一种基于迭代模型的中文百科知识图谱分类体系构建方法与流程
本发明涉及知识图谱分类体系构建,尤其涉及一种基于迭代模型的中文百科知识图谱分类体系构建方法。
背景技术:
知识图谱作为一个结构化的信息网络,打破了原有的关系型数据库的限制,具有非常强大的表达能力,它在信息检索和信息整合等领域扮演着越来越重要的角色。在知识图谱中,分类体系是整个系统的骨干结构,因为它区分了类目和实体,并且指明了类目之间的父子关系,同时还指出了实体所属的类目,使得整个图谱具有拓扑结构。分类体系中主要包含了两类节点:实体节点和类目节点;两类关系:类目之间的上下位关系Subclass-of,实体和类目之间的从属关系Instance-of。Subclass-of关系用来描述类目节点之间的父子关系,Instance-of关系则用来描述实体节点和类目节点的从属关系。通过多年的研究,构建分类体系的主要方法有两个:一是利用启发式规则进行判断,包括词法规则、语法规则、基于连通性的规则等;另一个方法则是利用机器学习来解决问题,机器学习所使用的特征包括从非结构化文本中挖掘到的词向量以及中文百科页面中的结构化信息等。
技术实现要素:
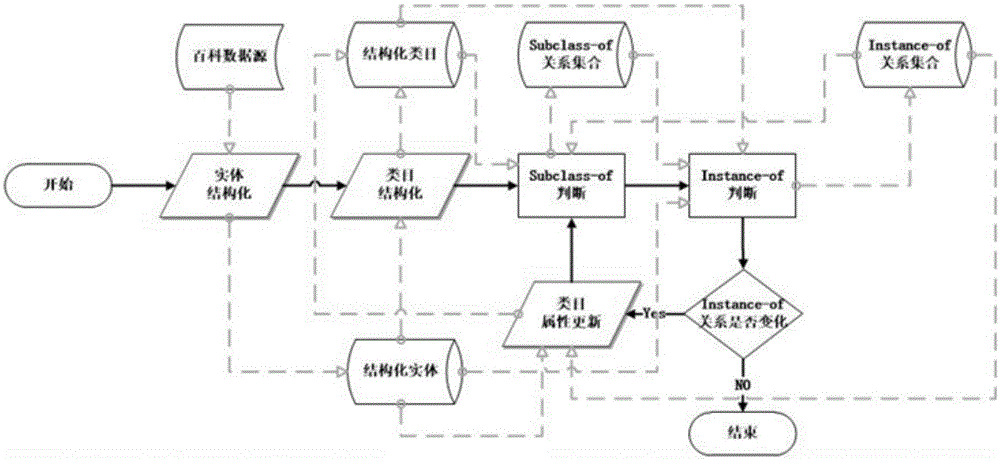
本发明的目的是为了解决构建知识图谱分类体系这一问题,提供一种基于迭代模型的中文百科知识图谱分类体系构建方法,包括如下步骤:
1)对中文百科知识图谱中的实体进行结构化表达;
2)利用中文百科信息中已有的类目与实体之间的关联,通过对实体特征求并集的方法,对知识图谱中的类目进行结构化表达;
3)利用类目的结构化特征,训练支持向量机模型判断两个类目之间是否存在上下位关系Subclass-of;
4)利用实体和类目的结构化特征,以及类目之间的Subclass-of关系约束,在满足Instance-of关系传递性的前提下,用非线性整数规划方法判断实体和类目之间的Instance-of关系;
5)判断步骤4)中获得的Instance-of关系是否有变化,若没有则结束迭代,若有变化则执行步骤6);
6)利用步骤4)中得到的Instance-of关系,重新计算类目的结构化特征,然后跳至步骤3)。
优选的,所述的步骤3)包括:
3.1)寻找类目h可能存在的父类,共有三种搜寻策略:a)基于类目共现频次查找,首先寻找与类目h共现次数最高的类目k,假设类目h与k的共现次数为N,则把与类目h共现次数超过0.8*N的类目放入到类目h的备选父类集合当中;b)基于类目标题词干匹配查找,如果某个类目k的标题是类目h的标题词干,并且两者之间符合有向性条件,则把类目k放入到类目h的备选父类集合当中;c)基于中文百科类目树查找;
3.2)支持向量机模型接受的特征包括语言特征和结构化特征两类,语言特征有词干匹配和修饰词匹配,结构化特征包含内链相似度、属性相似度、目录相似度以及相关词相似度,计算公式如下:
其中hi和he代表两个节点,L代表所有该维度结构化特征的并集,L(hi)和L(he)代表相应维度的结构化特征。
优选的,所述的步骤4)包括:
4.1)寻找实体h可能从属的类目,共有三种搜寻策略:a)基于实体的标签查找,类目是通过实体的标签属性进行抽取的,所以实体的标签集合成为了备选从属类目的主要部分;b)基于实体标题词干匹配查找,根据实体的标题词干选取类目;c)基于实体中文百科页面摘要查找,中文百科页面中的摘要字段,是对词条的简要描述,而摘要中的第一句话是对词条的性质陈述,从实体对应的中文百科页面中抽取出摘要字段,并把摘要字段的第一句话用自然语言处理工具进行分析,选取其中出现的首个类目名词加入到备选类目当中;
4.2)综合3.2)中的多种特征,采用coh(a,h)函数来表示实体a和类目h之间的相关度,计算公式如下:
其中的li表示两项语言特征,dj表示四项结构化特征,wi和wj都代表特征的权重,而μ代表语言特征的权重系数;
4.3)引入非线性整数规划方法判断实体的从属类目,在构建整个分类体系中,必须要协调好Subclass-of关系和Instance-of关系,使它们满足传递性规则,在非线性整数规划中存在一个Subset约束,目标方程如下:
