处理器资源分配方法及装置与流程
本发明是有关于电子装置的处理器控制,更具体地,是有关于电子装置中的需求处理器资源分配方法及相关装置。
背景技术:
根据相关技术,随着现代电子装置的进步,中央处理器(Central Process Unit,CPU)拓扑动态变化且增加了多样性。例如,从系统灵活性,功耗,散热策略,产品差异等角度出发,开发了从对称式多处理器(Symmetric Multi-Processor,SMP)到异构多核处理器(Heterogeneous Multi-Processor,HMP),非对称式多处理器(Asymmetric Multi-Processor,AMP)甚至混合结构等。与SMP相比,这些非SMP拓扑通常由有关物理特性的非对称式CPU变量所组成,包括微架构,计算能力及功耗等。在非对称式CPU之间的这些物理变量对传统技术的SMP热插拔(hot-plugging)及动态电压和频率调节(Dynamic Voltage and Frequency Scaling,DVFS)形成极大挑战。
传统的热插拔和DVFS起源于SMP系统,被设计为根据系统负载调节激活的核心(core)数目和有关的工作频率。例如,若系统负载高于某阈值,一个或多个核心可被插入,并执行频率上移(frequency up-shifting)。若系统负载低于某阈值,一个或多个核心可被移除(un-plugged),并执行频率下移。但是SMP系统不会考虑来调整哪个核心,这是因为所有的核心都没有差别。在非SMP系统上,为了在性能与低功耗之间进行平衡,特插拔和DVFS的决定有可能变得更加复杂。另外,在HMP上,一个较大的核心有可能具有更好的性能以及更高的功耗,而较小的核心可能具有更加平衡的功耗与性能。根据这些物理特性,两个较小的核心可提供与一个较大的核心相同的计算能力,但是具有较少的总功耗。然而,任务不总是能够可分的,且在两个较小的核心中的一个上面运行的性能有可能只有一个较大核心的性能的一半,或者小于一半。因此,性能和低功耗的均衡有可能成为现代移动装置上的重要问题,特别是在非对称式系统上。例如,选择错误类型的CPU有可能导致不佳的用户体验或不必要的系统电力浪费。已公开的实施方法及相关装置可应用于一种或多种类型的处理器资源的组合,例 如SMP架构,HMP架构以及AMP架构,其中SMP架构通常包含具有相同的每秒百万条指令的整数运算(Dhrystone Million Instructions Per Second,DMIPS)速度以及相同的工作频率(例如,以兆赫兹为单位)的多个核心,HMP架构通常包含具有不同的DMIPS,不同工作频率以及不同功耗的多个核心,以及AMP架构通常包含具有相同的DMIPS但不同的工作频率或制造工艺的多个核心。
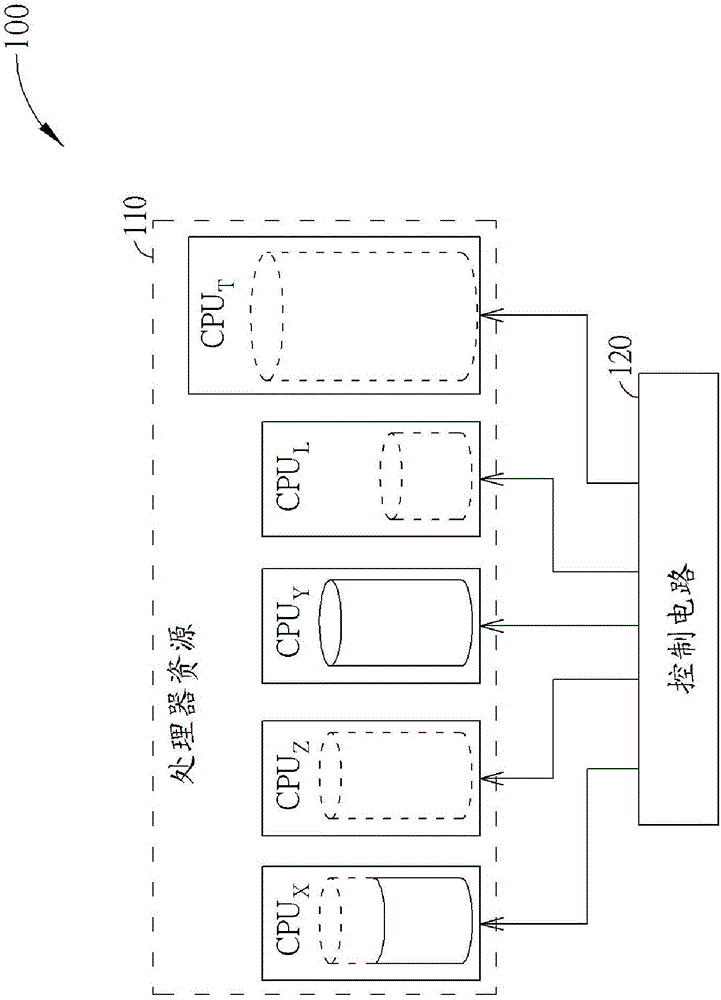
图1为本领域处理器资源分配的传统方法的示意图。例如,该传统方法可包含处理器资源110,处理器资源110包含多个处理器核心(例如,CPU核心),该多个处理器核心的例子可包含图1顶部所示的处理器核心CPUX,CPUZ,CPUY,CPUL和CPUT。如图1所示的多个处理器核心CPUX,CPUZ,CPUY,CPUL和CPUT中以虚线所表示的处理器核心(例如,处理器核心CPUZ,CPUL和CPUT)代表该处理器核心为热拔出的(hot-unplugged)(即该处理器核心的电力被临时关闭),以非虚线所表示的处理器核心(例如,处理器核心CPUX和CPUY)代表该处理器核心为热插入的(hot-plugged)(即该处理器核心的电力被临时打开),并根据该处理器核心中非虚线部分与虚线部分在整个处理器核心中所占的比率而以该处理器核心的全部能力或部分能力进行运作;举例而言,在图1所示处理器核心CPUX中,非虚线部分占据整个处理器核心的2/3,则处理器核心CPUX以其全部能力的2/3进行运作。在图1所示处理器资源110结构的下方,处理器核心中所显示的阴影内容指示该处理器核心相较于其计算能力的工作负载。该处理器核心的状态可能随时发生变化。
