基于贝叶斯模型的文本垃圾识别方法和系统与流程
技术特征:
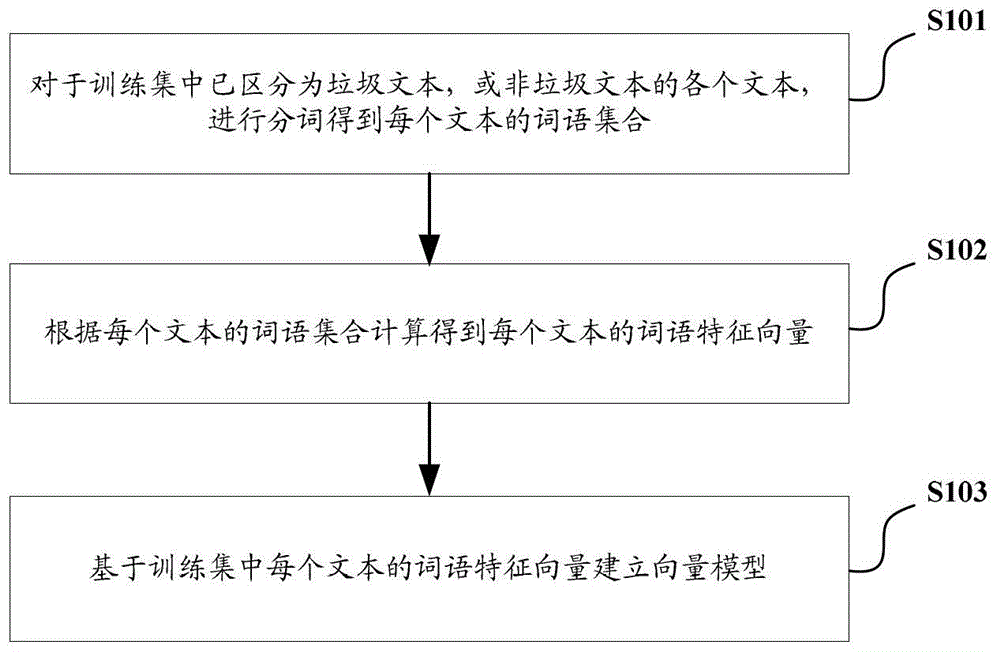
1.一种基于贝叶斯模型的文本垃圾识别方法,其特征在于,包括:对待判定文本进行分词,得到所述待判定文本的关键词;针对所述待判定文本的每个关键词,根据该关键词的TF值和IDF值,计算该关键词的特征值,并在贝叶斯模型中查找与该关键词相匹配的特征词,获取查找到的特征词的正向权重值和负向权重值,分别作为该关键词的正向权重值和负向权重值;其中,所述特征词的正、负向权重值分别指的是所述特征词属于非垃圾文本、垃圾文本的概率权重值,所述贝叶斯模型是应用词语的IDF值确定的;根据所述待判定文本的每个关键词的特征值以及正向权重值,计算所述待判定文本的正向分类值;根据所述待判定文本的每个关键词的特征值以及负向权重值,计算所述待判定文本的负向分类值;其中,所述待判定文本的正、负向分类值分别指的是所述待判定文本为非垃圾文本、垃圾文本的概率权重值;根据所述待判定文本的正向分类值和负向分类值,确定所述待判定文本是否为垃圾文本,具体包括:根据如下公式7,计算出所述待判定文本为垃圾文本的概率:其中,aprioity表示训练集中非垃圾文本的占比;Scoreg表示待判定文本的正向分类值;Scoreb表示待判定文本的负向分类值;根据计算出的概率Pbad,确定所述待判定文本是否为垃圾文本。2.如权利要求1所述的方法,其特征在于,所述贝叶斯模型为预先得到的:对于训练集中已区分为垃圾文本,或非垃圾文本的每个文本,进行分词后得到该文本的关键词,并计算该文本的每个关键词的类别相关度;从所述训练集的各文本的关键词中,选取类别相关度高于设定值的关键词作为所述贝叶斯模型的特征词;针对所述贝叶斯模型的每个特征词,根据该特征词的numg以及所述训练集中非垃圾文本总数,计算出该特征词的正向权重值;根据该特征词的numb以及所述训练集中垃圾文本总数,计算出该特征词的负向权重值;其中,numg为所述训练集的非垃圾文本中包含有该特征词的文本的数量;numb为所述训练集的垃圾文本中包含有该特征词的文本的数量。3.如权利要求2所述的方法,其特征在于,所述计算该文本的每个关键词的类别相关度具体包括:对于该文本的每个关键词,根据如下公式2计算该关键词的类别相关度:其中,T表示该关键词,CE(T)表示该关键词的类别相关度,P(C1|T)表示包含该关键词的文本属于垃圾文本类别的概率,P(C2|T)表示包含该关键词的文本属于非垃圾文本类别的概率,P(C1)表示垃圾文本在所述训练集中出现的概率,P(C2)表示非垃圾文本在所述训练集中出现的概率。4.如权利要求2所述的方法,其特征在于,所述根据该特征词的numg以及所述训练集中非垃圾文本总数,计算出该特征词的正向权重值;根据该特征词的numb以及所述训练集中垃圾文本总数,计算出该特征词的负向权重值,具体包括:根据如下公式3计算出该特征词的正向权重值weightg:根据如下公式4计算出该特征词的负向权重值weightb:其中,word_numg表示所述训练集的非垃圾文本中包含有该特征词的文本的数量;word_numb表示所述训练集的垃圾文本中包含有该特征词的文本的数量;total_numg表示所述训练集中非垃圾文本总数;total_numb表示所述训练集中垃圾文本总数。5.如权利要求1-4任一所述的方法,其特征在于,所述根据所述待判定文本的每个关键词的特征值以及正向权重值,计算所述待判定文本的正向分类值;根据所述待判定文本的每个关键词的特征值以及负向权重值,计算所述待判定文本的负向分类值,具体包括:根据如下公式5计算出所述待判定文本的正向分类值Scoreg:根据如下公式6计算出所述待判定文本的负向分类值Scoreb:其中,n表示所述待判定文本的关键词的总数;word_valuei表示所述待判定文本的n个关键词中的第i个关键词的特征值;word_weight_gi表示所述待判定文本的n个关键词中的第i个关键词的正向权重值;word_weight_bi表示所述待判定文本的n个关键词中的第i个关键词的负向权重值。6.