其中Ha代表需要判断是否和实体a有Instance-of关系的类集合,coh(a,hj)代表实体a和类目hj之间的相关度,coh(hk,hj)代表类目hk和类目hj之间的相关度,yj为1代表实体a和类目hj之间存在Instance-of关系,yj为0则表示不存在,最后λ为调和模型准确率和召回率的参数。
优选的,所述的步骤6)包括:
6.1)用Instance-of关系计算类目特征,随着迭代的进行,步骤4)中得到了实体与类目之间的Instance-of关系,利用Instance-of关系可以抽取出新的类目特征;
6.2)每次得到新的类目特征后,采用指数衰减的方式更新类目之间的相关度coh(hi,hj)以及类目和实体之间的相关度coh(a,hi),计算公式如下:
coht+1(a,hi)=β·coht(a,hi)+(1-β)·coh(a,hi)
coh0(a,hi)=coh(a,hi)
其中参数β控制着迭代的指数衰减的速度,函数coht(a,hi)代表t轮迭代中的相关度结果,coh(a,hi)代表在t轮迭代完成后计算出的相关度结果,而最后用coht+1(a,hi)来代表t+1轮迭代中的相关度结果。
本发明所提出的方法与传统独立判断Instance-of关系和Subclass-of关系的方法相比,具有以下优势:
1.获得的Instance-of关系结果在Subclass-of关系约束下满足传递性特征。
2.Instance-of关系和Subclass-of关系能够在迭代过程中不断相互提升,并且相互规范。
附图说明
图1是迭代模型的步骤示意图。
具体实施方式
如图1所示,本发明方法,包括以下步骤:
1)对中文百科知识图谱中的实体进行结构化表达。每个实体都可以用一个六元组来表示:Tuple(a)={T(a),L(a),C(a),P(a),R(a),H(a)},其中a代表实体,T(a)代表实体的标题,L(a)代表实体的内链集合,C(a)代表实体的目录集合,P(a)代表实体的属性集合,R(a)代表实体的相关词集合,H(a)代表实体的标签集合。
2)利用中文百科信息中已有的类目与实体之间的关联,通过对实体特征求并集的方法,对知识图谱中的类目进行结构化表达。每个类目都可以表示成一个六元组:Tuple(h)={T(h),L(h),C(h),P(h),R(h),A(h)},其中h代表类目,T(h)代表类目的标题,A(h)代表类目关联的实体集合,L(h)代表类目的内链集合,C(h)代表类目的目录集合,P(h)代表类目的属性集合,R(h)代表了类目的相关词集。
3)利用类目的结构化特征,训练支持向量机模型判断两个类目之间是否存在上下位关系Subclass-of。
3.1)寻找类目h可能存在的父类,共有三种搜寻策略:a)基于类目共现频次查找,首先寻找与类目h共现次数最高的类目k,假设类目h与k的共现次数为N,则把与类目h共现次数超过0.8*N的类目放入到类目h的备选父类集合当中;b)基于类目标题词干匹配查找,如果某个类目k的标题是类目h的标题词干,并且两者之间符合有向性条件,则把类目k放入到类目h的备选父类集合当中;c)基于中文百科类目树查找;
3.2)支持向量机模型接受的特征包括语言特征和结构化特征两类。语言特征有词干匹配和修饰词匹配,词干匹配用来表示两个类目的标题之间是否有共同的词干,可以通过后缀匹配来检测这一特征。标题具有相同词干的两个类目之间一般存在Subclass-of关系,例如标题为“中国演员”和“演员”的两个类目之间有Subclass-of的关系。同样这一特征也会在判断Instance-of关系中用到,标题具有相同词干的实体和类目之间一般存在Instance-of关系,例如标题为“牡丹鹦鹉”的实体和标题为“鹦鹉”的类目之间存在Instance-of关系。修饰词匹配表示两个类目的标题之间是否存在修饰关系,可以通过前缀匹配来检测。标题具有修饰关系的两个类目之间往往不具有Subclass-of关系,例如标题为“食品安全”和标题为“食品”的两个类目之间不存在Subclass-of关系。同样,我们在判断Instance-of关系中也利用了这一特征,标题之间的修饰关系对Instance-of关系的判定也是消极因素。
