机台零件剩余寿命预测系统与方法与流程
本发明有关于一种预测系统与方法,且特别是有关于一种机台零件剩余寿命预测系统与方法。
背景技术:
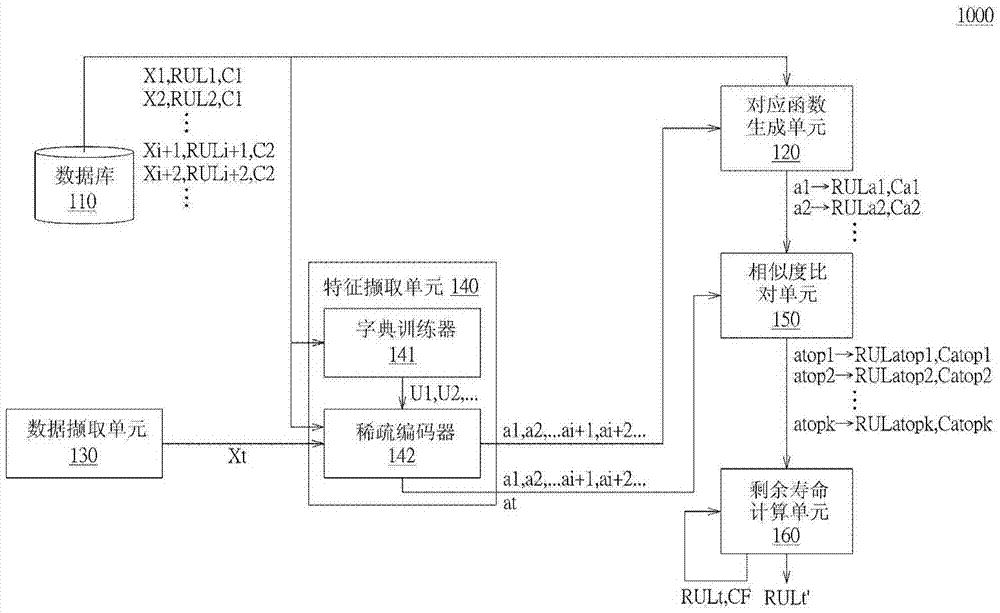
:生产制造预估是未来巨量数据的前五大垂直应用市场,约占10%。根据研究报告显示,重要资产设备的故障是影响公司营运风险最关键的因素,若能成功利用数据分析来管理和维护资产设备,即可有效提升效率,进而可使大幅提高企业的竞争力。设备预诊断及健康管理技术藉由分析机台数据来监控和评估设备/零件的健康状态,并根据健康状态来决定出最佳的维护或更换时机,减少非预期性停机与维修频率。若能够准确预测出零件的剩余寿命时,就可以事先规划维修排程,然而部分机台的零件故障数据少,且老化故障模式具有高度的变异性,导致难以训练出准确度高的预测模型。如何在少量的故障数据下,还能够准确预测出零件剩余寿命,,是值得研究,以发展出符合现况需求的技术。技术实现要素:本发明有关于一种机台零件剩余寿命预测系统与方法。根据本发明的一实施例,提出一种机台零件剩余寿命预测系统。机台零件剩余寿命预测系统包括一数据撷取单元(dataacquisitionunit,DAQunit)、一特征撷取单元、一对应函数生成单元、一相似度比对单元及一剩余寿命计算单元。数据撷取单元(dataacquisitionunit,DAQunit)用以取得一实时感测数据。特征撷取单元根据实时感测数据产生一估算样本特征,并根据数个历史感测数据产生数个训练样本特征。对应函数生成单元根据此些训练样本特征建立一对应函数。该对应函数表示此些训练样本特征与 至少一预测信息的对应关系。相似度比对单元根据此些训练样本特征,产生与估算样本特征近似的k个近似样本特征。剩余寿命计算单元根据此k个近似样本特征,透过该对应函数取得对应于此k个近似样本特征的k个预测信息中的至少一个,并根据此至少一预测信息,计算出一预测剩余寿命。根据本发明的另一实施例,提出一种机台零件剩余寿命预测方法。零件剩余寿命预测方法包括以下步骤。取得一实时感测数据。根据实时感测数据产生一估算样本特征,并根据数个历史感测数据产生数个训练样本特征。根据此些训练样本特征建立一对应函数,该对应函数表示此些训练样本特征与至少一预测信息的对应关系。根据此些训练样本特征,产生与估算样本特征近似的k个近似样本特征。根据此k个近似样本特征,透过该对应函数取得对应于此k个近似样本特征的k个预测信息中的至少一个,并根据此至少一预测信息,计算出一预测剩余寿命。为了对本发明的上述及其他方面有更佳的了解,下文特举较佳实施例,并配合所附图式,作详细说明如下:附图说明图1绘示金属有机物化学气相沉积(metalorganicchemical-vapordeposition,MOCVD)机台的感测曲线图。图2绘示机台零件剩余寿命预测系统的示意图。图3绘示机台零件剩余寿命预测方法的流程图。图4绘示周期编号的历史感测数据的示意图。图5绘示基底集合的示意图。图6绘示脱机后台系统的示意图。图7绘示线上实时系统的示意图。【符号说明】110:数据库120:对应函数生成单元130:数据撷取单元140:特征撷取单元141:字典训练器142:稀疏编码器150:相似度比对单元160:剩余寿命计算单元1000:零件剩余寿命系统1000A:脱机后台系统1000B:线上实时系统a1、a2、ai+1、ai+2:训练样本特征at:估算样本特征atop1、atop2、atopk:近似样本特征C1、C2、Ca1、Ca2:周期编号Catop1、Catop2、Catopk:近似周期编号CF:预测信心度L1、L2、L3:曲线RUL1、RUL2、RULi+1、RULi+2、RULa1、RULa2:训练剩余寿命U1、U2:基底集合RULatop1、RULatop2、RULatopk:近似剩余寿命RULt、RULt’:预测剩余寿命S301、S302、S303、S304、S305、S306、S307、S308、S309、S310、S311:流程步骤X1、X2、X3、Xi+1、Xi+2:历史感测数据Xt:实时感测数据具体实施方式为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明作进一步的详细说明。