一种硬件加速方法、编译器以及设备与流程
本发明涉及计算机技术领域,特别涉及一种硬件加速方法、编译器以及设备。
背景技术:
源代码有时也称为源程序。源代码是指未编译的按照一定的程序设计语言规范书写的程序指令序列。因此,源代码是一系列人类可读的计算机语言指令。在现代程序语言中,计算机源代码的最终目的是将人类可读的程序指令序列翻译成为计算机可以执行的二进制指令,这种过程叫做编译,通过编译器完成。
基于以上说明,目前代码编译以及执行流程如下:编译器在获得源代码后,将源代码编译为目标代码,然后将目标代码发送给执行代码的硬件如CPU(Central Processing Unit,中央处理器),由CPU执行目标代码获得执行结果。
但是以上方案代码执行效率仍然较低。
技术实现要素:
本发明实施例提供了一种硬件加速方法、编译器以及设备,用于提高代码执行效率从而实现硬件加速。
本发明实施例一方面提供了一种硬件加速方法,包括:
编译器获取编译策略信息以及源代码;所述编译策略信息指示第一代码类型与第一处理器匹配,第二代码类型与第二处理器匹配;
所述编译器根据所述编译策略信息分析所述源代码中的代码段,确定属于第一代码类型的第一代码段或属于第二代码类型的第二代码段;
所述编译器将第一代码段编译为第一可执行代码,将所述第一可执行代码发往所述第一处理器;将第二代码段编译为第二可执行代码,将所述第二可执行代码发往所述第二处理器。
结合一方面的实现方式,在第一种可选的实现方式中,所述将所述第二 可执行代码发往所述第二处理器包括:
所述编译器通过调度管理器将所述第二可执行代码发送给所述第二处理器;或者,
所述编译器在所述第二可执行代码中添加调用第二处理器的指示信息,通过调度管理器将所述第二可执行代码发送给所述第一处理器,使所述第一处理器获取到所述指示信息后将所述第二可执行代码发往所述第二处理器。
结合一方面的实现方式,在第二种可选的实现方式中,所述第一处理器为CPU,第二处理器为FPGA;所述编译器根据所述编译策略信息分析所述源代码中的代码段,确定属于第一代码类型的第一代码段或属于第二代码类型的第二代码段包括:
所述编译器统计所述源代码中的代码段的循环执行次数和/或CPU的执行时间,若统计得到的参数超过第一预定阈值,则确定该代码段属于第二代码段,否则确定该代码段属于第一代码段;或者,
所述编译器将所述源代码中的代码段与所述第二代码段的特征规则进行比较,若与所述第二代码段的特征规则匹配,则确定该代码段为第二代码段,否则,确定该代码段为第一代码段;或者,
所述编译器读取所述源代码中的加速标识信息,依据所述加速标识信息的指示确定所述源代码中的代码属于第一代码段或第二代码段。
结合一方面的第二种可选的实现方式,在第三种可选的实现方式中,所述编译器统计所述源代码中的代码段的循环执行次数和/或CPU的执行时间包括:
所述编译器调用统计指令集通过所述源代码中的功能代码确定所述源代码中的代码段的循环执行次数和/或CPU的执行时间;或者,所述编译器获取定时统计的代码执行统计报表确定所述源代码中的代码段的循环执行次数和/或CPU的执行时间。
结合一方面、一方面的第一种、第二种或者第三种可选的实现方式,在第四种可选的实现方式中,若所述第二代码段对应进程的优先级高于正在所述第二处理器中执行的可执行代码对应的进程的优先级,在将所述第二可执行代码发往所述第二处理器之前,所述方法还包括:
若所述第二处理器的繁忙度高于第二预定阈值,则停止正在所述第二处理器中执行的可执行代码;将正在所述第二处理器中执行的可执行代码对应的代码段编译为与第一处理器匹配的可执行代码,发送给所述第一处理器。
结合一方面、一方面的第一种、第二种或者第三种可选的实现方式,在第五种可选的实现方式中,若第一代码段属于主代码段,所述第二代码段从属所述主代码段,则所述方法还包括:
在所述第一可执行代码以及所述第二可执行代码中添加交互指令,使所述第二处理器向所述第一处理器返回所述第二可执行代码的执行结果。
本发明实施例二方面提供了一种硬件加速方法,包括:
编译器获取编译策略信息以及源代码;所述编译策略信息指示第一代码类型与第一处理器匹配,第二代码类型与第二处理器匹配;
所述编译器根据所述编译策略信息将所述源代码中的代码段编译为与第一处理器匹配的第一可执行代码,将所述第一可执行代码发往所述第一处理器;
若接收到所述第一处理器统计的所述第一可执行代码的第一执行信息,并依据所述第一执行信息确定所述第一可执行代码对应的代码段与第二处理器匹配,则将所述第一可执行代码对应的代码段编译为第二可执行代码,将所述第二可执行代码发往第二处理器。
结合二方面的实现方式,在第一种可选的实现方式中,在将所述第二可执行代码发往第二处理器之后,所述方法还包括:
接收来自所述第二处理器执行所述第二可执行代码的第二执行信息,若依据所述第二执行信息确定所述第二可执行代码对应的代码段与所述第二处理器匹配度低于期望值,则在所述第二处理器卸载所述第二可执行代码,将所述第二可执行代码对应的代码段对应的第一可执行代码发往所述第一处理器。
本发明实施例三方面还提供了一种编译器,包括:
获取单元,用于获取编译策略信息以及源代码;所述编译策略信息指示第一代码类型与第一处理器匹配,第二代码类型与第二处理器匹配;
确定单元,用于根据所述编译策略信息分析所述源代码中的代码段,确 定属于第一代码类型的第一代码段或属于第二代码类型的第二代码段;
编译单元,用于将第一代码段编译为第一可执行代码,将第二代码段编译为第二可执行代码;
发送单元,用于将所述第一可执行代码发往所述第一处理器,将所述第二可执行代码发往所述第二处理器。
结合三方面的实现方式,在第一种可选的实现方式中,所述发送单元用于通过调度管理器将所述第二可执行代码发送给所述第二处理器;或者,
所述编译单元还用于在所述第二可执行代码中添加调用第二处理器的指示信息;
所述发送单元还用于将所述第二可执行代码发送给调度管理器,通过调度管理器将所述第二可执行代码发送给所述第一处理器,使所述第一处理器获取到所述指示信息后将所述第二可执行代码发往所述第二处理器。
结合三方面的实现方式,在第二种可选的实现方式中,所述第一处理器为CPU,第二处理器为FPGA;所述确定单元用于统计所述源代码中的代码段的循环执行次数和/或CPU的执行时间,若统计得到的参数超过第一预定阈值,则确定该代码段属于第二代码段,否则确定该代码段属于第一代码段;或者,
所述确定单元用于将所述源代码中的代码段与所述第二代码段的特征规则进行比较,若与所述第二代码段的特征规则匹配,则确定该代码段为第二代码段,否则,确定该代码段为第一代码段;或者,
