品质管理系统及其方法与流程
本发明涉及一种品质管理系统及其方法,尤其涉及一种应用于生产批的品质管理方法。
背景技术:
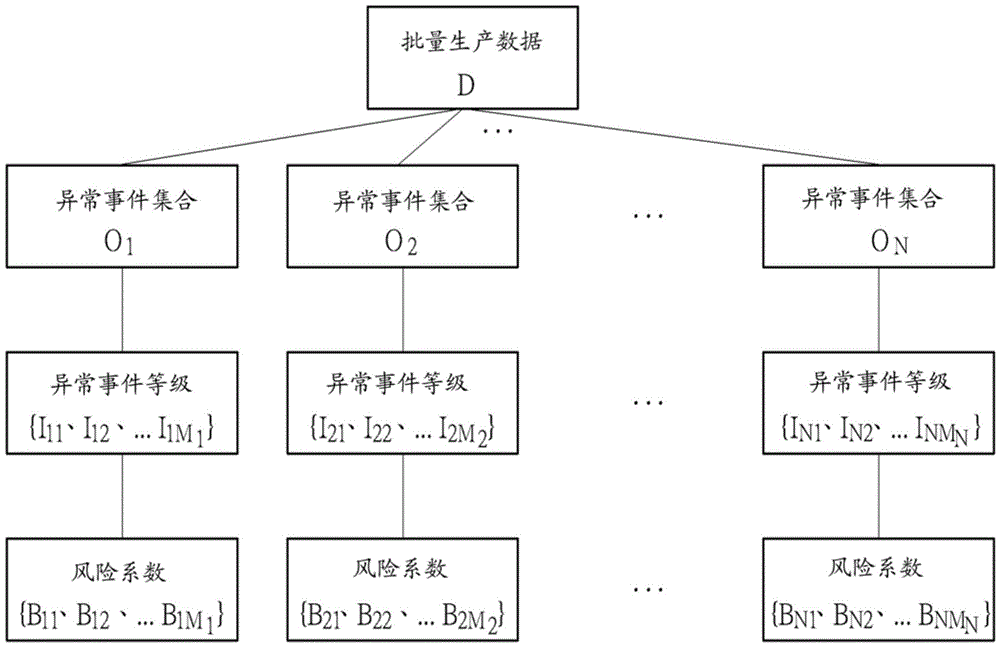
:近年来,由于工业技术的发达,批量生产制造的手段已由传统人力的制造方法逐渐被自动化的机器所取代。一般而言,生产批(productionlot)利用生产线的制造过程会经过许多站点,而每一个站点会执行对应的步骤和生产程序。然而,在实际的生产过程中,常常会有次品的产生,随着机器工作的时间增加,生产过程中可能发生机器偏离原始设定的现象。因此生产出的成品,其规格可能不符合要求。而次品的产生时会造成总存货成本的增加,并影响生产线的流畅性。因此,为了控管生产批的品质特性及成品率,常常会将生产批取样并做品质上的数据统计及分析。一般而言,在批量生产制造时会发生许多影响品质的异常事件(Issue),而各种异常事件影响品质特性的程度皆不相同,异常事件例如系统错误、地震、温度过高,甚至是机台死机等。而这些异常事件将会被对应的系统机台所记录。然而,因为系统机台的不同,所记录异常事件的标准亦不一致,这种不统一的数据将导致分析不易。再者,由于各个系统机台尚未整合,因此利用生产批取样的数据以及异常事件一并计算时,分析出的结果将有不准确的问题。因此,发展一种将各个系统机台整合的品质管理方法是非常重要的。技术实现要素:本发明一实施例描述了一种品质管理方法,包含由数据库中取得生产批的品质历史数据,依据生产批的品质历史数据,将生产批归类为N个异常事件集合,依据生产批的品质历史数据,将每一异常事件集合内多个异常事件的每一异常事件对应至合适的异常事件等级,设定对应于每一异常事件等级 的待估测的风险系数,根据生产批的品质历史数据及这些异常事件等级,计算每一异常事件等级对应的待估测的风险系数,依据这些异常事件等级及计算后的些风险系数,产生线性回归方程式,根据线性回归方程式,预测生产批品质特性的高可靠度区间所对应的风险分数,其中N为大于1的正整数。本发明另一实施例描述了一种品质管理系统,包含数据库及处理器。数据库是用以储存生产批的品质历史数据,处理器是耦接于该数据库。其中处理器由数据库中取得生产批的品质历史数据,处理器依据生产批的品质历史数据,将生产批归类为N个异常事件集合,处理器依据生产批的品质历史数据,将每一异常事件集合内多个异常事件的每一异常事件对应至合适的异常事件等级,处理器设定对应于每一异常事件等级的待估测的风险系数,处理器根据生产批的品质历史数据及这些异常事件等级,计算每一异常事件等级对应的待估测的风险系数,处理器依据这些异常事件等级及计算后的这些风险系数,产生线性回归方程式,处理器根据线性回归方程式,预测生产批品质特性的高可靠度区间所对应的风险分数,其中N为大于1的正整数。附图说明图1是发明实施例的品质管理系统的元件框图。图2描述了图1实施例中,处理器整合各站台系统生产批数据的示意图。图3为图1实施例中,产生品质特性和风险分数的基准线、上限及下限的示意图。【附图标记说明】100品质管理系统10数据库11处理器D生产批数据O1至ON异常事件集合I11至INMN异常事件等级B11至BNMN风险系数UB上限BL基准线LB下限QL品质特性RVL及RVR风险分数具体实施方式图1为本发明实施例的品质管理系统100的元件框图。如图1所示,品质管理系统100包含数据库10及处理器11。数据库10是用以储存生产批的品质历史数据。这里所指的品质历史数据为生产批经过许多站台系统后,各站台系统所记录的各种不同异常事件(Issue)的数据。处理器11是耦接于数据库10。这边所指的处理器11可为个人计算机上的处理器,分析服务器中的处理器或是工作机台上的处理器等。