用于阵列处理器的数据推测的制作方法
本公开涉及数据推测(speculation),并且更具体地涉及在处理周期期间结合推测性输入数据利用计算装置的未调度算术逻辑单元(ALU)。
背景技术:
术语“单指令多线程”是指相同处理代码在许多线程(每个线程中具有不同输入数据)中的同时执行。SIMT技术已经被用于阵列处理器,阵列处理器被专门设计为对许多输入重复地执行类似操作。例如,现代图形处理单元(GPU)阵列处理器包括数百或数千个算术逻辑单元(ALU),ALU均能够使用输入向量来计算函数。通过将不同输入向量馈送到不同ALU,可以通过许多输入在一个处理周期内多次计算给定函数。随着GPU继续变得更强大,计算机科学家已经开始使用GPU,GPU通常处理仅针对计算机图形的计算,以在传统上由CPU处理的应用中执行计算。该技术被称为“通用计算图形处理单元”(GPGPU)。然而,在给定处理周期期间,不能利用许多可用ALU。
技术实现要素:
根据本公开的一方面,公开了一种利用阵列处理器的多个算术逻辑单元(ALU)的方法。确定调度第一数量的ALU以在给定处理周期期间执行函数,每个ALU被调度2002-158d为使用多个所选输入向量中的相应一个作为输入。还确定不调度第二数量的ALU用于在给定处理周期期间使用。确定与多个所选输入向量不同的多个预测的未来输入向量。调度第二数量的ALU以使用多个预测的未来输入向量中的相应预测的未来输入向量作为输入在给定处理周期期间执行所述函数。在完成处理周期之后,缓存从第一数量的ALU和第二数量的ALU接收的函数输出。
根据本公开的另一方面,公开了一种计算装置,该计算装置的特征在于:包括多个算术逻辑单元(ALU)的阵列处理器、以及处理电路。处理电路可以在阵列处理器外部或位于阵列处理器内。处理电路被构造为确定调度第一数量的ALU以在给定处理周期期间执行函数,每个ALU被调度为使用多个所选输入向量中的相应一个作为输入。处理电路还被构造为确定不调度第二数量的ALU用于在所述给定处理周期期间使用。处理电路还被构造为确定与所述多个所选输入向量不同的多个预测的未来输入向量,并且调度所述第二数量的ALU以使用所述多个预测的未来输入向量中的相应预测的未来输入向量作为输入在所述给定处理周期期间执行所述函数。处理电路还被构造为在完成所述处理周期之后,缓存从所述第一数量的ALU和第二数量的ALU接收的函数输出。
在一些实施方式中,根据较大输入向量集合随机地确定预测的未来输入向量。在其它实施方式中,通过将一个或更多个遗传算法应用至在一个或更多个先前处理周期内已被用作针对给定函数的输入的一个或更多个先前输入向量来确定预测的未来输入向量。一个或更多个遗传算法的应用例如可以包括遗传交叉的使用和/或变异算子的应用。
在一个或更多个实施方式中,阵列处理器包括图形处理单元(GPU)。
附图说明
图1示意性地示出包括具有多个算术逻辑单元(ALU)的阵列处理器的示例计算装置。
图2示出利用图1的多个ALU的示例方法。
图3至图4示意性地示出将输入向量调度为多个ALU中的函数输入的示例。
图5示出图2的方法的一部分的示例实现。
图6示出图2的方法的一部分的示例实现。
图7示出确定预测的未来输入向量的交叉算法的示例应用。
具体实施方式
本公开描述了用于通过在给定处理周期期间使用阵列处理器的未调度算术逻辑单元(ALU)来更有效地利用计算资源的技术。还公开了用于通过那些未调度的ALU预测将被用作函数输入的未来输入向量的技术。通过推测将在未来处理周期内使用什么输入向量,计算装置可以计算针对函数的预测输出值的缓存。随后,如果作出使用推测性输入向量中的一个作为输入来执行所述函数的请求,则可以从缓存检索函数输出来代替重新计算函数输出。在一个或更多个实施方式中,使用一个或更多个遗传算法执行输入向量预测(或“推测”)。在其它实施方式中,可以通过从可能输入向量集合随机地选择输入向量或通过随机地生成输入向量来执行输入向量预测。
