基于独立子空间的多方向KICA间歇过程故障监测方法与流程
本发明涉及一种故障检测与诊断技术领域,具体为一种基于独立子空间的多方向kica间歇过程故障监测方法。
背景技术:
ica(independentcomponentcorrelationalgorithm,独立成分分析)对工业生产过程的非高斯数据的解决提供了方法,提高了故障监测的准确性和普遍性。间歇过程不同于普通过程,具有多批次的特点,而批次间没有明显区分,每个批次的时间也很不固定。间歇过程的生产速率、生产状况等又是无规则变化。这种生产状况让工人们处理起来很棘手,所以希望降低这种不规则变化,使生产过程尽量有规则可寻,对间歇过程的监测可行有效。
针对生产过程数据的繁重性,传统的kica(kernelindependentcomponentcorrelationalgorithm,核独立成分分析)直接对数据分析,固然可以监测到数据的整体信息。但整体的控制限只能体现出整体的性能,对于某一局部情况并不能清楚地表达,有些故障只与极少数变量有关,或者很少被采样,很容易就被整体数据稀释了,导致监测效果不明显或者根本就监测不出来,造成监测率的下降。
技术实现要素:
针对现有技术中传统的kica直接对数据分析存在监测效果不明显或造成监测率的下降等问题,本发明要解决的问题是提供一种可有效的掌握局部信息、提高故障的监测率基于独立子空间的多方向kica间歇过程故障监测方法。
为解决上述技术问题,本发明采用的技术方案是:
本发明一种基于独立子空间的多方向kica间歇过程故障监测方法,包括以下步骤:
1)采集间歇过程三维数据x(i×j×k),应用多向kica,将三维数据按批次展开成二维数据进行处理;其中i为批次数目,j为变量数目,k为采样点数目;
2)对按批次展开的二维数据进行离线建模,在ica的基础上加入核技巧,将非线性数据映射到高维特征空间,然后在高维空间进行线性处理;
3)应用t2和spe统计量对过程进行在线监测;将每一子数据得到的故障信息进行汇总,计算统计量是否超限。
对按批次展开的二维数据进行离线建模包括以下步骤:
2.1)训练间歇过程三维数据x进行数据标准化处理,得到标准化后的数据x′;
2.2)计算标准化后的数据x′的非高斯分布的独立元s;
2.3)根据独立元信息划分k个子数据空间;
2.4)分别对每个子空间进行kica建模。
步骤2.3)中,根据独立元信息划分k个子数据空间为:根据独立元信息s1,s2,s3,...sk求取出对其贡献度最大的数据
步骤2.4)中,分别对每个子空间进行kica建模为:
2.4.1)对第i个子数据空间κi来进行kica建模分析,对于第i个子数据空间,其过程变量为
2.4.2)通过非线性映射将标准化后的子空间过程数据
首先求出其协方差矩阵,表达式为:
表示为:c=(1/l)φφt
加入核函数k(·)来辅助计算,取核函数为:
其中,k∈rl×l,l=1,2,…l,l为常数,l为变量名,m=1,2,…l;
对核矩阵进行标准化处理得到的结果为:
式中,il为常数矩阵,其元素均相等,为1/n;
对核矩阵进行标准化处理为:
对
式中,λ′为
λ′1≥λ′2≥…≥λ′d(2.38)
所对应的特征向量为:
α1,α2,…,αd(2.39)
定义最高的维数的特征值个数,需要满足:
得到协方差矩阵c的d个特征值分别为λ1′/l,λ2′/l,…,λd′/l,相应的特征向量为v1,v2,…,vd,具体关系如下:
简写成:
v=φ·h·λ-1/2(2.42)