在本实施例中,处理器11将利用数据库10内的生产批的品质历史数据,利用演算法整合所有站台系统上的数据,并分析其统计特性及回归曲线。而处理器11依据分析后的结果,将预测生产批品质特性的高可靠度区间所对应的风险系数。而生产线上的工作人员即可利用这个生产批品质特性的高可靠度区间所对应的风险系数,挑选合适的生产批取样进行实验。而品质管理系统100将如何预测生产批品质特性的高可靠度区间所对应的风险系数,其演算法将详述于下。图2描述了图1实施例中,处理器11整合各站台系统生产批数据的示意图。在图2中,生产批数据D为生产批经过许多站台系统后,各站台系统所记录的各种不同异常事件(Issue)的数据集合,此数据存于数据库10中。而处理器11由数据库10中提取生产批数据D后,依据其站台系统,将生产批数据D归类为N个异常事件集合,如图2中的异常事件集合O1至异常事件集合ON。每一个异常事件集合对应不同的站台系统。在图2中,异常事件集合O1是为第1个站台系统的记录数据,异常事件集合O2是为第2个站台系统的记录数据,异常事件集合ON是为第N个站台系统的记录数据。在本实施例中,每一个异常事件集合会有相同或不同数量的异常事件。例如异常事件集合O1中有M1个异常事件,异常事件集合O2中有M2个异常事件,异常事件集合ON中有MN个异常事件。这里所用的N为大于1的正整数,而M1至MN为正整数。接下来,处理器11会将每一个异常事件集合内的异常事件对应至合适的异常事件等级(IssueGrade)。例如将图2中的异常事件集合O1中的M1个异常事件由小到大排序,并分别将这些排序后的异常事件对应为异常事 件等级I11至异常事件等级I1M1,而异常事件等级I11为较不严重的异常事件,异常事件等级I1M1为较严重的异常事件。处理器11会将异常事件集合O2中的M2个异常事件由小到大排序,并分别将这些排序后的异常事件对应为异常事件等级I21至异常事件等级I2M2,而异常事件等级I21为较不严重的异常事件,异常事件等级I2M2为较严重的异常事件。类似地,处理器11会将异常事件集合ON中的MN个异常事件由小到大排序,并分别将这些排序后的异常事件对应为异常事件等级IN1至异常事件等级INMN,而异常事件等级IN1为较不严重的异常事件,异常事件等级INMN为较严重的异常事件。因此,根据N个异常事件集合对应的异常事件等级,可以定义出一个异常事件指标(IssueCode),为下:IC=Σi=1NΣj=1MIij---(1)]]>在(1)式中,当第i个异常事件集合Oi内的第j个异常事件等级Iij为0或1的时候,(1)式中的异常事件指标IC即表示生产批所关连到的异常事件的数目。举例来说,生产批遭遇到了第1个异常事件集合O1的第2个异常事件I12,第2个异常事件集合O2的第3个异常事件I23以及第3个异常事件集合O3的第1个异常事件I31,则异常事件指标IC的数值即为I12+I23+I31。然而,观察(1)式所定义的异常事件指标IC仅可以知悉异常事件的索引(Index)以及异常事件的数目,并无法以量化的方式获得异常事件的风险严重性。因此,为了进一步分析异常事件对于生产风险的冲击度,处理器11会将第i个异常事件集合Oi内的第j个异常事件等级Iij(意即每一个异常事件)设定对应的风险系数Bij(RiskCoefficient)。如图2所示,第1个异常事件集合O1的异常事件等级I11至异常事件等级I1M1对应的风险系数为B11至B1M1,第2个异常事件集合O2的异常事件等级I21至异常事件等级I2M2对应的风险系数为B21至B2M2,第N个异常事件集合ON的异常事件等级IN1至异常事件等级INMN对应的风险系数为BN1至BNMN。