根据相关技术,传统方法有可能使用遗留的热插拔/DVFS方法。例如,在大概花费10毫秒(ms)或更长时间的第一次转换中,传统方法的DVFS操作有可能将线上的(online)CPU频率上移至合理水平(有可能是线上CPU的最大能力)。在大概花费100毫秒(ms)或更长时间的第二次转换中,当已有的线上CPU无法处理总体系统负载时,传统方法的热插拔操作可能使能(enable)一个或多个CPU减轻工作负载的紧张度(tensions)。使能CPU的考虑出发点可以是最大功率,最大工作效率,最大省电等。然而,传统方法也遇到了一些问题。例如,传统方法有可能响应比较晚,热插拔和DVFS的独立使用有可能导致额外的延迟和响应时间。
如上所述,在相关技术中存在一些问题。因此,需要一种新的方法来增强电子装置的处理器控制。
技术实现要素:
有鉴于此,本发明提供一种处理器资源分配方法及装置。
根据本发明一实施例的处理器资源分配方法,用于执行电子装置中的处理器资源分配,所述处理器资源分配方法包含:获取任务相关信息以确定多个任务中的一个是否为繁重任务(heavy task),以选择性地使用多个处理器核心中的特定处理器核心来执行所述任务;确定在所述多个任务中的其它任务中是否存在至少一个场景任务(scenario task),并根据多个应用需求确定最小处理器核心数目和用以执行所述至少一场景任务的最小工作频率;以及根据功率表和系统负载执行处理器资源分配,以执行所述多个任务中的任意剩余部分。
根据本发明一实施例的处理器资源分配装置,用于执行电子装置中的处理器资源分配,所述处理器资源分配装置包含:多个处理器核心,位于所述电子装置内,用于选择性地执行所述电子装置的多个操作;以及控制电路,嵌入于所述多个处理器核心内或者位于所述多个处理器核心之外,用于获取任务相关信息以确定多个任务中的一个任务是否为繁重任务,以选择性地使用所述多个处理器核心中的特定处理器核心来执行所述任务,并确定是否在所述多个任务中的其它任务中存在至少一场景任务,以选择性地根据应用需求确定最小处理器核心数目和用以执行所述至少一场景任务的最小工作频率,其中,所述控制电路根据功率表和系统负载执行处理器资源分频,以执行所述多个任务中的任意剩余部分。
本发明所提供的处理器资源分配方法及装置,其优点之一在于能够适当地进行处理器资源分配,提高电子装置的总体性能。
附图说明
图1为本领域处理器资源分配的传统方法的示意图。
图2为根据本发明一实施例的执行电子装置中的处理器资源分配的装置100的示意图。
图3为根据本发明一实施例的在电子装置中执行处理器资源分配的方法200的流程图。
图4为根据本发明一实施例的结合图3所示方法200的控制机制的示意图。
图5为根据本发明一实施例的图2所示控制电路120的一些具体实施示意图。
图6为根据本发明一实施例的结合图3所示方法200的时序图。
具体实施方式
