一种微博话题特征提取方法及装置与流程
本发明涉及中文信息处理领域,特别是涉及一种微博话题特征提取方法及装置。
背景技术:
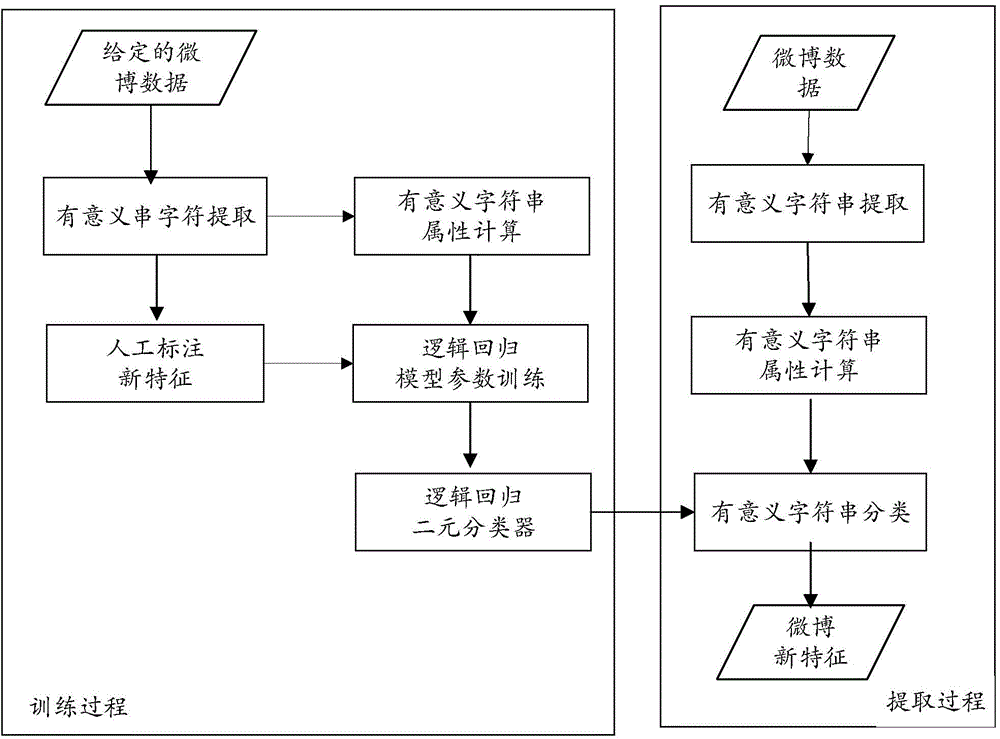
:近年来,随着web2.0社交网络的兴起,微博成为信息传播的一个重要媒介。微博凭借平台开放性、终端扩展性、内容简洁性和低门槛等特性,在网民中迅速流行起来。截至2013年年底,我国微博用户总用户量已经突破13亿,日均用户发帖量超过2亿。由于大量的网民在微博上参与讨论社会事件,微博不仅是信息产生和传播的重要平台,而且是反映社情民意的舆论阵地,所以,及时分析微博中的话题信息对于舆情监测、信息安全等领域具有重要的现实意义。在信息处理领域中,文本表示通常采用VSM(vectorspacemodel,向量空间模型),VSM文档被表示为特征项空间中的一个向量,一般采用词语作为特征项。而特征项选取的质量,直接影响到文本话题发现的性能和效果。因此,特征项的提取是话题发现等文本挖掘的基础和前提。微博信息实时反映了当前发生的社会事件,在微博中,描述最新事件的新鲜用语层出不穷,而且,每个用户随时都可以发表微博,信息具有原创性和时效性的同时,也表现出草根性和随意性,用词口语化、不规范现象严重、简称、缩略语大量存在。新词和新用语的大量涌现,给面向微博的文本挖掘带来新的挑战。采用传统的静态词典中的词语特征来表示微博文本,将会遗漏大量的关键特征,不能准确反映实时的微博信息,直接影响到微博话题分析等文本深度挖掘的质量。技术实现要素:本发明提供一种微博话题特征提取方法及装置,用以解决目前采用静态词典中的词语特征来表示微博文本,会遗漏大量的关键特征,不能准确反映实时微博信息的问题。根据本发明的一个方面,提供了一种微博话题特征项提取方法,包括:提取微博中的有意义字符串,所述有意义字符串为具有明确语义的语言单元;提取所述有意义字符串的异质属性信息;根据所述异质属性信息对所述有意义串进行分类,得到微博话题相关特征项。其中,所述提取微博中的有意义字符串包括:提取指定的微博集合中的重复字符串;提取所述重复字符串所在的文本中位于所述重复字符串前面的词语,得到第一邻接集合,提取所述重复字符串所在的文本中位于所述重复字符串后面的词语,得到第二邻接集合;确定所述第一邻接集合以及所述第二邻接集合中元素的个数;在所述第一邻接集合以及所述第二邻接集合中的元素个数均大于预设值时,确定当前重复字符串为有意义字符串。其中,所述重复字符串包括10个以内字符。其中,所述有意义字符串的异质属性信息包括以下几种:结构属性、内容属性以及自身属性;其中,所述结构属性至少包括:作者影响力、文档影响力、在出现文档中的平均影响力以及有在出现作者中平均影响力;所述内容属性至少包括:出现的频次、出现的文档频次、出现的作者频次、反映有意义字符串普遍重要性的词频*逆文档频次、词频*逆作者频次;所述自身属性包括:有意义字符串的长度。其中,所述根据所述异质属性信息对所述有意义串进行分类,得到微博话题相关特征项,包括:采用逻辑回归方法根据所述异质属性信息对所述有意义字符串进行二元分类,得到微博话题相关的特征项以及噪声特征项。根据本发明的另一个方面,提供了一种微博话题特征项提取装置,包括: 第一提取模块,用于提取微博中的有意义字符串,所述有意义字符串为具有明确语义的语言单元;第二提取模块,用于提取所述有意义字符串的异质属性信息;分类模块,用于根据所述异质属性信息对所述有意义串进行分类,得到微博话题相关特征项。其中,所述第一提取模块包括:第一提取单元,用于提取指定的微博集合中的重复字符串;第二提取单元,用于提取所述重复字符串所在的文本中位于所述重复字符串前面的词语,得到第一邻接集合,提取所述重复字符串所在的文本中位于所述重复字符串后面的词语,得到第二邻接集合;第一确定单元,用于确定所述第一邻接集合以及所述第二邻接集合中元素的个数;第二确定单元,用于在所述第一邻接集合以及所述第二邻接集合中的元素个数均大于预设值时,确定当前重复字符串为有意义字符串。