本发明可针对各种机台的零件(例如半导体或发光二极管制造机台的粒子过滤器(particlefilter))进行剩余寿命预测(remainingusefullifeprediction,RULprediction)。请参照图1,其绘示金属有机物化学气相沉积(metalorganicchemical-vapordeposition,MOCVD)机台的感测曲线图。 以金属有机物化学气相沉积机台为例,曲线L1为粒子过滤器执行完一次行程(run)所搜集到的感测数据(sensordata)(即dp.filtervalues)。当感测数据的中的最大值超过30时,即代表粒子过滤器需要被更换掉。曲线L2为从粒子过滤器全新到被更换掉的一个周期(cycle)所搜集到的感测数据。曲线L3为对每个行程所搜集到的感测数据的最大值的纪录曲线。金属有机物化学气相沉积机台的粒子过滤器的剩余寿命预测就是预测在几个行程之后,感测数据的最大值会发生超过30,后续将以曲线L3作为实施例详细说明。请参照图2及3,图2绘示机台零件剩余寿命预测系统1000的示意图,图3绘示机台零件剩余寿命预测方法的流程图。机台零件剩余寿命系统1000包括一数据库110、一对应函数生成单元120、一数据撷取单元(dataacquisitionunit,DAQunit)130、一特征撷取单元140、一相似度比对单元150及一剩余寿命计算单元160。数据库110用以储存各种数据,例如是一硬盘、一内存、一可携式储存装置或一云端储存中心。对应函数生成单元120用以根据各种数据生成一函数。数据撷取单元130用以撷取各种数据。特征撷取单元140用以根据数据撷取特征。特征撷取单元140包括一字典训练器141及一稀疏编码器142。相似度比对单元150用以进行相似度比对。剩余寿命计算单元160用以进行各种计算程序。对应函数生成单元120、特征撷取单元140、相似度比对单元150及剩余寿命计算单元160例如是一电路、一封装芯片、一电路板或储存数组程序代码的储存装置。数据撷取单元130例如是传感器、传输线、或无线传输装置。首先,在步骤S301中,由数据库110取得数个历史感测数据X1、X2、...、Xi+1、Xi+2、...。请参照图4,其绘示周期编号C1的历史感测数据X1、X2、X3、...及周期标号C2的历史感测数据Xi+1、Xi+2、...的示意图。每4个行程切割为一笔历史感测数据。历史感测数据X1、X2、X3、...、Xi+1、Xi+2、...各对应于一历史剩余寿命RUL1、RUL2、RUL3、...、RULi+i、RULi+2、...。历史剩余寿命RUL1、RUL2、RUL3、...、RULi+1、RULi+2、...可表示成剩余行程次数值或剩余百分比数值。举例来说,某一周期执行完第19次行程后即更换掉粒子过滤器,历史感测数据为执行完第5次行程时,所剩余行程次数值为14,剩余百分笔数值为73.6%(=14/19)。接着,在步骤S302中,利用字典训练技术(dictionarylearning),特征撷取单元140的字典训练器141根据此些历史感测数据X1、X2、X3、...、Xi+1、Xi+2、...产生至少一基底集合U1、U2、...。字典训练技术例如是K-SVD技术或线上字典训练技术(onlinedictionarylearning)。请参照图5,其绘示基底集合的示意图。基底集合也是4个行程的感测数据。透过基底集合的线性组合,可以组合出任一历史感测数据X1、X2、X3、...、Xi+1、Xi+2、...的近似值。然后,在步骤S303中,利用稀疏编码技术(sparsecoding),特征撷取单元140的稀疏编码器142根据此些历史感测数据X1、X2、X3、...、Xi+1、Xi+2、...产生数个训练样本特征a1、a2、...、ai+1、ai+2、...。稀疏编码技术例如是matchpursuit技术、orthogonalmatchingpursuit技术或Lasso技术。