一种基于LSTM和MLP结合的化工过程故障诊断方法与流程
本发明涉及化工过程故障诊断方法,特别是一种基于lstm和mlp结合的化工过程故障诊断方法。
背景技术:
化工是国家发展的基础行业,同时也具有较大的危险性,一旦出现故障,将会造成不可估量的损失,因此能够准确高效的进行化工过程故障诊断是化工行业安全运行平稳发展的基础。随着机器学习与人工智能的迅猛发展,深度学习技术随之诞生,且在图像、文本以及语音等领域广泛运用,深度学习借助其强大的学习能力在故障诊断方面也取得了新的研究进展。不同的网络都有各自不同的优缺点,需要针对对象有目标的搭建合适的深度学习网络模型进行故障诊断。作为典型的深度学习网络,长短期记忆网络(lstm)和多层感知器(mlp)在故障诊断上的研究取得了一定的进展,且lstm的长期记忆能力,正好适用于化工过程中非线性、强耦合、高维、时变的数据。
技术实现要素:
本发明针对现有技术的不足,提供了一种基于lstm和mlp结合的化工过程故障诊断方法。
本发明的技术方案:
a.将原始一维数据通过降维,去掉部分冗余数据点。
b.将得到的一维数据输入堆叠的lstm,提取得到具有时间特性的特征信息。
c.通过flatten层将lstm的输出数据展开,输入到由全连接层堆叠而成的mlp中,进行下一阶段的特征提取。
d.由最后一层全连接层中的softmax分类器进行故障类别的分类。
本发明的有益效果:与传统的故障诊断算法相比,本发明不需要人为手动提取特征,也不需要与相关领域的专业知识。与其他深度学习模型相比,卷积网络与单纯的mlp网络,不具备时间记忆功能,只能提取空间特性,循环网络存在比较多的缺陷,而化工过程是一个连续的整体过程,所以存在很大的时间关联性和时变性。本发明提出的方法,充分利用了lstm与mlp网络在时间与空间方面特征提取的优势,先利用lstm网络进行时间记忆特征信息的学习,由于lstm计算量大,速度慢,不宜大量堆叠使用,而mlp网络则相对简单,特征学习能力也很强,所以在两层lstm后便使用mlp网络去进行整体的特征提取与学习,可以针对性的运用于非线性、高耦合、时变以及多特征点的化工过程数据,诊断效果较好。
附图说明
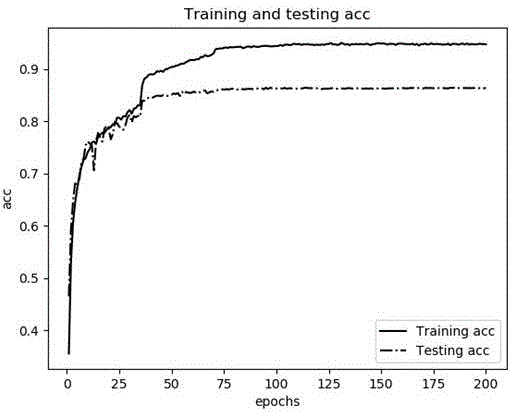
图1为训练集与测试集准确率;
图2为训练集与测试集损失。
具体实施方式
以下结合附图对本发明作进一步说明。
一种基于lstm和mlp结合的故障诊断方法,按下述步骤进行:
a.将原始一维数据通过一定技术降维,去掉部分冗余数据点;
b.将得到的一维数据输入堆叠的lstm网络,提取得到具有时间特性的特征信息;
c.通过flatten层将lstm的输出数据展开,输入到由全连接层堆叠而成的mlp中,进行下一阶段的特征提取;
d.由最后一层全连接层中的softmax分类器进行故障类别的分类。
前述的基于lstm和mlp结合的化工过程故障诊断方法所述步骤b中,在lstm网络中提取得到具有时间记忆特性的特征信息具体过程如下:lstm单元包括记忆细胞ct和三个门限:输入门it、遗忘门ft和输出门ot。当输入序列为xt时,三个门限和记忆细胞的输出如下:
其中whf、whi、who、whc分别表示遗忘门、输入门、输出门、记忆细胞它们与上一隐含层之间的权重矩阵,ht-1为前一时刻单元的输出,wxf、wxi、wxo、wxc分别表示输入与遗忘门、输入门、输出门、记忆细胞之间的权重矩阵,bf、bi、bo、bc分别表示遗忘门、输入门、输出门、记忆细胞的偏置,σ为sigmoid函数,在本发明中此lstm网络模型由两层lstm堆叠而成,为了避免过拟合,在每层lstm网络中加入了随机丢弃机制以及l2正则化。