在说明书及权利要求当中使用了某些词汇来指称特定的组件。本领域技术人员应可理解,硬件制造商可能会用不同的名词来称呼同一个组件。本说明书及权利要求并不以名称的差异来作为区分组件的方式,而是以组件在功能上的差异来作为区分的准则。在通篇说明书及权利要求当中所提及的“包含”及“包括”为一开放式的用语,故应解释成“包含但不限定于”。“大致”是指在可接受的误差范围内,本领域技术人员能够在一定误差范围内解决所述技术问题,基本达到所述技术效果。此外,“耦接”一词在此包含任何直接及间接的电性连接手段。因此,若文中描述一第一装置耦接于一第二装置,则代表该第一装置可直接电性连接于该第二装置,或通过其它装置或连接手段间接地电性连接至该第二装置。“连接”一词在此包含任何直接及间接、有线及无线的连接手段。以下所述为实施本发明的较佳方式,目的在于说明本发明的精神而非用以限定本发明的保护范围,本发明的保护范围当视后附的权利要求所界定者为准。
图2为根据本发明一实施例的执行电子装置中的处理器资源分配的装置100的示意图,其中装置100可包含该电子装置的至少一部分。例如,装置100可包含上述电子装置的一部分,更具体地,装置100可以是至少一硬件电路,例如电子装置内的至少一集成电路(Integrated Circuit,IC)及其相关电路。在另一实施例中,装置100可以是上述电子装置的全部。在另一实施例中,装置100可包含系统,该系统包含上述电子装置(例如,包含该电子装置的无线通信系统)。该电子装置的多个实施例可包含但不仅限于,移动电话(例如,多功能移动电话),平板电脑及诸如膝上型电脑或台式电脑的个人电脑。
根据本实施例,装置100可包含上述处理器资源110(包含多个处理器核心),在本实施例中,处理器资源110可位于电子装置之内。例如,装置100可包含电子装置中的至少一处理器,以及上述至少一处理器可包含多个处理器核心。为了便于理解,图中所示处理器核心CPUX,CPUZ,CPUY,CPUL和CPUT可作为本实施例的多个处理器核心的实施例。如图2所示,装置100可进一步包含含控制电路120,控制电路120可位于该多个处理器核心之外。根据一些实施例,控制电路120可嵌入于多个处理器核心之内。例如,控制电路120可使用上述至少一处理器来实施,在上述至少一处理器上可运行至少一程序模块,例如从 操作系统(Operating System,OS)的现有内核(kernel)修改得到的内核程序模块。
如图2所示,处理器核心CPUX位于线上(表示处理器核心CPUx可以是热插拔的,例如,处理器核心CPUX的电力可临时打开),且并未工作在最大工作频率上,这是因为剩余的虚线显示了未使用的频率能力,然而处理器核心CPUY完全以实线显示,这指示该处理器核心CPUY位于线上(表示处理器核心CPUY可以是热插拔的,例如,处理器核心CPUY的电力可临时打开)且工作在最大工作频率上,其中,完全以虚线所显示的核心CPUZ,CPUL和CPUT指示该处理器核心CPUZ,CPUL和CPUT位于线下(表示处理器核心CPUZ,CPUL和CPUT可以是热插拔的,例如,处理器核心CPUX的电力可临时关闭)。与原处理器核心相比,具有相同半径但总高度减半的多个处理器核心具有相同的DMIPS,但是最大工作频率的比率为1:2,例如,处理器核心CPUX,CPUY和CPUZ与处理器核心CPUL相比。以及更大的半径指示处理器核心具有更高的DMIP。由于处理器核心CPUT的高度大于处理器核心CPUX,CPUY和CPUZ,因此,处理器核心CPUT的最大工作效率高于处理器核心CPUX,CPUY和CPUZ。该多个处理器核心中的任意一个(例如图2所示的处理器核心CPUX,CPUZ,CPUY,CPUL和CPUT中的任意一个)的状态可随时发生变化。