所述确定单元用于读取所述源代码中的加速标识信息,依据所述加速标识信息的指示确定所述源代码中的代码属于第一代码段或第二代码段。
结合三方面的第二种可选的实现方式,在第三种可选的实现方式中,所述确定单元用于调用统计指令集通过所述源代码中的功能代码确定所述源代码中的代码段的循环执行次数和/或CPU的执行时间;或者,
所述确定单元用于获取定时统计的代码执行统计报表确定所述源代码中的代码段的循环执行次数和/或CPU的执行时间。
结合三方面、三方面的第一种、第二种或者第三种可选的实现方式,在第四种可选的实现方式中,若所述第二代码段对应进程的优先级高于正在所 述第二处理器中执行的可执行代码对应的进程的优先级,所述设备还包括:
第一处理单元,用于若所述第二处理器的繁忙度高于第二预定阈值,则停止正在所述第二处理器中执行的可执行代码;
第二处理单元,用于将正在所述第二处理器中执行的可执行代码对应的代码段编译为与第一处理器匹配的可执行代码,发送给所述第一处理器。
结合三方面、三方面的第一种、第二种或者第三种可选的实现方式,在第五种可选的实现方式中,若第一代码段属于主代码段,所述第二代码段从属所述主代码段,所述编译器还包括:
第三处理单元,用于在所述第一可执行代码以及所述第二可执行代码中添加交互指令,使所述第二处理器向所述第一处理器返回所述第二可执行代码的执行结果。
本发明实施例四方面提供了一种编译器,包括:
获取单元,用于获取编译策略信息以及源代码;所述编译策略信息指示第一代码类型与第一处理器匹配,第二代码类型与第二处理器匹配;
第一编译单元,用于根据所述编译策略信息将所述源代码中的代码段编译为与第一处理器匹配的第一可执行代码;
第一发送单元,用于将所述第一可执行代码发往所述第一处理器;
第一接收单元,用于接收所述第一处理器统计的所述第一可执行代码的第一执行信息;
第一处理单元,用于依据所述第一执行信息确定所述第一可执行代码对应的代码段是否与第二处理器匹配;
第二编译单元,用于所述第一处理单元依据所述第一执行信息确定所述第一可执行代码对应的代码段与第二处理器匹配,则将所述第一可执行代码对应的代码段编译为第二可执行代码;
第二发送单元,用于将所述第二可执行代码发往第二处理器。
结合四方面的实现方式,在第一种可选的实现方式中,所述编译器还包括:
第二接收单元,用于接收来自所述第二处理器执行所述第二可执行代码的第二执行信息;
第二处理单元,用于若依据所述第二执行信息确定所述第二可执行代码对应的代码段与所述第二处理器匹配度低于期望值,则在所述第二处理器卸载所述第二可执行代码,将所述第二可执行代码对应的代码段对应的第一可执行代码发往所述第一处理器。
本发明实施例五方面提供了一种设备,包括:
编译器和调度管理器,所述编译器包括:
获取单元、确定单元、编译单元以及发送单元;
所述获取单元,用于获取编译策略信息以及源代码;所述编译策略信息指示第一代码类型与第一处理器匹配,第二代码类型与第二处理器匹配;
所述确定单元,用于根据所述编译策略信息分析所述源代码中的代码段,确定属于第一代码类型的第一代码段或属于第二代码类型的第二代码段;
所述编译单元,用于将第一代码段编译为第一可执行代码,将第二代码段编译为第二可执行代码;
所述发送单元,用于将所述第一可执行代码和所述第二可执行代码发送给调度管理器;
所述调度管理器,用于将所述第一可执行代码发往所述第一处理器,将所述第二可执行代码发往所述第二处理器。
结合五方面的实现方式,在第一种可选的实现方式中,所述调度管理器,还用于配置编译策略信息,将所述编译策略信息发送给所述编译器。
结合五方面的实现方式,在第二种可选的实现方式中,若所述第一处理器为CPU,所述第二处理器为FPGA,
所述确定单元,还用于调用统计指令集通过所述源代码中的功能代码确定所述源代码中的代码段的循环执行次数和/或CPU的执行时间;或者
所述调度管理器,还用于获取定时统计的代码执行统计报表,将所述定时统计的代码执行统计报表发送给所述编译器;
所述确定单元,还用于依据所述代码执行统计报表确定所述源代码中的代码段的循环执行次数和/或CPU的执行时间;
所述确定单元用于确定属于第一代码类型的第一代码段或属于第二代码类型的第二代码段包括:若所述循环执行次数和/或CPU的执行时间超过第一 预定阈值,则确定该代码段属于第二代码段,否则确定该代码段属于第一代码段。
结合五方面的实现方式,在第三种可选的实现方式中,所述调度管理器,还用于若所述第二处理器的繁忙度高于第二预定阈值,在所述编译器停止正在所述第二处理器中执行的可执行代码,将正在所述第二处理器中执行的可执行代码对应的代码段编译为与第一处理器匹配的可执行代码后,接收来自所述与第一处理器匹配的可执行代码,并发送给第一处理器。
从以上技术方案可以看出,本发明实施例具有以下优点:编译器将源代码中与第一处理器匹配的代码段编译成第一处理器可以执行的第一可执行代码,将源代码中与第二处理器匹配的代码段编译成第二处理器可以执行的第二可执行代码;第一可执行代码被发往了第一处理器,第二可执行代码被发往了第二处理器,因此源代码中的代码段对应的可执行代码被分配到匹配度较高的硬件来执行,因此执行效率会更高,实现了硬件加速。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简要介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例中系统架构示意图;
图2为本发明实施例方法流程示意图;
图3为本发明实施例方法流程示意图;
图4为本发明实施例方法流程示意图;
图5为本发明实施例方法流程示意图;
图6为本发明实施例方法流程示意图;
图7为本发明实施例方法流程示意图;
图8为本发明实施例方法流程示意图;
图9为本发明实施例编译器结构示意图;
图10为本发明实施例编译器结构示意图;
图11为本发明实施例编译器结构示意图;
图12为本发明实施例编译器结构示意图;
图13为本发明实施例设备结构示意图;
图14为本发明实施例设备结构示意图;
图15为本发明实施例服务器结构示意图。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明作进一步地详细描述,显然,所描述的实施例仅仅是本发明一部份实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
本发明实施例提供了一种硬件加速方法、编译器以及设备,用于提高代码执行效率从而实现硬件加速。
为了方便理解本发明实施例,下面介绍本发明实施例中的系统架构。
