一种科技文本挑选方法及装置与流程
本发明涉及智能专家系统以及文本挖掘分析领域,尤其涉及一种科技文本挑选方法及装置。
背景技术:
近年来,我国越来越重视产学研合作,鼓励科研机构尽量多的进行成果转移。企业也越来越愿意与科研机构合作,一同开发新技术创造新价值。在合作的过程中,企业与科研机构的沟通,往往通过企业向科研机构提交技术文档作为起始。技术文档作为企业需求信息的有效载体,却因各企业技术专业水平不同而质量参差不齐,并且一份技术文档往往涉及多个学科,使得技术的界定模糊不清,加大了合作的难度。故而,当科研机构面对为数众多的科技文档时,如何预先对文档进行评价,挑选有价值有意义的合作企业、合作项目就显得尤为重要。
随着文本挖掘分析技术的日趋成熟,其在广电、金融、交通、零售等商业领域的应用越来越广泛。作为文本分析的一个分支,文本评价也受到了广泛的关注,已有大量基于对网页、微博、广告文本进行分析的方法得到发展。但对于一些专业性非常强的科技文本,例如前文所提到的企业技术文档,目前所开发的文本分析系统往往显得无能为力。因此,通过开发针对性强的分析挑选装置,降低专业文档的分析挑选难度,提高专业文本的分析效率、挑选效果就成为了众多学者关注的焦点。
技术实现要素:
本发明的目的是提供一种基于文本挖掘的科技文本挑选方法及装置。
本发明的上述技术目的是通过以下技术方案得以实现的:
文本挑选装置根据特定类别科技文本利用分层抽样选定所需要的样本集、专业词库、语料库,并对样本集中的文本进行预处理,包含去除无效字符、通过现有的自然语言处理工具进行分词,后将样本集存于高性能文件服务器中。
文本挑选装置包括有对文本进行分析以及特征评分的计算模块,包含基于文本的客观评分模块、文本的模糊评分模块以及文本与样本集间关联度评分模块。其中基于文本的客观评分模块包括文本的长度、语句长度方差、词汇信息熵、无效词所占比例加权求和获得评分,权值由样本集通过熵值取权法给定;基于文本的模糊评分模块包括文本所含专业词汇模糊评分、文本关键句式的判别与评分、文本语言客观度评分;基于文本的客观评分模块与文本的 模糊评分模块单独运行于另一独立的计算处理单元。
基于文本的客观评分模块:
计算文本的长度即文本所含的有效字符数的自然对数值;
文本语句长度的方差即
其中Nscentence为语句的个数,为第i个句子的字符数,为文本语句平均字符数,考虑到科技文本的特殊性,在划分文本句子以及统计每个语句的字符数时遵循以下规则:
(1)以“。”为句子的终结符号,
(2)若句子中同时存在“:”以及“;”号时,语句以“;”拆分成两句,多个“;”号则拆分成多句,分别进行统计,
(3)若语句中出现“,”则将字符数乘以0.75,n个“,”则乘以0.75的n次方;
词汇的信息熵即:
其中Mword为文本出现的不同词汇个数,为第i个词汇出现的个数,Nword为词汇总数;
无效词(停用词)所占比例即:
其中Ninvalid为文本无效词个数,Nword为词汇总数。
后利用熵值取权法确定各项指标权值,得到基于文本的客观评分为
l′i,Δ′i,S′i,d′i为第i个样本标准化后的文本的长度、语句长度方差、词汇信息熵、无效词比例评分值,ω为各项权值。
基于文本的模糊评分模块包括文本所含专业词汇模糊评分、文本关键句式的判别与评分、文本语言客观度评分。
其中文本所含专业词汇模糊评分为:
根据所选取的特定专业词库,匹配文本中所含有的专业词,统计专业词的最高信息度评分Smax,专业词个数n,平均信息度评分Savg。
利用以下公式计算文本所含专业词汇模糊评分:
其中M为文本词条总量。
文本关键句式的判别与评分为:
根据所选取的特定语料库与样本集,建立关键句式形容词表(例如:关键、重要、迫切……)、关键句式名词表(技术,问题,难题……)。匹配文本中句子是否同时出现关键句式形容词与名词,记录其数量为n1。匹配所得到的关键句中是否含有专业词,记录含有专业词的句子数量为n2。
利用以下公式计算文本关键句式模糊评分:
其中M为文本语句总量。
文本语言客观度评分为:
匹配选定语料库中的词汇,利用以下公式计算文本语言客观度评分:
其中,为匹配得出文本中形容词的平均情感强度,为除去形容词外第i个词语的情感强度,Nword为除去形容词外匹配获得的词语个数。
文本与样本集间关联度评分模块:
对于样本集利用TFIDF算法构建向量空间,TFIDF函数表示为:
其中,M为样本集个数,ni为含有词条ti的文档数目,tfi(d)为文本d中词条ti的出现频率。将文本向量化,分别计算其与样本集中其他文本向量的余弦距离记录得分,若S<0.001则认为两篇文本不相关。统计最高的得分Smax,相关文章篇数n,平均得分Savg。
利用以下公式计算文本与样本集间关联度模糊评分:
其中M为样本数量。
将文件服务器中的样本集取出通过各个评分模块进行评分,其中基于文本的客观评分模块与文本的模糊评分模块单独运行于另一台高性能计算服务器上,根据样本集数量的大小也可采用其他的分布式数据计算处理方法。
以各项评分与文本是否被标注为可选(1表示被选定、0表示不被选定),最为训练样本集,建立BP神经网络模型,根据输入向量的维数输入层定位5,隐层定义为12,输出层定义为1。隐层神经元传递函数采用S型正切函数tansig,输出层神经元传递函数采用S型对数函数logsig。根据不同的要求设置训练参数,通过反馈训练即得到可进行筛选的BP神经网络模型。
对于待挑选的科技文本先通过挑选装置评分模块进行特征评分,包括基于文本的客观评分、文本所含专业词汇模糊评分、文本关键句式的判别与评分、文本语言客观度评分以及文本与样本集间关联度评分,其中基于文本的客观评分包括文本的长度、语句长度方差、词汇信息熵、无效词所占比例加权求和获得;再经已训练好的BP神经网络筛选模型进行筛选。
综上所述,本发明具有以下有益效果:
1、本发明提供了一种科技文本的挑选方法及装置,通过选取科技文本样本集;对样本集中所有文本进行特征评分,包括基于文本的客观评分、文本所含专业词汇模糊评分、文本关键句式的判别与评分、文本语言客观度评分以及文本与样本集间关联度评分,建立BP神经网络模型训练得到可进行筛选的网络模型,对于科技文档的评价筛选考虑全面充分,能够很好的运用于实践,解决科技文本质量挑选的任务。
2、本发明还可推广到其他各种具有一定特征的专业文档的评价筛选与评价筛选系统的建立当中。
附图说明
图1是本发明挑选装置建立简化示意图以及挑选方法流程示意图;
图2是本发明挑选装置建立示意图;
图3是本发明挑选方法流程示意图;
图4是文本筛选BP神经网络模型示意图。
具体实施方式
以下结合附图对本发明作进一步详细说明。
如图1所示,本发明所提供的文本挑选装置包括:根据特定类别的科技文本需要,选定的已预处理的特征样本集、专业词库、语料库;基于文本的客观评分模块、文本的模糊评分模块以及文本与样本集间关联度评分模块;用于筛选的BP神经网络模型。装置的建立方案 为:将文件服务器中的样本集取出通过各个评分模块进行评分,以各项评分与文本是否被标注为可选(1表示被选定、0表示不被选定),最为训练样本集,根据不同的要求设置训练参数,通过反馈训练得到可进行筛选的BP神经网络模型。
文本挑选方法可在总的归纳成六步:对待挑选的文本进行预处理,计算基于文本的客观评分,文本专业词汇、关键句式及语言客观性评分,文本与样本集间的关联度评分,经已训练好的神经网络筛选模型进行筛选得到筛选结果。
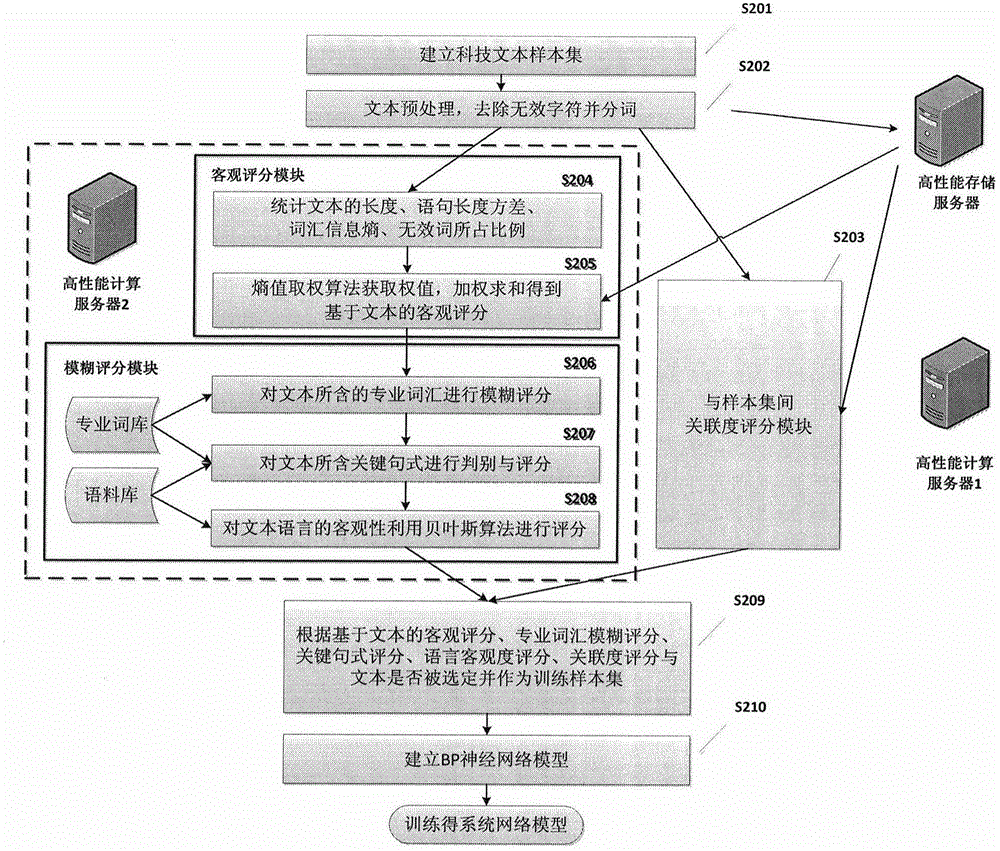