3.3)结构化特征包含内链相似度、属性相似度、目录相似度以及相关词相似度,计算公式如下:
其中hi和he代表两个节点,L(hi)和L(he)代表相应维度的集合特征。
支持向量机模型的训练集主要由手工标注生成。
4)利用实体和类目的结构化特征,以及类目之间的Subclass-of关系约束,在满足Instance-of关系传递性的前提下,用非线性整数规划方法判断实体和类目之间的Instance-of关系。
4.1)寻找实体h可能从属的类目,共有三种搜寻策略:a)基于实体的标签查找,类目是通过实体的标签属性进行抽取的,所以实体的标签集合成为了备选从属类目的主要部分;b)基于实体标题词干匹配查找,根据实体的标题词干选取类目;c)基于实体中文百科页面摘要查找,中文百科页面中的摘要字段,是对词条的简要描述,而摘要中的第一句话是对词条的性质陈述,从实体对应的中文百科页面中抽取出摘要字段,并把摘要字段的第一句话用自然语言处理工具进行分析,选取其中出现的首个类目名词加入到备选类目当中;
4.2)综合3)中的多种特征,采用coh(a,h)函数来表示实体a和类目h之间的相关度,计算公式如下:
其中的li表示两项语言特征,dj表示四项结构化特征,wi和wj都代表特征的权重,而μ代表语言特征的权重系数。
4.3)引入非线性整数规划方法判断实体的从属类目,在构建整个分类体系中,必须要协调好Subclass-of关系和Instance-of关系,使它们满足传递性规则,在非线性整数规划中存在一个Subset约束,目标方程如下:
其中Ha代表需要判断是否和实体a有Instance-of关系的类集合,coh(a,hj)代表实体a和类目hj之间的相关度,coh(hk,hj)代表类目hk和类目hj之间的相关度,yj为1代表实体a和类目hj之间存在Instance-of关系,yj为0则表示不存在,最后λ为调和模型准确率和召回率的参数。
5)判断步骤4)中获得的Instance-of关系是否有变化,若没有则结束迭代,若有变化则执行步骤6);
6)利用步骤4)中得到的Instance-of关系,重新计算类目的结构化特征,然后跳至步骤3)。
迭代的循环的部分包括Subclass-of关系的判断、Instance-of关系的判断,以及类目的特征更新。进行迭代优化的关键步骤是利用得到的Instance-of关系,对类目的特征进行更新。类目初始结构化是依靠实体所带的标签,抽取出类目相关的实体集合A(h),进而得到类目的相关特征。这一步骤中存在很多的噪声。但是如果已经得到了实体和类目之间的Instance-of关系,那么就可以利用Instance-of关系来抽取类目的特征,Instance-of关系相当于是对实体的标签进行去噪之后得到的准确率更高的数据,这样结构化类目自然就减少了噪声。所以迭代模型核心是在得到Instance-of关系之后,更新优化类目的特征,再利用更新后的结构化类目来挖掘新的Subclass-of关系,最后是把Subclass-of关系和新的结构化类目反馈到Instance-of关系的判断中。
6.1)用Instance-of关系计算类目特征。随着迭代的进行,步骤4)中得到了实体与类目之间的Instance-of关系,利用Instance-of关系可以抽取出新的类目特征。
6.2)每次得到新的类目特征后,采用指数衰减的方式更新类目之间的相关度coh(hi,hj)以及类目和实体之间的相关度coh(a,hi)。计算公式如下:
coht+1(a,hi)=β·coht(a,hi)+(1-β)·coh(a,hi)
coh0(a,hi)=coh(a,hi)
其中参数β控制着迭代的指数衰减的速度。函数coht(a,hi)代表t轮迭代中的相关度结果,coh(a,hi)代表在t轮迭代完成后计算出的相关度结果。而最后用coht+1(a,hi)来代表t+1轮迭代中的相关度结果。
- 还没有人留言评论。精彩留言会获得点赞!