图1示意性地示出包括主中央处理单元(CPU)12和阵列处理器14两者的示例计算装置10。在一个或更多个实施方式中,阵列处理器14包括图形处理单元(GPU)。当然,可以使用其它阵列处理器14。CPU 12和阵列处理器14中的每个均包括一个或更多个处理电路,该处理电路例如包括配置有实现这里论述的一个或更多个技术的适当软件和/或固件的一个或更多个微处理器、微控制器、专用集成电路(ASIC)等。
计算装置10包括高速缓冲存储器16。虽然高速缓冲存储器16被示出为阵列处理器14的一部分,但是将理解,这是非限制性示例,并且高速缓冲存储器16可以在阵列处理器14外部(例如,在储存器22或RAM 24中)。阵列处理器包括多个内核18a-18n,每个内核包括多个ALU 20a-20m。为了简单起见,示出了仅内核18a的ALU。然而,将理解,内核18a-18n中的每个均包括多个ALU 20。高速缓冲存储器16被配置为存储阵列处理器14的多个ALU 20的输出以用于一个或更多个函数。计算装置10还包括计算机可读存储介质(被示出为储存器22)、随机存取存储器(RAM)24、通信接口26(例如,无线收发器)以及一个或更多个输入/输出装置28(例如,电子显示器、鼠标、触摸屏、小键盘等)。储存器22例如可以包括固态或光学硬盘驱动器。
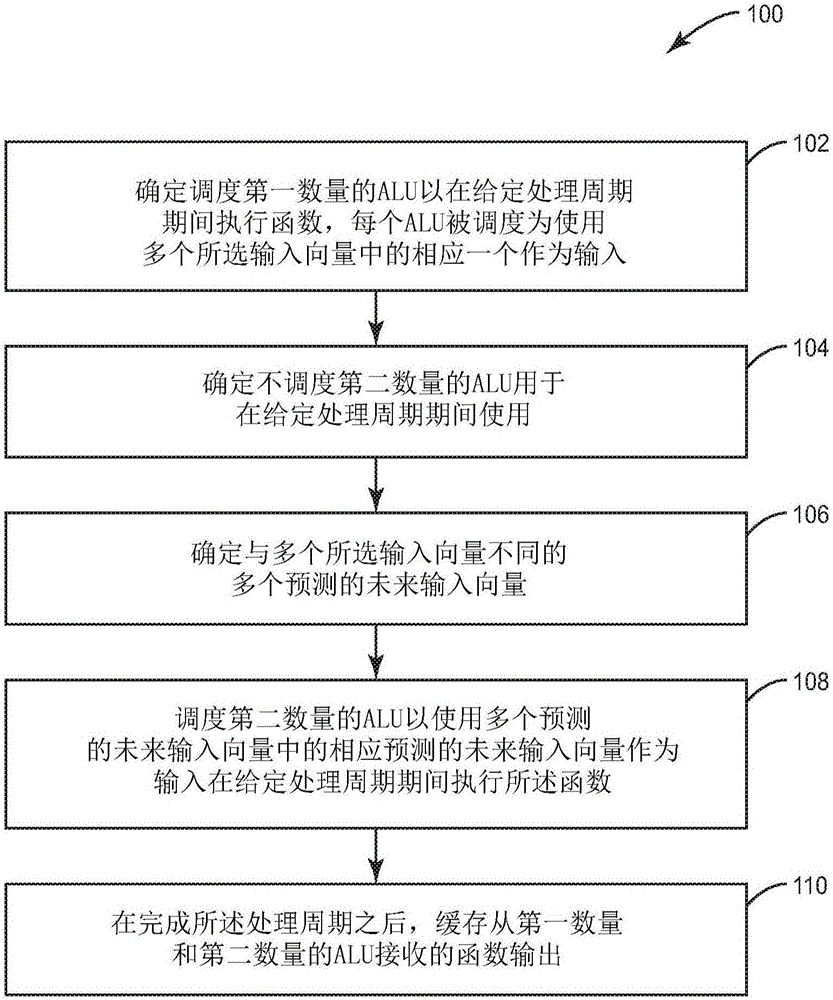
图2示出利用阵列处理器(例如,计算装置10的阵列处理器14)的多个ALU的示例方法100。计算装置10确定调度第一数量的ALU 20以在给定处理周期期间执行函数(框102),每个ALU被调度为使用多个所选输入向量中的相应一个作为输入。计算装置10还确定不调度第二数量的ALU用于在给定处理周期期间使用(框104)。计算装置10确定与多个所选输入向量不同的多个预测的未来输入向量(框106),并且调度第二数量的ALU 20以使用多个预测的未来输入向量中的相应预测的未来输入向量作为输入在给定处理周期间执行函数(框108)。在完成处理周期之后,缓存从第一数量的ALU和第二数量的ALU接收的函数输出(框110)。缓存例如可以发生在高速缓冲存储器16中。
图3提供方法100的示意性示例应用。根据针对给定处理周期的所请求调度(图3的左边),调度第一组30ALU,以使用输入向量X1-X10计算函数f,但是不调度第二组32ALU用于在处理周期期间使用。根据修改后的调度(图3的右边)在处理周期期间针对所述一组32 ALU将预测的未来输入向量X11-X16调度为到函数f的输入。在完成所述处理周期之后,缓存每个ALU的函数输出。当然,图3假定输入向量X1-X10先前未被用作函数输入,并且因此尚未缓存函数输出。图4提供已经缓存一些值的方法100的另一个示意性示例应用。
现在参照图4,根据针对给定处理周期的所请求调度(图4的左边),请求第一组30 ALU使用输入向量X1-X10计算函数f,但是不调度第二组32ALU用于在所述处理周期期间使用。然后,检测到输入向量X7和X8先前已被用作针对函数f的输入并且已具有被缓存的函数输出。图4的中间示出第一次修改后的调度,其中,确定已被用于利用输入向量X7和X8计算函数f的ALU_07和ALU_08可用。预测的未来输入向量X10-X18不仅针对所述组32 ALU还针对ALU_07和ALU_08在处理周期期间被调度为到函数f的输入(图4的右侧边)。在完成所述处理周期之后,缓存每个ALU的函数输出。