如图2所示,本发明可以将挑选系统的建立步骤详细的说明为:
S201:根据特定类别科技文本评价所选择特定样本集,通过分层抽样较大范围的覆盖该类别中各种质量的科技文本;并选定特定专业词库,库中包含专业词以及专业词信息度评分(1-10分),例如:太阳能(信息度评分:1.0)、染料敏化太阳能电池(信息度评分:8.0)等;特定语料库,库中包含语料元素、词性并包括预先标记的情感强度(1-10分),例如:太阳(词性:名词,情感强度:1.0)、分析(词性:动词,情感强度:2)、关键(词性:形容词,情感强度:7.0)等。
S202:对样本集中的文本进行预处理,包括去除无效字符并通过现有的自然语言处理工具进行分词,存于高性能文件服务器中。
S203:进行样本集中文本与样本集间关联度评分(属文本与样本集间关联度评分模块,运行于高性能计算服务器1):
对于样本集利用TFIDF算法构建向量空间,TFIDF函数表示为:
其中,M为样本集个数,ni为含有词条ti的文档数目,tfi(d)为文本d中词条ti的出现频率。将文本向量化,分别计算其与样本集中其他文本向量的余弦距离记录得分,若S<0.001则认为两篇文本不相关。统计最高的得分Smax,相关文章篇数n,平均得分Savg。
利用以下公式计算文本与样本集间关联度模糊评分:
其中M为样本数量。
S204:对文本进行的基于文本的客观评分(属基于文本的客观评分模块,运行于高性能计算服务器2):
计算文本的长度即文本所含的有效字符数的自然对数值;
文本语句长度的方差即:
其中Nscentence为语句的个数,为第i个句子的字符数,为文本语句平均字符数,考虑到科技文本的特殊性,在划分文本句子以及统计每个语句的字符数时遵循以下规则:
(1)以“。”为句子的终结符号,
(2)若句子中同时存在“:”以及“;”号时,语句以“;”拆分成两句,多个“;”号则拆分成多句,分别进行统计,
(3)若语句中出现“,”则将字符数乘以0.75,n个“,”则乘以0.75的n次方;
词汇的信息熵即:
其中Mword为文本出现的不同词汇个数,为第i个词汇出现的个数,Nword为词汇总数;
无效词(停用词)所占比例即:
其中Ninvalid为文本无效词个数,Nword为词汇总数。
S205:用熵值取权法确定各项指标权值(属基于文本的客观评分模块,运行于高性能计算服务器2)。
步骤为:
(1)对文本的长度、词汇信息熵进行正向标准化,语句长度方差、无效词比例进行负向标准化,标准化一般公式为:
正向标准化:
负向标准化:
(2)计算第i个样本第j个指标值得比重(M为样本数):
(3)计算指标信息熵以及其冗余度:
dj=1-ej
(4)计算指标权重为:
得到基于文本的客观评分为
l′i,Δ′i,S′i,d′i为第i个样本标准化后的文本的长度、语句长度方差、词汇信息熵、无效词比例评分值。
S206:计算文本所含专业词汇模糊评分(属基于文本的模糊评分模块,运行于高性能计算服务器2):
根据所选取的特定专业词库,匹配文本中所含有的专业词,统计专业词的最高信息度评分Smax,专业词个数n,平均信息度评分Savg。
利用以下公式计算文本所含专业词汇模糊评分:
其中M为文本词条总量
S207:计算文本关键句式的判别与评分(属基于文本的模糊评分模块,运行于高性能计算服务器2):
根据所选取的特定语料库与样本集,建立关键句式形容词表(例如:关键、重要、迫切……)、关键句式名词表(技术,问题,难题……)。
匹配文本中句子是否同时出现关键句式形容词与名词,记录其数量为n1。匹配所得到的关键句中是否含有专业词,记录含有专业词的句子数量为n2。利用以下公式计算文本关键句式模糊评分:
其中M为文本语句总量。