请参阅图1,该系统架构包括编译器、调度管理器、第一处理器、第二处理器以及程序库。
其中调度管理器负责管理和调度一片或多片第一处理器和第二处理器;把可执行文件加载到第一处理器和第二处理器上,把可执行文件从第一处理器和第二处理器上卸载;负责向编译器提供编译策略和硬件信息。
编译器用于编译源代码、生成中间代码和可执行代码。
第一处理器为CPU、GPU(Graphics Processing Unit,图形处理器)、NP(Network Processor,网络处理器)等芯片。
第二处理器为FPGA(Field Programmable Gate Array,现场可编程门阵列)、CPLD(Complex Programmable Logic Device,复杂可编程逻辑器件)、PAL(Programmable Array Logic,可编程化阵列逻辑)和GAL(Generic Array Logic,通用阵列逻辑)等可编程逻辑器件。
程序库中包括:源代码,中间代码和可执行代码。
在上述系统架构的基础上,对硬件加速方法通过以下实施例进行说明:
请参阅图2,本发明实施例中一种硬件加速方法包括:
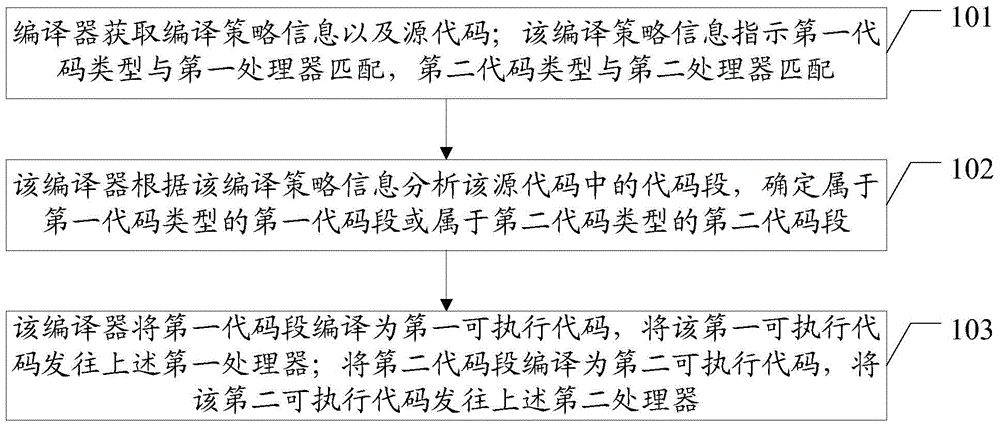
101、编译器获取编译策略信息以及源代码;该编译策略信息指示第一代码类型与第一处理器匹配,第二代码类型与第二处理器匹配;
本实施例中,编译器可以通过多种方法获取编译策略信息,例如:从本地存储器中获取预配置的编译策略信息,或者,接收调度管理器下发的编译策略信息。
在本实施例中,本地存储器中可以存储编译策略信息,也可以存储编译策略信息的指示信息,例如:指示如何获取编译策略信息的信息;或者编译策略信息的地址信息等。
该编译策略信息包括:编译检测出可以用FPGA进行加速时采用的策略,编译FPGA加速效果阈值,编译最长时间阈值(指由于FPGA的编译有时候花费的时间比较长,设置一个编译最长时间),编译异常策略(指在FPGA编译过程中和CPU编译过程中可能会产生一系列的异常,通过设置异常策略来处理这些异常)。
上述CPU用于指代第一处理器,上述FPGA用于指代第二处理器。
代码类型包括:可加速代码以及普通代码。其中可加速代码可以为:CPU指令,代码块,函数(模块)以及源文件。
第一处理器和第二处理器分别为:CPU、FPGA、GPU(Graphics Processing Unit,图形处理器)、NP(Network Processor,网络处理器)、ASIC(Application Specific Integrated Circuit,专用集成电路)、CPLD(Complex Programmable Logic Device,复杂可编程逻辑器件)、PAL(Programmable Array Logic,可编程化阵列逻辑)和GAL(Generic Array Logic,通用阵列逻辑)中的任意两项。可以理解的是,CPU,GPU,NP为具有软件编程能力的芯片,FPGA,ASIC,PAL,GAL,CPLD为可编程逻辑器件。
源代码可以由一个或多个文件组成,源代码所使用的编程语言可以是汇编语言,C语言以及脚本编程语言,还包括其他类型的语言,此处不再赘述。
102、该编译器根据该编译策略信息分析该源代码中的代码段,确定属于第一代码类型的第一代码段或属于第二代码类型的第二代码段;
在获取编译策略信息以及源代码后,编译器分析该源代码中的代码段, 确定属于第一代码类型的第一代码段或属于第二代码类型的第二代码段;
其中,该编译器会根据编译策略信息检测源代码中是否有可以加速的代码,根据检测结果将源代码中的普通代码生成中间源代码。中间源代码可以理解为源代码中的普通代码的另一种形式存在的源代码。
当第一处理器为CPU,第二处理器为FPGA时,可选的,该编译器统计该源代码中的代码段的循环执行次数和/或CPU的执行时间,若统计得到的参数超过第一预定阈值,则确定该代码段属于第二代码段,否则确定该代码段属于第一代码段;或者,该编译器将该源代码中的代码段与该第二代码段的特征规则进行比较,若与该第二代码段的特征规则匹配,则确定该代码段为第二代码段,否则,确定该代码段为第一代码段;或者,该编译器读取该源代码中的加速标识信息,依据该加速标识信息的指示确定该源代码中的代码属于第一代码段或第二代码段。其中该编译器统计该源代码中的代码段的循环执行次数和/或CPU的执行时间具体为:该编译器调用统计指令集通过该源代码中的功能代码确定该源代码中的代码段的循环执行次数和/或CPU的执行时间;或者,该编译器获取定时统计的代码执行统计报表确定该源代码中的代码段的循环执行次数和/或CPU的执行时间。统计指令集可以由CPU扩展,统计指令集可以对执行代码进行统计,编译器在编译时自动调用统计指令集,定时统计的代码执行统计报表可以通过外部程序实现,或者人工干预代码实现。
需要说明的是,上述第一预定阈值是与统计得到的参数对应的,若统计得到的参数很多,那么第一预定阈值可以是一组参数值;例如:统计得到的是循环执行次数,那么上述第一预定阈值可以是诸如100次、50次等参数,那么只要循环执行次数超过这个第一预定阈值指定的次数,那么表示需要将代码段编译为FPGA的可执行代码;若统计得到的是循环执行次数和CPU执行时间,那么可以是一组参数值,例如:100次、2S;那么循环执行次数超过100次,CPU执行时间超过2S都会出现超过阈值的情况,此种情况下,可以认为超过任一参数都认为超过第一预定阈值,也可以必须满足超过了以上两个参数才认为超过第一预定阈值。基于统计得到的参数不同,第一预定阈值还可以有其他参数类型,第一预定阈值的具体参数值可以按照经验或者加速 需求进行确定,以上举例不应理解为对本发明实施例的唯一性限定。
另外,上述特征规则指的是编译器预先设置一个可加速代码描述特征库,可加速代码描述特征库中包含着特征规则。
进一步的,上述加速标识信息指的是编程人员在源代码中选取目标代码,给目标代码添加标识,用来表示该目标代码可被加速。
103、该编译器将第一代码段编译为第一可执行代码,将该第一可执行代码发往上述第一处理器;将第二代码段编译为第二可执行代码,将该第二可执行代码发往上述第二处理器。
该编码器将该第一代码编译为第一处理器可执行代码,即第一可执行代码,将该第一可执行代码发往上述第一处理器;将该第二代码段编译为第二处理器可执行代码,即第二可执行代码,将该第二可执行代码发往上述第二处理器。在本发明实施例中,编译器将可执行代码“发往”处理器,不应狭隘的理解为以数据包的方式进行发送,应广义理解其含义为数据传递方式;数据传递方式除了以数据包的方式发送外,在编译器和处理器之间通常可以使用的数据传递方式还有很多,例如:将可执行代码存到存储空间内,例如:磁盘内,然后由CPU读取该执行代码;或者,将可执行代码存储到磁盘内,然后下载到FPGA芯片中。具体的数据传递方式可以依硬件的需求进行选用,本发明实施例对此不进行限定。