其中,所述重复字符串包括10个以内字符。其中,所述有意义字符串的异质属性信息包括以下几种:结构属性、内容属性以及自身属性;其中,所述结构属性至少包括:作者影响力、文档影响力、在出现文档中的平均影响力以及有在出现作者中平均影响力;所述内容属性至少包括:出现的频次、出现的文档频次、出现的作者频次、反映有意义字符串普遍重要性的词频*逆文档频次词频*逆作者频次;所述自身属性包括:有意义字符串的长度。其中,所述分类模块用于:采用逻辑回归方法根据所述异质属性信息对所述有意义字符串进行二元分类,得到微博话题相关的特征项以及噪声特征项。本发明有益效果如下:本发明实施例提供的方案,基于有意义字符串来提取微博特征项,该类特征项能够表征微博信息的实时内容,采用该方式能够准确地提取微博信息中的话题相关特征项,提高了特征提取的准确率。附图说明图1是本发明实施例1的微博话题特征项提取方法的流程图;图2为本发明实施例2的基于有意义串分类的微博特征项提取方法流程示意图;图3是本发明实施例3的微博话题特征项提取装置的结构框图。具体实施方式为了解决现有技术采用静态词典中的词语特征来表示微博文本,会遗漏大量的关键特征,不能准确反映实时微博信息的问题,本发明提供了一种微博话题特征提取方法及装置,以下结合附图以及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不限定本发明。实施例1图1是本发明实施例1的微博话题特征项提取方法的流程图,如图1所示,该方法包括如下步骤:步骤101:提取微博中的有意义字符串;其中,有意义字符串是指包含具体语义的,具有语义完整性,且能够独立使用的语言单元,能在多种不同语境中使用的字符串,包括了未登录的新词和命名实体,以及有意义的词组和短语,突破了词典中词语的界限,即有意义的字符串可以包括一个或多个词语,本实施例中,优选的该有意义字符串最多可以包括10个字符。上述步骤101具体可以按照如下具体实施方式来进行:提取指定微博集合中的重复字符串;提取重复字符串所在的文本中位于重复字符串前面的词语,得到第一邻接集合,提取在重复字符串所在的文本中位于重复字符串后面的词语,得到第二邻接集合;确定第一邻接集合以及第二邻接集合中元素的个数;在第一邻接集合以及第二邻接集合中的元素个数均大于预设值时,确定当前重复字符串为有意义串。步骤102:提取有意义字符串的异质属性信息;本实施例构造了三类有意义字符串的属性,第一类是内容属性,根据有意义字符串在微博信息的分布统计而产生,包括词频、文档频次、作者频次、平均文档频次、平均作者频次,以及反映有意义字符串普遍重要性的词频*逆文档频次和词频*逆作者频次;第二类是结构属性,根据微博作者的关注关系计算产生作者影响力、平均作者影响力以及根据微博信息的转发评论关系计算产生文档影响力、平均文档影响力;第三类是有意义字符串自身的长度属性。步骤103:根据异质属性信息对所述有意义串进行分类,得到微博话题相关特征项。其中,特征项指文本特征项,具体地,根据异质属性信息对特征项进行分类,得到与微博话题相关的特征项,包括:采用逻辑回归方法根据异质属性信息对有意义字符串进行二元分类,得到微博话题相关的特征项以及噪声特征项。实施例2图2为本发明实施例2的基于有意义串分类的微博特征项提取方法流程示意图,参阅图2,该方法包括如下步骤:步骤1,提取给定微博数据集合中的有意义字符串;其中,上述步骤1具体可以包括如下步骤11以及步骤12;步骤11,提取给定微博数据集合中的重复字符串,其中,重复字符串是指重复出现频次大于两次的字符串,重复字符串的长度限定在10个字符以内。对于同一话题或事件,微博中有大量的博主发帖或者转发,具有统计意义的微博特征项应该包含在重复串字符中,是重复字符串集合的子集。步骤12,对重复串进行上下文邻接分析,提取微博信息中的有意义字符串。