其中v=[v1,v2,…,vd]为特征向量矩阵,λ=diag(λ1,λ2,…,λd,)和h=[α1,α2,…,αd]分别为
令白化矩阵为p,则:
ptcp=i(2.45)
在特征空间中白化后的数据阵为:
由式(2.46)得到:
那么得到独立元y为:
步骤3)中应用t2和spe统计量对过程进行在线监测包括以下过程:
3.1)采集实时间歇过程数据xnew;
3.2)数据预处理,求独立元s,划分k个子空间;
3.3)对每个子空间kica建模并计算每个子空间中的数据的t2和spe统计量;
3.4)汇总计算统计量是否超限。
步骤3.3)中对每个子空间kica建模并计算每个子空间中的数据的t2和spe统计量,是采用t2统计和spe统计进行控制限的计算,其中采用t2统计计算控制限具体为:
对于第1~k个子数据空间,其hotelling-t2统计定义为:
将上式展开得到:
其中,y为独立元,d为核矩阵特征值的对角阵;
采用核密度估计的方法,随机变量y的独立同分布样本为y1,y2,…,yn,其概率密度函数为f(y),k(·)为核函数,hn为光滑系数,为一个常数,与样本数n有关,且hn>0,则:
由核密度估计方法计算出的概率密度函数,对它起作用的参数分别为样本数量、核函数和光滑系数的选取,其中对于已知的样本容量,通过光滑系数hn的大小和核函数k(·)的形式得到概率密度;对于核函数的选取需要满足三个条件:k(y)=k(-y);k(y)≥0;∫k(y)dy=1;
通过均方误差选择最优光滑系数,即估计的方差和偏差的平方和:
n为样本总数,u为相关变量,o为数学中无穷小量的符号;
据此得出最优的光滑系数hn的表达式:
此时,mse为最小,以n-4/5的速率趋于0;hopt以速率n-1/5→0收敛;
其中,高斯核函数
hn=cn-0.2δ
其中c=1.06,对应于高斯核函数的一个常数,δ是采样的标准差,n为样本总数;
通过计算正常数据的t2统计量,估计出对象的概率密度分布,再根据概率统计知识得到占据概率密度函数f(y)99%区域的上边界,边界这一点的值即为t2统计量的控制限。
用spe统计计算控制限,具体为:
其中,
对于一个新的k时刻的采样xnew∈xnew,首先对其进行规范化得到x″new,然后再经过子空间划分,得到第i个子数据空间的过程数据为
t2统计量为:
spe统计量为:
其中
对于每个子数据的监测结果,即对于第i个子数据空间,如果t2统计量超限,将其标为1,否则为0,于是得到如下公式:
s.t.1≤i≤m
对于spe统计量,相应的给出公式:
s.t.1≤i≤m
对于每个子数据空间的显示结果,用一种权重累加的方法,将统计结果合在一起,对于t2统计量,结果如下:
对于spe统计量,结果为:
式中,σi为第i个空间统计量所占的权重,且
在确定第i个空间统计量所占的权重σi时,用指数函数形式,
其中,tos为t2或spe统计量,tosl为其对应的控制限;然后再对σ′i进行归一化处理,得到σi。
本发明具有以下有益效果及优点:
1.本发明针对于间歇过程的多批次问题,使其数据成为三维数据阵,应用多向kica,有效的将三维数据展开成二维数据进行处理;在传统ica的基础上加入核技巧,将非线性数据映射到高维特征空间,然后在高维空间进行线性处理,应用kica对数据进行处理分析,之后应用t2和spe统计量对过程进行在线监测;对传统kica整体处理的方法改进,对初始数据进行了数据切分,划分为多个子空间,针对于每一个数据的子数据空间进行详细的kica分析,建立多模型的kica同时监测,将隐藏信息放大,有效的掌握局部信息,提高故障的监测率。