另外,若第一或者第二可执行代码的执行量很多,并且存在多个第一硬件或第二硬件的情况下,可以在同类硬件之间进行负载均衡处理。负载均衡的方式可以参考各种已经存在的负载均衡算法,本发明实施例不再赘述。
可以理解的是,在第一处理器和第二处理器分别接收到第一可执行代码和第二可执行代码后,第一处理器和第二处理器通过交互指令完成代码的交互。
可选的,在将该第二可执行代码发往该第二处理器之前,若该第二代码段对应进程的优先级高于正在该第二处理器中执行的可执行代码对应的进程的优先级,则有:若该第二处理器的繁忙度高于第二预定阈值,则停止正在该第二处理器中执行的可执行代码;将正在该第二处理器中执行的可执行代码对应的代码段编译为与第一处理器匹配的可执行代码,发送给该第一处理 器。
需要说明的是,上述繁忙度指的是第二处理器的数据处理资源被占用的程度,占用得越多则表示繁忙度越高;如果出现拥塞排队等情况,则排队等待时间越长繁忙度越高。第二预定阈值是繁忙程度的临界值,例如资源占用率超过某一阈值或者排队时间超过某一阈值等,这时可以确定第二处理器处于繁忙状态。另外,上述优先级指的是为不同的执行逻辑(任务、进程或线程等)分配不同的优先级。
可选的,若第一代码段属于主代码段,该第二代码段从属该主代码段,则有:在该第一可执行代码以及该第二可执行代码中添加交互指令,使该第二处理器向该第一处理器返回该第二可执行代码的执行结果。
上述主代码段可以理解为普通代码段,从代码段可以理解为可加速代码段。
另外,编译器可以通过多种方法将第二可执行代码发往该第二处理器,例如:通过调度管理器将该第二可执行代码发送给该第二处理器;或者,在该第二可执行代码中添加调用第二处理器的指示信息,通过调度管理器将该第二可执行代码发送给该第一处理器,使该第一处理器获取到该指示信息后将该第二可执行代码发往该第二处理器。
本实施例中,编译器将源代码中与第一处理器匹配的代码段编译成第一处理器可以执行的第一可执行代码,将源代码中与第二处理器匹配的代码段编译成第二处理器可以执行的第二可执行代码;第一可执行代码被发往了第一处理器,第二可执行代码被发往了第二处理器,因此源代码中的代码段对应的可执行代码被分配到匹配度较高的硬件来执行,因此执行效率会更高,实现了硬件加速。
请参阅图3,本发明实施例中一种硬件加速方法包括:
201、编译器获取编译策略信息以及源代码;该编译策略信息指示第一代码类型与第一处理器匹配,第二代码类型与第二处理器匹配;
本实施例中,步骤201和步骤101类似,此处不再赘述。
202、该编译器根据该编译策略信息将该源代码中的代码段编译为与第一处理器匹配的第一可执行代码,将该第一可执行代码发往该第一处理器;
该编译器通过编译器中的编译单元将该源代码中的代码段编译为与第一处理器匹配的第一可执行代码,将该第一可执行代码发往该第一处理器。
可以理解的是,编译器可以根据编译策略信息,生成中间源代码,再对中间源代码中的代码段进行编译。
203、若接收到该第一处理器统计的该第一可执行代码的第一执行信息,并依据该第一执行信息确定该第一可执行代码对应的代码段与第二处理器匹配,则将该第一可执行代码对应的代码段编译为第二可执行代码,将该第二可执行代码发往第二处理器。
第一处理器接收到第一可执行代码后,生成了第一执行信息,并将该第一执行信息发往编译器,编译器依据该第一执行信息确定该第一可执行代码对应的代码段与第二处理器匹配,则编译器通过调度管理器修改编译策略信息,将该第一可执行代码对应的代码段编译为第二可执行代码,并通过调度管理器将该第二可执行代码发往第二处理器。
上述第一执行信息是用来确定可执行代码与处理器之间是否匹配的参数,基于前述举例,这里的执行信息可以是第一可执行代码在第一处理器中的执行次数或执行时间,还可以是其他信息,在此处不再一一举例说明。
可选的,步骤203之后,还可以包括:
接收来自该第二处理器执行该第二可执行代码的第二执行信息,若依据该第二执行信息确定该第二可执行代码对应的代码段与该第二处理器匹配度低于期望值,则在该第二处理器卸载该第二可执行代码,将该第二可执行代码对应的代码段对应的第一可执行代码发往该第一处理器。
需要说明的是,第二可执行代码对应的代码段对应的第一可执行代码指的是将第二可执行代码对应的代码段重新编译,生成第一可执行代码,将第一可执行代码发往第一处理器。
在本实施例中,第二执行信息也是用来确定可执行代码与处理器之间是否匹配的参数,可以参考第一执行信息选用的参数举例说明。
本实施例中,将源代码中的代码段编译为与第一处理器匹配的第一可执行代码,当确定第一可执行代码对应的代码段与第二处理器匹配时,将第一可执行代码对应的代码段编译为第二可执行代码,通过第二处理器接收第二 可执行代码,因此源代码中的代码段对应的可执行代码被分配到匹配度较高的硬件来执行,因此执行效率会更高,实现了硬件加速。
此外,当第二可执行代码在第二处理器执行效率不高时,则在第二处理器上卸载该第二可执行代码,并对第二可执行代码对应的代码段重新编译,通过第一处理器来执行。
为了便于理解,下面对本发明实施例中的硬件加速方法进行详细描述,请参阅图4,本发明实施例中一种硬件加速方法包括:
301、编译器接收调度管理器下发的编译策略信息和硬件信息;
本实施例中,调度管理器配置编译策略信息和硬件信息,调度管理器将该编译策略信息和硬件信息发送给编译器。
本实施例中的编译策略信息为将可加速代码直接编译成FPGA可执行代码并在FPGA中加载运行。
硬件信息包括:CPU的型号和数量、CPU上的操作系统类型和版本号、CPU可使用的内存信息、FPGA型号和数量、与FPGA相连的外围芯片信息以及CPU和FPGA之间的交互方式。
302、编译器接收源代码;
源代码可以由一个或多个文件组成,源代码所使用的编程语言可以是汇编语言,C语言以及脚本编程语言,还包括其他类型的语言,此处不再赘述。以C语言为例,假设本实施例中的源代码为:
303、编译器分析该源代码,确定可加速代码;
编译器中预先设置一个可加速代码描述特征库,编译器将源代码与该可加速代码描述特征库中的特征规则进行比较,如果源代码中有某段代码能匹 配上,则表明上述某段代码可以用FPGA来加速。
需要说明的是,还可以采用其他方法,例如:编程人员可以在源代码中设置需要加速的代码,比如:
用#program fpga_acc_func来表明该函数需要被加速。又比如:
用#program fpga_acc_begin和#program fpga_acc_end来表明该对之间的代码需要被加速。
304、编译器将源代码中的普通代码转换为中间源代码;
编译器根据可加速代码描述特征库、编译策略和硬件信息来检测源代码 中是否有可以加速的代码,然后根据检测结果将源代码中的普通代码转换为中间源代码,中间源代码可以为:
305、编译器将中间源代码编译成CPU可执行代码,并向调度管理器发送CPU可执行代码;
编译器通过CPU编译单元将中间源代码编译成CPU可执行代码,CPU编译单元位于编译器中。
306、编译器将可加速代码编译成FPGA可执行代码,并向调度管理器发送FPGA可执行代码;
编译器通过FPGA编译单元将可加速代码编译成FPGA可执行代码,并向调度管理器发送FPGA可执行代码,FPGA编译单元位于编译器中。
需要说明的是,可加速代码在FPGA中的执行效率高于在CPU中的执行效率。
另外,也可以将可加速代码转换为逻辑语言代码,在将转换后的逻辑语言代码编译成FPGA可执行代码。
307、调度管理器将CPU可执行代码加载到CPU上执行;
调度管理器接收来自编译器的CPU可执行代码,调度管理器将CPU可执行代码加载到CPU上执行。
308、调度管理器将FPGA可执行代码加载到FPGA上执行;
调度管理器接收来自编译器的FPGA可执行代码,调度管理器将FPGA可执行代码加载到FPGA上执行。
需要说明的是,步骤307可以位于步骤308后面,步骤307与步骤308 之间的顺序可以调换。
309、CPU和FPGA执行代码的交互。
可以通过预配置的互操作协议来实现CPU可执行代码和FPGA可执行代码的交互,具体地,可以定义互操作原语:
Handshake,握手。
Negotiate,协商能力,包括各自支持的能力和规格,使用的互操作协议版本和特性等。
WriteData,直接向对方写数据。
ReadData,直接向对方读数据。
WriteDataAddress,通过地址向对方写数据。比如在DMA方式下,通过对方告诉的一个内存地址和长度,向该地址中写内容。
ReadDataAddress,通过地址向对方读数据。比如在DMA方式下,通过对方告诉的一个内存地址和长度,向该地址中读内容。
Call,调用对方的功能。
Callback,调用对方的功能,该功能执行后的返回值或者功能回调。
本实施例中,编译器将源代码中与FPGA匹配的代码段编译成FPGA可执行代码,将源代码中与CPU匹配的代码段编译成CPU可执行代码;FPGA可执行代码被发往了FPGA,CPU可执行代码被发往了CPU,因此源代码中的代码段对应的可执行代码被分配到匹配度较高的硬件来执行,因此执行效率会更高,实现了硬件加速。
为了便于理解,下面对本发明实施例中的硬件加速方法进行详细描述,请参阅图5,本发明实施例中一种硬件加速方法包括:
401、编译器接收调度管理器下发的编译策略信息和硬件信息;
本实施例中,编译策略信息为:统计源代码中的可加速代码在CPU中的执行次数,当执行次数达到第一预定阈值(本实施例假设第一预定阈值为100)后,将可加速代码编译成FPGA可执行代码并在FPGA中加载运行。
402、编译器接收源代码;
假设本实施例中的源代码为:
403、编译器分析该源代码,确定可加速代码;
步骤403与步骤303类似,此处不再赘述。
404、编译器将源代码中的普通代码转换为中间源代码;
中间源代码可以为:
405、编译器将中间源代码编译成CPU可执行代码,并向调度管理器发 送CPU可执行代码;
406、编译器将可加速代码编译成FPGA可执行代码,并向调度管理器发送FPGA可执行代码,FPGA可执行代码携带调用FPGA的指示信息;
步骤405、步骤406与步骤305、步骤306类似,此处不再赘述。
另外,步骤405可以位于步骤406后面,步骤405与步骤406之间的顺序可以调换。
此外,编译器在FPGA可执行代码中添加调用FPGA的指示信息。其中指示信息表示:当FPGA可执行代码在CPU中的执行次数大于100次(说明执行效率过低),则将FPGA可执行代码发往FPGA。
407、调度管理器将CPU可执行代码加载到CPU上执行,将FPGA可执行代码加载到CPU上执行;
408、CPU根据指示信息将FPGA可执行代码发往FPGA;
在确定FPGA可执行代码在CPU中的执行次数大于100次后,CPU根据指示信息将FPGA可执行代码发往FPGA。
409、CPU和FPGA执行代码的交互。
本实施例中,首先将FPGA可执行代码和CPU可执行代码发送给CPU,CPU根据FPGA可执行代码携带的指示信息以及FPGA可执行代码在CPU中的执行次数大于第一预定阈值,将FPGA可执行代码发往FPGA,由于FPGA可执行代码在FPGA中执行效率更高,因此执行效率会更高,实现了硬件加速。
为了便于理解,下面对本发明实施例中的硬件加速方法进行详细描述,请参阅图6,本发明实施例中一种硬件加速方法包括:
501、编译器接收调度管理器下发的编译策略信息和硬件信息;
502、编译器接收源代码;
503、编译器分析该源代码,确定可加速代码;
504、编译器将源代码中的普通代码转换为中间源代码;
505、编译器将中间源代码编译成第一CPU可执行代码,并向调度管理器发送第一CPU可执行代码;
506、编译器将可加速代码编译成第一FPGA可执行代码,并向调度管理 器发送第一FPGA可执行代码;
步骤501至步骤506与步骤401至步骤406类似,此处不再赘述。
507、调度管理器将第一CPU可执行代码加载到CPU上执行;
508、调度管理器将第一FPGA可执行代码加载到FPGA上执行;
需要说明的是,步骤507可以位于步骤508后面,步骤507与步骤508之间的顺序可以调换。
509、CPU确定第一CPU可执行代码中各代码的执行次数;
第一CPU可执行代码中可能存在执行效率较低的代码,这些执行效率低的代码执行次数也就高,故可以通过执行次数找出可加速代码。
510、CPU向调度管理器上报执行次数的统计信息;
当第一CPU可执行代码中存在代码的执行次数大于100次时,说明该代码可以被加速,可以由FPGA来执行该代码,因此CPU向调度管理器上报统计信息,统计信息为该代码的执行次数;需要说明的是,FPGA也有可能向调度管理器上报统计信息(此时在FPGA中存在执行效率低的代码)。
511、调度管理器修改编译策略信息,并将修改后的编译策略信息发往编译器;
调度管理器接收到统计信息后,确定执行次数大于100次,调度管理器修改编译策略信息,并将修改后的编译策略信息发往编译器。