现在参照图5,示出图2的方法100的一部分的示例实现200。利用一个或更多个输入向量作为输入调用函数(框202为“是”)。然后,计算装置10检查任一个输入向量是否已缓存针对函数的结果(框204)。如果任一个输入向量已缓存针对函数的输出结果(框204为“是”),则使用那些缓存结果,并且释放本该重新计算缓存结果的一个或更多个ALU(框206)。
计算装置10每输入向量使用一个ALU在随后处理周期内调度函数的执行(框208)。如果在所调度的处理周期内没有额外ALU可用(框210为“否”),则计算装置使用所调度的输入向量作为输入计算函数(框214),并且从处理周期缓存从ALU接收的函数输出(框216)。
然而,如果额外ALU在所调度的处理周期内可用(框210为“是”),则计算装置10调度在可用ALU中的预测的未来输入向量(框212),并且然后执行框214-216。预测的未来输入向量的使用增加在未来处理周期内针对函数的所选输入向量将缓存能够从高速缓冲存储器返回而不是重新计算的输出的几率。
在一个或更多个实施方式中,如果高速缓冲存储器16变满,则可以选择缓存输入向量(及其对应函数输出)用于替换。在一个或更多个实施方式中,根据适合度得分的分布使用随机采样执行该选择。适合度得分指示已从高速缓冲存储器返回缓存值多少次。由此,因为具有最低适合度得分的缓存项不太频繁地被使用,所以替换具有最低适合度得分的缓存项。另选地,可能期望替换很少或不强调适合度得分的更老缓存项。
推测性未来输入向量可以以多种方式被预测。在一些实施方式中,所选输入向量是较大输入向量集合的一部分,并且确定与多个所选输入向量不同的多个预测的未来输入向量(框106)的特征在于:从尚未用作到函数的输入的输入向量集合随机地选择输入向量作为预测的输入向量。在一些实施方式中,随机地生成预测的输入向量。在一些实施方式中,遗传算法被用于预测的未来输入向量。
图6示出遗传交叉被用于预测的未来输入向量的图2的方法的一部分的示例实现300。执行初始推测以确定将额外ALU中被用作针对函数的输入的推测性输入向量(框302)。执行检查以确定是否调度函数以在即将到来的处理周期内计算(框304)。如果不调度函数以计算,则计算装置10等待另一个周期(框306)。否则,如果调度函数以在即将到来的周期内计算(框304为“是”),则计算装置10确定被选择作为输入的所选输入向量中的任一个是否已缓存针对所述函数的结果(框308)。
如果所选输入向量中的任一个已缓存输出,则在调度处理周期之后,计算装置10使针对那些缓存结果中的每个的适合度得分递增,并且将适合度得分分配给缓存结果及其对应输入向量(框310)。如果预定义数量的适合度得分已递增(框312为“是”),则计算装置选择具有适合度得分的两个输入向量(框314),并且执行遗传交叉,以确定将在随后处理周期内用作针对函数的输入的两个新输入向量(框316)。可选地,计算装置将变异算子应用至新输入向量中的一个或两个。
再次参照框314,在一个或更多个实施方式中,根据先前输入向量的适合度得分的分布执行具有适合度得分的两个输入向量的选择。这可以包括选择具有两个最高适合度得分的两个输入向量,或从处于适合度值分布的最上区域(指示那些输入向量比其它输入向量更多地被请求作为函数输出)处的输入向量池选择两个输入向量。