如权利要求1-4任一所述的方法,其特征在于,所述对待判定文本进行分词,得到所述待判定文本的关键词,具体包括:对于待判定文本进行分词后得到的每个词语,确定该词语的词性和IDF值;从对待判定文本进行分词后得到的词语中,选择IDF值高于设定阈值、词性符合预设条件的词语作为所述待判定文本的关键词。7.一种建模方法,其特征在于,包括:对于训练集中已区分为垃圾文本,或非垃圾文本的每个文本,进行如下操作:对该文本进行分词后得到的每个词语,确定该词语的词性和IDF值;从对该文本进行分词后得到的词语中,选择IDF值高于设定阈值、词性符合预设条件的词语作为该文本的关键词;计算该文本的每个关键词的类别相关度;从所述训练集的各文本的关键词中,选取类别相关度高于设定值的关键词作为贝叶斯模型的特征词;针对所述贝叶斯模型的每个特征词,在所述训练集中统计非垃圾文本中包含有该特征词的文本的数量numg,统计垃圾文本中包含有该特征词的文本的数量numb;根据该特征词的numg以及所述训练集中非垃圾文本总数,计算出该特征词的正向权重值;根据该特征词的numb以及所述训练集中垃圾文本总数,计算出该特征词的负向权重值;以及所述贝叶斯模型用于对待判定文本进行垃圾文本识别时,根据待判定文本关键词的TF值和IDF值计算出的所述关键词的特征值进行识别。8.如权利要求7所述的方法,其特征在于,所述计算该文本的每个关键词的类别相关度具体包括:对于该文本的每个关键词,根据如下公式2计算该关键词的类别相关度:其中,T表示该关键词,CE(T)表示该关键词的类别相关度,P(C1|T)表示包含该关键词的文本属于垃圾文本类别的概率,P(C2|T)表示包含该关键词的文本属于非垃圾文本类别的概率,P(C1)表示垃圾文本在所述训练集中出现的概率,P(C2)表示非垃圾文本在所述训练集中出现的概率。9.一种基于贝叶斯模型的文本垃圾识别系统,其特征在于,包括:关键词确定模块,用于对待判定文本进行分词,得到所述待判定文本的关键词;正负向权重值计算模块,用于针对所述关键词确定模块得到的所述待判定文本的每个关键词,根据该关键词的TF值和IDF值,计算该关键词的特征值,并在贝叶斯模型中查找与该关键词相匹配的特征词,获取查找到的特征词的正向权重值和负向权重值,分别作为该关键词的正向权重值和负向权重值;其中,所述特征词的正、负向权重值分别指的是所述特征词属于非垃圾文本、垃圾文本的概率权重值,所述贝叶斯模型是应用词语的IDF值确定的;正负向分类值计算模块,用于根据所述待判定文本的每个关键词的特征值以及正向权重值,计算所述待判定文本的正向分类值;根据所述待判定文本的每个关键词的特征值以及负向权重值,计算所述待判定文本的负向分类值;其中,所述待判定文本的正、负向分类值分别指的是所述待判定文本为非垃圾文本、垃圾文本的概率权重值;判定结果输出模块,用于根据所述待判定文本的正向分类值和负向分类值,确定所述待判定文本是否为垃圾文本,具体包括:根据如下公式7,计算出所述待判定文本为垃圾文本的概率:其中,aprioity表示训练集中非垃圾文本的占比;Scoreg表示待判定文本的正向分类值;Scoreb表示待判定文本的负向分类值;根据计算出的概率Pbad,确定所述待判定文本是否为垃圾文本;并将判定结果输出。10.如权利要求9所述的系统,其特征在于,所述关键词确定模块、正负向权重值计算模块、正负向分类值计算模块、判定结果输出模块包含于所述系统的识别装置中;以及所述系统还包括:建模装置;所述建模装置包括:训练集关键词确定模块,用于对于训练集中已区分为垃圾文本,或非垃圾文本的每个文本,进行分词后得到该文本的关键词;特征词选取模块,用于针对训练集中每个文本,计算该文本的每个关键词的类别相关度;从所述训练集的各文本的关键词中,选取类别相关度高于设定值的关键词作为所述贝叶斯模型的特征词;统计模块,用于针对所述贝叶斯模型的每个特征词,在所述训练集中统计非垃圾文本中包含有该特征词的文本的数量numg,统计垃圾文本中包含有该特征词的文本的数量numb;特征词正负向权重值计算模块,用于根据该特征词的numg以及所述训练集中非垃圾文本的总数,计算出该特征词的正向权重值;根据该特征词的numb以及所述训练集中垃圾文本总数,计算出该特征词的负向权重值。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1