512、编译器根据编译策略信息重新编译,生成第二CPU可执行代码和第二FPGA可执行代码,向调度管理器发送第二CPU可执行代码和第二FPGA可执行代码;
可以理解的是,编译器将源代码重新编译生成中间源代码,显然,此处的中间源代码和步骤404中的源代码是不同的。
513、调度管理器将第二CPU可执行代码加载到CPU上执行;
514、调度管理器将第二FPGA可执行代码加载到FPGA上执行;
515、CPU和FPGA执行代码的交互。
步骤513至步骤515与步骤307至步骤309类似,此处不再赘述。
本实施例中,当CPU可执行代码中存在代码的执行次数大于第一预定阈值时,说明执行速度过慢,所以通过调度管理器修改编译策略信息,使编译 器重新编译,生成新的CPU可执行代码和新的FPGA可执行代码,因此执行效率会更高,实现了硬件加速。
为了便于理解,下面对本发明实施例中的硬件加速方法进行详细描述,请参阅图7,本发明实施例中一种硬件加速方法包括:
601、编译器接收调度管理器下发的编译策略信息和硬件信息;
602、编译器接收源代码;
603、编译器分析该源代码,确定可加速代码;
604、编译器将源代码转换为中间源代码;
605、编译器将中间源代码编译成第一CPU可执行代码,并向调度管理器发送第一CPU可执行代码;
步骤601至步骤605与步骤401至步骤405类似,此处不再赘述。
另外,可以理解的是,源代码中的可加速代码也被编译成第一CPU可执行代码。
606、调度管理器将第一CPU可执行代码加载到CPU上执行;
607、CPU确定可加速代码在CPU中的执行次数;
可加速代码也被编译成第一CPU可执行代码,显然,可加速代码在CPU中的执行效率不高,也就是执行次数会比普通代码执行次数更多。
608、CPU向调度管理器上报执行次数的统计信息;
当执行次数大于100时,说明该可加速代码可以由FPGA来执行,来提高执行效率,因此CPU向调度管理器上报执行次数的统计信息。
609、调度管理器修改编译策略信息,并将修改后的编译策略信息发往编译器;
当调度管理器通过统计信息确定可加速代码在CPU中的执行效率不高时,调度管理器修改编译策略信息,并将修改后的编译策略信息发往编译器。
610、编译器根据修改后的编译策略信息将源代码中的普通代码重新生成中间源代码;
611、编译器将重新生成的中间源代码编译成第二CPU可执行代码,并发送给调度管理器;
612、编译器将可加速代码编译成FPGA可执行代码,并发送给调度管理 器;
613、调度管理器将第二CPU可执行代码加载到CPU上执行;
614、调度管理器将FPGA可执行代码加载到FPGA上执行;
615、CPU和FPGA执行代码的交互。
本实施例中,编译器将源代码转换为中间源代码,再将中间源代码编译为CPU可执行代码(同时,未编译FPGA可执行代码),当CPU可执行代码中存在代码的执行次数大于第一预定阈值时,说明该代码可以由FPGA来执行,来提高执行效率,通过重新编译的方法,生成FPGA可执行代码和新的CPU可执行代码,因此执行效率会更高,实现了硬件加速。
需要说明的是,上述各实施例中,编译策略信息还可以为:
一定时间内代码在CPU中的执行次数达到第一预定阈值,则编译成FPGA可执行代码并加载运行。或者统计代码的执行时间,当执行时间超过第一预定阈值,则编译成FPGA可执行代码并加载运行。
另外,统计源代码中的代码在CPU中的执行次数可以在编译阶段由编译器智能插入统计功能代码,也可以在CPU中扩展统计指令集,通过统计指令集对代码进行统计,编译器在编译时自动调用扩展统计指令集。进一步的,也可以通过外部程序或人工干预的方法。
进一步的,当FPGA接收到FPGA可执行代码,但是FPGA中没有足够的资源来执行加速,则判断该FPGA可执行代码对应的进程1的优先级是否高于正在FPGA中执行的可执行代码对应的进程2的优先级(优先级可以根据进程预先设置),若判断是,则将进程2在FPGA中加速的功能占用的资源释放出来,由进程1来使用。
为了便于理解,下面对本发明实施例中的硬件加速方法进行详细描述,请参阅图8,本发明实施例中另一种硬件加速方法包括:
701、CPU确定FPGA中FPGA可执行代码的执行次数;
需要说明的是,FPGA可执行代码的执行次数还可以由FPGA本身统计得到。
步骤701之前,已经有可执行代码分别在CPU和FPGA中运行,并且原编译策略信息为:在一段时间内统计FPGA可执行代码在FPGA中的执行次 数,当执行次数小于第一预定阈值(100)时,将FPGA可执行代码对应的代码重新编译为CPU可执行代码并在CPU中加载运行。
702、CPU向调度管理器上报执行次数的统计信息;
703、调度管理器修改编译策略信息,并将修改后的编译策略信息发往编译器;
当统计信息中的执行次数小于100时,修改编译策略信息,修改的编译策略信息为:不使用FPGA加速,重新编译和加载。
704、编译器根据修改后的编译策略信息重新将FPGA可执行代码对应的源代码转换为新的中间源代码;
假设源代码为:void func2(bool c,FILE*file1,FILE*file2)
步骤701之前,源代码转换的中间源代码可以为:
则编译器根据修改后的编译策略信息,重新生成的中间源代码可以为:
705、编译器将新的中间源代码编译成CPU可执行代码,并发送给调度管理器;
706、调度管理器将CPU可执行代码加载到CPU上执行;
707、调度管理器将FPGA可执行代码从FPGA中卸载。
本实施例中,当FPGA中执行的代码在一定时间内执行次数小于第一预定阈值时,说明此时FPGA执行效率不高,故重新编译,通过CPU来执行,因此能够提高执行效率,实现硬件加速。
为了便于理解,下面以一实际的应用场景对本发明实施例中的硬件加速方法进行描述:
调度管理器配置编译策略信息以及硬件信息(CPU和FPGA),调度管理机将该编译策略信息以及硬件信息发送给编译器,编译器接收源代码,编译器预先设置一个可加速代码特征库,将源代码和该可加速代码特征库中的特征规则进行比较,该特征规则为:如果源代码中存在匹配的代码段,则表明该代码段可以用FPGA加速。在编译器通过特征规则确定了属于普通代码类型的第一代码段,以及属于可加速代码类型的第二代码段后,将该第一代码段编译为CPU可执行代码,通过调度管理器发送给CPU,将该第二代码段编译为FPGA可执行代码,通过调度管理器发送给FPGA。
上面对本发明实施例中的硬件加速方法进行了描述,下面对本发明实施例中的编译器进行描述,请参阅图9,本发明实施例编译器包括:
获取单元801,用于获取编译策略信息以及源代码;该编译策略信息指示第一代码类型与第一处理器匹配,第二代码类型与第二处理器匹配;