2.本发明对间歇过程中具有多批次、非高斯特点的数据通过划分子空间分别监测,克服了之前数据属于不同批次的复杂影响和传统kica方法中控制线只能体现整体性能而出现少数故障被整体数据稀释所导致的监测不理想现象。
3.本发明与以往的随机空间rsm划分不同,是根据数据的独立元信息,对数据进行有选择的划分,使每个子数据空间具有差异性和有效性,然后对于故障的监测,本发明把每一子数据得到的故障信息进行汇总,使监测效果更加一目了然。
4.本发明方法通过子空间多模型同时监测,能够起到很好的效果;最后对青霉素发酵过程中错误操作改变输入量的底物流加速率和错误操作改变输入量的空气流量这两类故障数据的监测验证本方法的有效性。
附图说明
图1为青霉素发酵示意图;
图2为间歇过程的多方向按批次展开示意图;
图3a为独立元分析示意图;
图3b为子空间之间没有公共部分但无遗漏数据的划分方法示意图;
图3c为子空间可以有交集也可以遗弃数据的划分方法示意图;
图4为子空间划分示意图;
图5为本发明具体实施方式中的离线数据建模流程图;
图6为本发明具体实施方式中的在线数据故障监测流程图;
图7a为故障一在传统处理方式下随机空间划分方法的t2统计量曲线图;
图7b为故障二在传统处理方式下随机空间划分方法的spe统计量曲线图;
图7c为故障一在本发明处理方式下基于独立子空间划分的多方向kica方法的t2统计量曲线图;
图7d为故障一在本发明处理方式下基于独立子空间划分的多方向kica方法的spe统计量曲线图;
图7e为本发明中各个独立子空间中t2统计量曲线图;
图7f为本发明中各个独立子空间中spe统计量曲线图;
图8a为故障二在本发明处理方式下基于独立子空间划分的多方向kica方法的t2统计量曲线图;
图8b为故障二在本发明处理方式下基于独立子空间划分的多方向kica方法的spe统计量曲线图。
具体实施方式
下面结合说明书附图对本发明作进一步阐述。
本发明一种独立子空间划分的多方向kica间歇过程故障监测方法,包括以下步骤:
1)采集间歇过程三维数据x(i×j×k),应用多向kica,将三维数据按批次展开成二维数据进行处理;
2)对按批次展开的二维数据进行离线建模,在ica的基础上加入核技巧,将非线性数据映射到高维特征空间,然后在高维空间进行线性处理;
3)应用t2和spe统计量对过程进行在线监测;将每一子数据得到的故障信息进行汇总,计算统计量是否超限。
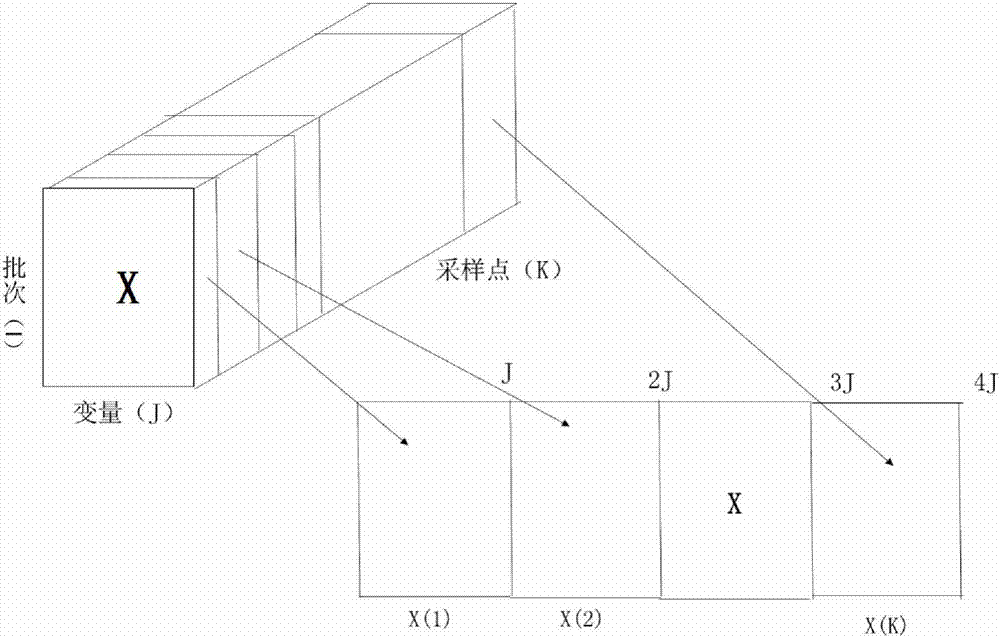
步骤1)中,如图2所示,获取间歇过程的三维过程数据x(i×j×k),其中i为批次数目,j为变量数目,k为采样点数目。将每一个批次当作一个方向,将时间和过程变量的数据揉合在一起组成新的二维数据,从而转化为二维矩阵x(i×kj),那么这样该二维矩阵的每行都包含一个批次的所有数据。同样的变量展开之后依然要进行数据标准化处理,这需要对过程变量的不同批次、不同采样时刻以及不同变量的标准化处理,这样能方便数据处理,同时也保留了数据特征。
步骤2)中,对按批次展开的二维数据进行离线建模包括以下步骤:
2.1)训练数据集x进行数据标准化处理,得到标准化后的数据x′;
2.2)计算标准化后的数据x′的非高斯分布的独立元s;
2.3)根据独立元信息划分k个子数据空间;
2.4)分别对每个子空间进行kica建模。
步骤2.1)中,对数据进行标准化处理,即将每个变量都变为平均值为0,方差为1的标准化变量。具体步骤如下:
2.1.1)多方向展开后得到的训练数据集x为:
其中,xi(i=1,2,...,n)为一组采样列向量。
由此可以得到标准化后的过程变量矩阵,为:
其中,xi,j为原数据矩阵中的一个元素,x′i,j为经过标准化后的数据矩阵中的一个元素,xj为j列元素,
2.1.2)求出样本的协方差矩阵s:
其中,x′为标准化处理以后的过程数据。
2.1.3)得出协方差矩阵之后,继续将协方差矩阵ss进行特征值分解,p可以表示为:
ss=pλpt(2.7)
其中,对角阵λ包含非负特征值λ1≥λ2≥...≥λi≥0,λi是第i个的特征值,m为特征值个数,p为x′的负载向量,由特征值λi对应的单位化特征向量构成,并且ptp=i,i是单位矩阵。
2.1.4)求出得分矩阵t
选择一个负载矩阵p∈rm×l的列,使其与前l个特征值相关联的负荷向量相对应,则x′到低维空间的投影就包含在得分矩阵t中:
t=x′p(2.8)
主元个数的选择是十分重要的,通常选取l(l<m)个主成分来代替原m个相关变量,这l个主成分就可以代表原m个变量所包含的信息。通常采用主成分累积贡献率超过85%来保留主元的个数,如下式
将标准化后的数据x′分解为外积之和的形式,如下式所示
其中,ti∈rn称为得分向量(scorevector),也称为主成分;pi∈rm称作负载向量(loadingvector),代表主成分的投影方向。将上式转化为矩阵形式,为:
x′=tpt(2.11)
其中,t=[t1t2…tm]称为得分矩阵,p=[p1p2…pm]称为负载矩阵。
2.1.5)得出ica模型求取独立元信息
由2.1.4)得出
x′=as(2.12)
式中,
s=a-1x′(2.13)
取a的逆矩阵w,w∈rk×n,w为解混矩阵,所以式3.13可以写成:
s=wx′(2.14)
现在的目的就是求取解混矩阵w。本实施例利用微分熵准则,假设y是一随机向量,其概率密度为p(y),则y的微分熵为:
所以y的负熵为:
j(y)=h(yg)-h(y)(2.16)
由于在实际当中计算负熵很难做到,为了方便计算,对于式(2.16),取j的近似表达式:
j(y)≈τ[e{g(y)}-e{g(yg)}]2(2.17)
式中:τ是一个常数,τ>0,g(·)为任意非二次函数。
所以就可以得到如下表达式:
j(s)≈k[e{g(wtt)}]2-2k*e{g(wtt)}*e{g(sg)}+k[e{g(sg)}]2(2.18)
式中sg=wtt,可以得到使j达到最小的w。求出解混矩阵w为:
所以就可以求出s。
s=[s1,s2,…,sk](2.20)
关于子空间划分如图4所示,步骤2.3)中,根据独立元信息划分k个子数据空间为:根据独立元信息s1,s2,s3,…sk求取出对其贡献度最大的数据
围绕每个独立元划分子数据空间,很好的解决了差异性的问题,因为独立元信息批次之间独立,信息差别较大,围绕独立元信息建立的子空间自然就有了差异性,而随机划分并没有这一性质。
构建独立元的相似度矩阵
由式(2.14)可以得到:
所以,对于第i个独立元si,可以表示为:
si=wi1×x1′+wi2×x2′+…+win×xn′,(2.22)
其中:i=1,2,…k。
为了围绕si建立子数据空间,选出最能表达出si信息的数据量,由于s与x的维数不同,不方便直接求取相似性,所以先要选出对si贡献度最大的数据,最接近si的
取贡献度最大的那个数据代表si,所以相应的
其中j为使μij取得最大值所对应的j,若xsi重复选取,则顺延至使μij取得第二大值的j,以此类推,得到能够代表各个独立元信息的数据集xs′,