上下文邻接分析指提取重复串字符的邻接集合,计算邻接类别。邻接集合和邻接种类定义如下:邻接集合:分为左邻接集合(即上述第一邻接集合)NBL和右邻接集合NBR(即上述第二邻接集合),分别指真实文本中,与字符串S左边或者右边相邻的词语的集合。当字符串做为一个句子的开始,其左邻接元素记为BOS,做为句子的结束时,其右邻接元素记为EOS。邻接种类:分为左邻接种类VL和右邻接种类VR,分别指左邻接集合中和右邻接集合种元素的数目,它们反映了字符串上文和下文语境种类的多少。选取左邻接类别和右邻接类别中的较小值记为minVN。当重复串的minVN大于阈值TVN时,该字符串就是有意义字符串。阈值TVN的选取与微博信息的规模相关,取值应大于2,本实施例取值为3。步骤2,提取有意义串字符的三类异质属性,包括结构属性,内容属性和自身属性,刻画了每个有意义字符串在真实文本中的流通特点。本实施例从微博的结构关系中构造的有意义字符串的结构属性,结构属性包括有意义字符串的作者影响力Inf_Auth和平均作者影响力Ave_Inf_Anth,文档影响力Inf_Doc和平均文档影响力Ave_Inf_Doc。有意义字符串的作者影响力Inf_Auth和平均作者影响力Ave_Inf_Anth,的计算依据是每个作者的自身影响力。每个作者的自身影响力AuthRank,采用类PageRank的方法来计算微博博主的影响力AuthRank,计算公式如下:AuthRank(ui)=1-qM+qΣujAuthrank(uj)L(uj);]]>其中,M是总的博主数,uj表示关注博主ui的博主,L(uj)是博主uj关注的博主数,q是阻尼系数,一般取值为0.85。有意义字符串的作者影响力Inf_Auth,指有意义字符串出现的所有微博信息的作者影响力之和,计算公式如下:Inf_Auth(Fi)=Σj=0NAuth_Rank(user(Dj));]]>有意义字符串的平均作者影响力Ave_Inf_Anth,指有意义字符串出现的所 有微博信息中的平均作者影响力,计算公式如下:Ave_Inf_Auth(Fi)=Inf_Auth(Fi)/DF(Fi);其中,DF(Fi)表示有意义字符串出现的微博文档数。有意义字符串的文档影响力Inf_Doc和平均文档影响力Ave_Inf_Doc的计算依据是微博信息的文档影响力。微博信息的文档影响力与微博的评论数和转发数相关,计算公式如下:DocRank(Di)=-γ×logNcom(Di)MAX{Ncom(Dj)}-δ×logNrep(Di)MAX{Nrep(Dj)}]]>其中,Ncom、Nrep分别表示一条微博信息的评论数和转发数,MAX{Ncom(Dj)}、MAX{Nrep(Dj)}分别表示文档集合中的最大评论数和最大转发数,γ和δ是调节参数,这两个调节参数优选的均可以取1。有意义字符串的文档影响力Inf_Doc,指特征出现的所有微博信息的影响力之和。Inf_Doc(Fi)=Σj=0NDocRank(Dj);]]>其中,N表示特征Fi的总频次,Dj表示特征Fi第j次出现的文档。有意义字符串的平均文档影响力Ave_Inf_Doc,指有意义字符串出现的所有微博信息中的平均作者影响力,计算公式如下:Ave_Inf_Doc(Fi)=Inf_Auth(Fi)/DF(Fi)其中,DF(Fi)表示有意义字符串出现的微博文档数。本实施例构造的有意义字符串的属性优选地可以包括如下表中所示的10种:序号属性名称含义1TF特征出现的频次2DF特征出现的文档频次3AF特征出现的作者频次4TF*idf反映了特征重要性5TF*iaf反映了特征重要性6Inf_Auth特征的作者影响力7Inf_Doc特征的文档影响力8Inf_Doc/DF特征在出现文档中的平均影响力9Inf_Auth/AF特征在出现作者中的平均影响力10Len特征长度步骤3,对有意义字符串进行二元分类,得到微博话题相关的特征项。