确定单元802,用于根据该编译策略信息分析该源代码中的代码段,确定属于第一代码类型的第一代码段或属于第二代码类型的第二代码段;
编译单元803,用于将第一代码段编译为第一可执行代码,将第二代码段编译为第二可执行代码;
发送单元804,用于将该第一可执行代码发往该第一处理器,将该第二可执行代码发往该第二处理器。
可选的,上述获取单元801,用于从本地存储器中获取预配置的编译策略信息;或者,获取单元801,用于接收调度管理器下发的编译策略信息。
其中第一处理器和第二处理器分别为:CPU,FPGA,GPU,NP,ASIC,CPLD,PAL和GAL中的任意两项。可以理解的是,CPU,GPU,NP为具有软件编程能力的芯片,FPGA,ASIC,PAL,GAL,CPLD为可编程逻辑器件。
若该第二代码段对应进程的优先级高于正在该第二处理器中执行的可执 行代码对应的进程的优先级,可选的,本实施例还包括:
第一处理单元805,用于若该第二处理器的繁忙度高于第二预定阈值,则停止正在该第二处理器中执行的可执行代码;
第二处理单元806,用于将正在该第二处理器中执行的可执行代码对应的代码段编译为与第一处理器匹配的可执行代码,发送给该第一处理器。
可选的,上述发送单元804,用于通过调度管理器将该第二可执行代码发送给该第二处理器;或者,编译单元803还用于在该第二可执行代码中添加调用第二处理器的指示信息;发送单元804还用于将第二可执行代码发送给调度管理器,通过调度管理器将该第二可执行代码发送给该第一处理器,使该第一处理器获取到该指示信息后将该第二可执行代码发往该第二处理器。
当第一处理器为CPU,第二处理器为FPGA时,可选的,确定单元802用于统计该源代码中的代码段的循环执行次数和/或CPU的执行时间,若统计得到的参数超过第一预定阈值,则确定该代码段属于第二代码段,否则确定该代码段属于第一代码段;或者,
确定单元802用于将该源代码中的代码段与第二代码段的特征规则进行比较,若与该第二代码段的特征规则匹配,则确定该代码段为第二代码段,否则,确定该代码段为第一代码段;或者,
确定单元802用于读取该源代码中的加速标识信息,依据该加速标识信息的指示确定该源代码中的代码属于第一代码段或第二代码段;或者,
确定单元802用于调用统计指令集通过该源代码中的功能代码确定该源代码中的代码段的循环执行次数和/或CPU的执行时间;或者,
确定单元802用于获取定时统计的代码执行统计报表确定该源代码中的代码段的循环执行次数和/或CPU的执行时间。
可选的,本实施例还包括:第三处理单元807,用于在该第一可执行代码以及该第二可执行代码中添加交互指令,使该第二处理器向该第一处理器返回该第二可执行代码的执行结果。
本实施例中,编译器将源代码中与第一处理器匹配的代码段编译成第一处理器可以执行的第一可执行代码,将源代码中与第二处理器匹配的代码段编译成第二处理器可以执行的第二可执行代码;第一可执行代码被发往了第 一处理器,第二可执行代码被发往了第二处理器,因此源代码中的代码段对应的可执行代码被分配到匹配度较高的硬件来执行,因此执行效率会更高,实现了硬件加速。
请参阅图10,本发明实施例中编译器包括:
获取单元901,用于获取编译策略信息以及源代码;该编译策略信息指示第一代码类型与第一处理器匹配,第二代码类型与第二处理器匹配;
第一编译单元902,用于根据该编译策略信息将该源代码中的代码段编译为与第一处理器匹配的第一可执行代码;
第一发送单元903,用于将该第一可执行代码发往该第一处理器;
第一接收单元904,用于接收第一处理器统计的第一可执行代码的第一执行信息;
第一处理单元905,用于依据该第一执行信息确定该第一可执行代码对应的代码段是否与第二处理器匹配;
第二编译单元906,用于该第一处理单元905依据该第一执行信息确定该第一可执行代码对应的代码段与第二处理器匹配,则将该第一可执行代码对应的代码段编译为第二可执行代码;
第二发送单元907,用于将该第二可执行代码发往第二处理器。
可选的,本实施例还包括:
第二接收单元908,用于接收来自该第二处理器执行该第二可执行代码的第二执行信息;
第二处理单元909,用于若依据该第二执行信息确定该第二可执行代码对应的代码段与该第二处理器匹配度低于期望值,则在该第二处理器卸载该第二可执行代码,将该第二可执行代码对应的代码段对应的第一可执行代码发往该第一处理器。
本实施例中,将源代码中的代码段编译为与第一处理器匹配的第一可执行代码,当确定第一可执行代码对应的代码段与第二处理器匹配时,将第一可执行代码对应的代码段编译为第二可执行代码,通过第二处理器接收第二可执行代码,通过不同的硬件执行不同的代码类型,提高了执行效率。
此外,当第二可执行代码在第二处理器执行效率不高时,则在第二处理 器上卸载该第二可执行代码,并对第二可执行代码对应的代码段重新编译,通过第一处理器来执行。
为了便于理解,下面以一实际的应用场景对本实施例中设备各单元间的交互进行描述:
调度管理器配置编译策略信息,调度管理器将该编译策略信息发送给获取单元801,同时,获取单元801接收源代码。其中该编译策略信息指示第一代码类型与第一处理器匹配,第二代码类型与第二处理器匹配。代码类型包括:可加速代码以及普通代码。其中可加速代码可以为:CPU指令,代码块,函数(模块)以及源文件。在获取编译策略信息以及源代码后,确定单元802根据该编译策略信息分析该源代码中的代码段,确定属于第一代码类型的第一代码段或属于第二代码类型的第二代码段。
编译单元803通过编译器中的编译单元将第一代码段编译为第一可执行代码,发送单元804将该第一可执行代码通过调度管理器发往上述第一处理器。同理,编译单元803将第二代码段编译为第二可执行代码,由于不同的执行逻辑(任务,进程,线程等)具有不同的优先级,因此存在一种可能,即上述第二代码段对应进程的优先级高于正在该第二处理器中执行的可执行代码对应的进程的优先级。当第二处理器中没有足够的资源来执行第二可执行代码时(也即是通过第一处理单元805说明第二处理器的繁忙度高于预设阈值),则将第二处理器中正在执行的可执行代码占用的资源释放出来(也即是停止正在该第二处理器中执行的可执行代码);第二处理单元806将正在第二处理器中执行的可执行代码对应的代码段编译为与第一处理器匹配的可执行代码,发送给该第一处理器;这样第二处理器就有足够的资源来执行第二可执行代码,将该第二可执行代码发往上述第二处理器。
请参阅图11,本发明实施例中编译器包括:
输入单元1001、编译单元1002和输出单元1003;