现在来建立子数据空间κi,对于整个过程变量x1′,x2′,x3′,…,xn′,分别求取其与
这样对整个
由此,对于所有独立元信息s1,s2,s3,...sk和所有过程变量x′1,x′2,x′3,…,x′n,给出相关度矩阵为:
由式(2.28)可知,得到的rij越大,就表示所对应的x′j与独立元si的相似度越大,这样这个变量信息就能更清楚地体现出独立元si的特征信息。再用这样的一个子空间数据集来建模分析,就能详细的监测出在这个方向上的故障信息,这样就能很有针对性的监测出各个方面的故障信息,细致的了解系统内部的具体情况,使监测效果有了很大的提高。
只需要根据已经得到的相似度矩阵,就可以划分出想要的子数据空间。这样得到的子数据空间κ1,κ2,κ3,…κk就能很好的表示出s1,s2,s3,...sk的信息,同时也满足了前面对各子空间差异性和有效性的要求。差异性很好理解,因为独立元s1,s2,s3,...sk本身就是彼此相互独立的,所以它们之间有很大的差异性,所以围绕它们建立的子数据空间,自然就体现了不同独立元各自的特性,也就具有了明显的差异性;关于有效性,建立的子数据空间有足够的数据量,而且建立的时候也按照了有效的标准,保证了有效性。
本实施例以构建子数据空间κi为例,具体的方法为:
取相似度矩阵的第i行ri1,ri2,ri3,…rin,i=1,2,…k,对应的每个相关系数表示了对于独立元信息si分别与每个过程数据x′1,x′2,x′3,…,x′n的相似度情况,选取与si相似度高的l个数据成立子数据空间κi,也就是说对于每一行,都要对相似度做一个排名,可以得到如下:
则所对应的l个x′变量
i由1到k,重复这个过程,就可以构建出1~k个子数据空间κ1,κ2,κ3,…κk。
关于每个子数据空间的大小,也就是常数l的选取,并不是随意选取的。l选取过大,则每个子数据空间的数据量过多,这样每个子数据空间的计算量也会很大,差异性不是很明显,并不能很好的体现出局部的详细信息;如果l选取过小,则每个子数据空间的数据量过少,空间过小又遭成了数据单一性太强,没有合理的有效性。所以,关于l的选取,本发明采用的方法是:
首先,求出对于每个独立元信息si的相似度绝对值均值如下:
然后,计算出相似度大于均值的个数ui,对于每一个独立元信息都做这样的运算,得到u1,u2,u3,…uk,,然后得到
其中,
根据一个由累计相似度组成的优化不等式:
由此求出满足不等式的最小的l,这样能保证有足够的信息,满足有效性,同时也满足了各个子数据空间的差异性。
步骤2.4)中,如图5所示的离线数据建模流程图,分别对每个子空间进行kica建模为:
2.4.1)对第i个子数据空间κi来进行kica建模分析。对于第i个子数据空间,其过程变量为
2.4.2)通过非线性映射将标准化后的子空间过程数据
此特征空间的协方差矩阵是一个单位矩阵,可以表示c为c=(1/l)φφt,在特征空间中,需要求出c的特征向量,由于数据的非线性,给计算造成很大的麻烦,无法直接得到φ(·)函数,为将原始数据映射到高维空间的映射函数,所以在此加入核函数k(·)来辅助计算。核函数有很多种方式,在本发明中,取核函数为:
其中,k∈rl×l,l=1,2,…l、m=1,2,…l。然后对核矩阵进行标准化处理得到的结果为:
式中,il为常数矩阵,其元素均相等为l,对核矩阵进行标准化处理为:
接下来对
式中,λ′为
λ′1≥λ′2≥…≥λ′d(2.38)
所对应的特征向量为:
α1,α2,…,αd(2.39)