由于多个处理器核心中的任意一个可临时热插入或热拔出,该多个处理器核心可用于选择性地执行用于电子装置的操作。另外,控制电路120可用于将多个任务划分为多个类别,并进一步根据上述一个或多个任务属于多个类别中的哪个,将一个或多个任务分配或重新分配给该多个处理器核心中的一个或多个。根据本实施例,控制机制可用于满足能效考虑,适用于任意现代CPU拓扑(包括但不仅限于SMP,HMP,AMP及混合结构)等性能需求。除系统总体负载之外,控制机制可将任务的不同所带来的计算需求的变化也纳入考量,不同任务所对应的计算需求应被独立看待,而不应与系统负载的概念相混。例如,控制机制根据特性对关注性能的任务进行分类,包括但不仅限于帧产生(frame rendering)的任务,繁重负载的任务等,以便分配所需的核心数量及对应的类别(class)或频率。基于性能所需的核心数量,类别,频率及总体系统负载,控制机制可参考一功率表以寻求满足整个系统需求的最小功耗。因此,本实施例的系统100可解决图1所示的传统方法中的上述问题。
根据一些实施例,对于给定的一组CPU资源,根据该控制机制工作的装置100可基于性能需求和能源问题分配必要的CPU。例如,通过使用CPU热插拔 和DVFS,装置100可尽量在具有不同物理特性(包括计算能力和电源效率)的群集(Cluster/Clusters)与一个或多个CPU之间作出最佳抉择,以满足性能需求。
图3为根据本发明一实施例的在电子装置中执行处理器资源分配的方法200的流程图。图3所示的方案200可应用于图2所示的装置100及其上述至少一处理器,并可应用于上述控制电路120,而不论控制电路120位于图2所示实施例中的多个处理器核心的外部还是嵌入于上述一些实施例的多个处理器核心的内部。
在步骤210中,控制电路120可获取任务相关信息以确定多个任务中的一个任务是否为繁重任务,然后选择性地使用多个处理器核心中的特定处理器核心来执行该任务,其中,该特定处理器核心可以是相较于该多个处理器核心中的其它处理器核心具有较高计算能力的处理器核心,以满足繁重任务的需求。例如,当该任务为繁重任务时,控制电路120可使用特定处理器核心(例如,相较于该多个处理器核心中的其它处理器核心具有较高计算能力,且满足繁重任务需求的处理器核心)来执行该任务。为了实现最佳性能,该特定处理器核心可工作在其最高工作频率上,例如,该特定处理器核心可用的最大工作频率。根据一些实施例,任务相关信息可从运行在电子装置上的程序模块来获取,例如,内核程序。
举例而言,任务相关信息可以包含排队时间(queue time),排队时间表示该任务排队所需的时段;以及任务相关信息可进一步包含连续执行时间,连续执行时间表示任务在排队排到后执行所需的时段。控制电路120可确定排队时间和执行时间的总和是否满足预定准则(例如,该准则可以指示该繁重任务相较于该多个任务中的其它任务对应于较重的负载),以确定该任务是否为繁重任务。例如,当排队时间和执行时间的总和达到预定时间阈值时,控制电路120可确定该任务为繁重任务。在另一实施例中,当排队时间和执行时间的总和与某时段的比率达到预定比率阈值时,控制电路120可确定该任务为繁重任务。
在步骤220中,控制电路120可确定在该多个任务中的其它任务中是否存在至少一场景任务,以根据应用需求选择性地确定用以执行上述至少一场景任务的最小处理器核心数目和最小工作频率。例如,当上述至少一场景任务存在时,控制电路120可根据应用需求确定用以执行上述至少一场景任务的最小处理器核心数目和最小工作频率。更具体地,当上述至少一场景任务存在时,控制电路120可使用该多个处理器核心中的至少另一处理器核心来执行上述至少 一场景任务,其中,上述至少另一处理器核心的数目大于或等于最小处理器核心数目,以及上述至少另一处理器核心的工作频率大于或等于该场景任务的应用所需的最小工作频率。
在步骤230中,控制电路120可根据功率表和系统负载来执行处理器资源分配,以执行该多个任务中的任意剩余部分,例如该多个任务中的其它任务。举例而言,控制电路120可计算所有剩余任务的工作负载的加和,然后根据该功率表执行表查找操作,用以调整处理器核心的数目及共享总体工作负载,其中,对应于最小功耗的一个或多个已选择处理器核心可具有步骤230中所使用的最高优先级。