各个历史感测数据X1、X2、X3、...、Xi+1、Xi+2、...系为此些训练样本特征a1、a2、...、ai+1、ai+2、...的其中之一与基底集合U1、U2、...的线性组合。举例来说,训练样本特征a1为矩阵[0,0.5,1,0,0,1,...],历史感测数据X1系为训练样本特征a1与基底集合U1、U2、...的线性组合。训练样本特征a2为矩阵[0,0,1.5,0,0,1,...],历史感测数据X2系为训练样本特征a2与基底集合U1、U2、...的线性组合。然后,在步骤S304中,对应函数生成单元120根据此些训练样本特征a1、a2、...、ai+1、ai+2、...建立一对应函数,此对应函数表示此些训练样本特征a1、a2、...、ai+1、ai+2、...与至少一预测信息的对应关系,预测信息包含此些训练剩余寿命RUL1、RUL2、RUL3、...、RULi+1、RULi+2、...及此些周期编号C1、C2、...。各个周期编号C1、C2、...对应于不同操作周期。举例来说,训练样本特征a1对应于训练剩余寿命RULa1及周期编号Ca1,训练样本特征a2对应于训练剩余寿命RULa2及周期编号Ca2,依此类推。然后,在步骤S305中,数据撷取单元130取得一实时感测数据Xt。接着,在步骤S306,特征撷取单元140的稀疏编码器142根据实时感测数据Xt产生一估算样本特征at。然后,在步骤S307,利用相似度比对技术,相似度比对单元150根据此些训练样本特征a1、a2、...、ai+1、ai+2、...,产生与此估算样本特征 at近似的k个近似样本特征atop1、atop2、...、atopk。相似度比对技术例如是k-nearestneighbor技术。请参照表一,其表示估算样本特征at与训练样本特征a1、a2、...、ai+1、ai+2、...的相似度。透过估算样本特征at与所有训练样本特征a1、a2、...、ai+1、ai+2、...进行相似度的计算后,针对相似度进行排序,即可得到最近似的k个近似样本特征atop1、atop2、...、atopk。比较相似度估算样本特征at与训练样本特征a10.569估算样本特征at与训练样本特征a20.301估算样本特征at与训练样本特征a30.0301......表一接着,于步骤S308中,相似度比对单元150根据k个近似样本特征atop1、atop2、...、atopk,透过对应函数取得对应于k个近似样本特征atop1、atop2、...、atopk的k个预测信息中的至少一个,例如是对应于此些近似样本特征atop1、atop2、...、atopk的k个近似剩余寿命RULatop1、RULatop2、...、RULatopk及k个近似周期编号Catop1、Catop2、...、Catopk。然后,在步骤S309中,剩余寿命计算单元160根据此些预测信息(例如是近似剩余寿命RULatop1、RULatop2、...、RULatopk)计算出一预测剩余寿命RULt。在此步骤中,剩余寿命计算单元160对此些近似剩余寿命RULatop1、RULatop2、...、RULatopk进行一加权平均运算,以计算出预测剩余寿命RULt。在一实施例中,加权平均运算系根据反比于或正比于预测信息的关系进行。举例来说,近似剩余寿命RULatop1、RULatop2、...、RULatopk的加权系数正比于周期编号Catop1、Catop2、...、Catopk的重复次数。举例来说,请参照表二,其表示三个近似剩余寿命RULatop1、RULatop2、RULatop3与三个周期编号Catop1、Catop2、Catop3的情况。近似剩余寿命周期编号RULatop1=18Catop1=13RULatop2=13Catop2=13RULatop3=17Caop3=1表二周期编号Catop1、Catop2皆为13,重复了两次。故近似剩余寿命RULatop1、RULatop2的加权系数应为近似剩余寿命RULatop3的两倍。故预测剩余寿命RULt可以按照下式(1)计算。