在理论上,非零特征值的数目等于最高的维数,在这里定义了最高的维数的特征值个数,需要满足:
得到c的d个特征值分别为λ′1/l,λ′2/l,…,λ′d/l,相应的特征向量为v1,v2,…,vd,具体关系如下:
式(2.41)可以简写成:
v=φ·h·λ-1/2(2.42)
其中v=[v1,v2,…,vd]为特征向量矩阵,λ=diag(λ1,λ2,…,λd,)和h=[α1,α2,…,αd]分别为
令白化矩阵为p,则:
ptcp=i(2.45)
得到白化矩阵之后,就可以得到在特征空间中白化后的数据阵为:
详细的,由式(2.46)可以得到:
那么独立元y为:
步骤3)中,如图6所示,应用t2和spe统计量对过程进行在线监测包括以下过程:
3.1)采集实时间歇过程数据xnew;
3.2)数据预处理,求独立元s,划分k个子空间;
3.3)对每个子空间kica建模并计算每个的t2和spe统计量;
3.4)汇总计算统计量是否超限。
步骤3.3)中,对每个子空间kica建模并计算每个的t2和spe统计量,是采用t2统计和spe统计进行控制限的计算,具体为:
对于第1~k个子数据空间,其hotelling-t2统计定义为:
将上式展开,得到:
对于kica建模分析来说,独立元信息s通常是不服从高斯分布的,所以在计算t2统计控制上限时,不能用f分布直接进行计算。这里采用核密度估计的方法。
随机变量y的独立同分布样本为y1,y2,…,yn,其概率密度函数为f(y)。k(·)为实数域上一个给定的概率密度函数,hn是一个常数,与样本数n有关,且hn>0。记:
所以未知的密度函数f的一个核密度估计就是fn,k(·)表示核函数,hn称为光滑系数,由式(2.51)可知,由核密度估计方法计算出的概率密度函数,对它起作用的参数分别为样本数量、核函数和光滑系数的选取。
对于已知的样本容量,只要有了光滑系数hn的大小和核函数k(·)的形式,就可以得到概率密度。对于核函数的选取需要满足三个条件:k(y)=k(-y);k(y)≥0;∫k(y)dy=1。常用的核函数有多项式核(polynomial)、均匀核(uniform)、高斯核(gaussian)、三角核(triangle)等。
在选定核函数之后,接下来就是求取光滑系数hn。对于hn的选取很关键。从理论上讲,hn会随着样本个数n→∞而趋于0。当hn的取值太小时,随机性的影响会加强,使得fn(y)呈现很不规则的形状,从而屏蔽了其的重要特性;反之,hn选取过大时,fn(y)将会过度光滑,从而无法显露f(y)的比较细致的性质。均方误差(mse)是一个选择最优光滑系数的常用的原则,即估计的方差和偏差的平方和:
由上面的式子可以得到,hn的值越大,数据的方差就越大,拟合越不光滑;hn的值越小,方差就越大,这时候拟合就太过于光滑了。据此得出最优的光滑系数hn的表达式:
此时,mse为最小,以n-4/5的速率趋于0;hopt以速率n-1/5→0收敛。
这里的核函数选用高斯核函数
通过计算出正常数据的t2统计量,就能估计出对象的概率密度分布,再根据概率统计知识得到占据密度函数f(y)99%区域的上边界,边界这一点的值即为所求的t2统计量的控制限。
在计算完t2统计量之后,求出第1~k子数据空间的spe统计量的计算,具体过程如下:
其中,
为了实现对过程的监控,对于一个新的k时刻的采样xnew∈xnew,首先对其进行规范化得到x″new,然后再经过子空间划分,得到第i个子数据空间的过程数据为
t2统计量为:
spe统计量为:
其中