前述的基于lstm和mlp结合的化工过程故障诊断方法所述步骤c中,在mlp网络中提取特征信息具体如下:在mlp输入层将之前lstm的输出展开为x1,x2,x3...化为向量x[1],mlp输入层到下一层之间权重为w1,w2,w3...化为向量w[1],其中1表示mlp第一层的权重,偏置b[1]同理,则第一层的计算为z[1]=w[1]x+b[1],之后a[1]=sigmoid(z[1]),其中z[1]为输入的线性组合,a[1]为z[1]通过激活函数sigmoid得到的值,对于mlp第一层的输入为x[1],输出为a[1],也就是下一层的输入值,即x[2]=a[1],依次类推到下一层,本发明mlp网络由五层全连接网络堆叠而成。为了避免出现过拟合,加强模型泛化性能,在每两层全连接层之间加入随机丢弃层,同时在每一个全连接层中加入l2正则化,并且采用he_normal作为权重的初始化方法。
前述的基于lstm和mlp结合的化工过程故障诊断方法所述步骤d中,通过softmax分类器进行故障类别的分类具体如下:选择softmax作为最后一层全连接层的激活函数,用于计算样本属于不同类别的概率,对于给定的输入x,利用函数针对于每一类别j估算出概率值p,并最终输出诊断结果。随后softmax的输出向量[y1,y2,y3...]和样本的实际标签做交叉熵计算,公式如下:
为了验证本发明的有效性,采用田纳西-伊斯曼(te)过程数据集进行下述实验:
数据简介
te过程是由美国eastman化学公司提出的一个化工仿真过程模型,其中包含41个测量变量和12个控制变量,所有的过程测量值都包含高斯噪声,预设定21种故障,其中16个是已知的,知道故障的具体形式,5个是未知的,不知道故障的具体形式,且故障1至7与过程变量的阶跃变化有关,故障8至12与一些过程变量的可变性有关,故障13是反映动力学中的缓慢漂移,故障14、15、21是与阀粘滞有关。训练集样本与测试集样本的采样间隔都为3分钟,每个故障的训练集由480个样本构成;测试集由960个样本组成,每个预设故障是在160个样本后开始被引入。在此先将所有测试集与训练集数据标注好后随机打乱混合,并选择52个特征点中的46个区分性较强的特征点进行试验,再按照80%和20%的比例重新划分训练集与测试集。
激活函数与优化器的选择
随着深度学习技术的发展,激活函数一不仅仅是sigmoid、tanh等了,专家学者针对于每个激活函数缺陷进行了一定的改进,在此选择运用较为广泛,功能也较为强大的elu作为mlp网络的激活函数。如今现有的优化器也是多样的,也都有各自的优缺点,需要根据实际情况去选择,此试验中选择adam作为优化器,此优化器功能相对较为强大,运用范围也比较广泛。
构建模型
此处先使用两层lstm网络进行特征提取,随后将提取的特征向量输入mlp网络,mlp网络由五层全连接网络构成,且为了避免过拟合,每两层全连接层之间加入随机丢弃层,在lstm网络中也加入了随机丢弃机制,每一层lstm网络与全连接网络之中都加入了l2正则化项,采用he_normal作为权重初始化方法,最后由一层全连接层进行输出分类,其激活函数为softmax。
实验结果
模型在训练集上训练了200轮,每个批次128个样本,学习率每35轮下降0.1倍,最终结果如图1和图2所示,在测试集上准确率达到了86.3%,测试集损失也降低到0.65。
综上,本发明能够很好的运用于te化工过程数据,准确率、诊断时间以及泛化性能都较好。
- 还没有人留言评论。精彩留言会获得点赞!