在本实施例中,由于在同一个异常事件集合内的异常事件的严重度为由小到大排列,因此对应的风险系数为由大到小排列,意即风险系数越大表示对应的异常事件对品质的冲击程度越轻微,风险系数越小表示对应的异常事件对品质的冲击程度越严重。故在图2中,B11>B12…>B1M1,B21>B22…>B2M2,BN1>BN2…>BNMN。因此,根据N个异常事件集合对应的异常事件等级的风险系数,可以定义出一个风险分数指标(Risk Value),为下:RV=Σi=1NΣj=1MiBijIij---(2)]]>然而,本发明在同一个异常事件集合内的异常事件的严重性及其对应异常事件的等级并不限于实施例所述的由小到大排序,而异常事件等级所对应的风险系数亦不限制为由大到小排列。举例来说,在其它实施例中,异常事件等级所对应的系数可为由小到大排列。而本实施例接下来的说明中,会利用一个矩阵的关系式,推出所有异常事件集合对应的异常事件等级的风险系数,再将计算出来的风险系数带回(2)式中,使得(2)式变为一个具有个变数的线性回归方程式,其中表示所有考虑的异常事件总数,且线性回归方程式为单调性递增(MonotonicallyIncreasing)或单调性递减(MonotonicallyDecreasing),而处理器11将根据线性回归方程式,取得关于品质特性对风险系数的基线(BaseLine)、上限(UpperBound)以及下限(LowerBound)。处理器11会依据上述这些统计结果,预测生产批品质特性的高可靠度区间所对应的风险分数。这里用一个例子来说明处理器11整合各站台系统生产批数据以及预测生产批品质特性的高可靠度区间所对应的风险系数的流程。在此,为了简化描述,数据库10只考虑2个站台系统记录的数据,如下表所示:在上表中,两个站台系统分别记录2种类别的异常事件集合,每一个异常事件集合有3个异常事件,第一类别的第1个异常事件为无品质损失的事件,因此其严重性较低,第一类别的第2个异常事件为品质损失在10%以下的事件,其严重性中等,第一类别的第3个异常事件为品质损失在10%以上的事件,其严重性最高。第二类别的第1个异常事件为无品质损失的事件,因此其严重性较低,第二类别的第2个异常事件为品质损失在5%以下的事件,其严重性中等,第二类别的第3个异常事件为品质损失在5%以上的事件,其严重性最高。这边的品质特性可为任何生产品质的标准,例如成品率(Yield)等。接下来,处理器11会将每一个异常事件集合内的每一个异常事件设定对应的风险系数。因此,第一类别的第1个异常事件被设定对应风险系数为B11,第一类别的第2个异常事件被设定对应风险系数为B12,第一类别的第3个异常事件被设定对应风险系数为B13,第二类别的第1个异常事件被设定对应风险系数为B21,第二类别的第2个异常事件被设定对应风险系数为B22,第二类别的第3个异常事件被设定对应风险系数为B23。为了推出所有异常事件集合对应的异常事件等级的风险系数,首先会根据数据库10中2个站台系统记录的数据,建立一个异常事件等级矩阵。这个异常事件等级矩阵为一个稀疏矩阵(SparseMatrix),且此异常事件等级矩阵的每一元素为0或1,而异常事件等级矩阵的定义在于生产批的每一个产品被归类为第一类别的异常事件集合与第二类别的异常事件集合的所有异常事件组合的呈现。举例来说,若实施例中生产批的产品数量为NLOT。为了方便表示,实施例将生产批中的产品表示为编号1至NLOT索引值的产品,则异常事件等级矩阵可表示为下:上表中为考虑第一类别的异常事件集合与第二类别的异常事件集合中,生产批中数量为NLOT的产品所遭遇的异常事件种类的组合。以本实施例而言,因每一个类别的异常事件共有三种,因此生产批所遭遇到的异常事件种类即 有3×3=9种可能。因此,若生产批中产品的数量NLOT>9,则表示在生产批中有某些不同索引值的产品会遭受到相同的异常事件(以一般成品率较高的生产批而言,品质特性在两种类别均无损失的比率较高)。