对于每个子数据的监测结果,为了方便计算,用0表示正常情况,用1表示发生故障,也就是说,对于第i个子数据空间,如果t2统计量超限,就将其标为1,否则为0,于是可以得到如下公式:
s.t.1≤i≤m
对于spe统计量,相应的给出公式:
s.t.1≤i≤m
对于每个子数据空间的显示结果,逐个观察太麻烦,需要想个办法将结果汇总,统一观察。本发明采用一种权重累加的方法,将统计结果合在一起,对于t2统计量,结果如下:
对于spe统计量,结果为:
式中,σi为第i个空间统计量所占的权重,且
a.在确定权重的时候,对于在各自子数据空间内,其t2和spe统计量没有超限的子空间,在总的汇总当中应该有较小的权重,几乎不对总的输出结果其作用,对于在各自子数据空间内,其t2和spe统计量超过限值的子空间,在总的汇总结果里应该占有较大的权重,对输出结果起主要作用。这样就能保证无故障的空间不会产生干扰,有故障的空间凸显的效果明显。
b.权重值要跟每个子数据空间有关,不是凭空写出来的,这样能保证联系的紧密型。并且对于过度超限值的情况,所占的权重不能无限大,避免一个空间决定最终结果,有效的避免偶然性,所以不能直接采用比例函数形式,应该选用指数函数形式。
c.对于限值的选取,如果过大,会造成结果不明感,故障监测效率不高,如果过小,则过于敏感,会产生误报的情况。由于在实际情况中,有些故障会在很多个子空间里体现出来,这种比较明显,很容易监测。而有些故障只在很少数几个子空间里有体现,这种就算比较隐蔽的了,需要有很小的限值δ才能监测出来。所以,为了能够体现出这个算法的优势,充分体现出局部的详细信息,本发明选取一个较小的δ值。该δ值如果过大,会造成结果不明感,故障监测效率不高,如果过小,则过于敏感,会产生误报的情况。同时有些故障只在很少数几个子空间里有体现,因此需要有很小的限值δ才能监测出来。
所以为了满足以上3点的要求,本发明给出了一种权重的计算方法,如下:
其中,tos为t2或spe统计量,tosl为其对应的控制限。然后再对σ′i进行归一化处理,得到σi。
本实施例以青霉素发酵过程为工业背景,青霉素发酵示意图如图1所示。对非线性间歇过程故障检测进行研究。采用青霉素benchmark模型,应用pensim仿真系统生成仿真数据。在青霉素发酵过程的每个批次时间约为300小时,本实施例选择的采样间隔为0.1小时,在每个发酵过程共采集3000个数据样本点。每个样本点有16个过程变量,也就是需要对发酵过程进行控制的16个量,有一个发生改变就会产生故障。
本实施例采集50个正常批次的数据作为训练数据,得到一个三维数据x(50*16*3000),由此可以进行离线建模。在按照本发明方法建立子空间多模型kica分析之后,选择两组有故障的数据进行仿真分析:
故障一:在选定的一个批次中,引入由于错误操作改变输入量的底物流加速率,从而形成故障,这是一个阶跃故障。并且底物流加速率的改变影响的变量很少,而且是在发酵过程的第二阶段才起作用的一个变量,它的改变不容易在结果中体现出来,属于一种局部故障。实验中在第200个采样点引入此故障,并且故障持续到第500个采样点情况下,图7a、7b分别为传统随机空间划分方法的t2和spe示意图。图7c与7d分别为本发明提出的基于独立子空间划分的多方向kica方法对于故障一的监测情况的t2统计量和spe统计量示意图。图7e与7f分别是本发明划分出来的各个独立子空间中t2统计量和spe统计量;
