j,k=wj,k(1-u)+u*sign(wj,k)(|wj,k|-λ1+exp(|wj,kλ|n-1)),|wj,k|≥λwj,k(1-u),|wj,k|<λ;]]>其中,u、n为调节系数,u的取值范围为[0,1],n为非0自然数;λ为阈值,根据实际需要进行选择;wj,k为原始小波系数,为估计小波系数。经过阈值函数滤波后得到的压力值的滤波效果最佳,所述的滤波方法特别适用于装载机压力信号的滤波处理。2、模糊化处理,经过数据预处理操作后得到的压力值数据,继续进行模糊化处理14操作。对各压力传感器数据所处的作业状态采用3种模糊集合来描述:非作业、状态待定、作业等描述,用标号即为{W-1,W0,W1}。模糊化处理采用模糊隶属度函数为s型,公式如下:A(x;a,b,c)=0,x≤a2(x-ac-a),a<x≤b1-2(x-cc-a),b<x≤c1,x>c;]]>其中,根据模糊隶属度函数与实际采集的压力曲线,确定a、b、c取值,且a<c,确定a、b、c取值后可确定各隶属度函数。其中A(x;a,b,c)为模糊处理公式,x为初始化值,a,b,c为变量参数,用于划定模糊区间。工作油泵压力的模糊隶属度函数如下所示,其中,a=0.2,b=0.3,c=0.4。A(x)=0,x≤0.210x-2,0.2<x≤0.35-10x,0.3<x≤0.41,x>0.4]]>动臂大腔压力的模糊隶属度函数如下所示,其中,a=0.2,b=0.3,c=0.4。A(x)=0,x≤0.210x-2,0.2<x≤0.35-10x,0.3<x≤0.41,x>0.4]]>转斗大腔压力的模糊隶属度函数如下所示,其中,a=0.2,b=0.4,c=0.6。A(x)=0,x≤0.25x-1,0.2<x≤0.44-5x,0.4<x≤0.61,x>0.6]]>设数据预处理后得到的归一化数据为X,通过模糊隶属度函数A(x)对归一化数据X进行处理,得到新的模糊数据序列Y=X*A(x)。新处理得到的数据序列的值还是在[0,1]里面,根据模糊集的定义{W-1,W0,W1},现令Y(i)>=0.75的Y(i)值取-1,Y(i)<=0.25的Y(i)值取1,其他取零值。通过该方法,就将当前压力值划归到3个模糊空间内,然后进行加权融合处理。3、加权融合传感器数据的加权融合算法的核心思想是兼顾每个传感器的局部估计,按照一定的原则为工作油泵压力值、动臂大腔压力值和转斗大腔压力值定制加权因子,得到对应工作油泵压力值、动臂大腔压力值和转斗大腔压力值的局部估计,加权综合所有的局部估计,得到全局估计。设工作油泵压力传感器M1、动臂大腔压力传感器M2和转斗大腔压力传感器M3分别对应的工作油泵压力值、动臂大腔压力值和转斗大腔压力值的加权因子分别为W1、W2、W3,根据加权融合规则,融合后的值和加权因子满足如下规则:x^=Σi=13WixiΣi=13Wi=1;]]>其中,Wi为工作油泵压力值、动臂大腔压力值和转斗大腔压力值的加权因子。由于三种压力传感器是相互独立得,对工程车辆的作业段过程的体现因素基本相同,因此选用平均方式确定加权因子,即假设各传感器的加权因子近似相等,得到的融合值为:x^=13Σi=13xi.]]>利用该融合方法对3个压力传感器进行融合处理,就得到一组融合的压力传感器值,然后对该组压力传感器值进行决策分析。4、决策分析决策分析采用模糊逻辑C均值聚类(FCM)算法。对于得到的融合压力传感器值,可以看出其具有明显的周期特征。现有技术的融合压力传感器值被划分为工作、非作业、状态待定等3种状况,而实际需要被分为作业与非作业两种情况,作业段与非作业段值都是连续的,因此,可以通过统计各连续段的时间,根据连续段时间和融合压力值来区分出作业与非作业两种状态,则作业周期也就能区分出来了。连续线段的时间统计原则为从线段的起始点开始算,对每个线段点进行计数,当到达另外一个连续线段的转折点时,记录前一个连续线段的总点数及最后一点的位置,然后在开始另一个连续线段的时间统计。每个连续线段最后一点的位置统计是为了后面对各作业循环进行划分。连续线段的时间统计完毕后,对连续线段按照处于作业状态与非作业状态在进一步区分出来,最后将作业状态下与非作业状态下的连续线段的时间统计值进行归一化处理,即只显示各状态下的连续线段的时间比例。为了对各线段的时间长度进行模糊逻辑C均值聚类分析,将非作业与作业状态下的各线段的时间长度单独提取出来,并设对应横坐标都为1,构建非作业与作业的时间长度样本集合X1和X2,即X={{1,t1},{1,t2},{1,t3},...,{1,tn}}。样本集合X构建完成后,开始进行如下的FCM算法运算:1)初始化:给定聚类类别数c(2≤c≤n),由于非作业状态下个别特殊情况如临时停车等导致个别时间长度较长,因此将非作业的样本集合的聚类类别数取值3,即c1=3;作业状态下时间长度都比较一致,将其样本集合的聚类类别取值2,即c2=2。两者的模糊权数m都取一般值2;设定迭代停止阈值ε为0.002;迭代计数次数l设为2000,并初始化聚类原型V(l)(l=0)。2)根据V(l),按照下面公式,更新模糊划分矩阵U(l+1)得:uij(l+1)=(dij(l)Σj=1cdij(l))-2m-1.]]>3)根据U(l),按照下面公式,计算新的聚类中心矩阵V(l+1)得:vi(l+1)=(Σi=1n(uij(l))mxiΣi=1n(uij(l))m)-2m-1.]]>4)判断阈值,根据给定的阈值ε,如果||V(l+1)-V(l)||≤ε,则停止迭代,否则l=l+1,并跳转到第2步继续迭代。根据上述的算法,获取得到的聚类中心值。根据得到的聚类结果,取最低的两个聚类中心值求平均值,在作业周期内,对低于平均值的连续线段的时间清零,高于平均值的连续线段的时间即为各个作业周期中确定的作业与非作业的时间长度。为了进一步划出作业周期,将对应的作业状态下与非作业状态下的连续线段的最后时间点求和计算两者的中间点,作为最后作业周期的分段点。然后统计作业周期的个数,即为作业斗数。根据决策分析,就可以得到该时间段内作业斗数值,然后进行是否提取斗数判断,如果作业斗数为0,保留原始采集数据,调整定时长度,继续进行人机交互、通信处理和报警处理等后续处理;如果提取得到作业斗数,则将作业斗数进行叠加,并依据作业斗数划分的位置,将数据进行数据分离,将最后分段出遗留的数据进行保存,参与下次的识别操作,其他数据舍弃。然后统计每斗挖掘时间长度,并与中断定时时间比较,判断是否调整定时长度,需要调整的话就行调整定时长度操作,不需要调整则继续进行人机交互、通信处理和报警处理等后续处理。最后程序回到数据采集,继续进行下一次的循环操作。上述实施例仅是用来说明本发明,而并非用作对本发明的限定。只要是依据本发明的技术实质,对上述实施例进行变化、变型等都将落在本发明的权利要求的范围内。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1