例如在上表中,索引(1)、索引(2)及索引(6)的产品就遭受到相同的异常事件(品质特性无损失)。因此,建立完成的异常事件等级矩阵,其row的维度为NLOT。再者,以本实施例而言,总共有6种异常事件被考虑,因此建立完成的异常事件等级矩阵,其column的维度为3+3=6(然而在通式中,若考虑N个异常事件集合,假设第n个异常事件集合内有Mn个数量的异常事件,则异常事件等级矩阵其column的维度为其中∑为连加符号)。而将上述的异常事件等级矩阵展开可表示为下:IM=100100100100010001100010001001100100001100..................010011---(3)]]>其中IM表示异常事件等级矩阵,其维度为NLOT×6。将异常事件等级矩阵IM建立完成后,依据(2)式中的关系,每一个风险系数会对应至每一种异常事件。因此,将第一类别的异常事件集合中的风险系数B11、风险系数B12、风险系数B13,以及将第二类别的异常事件集合中的风险系数B21、风险系数B22、风险系数B23展开,并产生一个风险系数向量。在本实施例中,风险系数向量内即有6个元素(然而在通式中,若考虑N个异常事件集合,假设第n个异常事件集合内有Mn个数量的异常事件,则风险系数向量内即有个元素,其中∑为连加符号),此风险系数向量可表示为下:B=B11B12B13B14B15B16---(4)]]>其中B为风险系数向量,其维度为6×1。因此,当将(3)式中的异常事件等级矩阵IM与(4)式中的风险系数向量B相乘时,输出的向量Y即为生产批中在每一种异常事件组合所对应的风险系数指标向量。然而,本实施例生产批中的产品数量为NLOT,此输出的向量Y中所表示的风险系数指标即为NLOT×1的维度,为下所示:Y=Y1Y2Y3Y4Y5Y6Y7...YNLOT=100100100100010001100010001001100100001100..................010011×B11B12B13B21B22B23+ϵ1ϵ2ϵ3ϵ4ϵ5ϵ6ϵ7...ϵNLOT---(5)]]>在(5)式中,B11至B23可以利用数据库10内存的2个站台系统记录的数据以及(3)式中的异常事件等级矩阵IM估测其数值。由于异常事件等级矩阵IM并非为方阵,因此不能直接做矩阵反转(MatrixInverse)。在本实施例中,求出B11至B23的方式可利用异常事件等级矩阵IM的虚拟反转法(PseudoInverse)、或是使用线性回归的方式,藉由最小平方逼近法(Least-SquaredApproach)或是最小误差逼近法(Minimum-Mean-SquaredErrorApproach)逼近求出(此时于(5)式中需要一组微误差量ε1至来辅助求解)。虽然本实施例式以(5)式的架构来求解B11至B23,但本发明却不限于此,在其它实施例中,亦可以将异常事件等级矩阵IM以一个常数行向量(ColumnVector)扩充其维度,或将风险系数向量B以一个常数扩充其维度,如下所示:在(6)式中,C为一常数,所对应的IM最左侧的行向量亦为常数向量,在这种情况下B11至B23仍可使用最小平方逼近法(Least-SquaredApproach)或是最小误差逼近法(Minimum-Mean-SquaredErrorApproach)求解。而求出的解与由(5)式中的解仅差距一个常数偏移量(ConstantOffset),因此不会影响之后分析的统计特性。