故障二:选定另一个批次,引入由于一个错误操作改变输入量的空气流量,这是一个阶跃故障。空气流量的改变对整个发酵过程的温度、溶解氧浓度、ph值等都有影响,属于一个影响比较广泛的变量。因此这个故障时比较容易体现出来的,属于全局性故障。此故障的引入时间为第300个采样点,也是持续到第500个采样点情况下,图8a与8b分别为本发明提出的基于独立子空间划分的多方向kica方法对于故障一的监测情况的t2统计量和spe统计量;
对于故障1的监测,根据对比传统随机空间划分方法和本文提出的基于独立子空间划分的多方向kica方法,由图7a和7b看出在t2和spe统计量中,都可以监测到故障的发生。但是这两个有一个共同点就是故障的发生有些延迟,可以看到大约在第210个采样点处统计量才超过控制限。并且无论是得分统计还是残差统计的波动都很大,在200采样点之前,大约在50、80和175采样点处都出现了超过控制限的波动,这是由于发酵过程中系统的波动引起的,尽管可以通过设置报警系统避免这种干扰,但难免会有更大的波动造成误报的现象。而在故障发生之后,有些波动造成了统计量又降至控制限之下,尽管对整体监测效果没有实质性的影响,但也会对输出结果造成干扰。总体来说,传统方法对于故障1的监测有效,但有延迟、有波动,效果一般。由图7c和7d看出本发明提出的新的空间划分方法对于故障1的监测效果,由于在各个空间汇总时加入了权重分配,时没有超限的空间所占比例小,超限空间所占比例大,使整体输出结果小的更小,大的更大。由图7c和7d看出中显示的很清楚,阶跃效果非常明显,故障发生之前与之后的统计量差距非常大,并且在第200采样点多一点点,也就201个或202个采样点处就发生阶跃跳变,几乎没有延迟。并且统计量的整体波动很小,偶有几个比较大的波动也远不及控制限,对输出结果没有干扰。其中在200采样点之前的波动是由于在个别超限的空间中有较大的统计量值,所占的比例较大使结果产生波动。而在200采样点之后也产生了一些波动,是由于在有些空间中没有达到控制限,导致所占比例很小,小而又小就造成了波动。但总体来说,本发明方法能够有效的监测出故障1,并且波动小,没有干扰,可以说效果非常好。
关于子空间,从图7e和7f中可以看到,在子空间1和4(即图7e及图7f中的subspace1和subspace4)中,几乎监测不到故障的发生;在子空间5(即图7e及图7f中的subspace5)中,200采样点之后虽然能够达到控制限之上,但并没有整体超过,其结果很不稳定;而在子空间2、3和6(即图7e及图7f中的subspace2、subspace3和subspace6)中,能够很好地监测出故障的发生。当将图片放大看的时候,可以看到监测出故障发生的点有的空间是在200个采样点就发生阶跃变化,而有的空间在203和205采样点发生阶跃变化,这说明在不同的空间中,故障的发生时间略有不同。整体来看,造成不同空间中监测结果不同的原因就是本文的空间划分方法是按照独立信息来划分的,每个空间的差异性很大。改变底物流速率影响到了有些变量,对另一些变量并没有影响,所以就造成了有的空间没有故障发生,而有的空间故障发生明显。由于发生故障的子空间所占的权重比较大,所以就很好的在总的统计量上体现了出来。这就说明了本文提出的方法对于这些对于少量变量产生影响的故障监测效果的优越性,提高了监测效率,降低了波动干扰,是一种十分有效的方法。
对于故障二的监测,两种方法(如图8a、8b所示,8a为传统随机空间划分方法,8b为本文的独立信息空间划分方法)对故障2的监测效果都很好,本发明方法依然更佳,其故障相应时间没有延迟,整体波动也非常小。尽管偶有干扰,但对结果没有任何影响。
- 还没有人留言评论。精彩留言会获得点赞!