接着,在步骤S310,剩余寿命计算单元160更计算一预测信心度CF。预测信心度CF相关于预测信息的变异程度(例如是此些近似剩余寿命RULatop1、RULatop2、...、RULatopk的一变异程度)。近似剩余寿命RULatop1、RULatop2、...、RULatopk的变异程度越大时,预测信心度CF越低。以上述表二为例,预测信心度可以下式(2)进行计算。然后,在步骤S311中,剩余寿命计算单元160根据预测信心度CF调整预测剩余寿命RULt为预测剩余寿命RULt’。举例来说,请参照表三,其表示前一次与这一次预测剩余寿命RULt的情况。由于前一次的预测信心度CF较高,故以前一次预测剩余寿命RULt(=15.8)减一次作为调整后的预测剩余寿命RULt’(14.8)。表三在一实施例中,零件剩余寿命预测系统1000可以分为脱机后台系统1000A与线上实时系统1000B。请参照图6及图7,图6绘示脱机后台系统1000A的示意图,图7绘示线上实时系统1000B的示意图。脱机后台系统1000A包括数据库110、对应函数生成单元120及特征撷取单元140。脱机后台系统1000A用以执行步骤S301~S304。线上实时系统1000B包括对应函数生成单元120、数据撷取单元130、特征撷取单元140、相似度 比对单元150及剩余寿命计算单元160。脱机后台系统1000A用以执行步骤S305~S311。根据上述实施例,零件剩余寿命预测系统1000及脱机后台系统1000A可以从零件的历史感测数据X1、X2、...、Xi+1、Xi+2、...,训练出基底集合U1、U2、...,再将历史感测数据X1、X2、...、Xi+1、Xi+2、...表示成训练样本特征a1、a2、...、ai+1、ai+2、...。然后,可以训练剩余寿命RUL1、RUL2、RUL3、...、RULi+1、RULi+2、...及周期编号C1、C2、...作为预测信息,来建立训练样本特征a1、a2、...、ai+1、ai+2、...与此些训剩余寿命RUL1、RUL2、RUL3、...、RULi+1、RULi+2、...及周期编号C1、C2、...的对应关系,例如是「训练样本特征a1对应于训练剩余寿命RULa1及周期编号Ca1,训练样本特征a2对应于训练剩余寿命RULa2及周期编号Ca2,依此类推」。零件剩余寿命预测系统1000及线上实时系统1000B可以将实时感测数据Xt表示成估算样本特征at,并找出与此估算样本特征at近似的k个近似样本特征atop1、atop2、...、atopk。再利用k个近似剩余寿命RULatop1、RULatop2、...、RULatopk,以加权平均方式计算出预测剩余寿命RULt及预测信心度CF。最后,再根据预测信心度CF,来调整预测剩余寿命RULt。综上所述,虽然本发明已以较佳实施例公开如上,然其并非用以限定本发明。本发明所属
技术领域:
中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当以权利要求的保护范围为准。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
- 一种Ni45?SiC?TiO<sub>2</sub>?Cu纳米涂层及其制备方法
- 一种Fe?SiO<sub>2</sub>?TiO<sub>2</sub>纳米涂层及其制备方法
- 一种Fe?TiO<sub>2</sub>?Al<sub>2</sub>O<sub>3</sub>?Mn纳米材料及其制备方法
- 一种Ni60B?CrC?Mo?Fe纳米焊层及其制备方法
- 一种Co?Ni?W?B纳米材料及其制备方法
- 一种Fe?TiO<sub>2</sub>?Al<sub>2</sub>O<sub>3</sub>?Cu纳米材料及其制备方法
- 一种Ni45?SiO<sub>2</sub>纳米粉末及其制备方法
- 一种WC?ZrO<sub>2</sub>?SiO<sub>2</sub>纳米粉末及其制备方法
- 输送带生产用平板硫化机的制作方法
- 一种制备粉末冶金零件的组合模具的制作方法