当上述(5)式建立完成且经由(5)式将风险系数B11至B23求出来之后,风险系数B11至B23即带回(2)式中的风险分数指标,就可以将(2)式变为一个具有6个变数的线性回归方程式,其中变数的数量即表示所有考虑的异常事件总数(在通式中,若考虑N个异常事件集合,假设第n个异常事件集合内有Mn个数量的异常事件,则(2)式即变为一个具有个变数的线性回归方程式)。在此,线性回归方程式为单调性递增(MonotonicallyIncreasing)或单调性递减(MonotonicallyDecreasing)。举例来说,求出的线性回归方程式LY可展开如下:LY=91.378+0.0×I11-3.52×I12-8.61×I13+0.0×I21-5.07×I22-32.32×I23(7)在本实施例中,通过(5)式将风险系数逐一求解,而解集合为B11=0.0、B12=-3.52、B13=-8.61、B21=0.0、B22=-5.07、B23=-32.32。然而,本发明的风险系数解集合会随着生产批品质特性不同而有所差异,上述所列的解集合仅为实施例中一种解集合的表示,并非用以限制本发明的求解过程和结果。本实施例所求出的风险系数解也应证了前述条件,因为本实施例在整合不同系 统所记录的异常事件集合时,处理器11会将每一个异常事件集合中的异常事件由小到大排序,因此对应的风险系数其大小排序也应满足B11>B12>B13以及B21>B22>B23的条件。而在(7)式中,91.378为一个预定的常数,因此不影响之后分析的统计特性。当(7)式中的线性回归方程式LY求出之后,通过风险分数模型检定,可产生基准线(BaseLine)及对应该基准线的上限(UpperBound)及下限(LowerBound)结果,如图3所示。图3为本发明产生对应品质特性和风险分数的基准线、上限及下限的示意图。举例来说,当考虑新的生产批加入时,对应新的生产批的异常事件指标(IssueCode)及异常事件等级(IssueGrade)亦会被带入(7)式中而产生不同线性回归方程式LY的输出。而本发明的品质管理系统即会依此产生如图3中的风险分数及对应基准线、上限及下限等的统计特性。在图3中,X轴为风险分数,Y轴为品质特性,上限UB为具有圆形标点的线段,基准线BL为具有三角形标点的线段,下限LB为具有矩形标点的线段。当工程批至少要求品质特性满足QL的标准时,对应上限UB的风险分数为RVL,此风险分数RVL所代表的意义即为满足品质特性QL的标准时,工程批所挑选风险分数的下限。因此,为了增加工程批取样的可靠度,处理器11会以基准线BL的角度来计算满足品质特性QL的标准时,对应的风险分数。在这个情况下,由于基准线BL对应于品质特性QL的风险分数为RVR,故处理器11将会建议生产线上的工程人员挑选符合基准线BL的风险系数至少为RVR的工程批取样。然而,图3所述的品质特性和风险分数的基准线、上限及下限,其斜率并不限制本发明的演算法。举例来说,若实施例中的品质特性为考虑成品率(Yield),则基准线、上限及下限的斜率将同于图3,其斜率为正。反之,在其它实施例中,若品质特性为考虑次品率(DefectiveRate),则基准线、上限及下限的斜率将与图3相反,其斜率为负。综上所述,本发明描述了一种应用于生产批的品质管理系统及其方法,其观念为整合生产批不同平台系统的记录数据,并将这些异常事件的数据对应至合适的异常事件等级及风险系数。藉由建立异常事件等级矩阵以及风险系数向量,可以通过回归的方式将所有的风险系数求出,进而求得风险分数指标的线性回归方程式,并进一步预测生产批品质特性的高可靠度区间所对应的风险分数。因此,生产线上的工程人员很容易的利用建议的风险分数, 挑选出可靠度较高的生产批取样。以上所述仅为本发明的优选实施例,凡依本发明权利要求所做的等同变化与修饰,皆应属本发明的涵盖范围。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1