其中输入单元1001,用于接收源代码、编译策略信息、硬件信息以及可加速代码描述特征库;
编译单元1002,用于编译CPU可执行代码以及FPGA可执行代码;
输出单元1003,用于将CPU可执行代码和FPGA可执行代码发送出去。
其中编译单元1002有三个核心的功能组件,可参考图12,分别是:编译控制单元、CPU编译单元以及FPGA编译单元。
编译策略信息和硬件信息可以通过外部程序输入,也可以由编译控制单元进行操作。
编译控制单元识别并执行编译策略信息,识别和处理可加速代码描述特征库,增减和修改规则,还可以根据可加速代码描述特征库、编译侧罗和硬件信息来检测源代码中是否有可加速的代码,然后根据检测结果生成中间源代码。
CPU编译单元用来编译生成CPU可执行代码,FPGA编译单元用来编译生成FPGA可执行代码。FPGA编译单元可以直接根据源代码或中间源代码来编译,也可以将可加速代码或者中间源代码翻译转换成逻辑语言代码,再将逻辑语言代码编译成FPGA可执行代码。
需要说明的是,一个编译控制单元可以管理一个或多个CPU编译单元,一个编译控制单元可以管理一个或多个FPGA编译单元,一个CPU编译单元或FPGA编译单元可以受一个或多个编译控制单元管理。
本发明实施例还提供一种设备,请参阅图13,本发明实施例中设备包括:
编译器和调度管理器,该编译器包括:
获取单元1101、确定单元1102、编译单元1103以及发送单元1104;
获取单元1101,用于获取编译策略信息以及源代码;该编译策略信息指示第一代码类型与第一处理器匹配,第二代码类型与第二处理器匹配;
确定单元1102,用于根据该编译策略信息分析该源代码中的代码段,确定属于第一代码类型的第一代码段或属于第二代码类型的第二代码段;
编译单元1103,用于将第一代码段编译为第一可执行代码,将第二代码段编译为第二可执行代码;
发送单元1104,用于将该第一可执行代码和该第二可执行代码发送给调度管理器;
调度管理器,用于将该第一可执行代码发往该第一处理器,将该第二可执行代码发往该第二处理器。
可选的,调度管理器,还用于配置编译策略信息,将编译策略信息发送 给编译器。
调度管理器,还用于若该第二处理器的繁忙度高于第二预定阈值,在该编译器停止正在该第二处理器中执行的可执行代码,将正在该第二处理器中执行的可执行代码对应的代码段编译为与第一处理器匹配的可执行代码后,接收来自该与第一处理器匹配的可执行代码,并发送给第一处理器。
进一步可选的,若第一处理器为CPU,第二处理器为FPGA,确定单元1102,还用于调用统计指令集通过该源代码中的功能代码确定该源代码中的代码段的循环执行次数和/或CPU的执行时间;或者
调度管理器,还用于获取定时统计的代码执行统计报表,将该定时统计的代码执行统计报表发送给该编译器;
确定单元1102,还用于依据该代码执行统计报表确定该源代码中的代码段的循环执行次数和/或CPU的执行时间;
确定单元1102用于确定属于第一代码类型的第一代码段或属于第二代码类型的第二代码段包括:若该循环执行次数和/或CPU的执行时间超过第一预定阈值,则确定该代码段属于第二代码段,否则确定该代码段属于第一代码段。
本发明实施例还提供一种设备,请参阅图14,本发明实施例中设备包括:
编译器和调度管理器,该编译器包括:
获取单元1201、编译单元1202、发送单元1203、接收单元1204以及处理单元1205;
获取单元1201,用于获取编译策略信息以及源代码;该编译策略信息指示第一代码类型与第一处理器匹配,第二代码类型与第二处理器匹配;
编译单元1202,用于根据该编译策略信息将该源代码中的代码段编译为与第一处理器匹配的第一可执行代码;
发送单元1203,用于将该第一可执行代码发送给第一处理器;
接收单元1204,用于接收第一处理器统计的第一可执行代码的第一执行信息;
处理单元1205,用于依据该第一执行信息确定该第一可执行代码对应的代码段是否与第二处理器匹配;
编译单元1202,还用于该处理单元1205依据该第一执行信息确定第一可执行代码对应的代码段与第二处理器匹配,则将该第一可执行代码对应的代码段编译为第二可执行代码;
发送单元1203,还用于将该第二可执行代码发送给调度管理器;
调度管理器,用于将第二可执行代码发往该第二处理器。
可选的,调度管理器,还用于接收来自该第二处理器执行该第二可执行代码的第二执行信息,依据该第二执行信息确定该第二可执行代码对应的代码段与该第二处理器匹配度低于期望值,则在该第二处理器卸载该第二可执行代码;将该第二可执行代码对应的代码段对应的第一可执行代码发往该第一处理器。
本发明实施例还提供一种服务器,请参阅图15,本发明实施例中服务器包括:
该服务器1300可因配置或性能不同而产生比较大的差异,可以包括编译器1301、调度管理器1302、FPGA1303、一个或一个以上中央处理器(central processing units,CPU)1304(例如,一个或一个以上处理器)和存储器1305,一个或一个以上存储应用程序1306或数据1307的存储介质1308(例如一个或一个以上海量存储设备)。其中,存储器1305和存储介质1308可以是短暂存储或持久存储。存储在存储介质1308的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对服务器中的一系列指令操作。更进一步地,中央处理器1304可以设置为与存储介质1308通信,在服务器1301上执行存储介质1305中的一系列指令操作。
服务器1300还可以包括一个或一个以上电源1309,一个或一个以上有线或无线网络接口1310,一个或一个以上输入输出接口1311,和/或,一个或一个以上操作系统1312,例如Windows ServerTM,Mac OS XTM,UnixTM,LinuxTM,FreeBSDTM等等。
值得注意的是,上述设备和编译器实施例中,所包括的各个单元只是按照功能逻辑进行划分的,但并不局限于上述的划分,只要能够实现相应的功能即可;另外,各功能单元的具体名称也只是为了便于相互区分,并不用于限制本发明的保护范围。
另外,本领域普通技术人员可以理解实现上述各方法实施例中的全部或部分步骤是可以通过程序来指令相关的硬件完成,相应的程序可以存储于一种计算机可读存储介质中,上述提到的存储介质可以是只读存储器,磁盘或光盘等。
以上仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明实施例揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!