S208:文本语言客观度评分(属基于文本的模糊评分模块,运行于高性能计算服务器2):
匹配选定语料库中的词汇,利用以下公式计算文本语言客观度评分:
其中,为匹配得出文本中形容词的平均情感强度,为除去形容词外第i个词语的情感强度,Nword为除去形容词外匹配获得的词语个数。
S209:以各项评分与文本是否被标注为可选(1表示被选定、0表示不被选定),建立训练样本集。
S210:BP神经网络筛选模型,如图4所示,根据输入向量的维数输入层定位5,隐层定义为12,输出层定义为1。隐层神经元传递函数采用S型正切函数tansig,输出层神经元传递函数采用S型对数函数logsig。根据不同的要求设置训练参数,通过反馈训练优化ωij,θj,ωj,即得到可进行筛选的BP神经网络模型。
如图3所示,本发明可以将挑选方法步骤详细的说明为:
S301:对待挑选文本进行预处理,去除无效字符并通过自然语言处理工具进行分词。
S302:计算待挑选文本的基于文本的客观评分(通过挑选装置基于文本的客观评分模块计算,运行于高性能计算服务器2):
计算文本的长度即文本所含的有效字符数的自然对数值;
文本语句长度的方差即:
其中Nscentence为语句的个数,为第i个句子的字符数,为文本语句平均字符数。
词汇的信息熵即:
其中Mword为文本出现的不同词汇个数,为第i个词汇出现的个数,Nword为词汇总数;
无效词(停用词)所占比例即:
其中Ninvalid为文本无效词个数,Nword为词汇总数,总分通过加权求和获取,权值为挑选系统给出。
S303:计算待挑选文本所含专业词汇模糊评分(通过挑选装置基于文本的模糊评分模块计算,运行于高性能计算服务器2):
根据所选取的特定专业词库,匹配文本中所含有的专业词,统计专业词的最高信息度评分Smax,专业词个数n,平均信息度评分Savg。
利用以下公式计算文本所含专业词汇模糊评分:
其中M为文本词条总量
S304:计算待挑选文本关键句式的判别与评分(通过挑选装置基于文本的模糊评分模块计算,运行于高性能计算服务器2):
根据所选取的特定语料库与样本集,建立关键句式形容词表(例如:关键、重要、迫切……)、关键句式名词表(技术,问题,难题……)。
匹配文本中句子是否同时出现关键句式形容词与名词,记录其数量为n1。匹配所得到的关键句中是否含有专业词,记录含有专业词的句子数量为n2。利用以下公式计算文本关键句式模糊评分:
其中M为文本语句总量。
S305:计算待挑选文本语言客观度评分(通过挑选装置基于文本的模糊评分模块计算,运行于高性能计算服务器2):
匹配选定语料库中的词汇,利用以下公式计算文本语言客观度评分:
其中,为匹配得出文本中形容词的平均情感强度,为除去形容词外第i个词语的情感强度,Nword为除去形容词外匹配获得的词语个数。
S306:计算待挑选文本及装置样本集间关联度评分(通过挑选装置文本与样本集间关联度评分模块计算,运行于高性能计算服务器1):
对于样本集利用TFIDF算法构建向量空间,TFIDF函数表示为:
其中,M为样本集个数,ni为含有词条ti的文档数目,tfi(d)为文本d中词条ti的出现频率。将文本向量化,分别计算其与样本集中其他文本向量的余弦距离记录得分,若S<0.001则认为两篇文本不相关。统计最高的得分Smax,相关文章篇数n,平均得分Savg。
利用以下公式计算文本与样本集间关联度模糊评分:
其中M为样本数量。
S307:经挑选系统已训练好的BP神经网络筛选模型进行筛选,得到筛选结果。
本具体实施例仅仅是对本发明的解释,其并不是对本发明的限制,本领域技术人员在阅读完本说明书后可以根据需要对本实施例做出没有创造性贡献的修改,但只要在本发明的权利要求范围内都受到专利法的保护。
- 还没有人留言评论。精彩留言会获得点赞!