现在将关于利用函数f(x,y,a,b,z)(该函数例如可以在生物医学应用中用于计算针对不同窗口大小的串中的字符的同现并且将那些同现与特定值进行比较)的自然语言处理示例描述图6的过程300。函数的变量表示以下内容:
-“x”是字符串;
-“y”是窗口大小;
-“a”是将在比较中使用的第一字符;
-“b”是将在比较中使用的第二字符;以及
-“z”是与同现的数量相比较的值。
还假定函数f(x,y,a,b,z)取大小为“y”的“x”的所有子串“s”,并且如果a和b出现在s中,则将c(s,a,b)=1应用至子串“s”。即,如果a和b两者出现在子串s中,则确定为1。否则,确定为0。在对针对每个子串的所产生值求和之后,函数f将它们与值z进行比较,并且询问比较是真还是假。
假定最初使用具有以下元素的输入向量:
-x=″ADCEADFEBACED″
-y=3
-a=′A′
-b=′C′
-z=4.
这可以以更传统的向量形式(如"ADCEADFEBACED″,3,′A′,′C′,4)示出。该输入向量在图5中被示出为40。将这些值插入到函数f中可以用以下表达式来表示。
f(ADCEADFEBACED,3,′A′,′C′,4)
分析三个字符(y=3)的第一个窗口,该第一个窗口对应于第一个子串“ADC”。因为‘A’和‘C’都出现在子串“ADC”中,所以产生1(参见下面括号中的第一个“1”)。三个字符的第二个子串为“DCE”。因为‘A’和‘C’都未出现在该子串中,所以产生0(参见下面括号中的第一个“0”)。第三个子串为“CEA"。因为‘A’和‘C’都出现在该子串中,所以产生1(参见下面括号中的第二个“1”)。这针对串x中的三个连续字符的每个子串继续。由此,当使用输入向量40时的函数f询问以下内容:
(1+0+1+0+0+0+0+0+0+1+0)>4?
这可以被重述为询问3>4是否为真。因为这不为真,所以将由使用上述输入向量的函数输出0。输出值0将连同输入向量一起被存储在高速缓冲存储器16中。
当将针对给定输入向量执行f的计算时,计算装置10检查高速缓冲存储器16,以查看是否已针对该输入向量计算了函数f。如果缓存了期望输出,则可以返回缓存的输出结果,代替用输入向量重新计算f。每次这发生时,都使针对该输入向量的适合度得分递增。下面示出包括输入向量、其函数输出(“假”)及其适合度得分(“1”)的缓存项。
((″ADCEADFEBACED″,3,′A′,′C′,4),假,1)。
如果再次请求使用针对所述函数的输入向量,则将再次返回缓存的输出,并且使适合度得分再次递增(例如,递增1)。
如果高速缓冲存储器16变满,则可以选择单独缓存的输入向量(及其对应输出)用于替换(例如,通过根据适合度得分的适合度分布随机地采样)。由此,因为具有较低(或最低)适合度得分的缓存项不太频繁地被使用,所以可以替换具有较低(或最低)适合度得分的缓存项。
如果调度阵列处理器14以在给定处理周期期间计算函数,并且阵列处理器14的ALU在该处理周期期间可用,则调度预测的未来输入值(参见图2的框108)。这可以包括从可能输入向量的已知集合随机地选择输入向量,或者可以包括随机地生成输入向量。例如,可以随机地生成输入向量(″BDCEEDFEDACAD″,5,′D′,′C′,2)用于使用。该输入向量在图6中被示出为60。
一个或更多个遗传算法(诸如两个输入变量之间的遗传交叉、或单个输入向量的元素的变异)可以被应用以确定另外预测的未来输入向量。现在将论述应用遗传交叉和变异的示例。假定以上输入向量40、60中的每个已被使用,并且因此具有适合度得分。基于那些适合度得分,选择两个输入向量40、60以用于执行遗传交叉。
