基于聚类的多模板行人检测方法与流程
本发明属于图像处理领域,更进一步涉及图像或视频中的行人检测方法,可用于无人驾驶和视频智能监控。
背景技术:
在计算机视觉领域,行人检测具有重要的理论和实践意义,由于实际应用中人体姿态变化多样,衣着体型差异较大,且人的活动范围广,所处的环境非常复杂,这些将使得行人检测算法鲁棒性难以满足实际要求。
现有的检测方法可分为两大类:一类是基于前景分析的方法。Tianyi Zhou和Dacheng Tao在文章“GoDec:Randomized Low-rank&Sparse Matrix Decomposition in Noisy Case”(Proceedings of the 28th International Conference on Machine Learning)中提出一种前景分割方法,该方法将连续多帧图像组成一个三维矩阵,采用矩阵分解的方法从背景中提取出运动的前景目标。这类方法存在的不足是:该类方法的前提假设是背景是静止的,目标是运动的。然而实际中行人有可能处于静止状态,背景也可能处于运动状态,使得这类方法不适用。另一类采用机器学习的方法,通过求取行人的特征,离线训练得到行人模板,对图像进行多尺度滑窗搜索,将每个窗口与模板匹配得到检测结果。Navneet Dalal和Bill Triggs在文章“Histograms of Oriented Gradients for Human Detection”(IEEE Conference on Computer Vision and Pattern Recognition,2005,pp.886-893)中提出一种梯度方向直方图特征,并将其应用于行人检测中,获得了较准确的检测结果。但是该方法训练得到的单个模板不足以适应行人的外观变化,检测准确率还有待进一步提升。
上海交通大学提出的专利申请“基于前景分析和模式识别的行人检测方法”(申请号:CN201110081075.3,公开号:CN102147869A)公开了一种前景分割和机器学习结合的行人检测方法。该方法采用高斯混合模型对视频图像的场景进行背景建模,利用阈值化操作和形态学后处理获得初步行人检测结果;在初步检测结果位置附近采样并与模板匹配,排除非行人前景目标,得到最终行人检测结果,这种方法虽说可提高行人检测速度,但由于要求行人与背景之间存在相对运动,故不能检测静止的行人,容易造成较高的漏检率。
技术实现要素:
本发明的目的在于针对上述已有技术的不足,提出一种基于聚类的多模板行人检测方法,以实现在任意场景下的行人检测,提升行人检测的准确率。
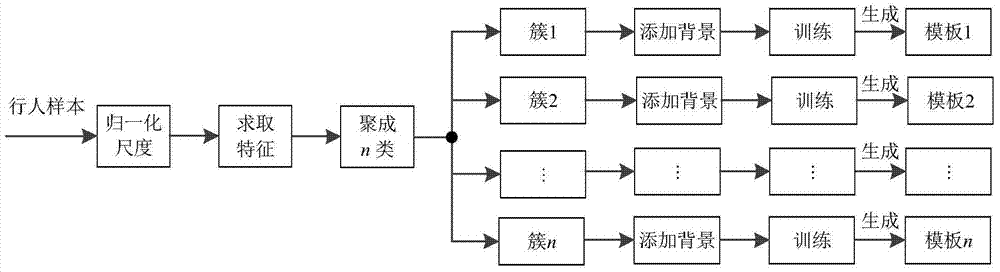
本发明的技术方案是:通过聚类算法对行人样本进行聚类,将具有相似外观、姿态的行人聚成一类,再分别对每一类样本独立训练一个模板,得到多个行人模板;通过不同模板独立检测图片中的目标,并采用线性加权的方式融合不同模板的重复检测结果,其实现步骤包括如下:
(1)从行人图像数据库中提取5000张以上行人样本图像,将每一张图像归一化尺度为64x32的像素大小;
(2)求取行人样本的梯度方向直方图特征,得到样本的特征描述;
(3)设定聚类数目,对行人样本按照梯度方向直方图特征进行聚类,得到多个聚类簇;
(4)对于每一个簇,分别根据簇中的行人样本生成训练数据集,得到多组数据集,再分别对每一组训练数据集采用线性支持向量机训练分类器生成模板:
(4a)对于每个簇中的每个行人样本,以其在原图中的位置为中心,在中心的上下左右四个方向各扩大10%样本大小的背景像素,若扩大后的行人样本超出原图边界,则通过复制原图边界像素值的方法填充图像,将添加背景后的行人样本归一化至128x64大小,得到训练所用的正样本;
(4b)从不包含行人的图像中随机选取产生大小为128x64像素的负样本,负样本的个数大于10000个;
(4c)对于每个簇中的行人样本,分别求取其梯度方向直方图特征,得到多组训练数据;
(4d)分别对每一组训练数据集采用线性支持向量机训练分类器生成模板。本发明采用了LibSVM工具完成训练。LibSVM是一个快速有效的SVM模式识别与回归的软件包,该软件包可以在http://www.csie.ntu.edu.tw/~cjlin/libsvm免费获得。
(5)求取待检测图像的特征金字塔,特征金字塔的层数为3;
(6)用训练得到的多个模板分别独立检测图像中的行人,对特征金字塔进行多尺度滑窗搜索,得到多模板的初步检测结果:
(6a)分别用每个模板对特征金字塔进行滑窗搜索,将每个窗口与各模板匹配,即将各模板分别与特征金字塔的每一层做卷积运算,得到每个窗口与模板的匹配程度;
(6b)选取检测阈值,若某一窗口与模板的匹配程度大于阈值2.5,则认为该检测窗口为目标,记录其在原图中的位置及其与模板的匹配程度,得到各模板的初步的检测结果;
(7)获得多组单个模板的检测结果:
(7a)分别计算各模板初步检测结果之间的重复率ao:
其中,BBi表示模板匹配第i个窗口的检测结果在图中的位置,BBj表示模板匹配第j个窗口的检测结果在图中的位置,score表示该检测结果与模板的匹配程度;
(7b)判断ao是否大于阈值0.5:若大于,则采用NMS方法滤除score更低的检测结果,得到多组单个模板的检测结果;反之,则舍弃该模板的检测结果;
(8)获得最终的检测结果:
(8a)计算两个不同模板检测结果之间的重复率a'o:
其中,CCk表示第k个模板的检测结果在图中的位置,CCn表示第n个模板的检测结果在图中的位置;
(8b)判断a'o是否大于阈值0.5:若a'o大于阈值0.5,则用加权融合的方法融合这两个不同模板的检测结果;反之,则同时保留这两个模板的检测结果;返回步骤(9a)直到所有两个不同的模板的检测结果都被判断为融合或同时保留,整理所有模板检测出的行人在图中的位置,完成最终的行人检测。
本发明与现有技术相比具有以下优点:
第一,本发明由于引入了聚类算法自动分类训练样本,克服了现有技术中手工分类训练样本的繁琐过程,同时降低了人为因素的干扰。
第二,本发明由于引入了多个模板同时用于检测,提高了对行人外观变化及复杂背景的适应性,进而提高了检测准确率。
第三,本发明的检测由于对不同模板进行独立匹配,可以并行操作,因此加快了检测速度。
附图说明
图1为本发明的整体流程图;
图2为本发明中训练多模板的子流程图;
图3为本发明中聚类多组簇的子流程图;
图4为本发明中用多模板检测行人的子流程图;
图5为本发明与现有梯度方向直方图算法对INRIA数据库图片的检测结果图。
具体实施方案和
下面结合附图,对本发明实现的步骤和效果作进一步的详细描述。
参照图1,本发明的实现步骤如下:
步骤1,获取行人样本图像,归一化尺度为64x32大小。
(1a)从给定的图像数据库中提取5000个以上行人样本,每个样本为一矩形图像,如果提取到的行人样本不足5000个,则可将每个样本左右对换得到新的样本;
(1b)采用最近邻插值算法对行人样本的大小进行归一化,得到尺度大小为64x32的图像Inew(x,y),Inew(x,y)=I(round(x/αx),round(y/αy)),其中,αx和αy分别为图像x方向和y方向的尺度缩放因子,I表示图像,round表示向上取整。
步骤2,求取样本图像的梯度方向直方图特征,得到样本的特征描述。
(2a)采用一维的梯度算子[1,0,-1]和[1,0,-1]T分别计算图像x方向和y方向的梯度分量Gx(x,y)=I(x+1,y)-I(x-1,y)和Gy(x,y)=I(x,y+1)-I(x,y-1),I表示图像;
(2b)求取图像每个像素点的梯度大小和方向
(2c)将图像划分成8x8像素大小的细胞单元,求取每个细胞单元的梯度方向直方图,即将梯度方向均匀划分为9个区域,梯度方向的取值为[0°,180°],以梯度强度为权值对其所属的区域进行加权,得到细胞单元的梯度方向直方图,即一个9维的特征向量;
(2d)将相邻的四个细胞单元的直方图串联组成一个以块为单元的特征向量v,并采用L2-norm方法归一化,得到归一化后的特征向量vnew,其中||·||是范数,ε为一很小的数,防止除数为零,本实例取ε为0.01,得到块单元的梯度方向直方图;
(2e)将块单元以8个像素为移动步长,遍历图像,将每个块单元的直方图按其位置组成三维矩阵,得到图像的梯度方向直方图特征。
步骤3,指定聚类数目,对行人样本聚类得到多个簇。
参照图2,本步骤的具体实现如下:
(3a)设定聚类数目为3;
(3b)随机选取指定数目的聚类中心c;
(3c)计算每个行人样本到各聚类中心的欧式距离,将行人样本划分到离其最近的簇中;
(3d)更新聚类中心c,即计算簇中所有对象的均值;
(3e)返回步骤(3c)直到达到初始设定的循环次数3或者前后两次迭代各聚类中心变化小于阈值10-2。
步骤4,对于每一个簇,分别根据簇中的行人样本生成训练数据集,得到多组数据集,再分别对每一组训练数据集采用线性支持向量机训练分类器生成模板。
参照图3,本步骤的具体实现如下:
(4a)对于每个簇中的每个行人样本,以其在原图中的位置为中心,在中心的上下左右四个方向各扩大10%样本大小的背景像素,若扩大后的行人样本超出原图边界,则通过复制原图边界像素值的方法填充图像,将添加背景后的行人样本归一化至128x64大小,得到训练所用的正样本;
(4b)从不包含行人的图像中随机选取产生大小为128x64像素的负样本,负样本的个数大于10000个;
(4c)对于每个簇中的行人样本,分别求取其梯度方向直方图特征,得到多组训练数据。
(4d)对于每一组训练数据集分别采用线性支持向量机训练分类器生成模板,本步骤采用LibSVM工具完成训练,LibSVM是一个快速有效的SVM模式识别与回归的软件包,该软件包可以在http://www.csie.ntu.edu.tw/~cjlin/libsvm免费获得。
步骤5,求取待检测图像的特征金字塔。
循环对待检测图像进行下采样,并求取下采样图片的梯度方向直方图特征,直到min(Ih,height)*αn小于模板的高度或者min(Iw,width)*αn小于模板的宽度,即得到图像的特征金子塔,min(·)为取最小值,n为下采样次数,α为下采样的比例因子,其取值范围为[0.9,0.95],比例因子越大可以提高检测精度,检测所需消耗的时间也越多。
步骤6,将训练得到的多个模板分别独立检测图像中的行人,对特征金字塔进行多尺度滑窗搜索,得到各模板的初步检测结果。
(6a)分别用每个模板对特征金字塔进行滑窗搜索,将每个窗口与各模板匹配,即将各模板分别与特征金字塔的每一层做卷积运算,得到每个窗口与模板的匹配程度;
(6b)选取检测阈值,若某一窗口与模板的匹配程度大于阈值2.5,则认为该检测窗口为目标,记录其在原图中的位置及其与模板的匹配程度,得到各模板的初步的检测结果。阈值选取越大,漏检率越高,误检结果越少;反之,漏检率越低,误检结果越多。
步骤7,分别计算各模板检测结果之间的重复率ao,得到多组单个模板的检测结果。
(7a)分别计算各模板初步检测结果之间的重复率ao:
其中,BBi表示模板匹配第i个窗口的检测结果在图中的位置,BBj表示模板匹配第j个窗口的检测结果在图中的位置,Si表示该第i个窗口检测结果与模板的匹配程度,Sj表示该第j个窗口检测结果与模板的匹配程度;
(7b)判断ao是否大于阈值0.5:若同一模板的两个检测结果的重复率ao大于0.5,则去除匹配程度更低的检测结果;反之,则舍弃该模板的检测结果。
步骤8,计算多个模板检测结果之间的重复率a'o,得到最终的检测结果。
参照图4,本步骤的具体实现如下:
(8a)不同模板检测结果两两之间的重复率a'o定义为:
其中,CCk表示第k个模板的检测结果在图中的位置,CCn表示第n个模板的检测结果在图中的位置;
(8b)判断a'o是否大于阈值0.5:
若不同模板的两个检测结果的重复率a'o大于阈值0.5,则认为它们重复,对于多个模板之间的所有重复检测结果,记为集合O,并用下式进行线性加权融合,得到融合之后的检测结果[CC,s],其中CCi表示第i个模板的检测结果在图中的位置;
若不同模板的两个检测结果的重复率a'o小于阈值0.5,则同时保留这两个模板的检测结果;
(8c)返回步骤(8a)直到所有两个不同的模板的检测结果都被判断为融合或同时保留,分别统计同时保留的检测结果和融合之后的检测结果,在图中找出并标记它们的位置,完成最终的行人检测。
本发明的效果结合以下仿真实验进一步说明:
1.仿真条件
本发明是在中央处理器为Intel(R)Core i3-3502.93GHZ、内存2G、WINDOWS7操作系统的PC上,运用MATLAB软件进行的实验仿真。
2.仿真内容
取训练行人样本为INRIA和ETH数据库的所有训练样本,测试图像为INRIA数据库中的测试图像,采用梯度方向直方图算法和本发明方法对10张测试图像中的行人进行检测,结果如图5所示,其中图5(a)为梯度方向直方图算法的检测结果,图5(b)为本发明方法的检测结果。
行人检测的目的是将图像中的行人区域准确的检测出来,由图5结果可见,采用本发明进行行人检测的平均丢失率低于梯度方向直方图算法。因此,与梯度方向直方图相比,本发明通过引入聚类算法训练多个模板,能有效提高对行人外观变化的适应性,从而提高了检测的准确率。
以上描述仅是本发明的一个具体实例,显然对于本领域的专业人员来说,在了解了本发明内容和原理之后,都可能在不背离本发明原理、结构的情况下,进行形式和细节上的各种修正和改变,但是这些基于本发明思想的修正和改变仍在本发明的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!