对有意义字符串分类采用逻辑回归方法建模,每个有意义字符串的10个属性构成10维向量,记作xi={xi1,xi2...xi10},分类结果用Y表示,Y=1表示话题相关特征,Y=0表示噪音特征,则有意义字符串的逻辑回归分类模型为:Pr(Y=1|X=x)=e(β10+β1Tx)1+e(β10+β1Tx)Pr(Y=0|X=x)=11+e(β10+β1Tx)]]>其中,Pr(Y=1|X=x)表示有意义字符串x分类结果为1的概率,Pr(Y=0|X=x)表示有意义字符串分类结果为0的概率,显然,二者概率之和为1。β10,β1T是模型中待拟合的参数,β1T是与向量x维度相同的10维向量。可以通过人工选择N个有意义字符串进行标注,标注为新特征或者噪音特征,作为训练集合,采用常用的最大似然估计来拟合逻辑回归模型中的参数β10,β1T。N个特征对数似然函数为:l(θ)=Σi=1NlogPr(Y=1|x=xi;θ)]]>其中,θ表示参数集{β10,β1T}。设p(xi;θ)=Pr(Y=1|x=xi;θ),yi表示标注的分类结果,则对数似然可以表示为:l(β)=Σi=1N{yilogp(xi;β)+(1-yi)log(1-p(xi;β))=Σi=1N{yiβTxi-log(1+eβTxi)}]]>其中,β={β10,β1},假定输入向量xi包含一个常数项1,以便接纳截距。为极大化对数似然,令上述公式的导数为0,得到16个β上的非线性方程组:∂l(β)∂β=Σi=1Nxi(yi-p(xi;β))=0]]>为求解上述公式,使用牛顿-拉夫森(Newton-Raphson)迭代算法,计算二阶导数,得到:∂2l(β)∂β∂βT=-Σi=1NxixiTp(xi;β)(1-p(xi;β))]]>以βold开始,单个牛顿-拉夫森更新是:βnew=βold-(∂2l(β)∂β∂βT)-1∂l(β)∂β]]>经过数次更新迭代,βnew收敛,得到逻辑回归模型的参数。利用训练好的逻辑回归模型对每个有意义串分类,得到微博新特征。实施例3本实施例提供了一种微博话题特征项提取装置,该装置用于实现上述微博话题特征项提取方法,图3是本发明实施例3的微博话题特征项提取装置的结构框图,如图3所示,该装置30包括如下组成部分:第一提取模块31,用于提取微博中的有意义字符串;第二提取模块32,用于提取有意义字符串的异质属性信息;分类模块33,用于根据异质属性信息对所述有意义字符串进行分类,得到与微博话题相关的特征项。其中,上述第一提取模块31包括:第一提取单元,用于提取指定微博集合中的重复字符串;第二提取单元,用于提取重复字符串所在的文本中位于重复字符串前面的词语,得到第一邻接集合,提取重复字符串所在的文本中位于重复字符串后面的词语,得到第二邻接集合;第一确定单 元,用于确定第一邻接集合以及第二邻接集合中元素的个数;第二确定单元,用于在第一邻接集合以及第二邻接集合中的元素个数均大于预设值时,确定当前重复字符串为有意字符义串。其中,上述重复字符串包括10个以内字符,也即有意义字符串包括10个以内字符。其中,上述有意义字符串的异质属性信息包括以下几种:结构属性、内容属性以及自身属性;其中,所述结构属性至少包括:作者影响力、文档影响力、在出现文档中的平均影响力以及有在出现作者中平均影响力;所述内容属性至少包括:出现的频次、出现的文档频次、出现的作者频次、反映有意义串普遍重要性的词频*逆文档频次、词频*逆作者频次;所述自身属性包括:有意义字符串的长度。其中,上述分类模块33用于:采用逻辑回归方法根据异质属性信息对有意义字符串进行二元分类,得到微博话题的有用特征项以及噪声特征项。尽管为示例目的,已经公开了本发明的优选实施例,本领域的技术人员将意识到各种改进、增加和取代也是可能的,因此,本发明的范围应当不限于上述实施例。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1