图7中示出输入向量40、60的遗传交叉。首先,并置每个输入向量以形成串42、62。然后,针对每个串选择相同交叉点。在图7的示例中,随机地选择交叉点6(参见附图标记44、64)。交叉点44的使用将串42划分为子串46和48。类似地,交叉点64的使用将串62划分为子串66和68。
然后,执行在子串的相应交叉点处交换子串以产生新串50、70的交叉。串50包括区段46和68,并且串70包括区段66和48。然后,串50被格式化为输入向量52,并且串70被格式化为输入向量72。每个输入向量52、71被分配有适合度得分0。在一个示例中,不分配适合度得分,直到输入向量52、72在处理周期内实际上被用作函数输入之后为止。
由此,在一些实施方式中,确定多个预测的未来输入向量(图2的框106)包括:选择已在一个或更多个处理周期内已被用作针对给定函数的输入的一个或更多个先前输入向量,以及将一个或更多个遗传算法应用至一个或更多个先前输入向量,以确定多个预测的未来输入向量的至少一部分。例如,遗传算法可以用于预测图3的一些ALU 32的输入向量,并且可以随机地预测其它输入向量。
而且,如上所述,在一些实施方式中,可以使用适合度得分,在每次输入向量被选择为针对给定函数的输入时,使针对给定输入向量的适合度得分递增。在一些这样的实施方式中,基于先前输入值的适合度得分来执行已被用作针对给定函数的输入的一个或更多个先前输入向量的选择(图6的框314)。
在图7的示例中,将遗传算法应用至先前输入向量40、60的特征在于:对两个先前输入向量40、60执行遗传交叉,以确定两个不同的新输入向量52、72。在相同或其它实施方式中,应用遗传算法的特征在于:将变异算子应用至新输入向量52、72中的一个或更多个元素(或应用至先前输入向量40、60)。一些示例变异算子包括:用随机值替换输入向量的元素的值,对输入向量的元素的值求反,使输入向量的元素的值增加预定义量,并且使输入向量的元素的值减小预定义量。例如,可以通过将输入向量40中的“3”改变为“2”将变异算子应用至输入变量40,这改变上述函数f的输出。
当然,将理解,上述示例仅是非限制性示例,并且可以应用使用相同或不同遗传算子、交叉点以及变异的各种其它遗传算法。例如,可以使用包括以下遗传算子的各种组合的一些另外遗传算法:求反、多点交叉、三父辈交叉以及均匀交叉。作为另外示例,还可以使用的一些另外遗传算子包括通过将群体划分为子群体(例如,再分组、殖民-灭绝或迁移)工作于群体等级的算子。因为这种遗传算子和遗传算法对于本领域普通技术人员来说是已知的,所以这里不详细论述它们。
因为空余计算资源被利用而不是空闲,所以针对许多内核处理器(或甚至具有多个ALU的单核处理器)执行上述数据推测以确定预测的未来输入向量并且然后使用这样的计算装置上的充裕空余处理能力利用那些输入向量计算函数输出可以是有利的。而且,如果推测被很好地执行,并且预测的未来输入向量在未来被请求作为函数输入,则它们的值可以从高速缓冲存储器快速地返回,而不是被重新计算。这些技术对于具有数百或数千个可用ALU的GPU阵列处理器来说是特别有用的。
而且,虽然在以上各种示例中已经提及图1的计算装置10,但是将理解,图1的计算装置10仅是非限制性示例,并且可以使用包括具有多个ALU的阵列处理器的其它计算装置。
当然,在不脱离本公开的基本特征的情况下,本公开可以以除了这里具体阐述的那些方式之外的其它方式来实现。本实施方式在所有方面都被认为是示例性的且不是限制性的,并且在所附权利要求的意义和等同范围内的所有改变旨在包含在其中。
- 还没有人留言评论。精彩留言会获得点赞!