在一些实施例中,控制电路120可将功率表和总体工作负载也纳入考虑,以选择最合适的分配,从而以最低的功率成本满足系统需求。例如,在这些实施例中的系统负载可以是代表总体工作负载的一个数字,而不同的任务特性有可能不会被考虑。
根据一些实施例,控制电路120可对任务执行负载测量以产生负载测量结果。负责测量结果的多个实施例可包含但不仅限于,排队时间,执行时间及二者的派生(例如,排队时间和执行时间的总和,或者排队时间和执行时间的总和与某时段的比率)。另外,控制电路120可根据负载测量结果产生步骤210所提到的任务相关信息。例如,在步骤210中,当负载测量结果到达预定阈值(例如,预定时间阈值或预定比率阈值,取决于不同的预定准确实施例)时,控制电路120可确定该多个任务中的该任务为繁重任务。为便于说明,负载测量结果可在0%至100%的范围内变化,以及基于多种不同需求,预定阈值可定义为90%或另一固定值。此处仅用于说明目的,本发明并不以此为限。
根据一些实施例,例如图4-7所示的一个或多个实施例,控制电路120可将多个任务划分为多个分类,其中,该多个分类可包含“繁重任务类别”,“场景类别”以及“其它类别”。
表1
例如,控制电路120可将多个任务分类为根据任务的特性的多个分类,例如表1所示的分类。多个分类的实施例可包含但不仅限于,繁重任务类别(标识为表1中的“繁重任务”),场景类别(标识为表1中的“场景”)及上述其它类别(标识为表1中的“其它”)。繁重任务类别可对应于步骤210中所提到的繁重任务,场景类别可对应于步骤220中所提到的至少一场景任务,以及其它类别可对应于该多个任务中的剩余部分(即步骤230中所提到的剩余部分)。例如,步骤220中所提到的该至少一场景任务可包含至少一帧产生任务。为便于理解,帧产生任务可视为场景类别的一个例子,其中,对应于帧产生任务的多个任务的数目NFPS,累加的负载参数AccLoadFPS,以及预定的工作频率FFPS可分别视为对应于场景类别的任务的数目NSCE,累加的负载参数AccLoadSCE,以及预定的工作频率FSCE的例子。
关于场景类别,假定装置100通过执行对应于帧产生的一个或多个任务来更新帧。控制电路120可确定与场景类别有关的一些参数,例如一组每秒帧(Frame Per Second,FPS)参数。例如,有可能存在NFPS帧产生任务,其中,数目NFPS为大于或等于0的证书。这组FPS参数的例子可包含但不仅限于:
(F0),累加的负载参数AccLoadFPS,即,对应于一个或多个帧产生任务的累加负载;
(F1),用于帧产生任务所需的多个处理器核心中的在线核心的最小数目,例如,等于NFPS的一个数字;以及
(F2),这些在线核心所需的最小频率,例如预定工作频率FFPS。
为了满足帧产生任务的需求,在该多个处理器核心内用于帧产生任务所需的在线核心的数目可等于或大于NFPS,以及应用于帧产生任务的每个处理器核心的工作频率可等于或大于FFPS。
关于繁重任务类别,控制电路120可确定与繁重任务类别有关的一些参数。例如,在步骤210所述多个任务内存在NHT个繁重任务,其中,数目NHT为大于或等于0的整数。这组繁重任务(HT)参数的例子可包含但不仅限于:
(H0),累加的负载参数AccLoadFPS,即,对应于繁重任务的累加负载;以及
(H1),在该多个处理器核心中用于繁重任务所需的最强处理器核心(例如,最强CPU核心)的数目,例如,等于NHT的一个数字。
根据一些实施例,当电力充足且无需省电时,在该多个处理器核心中用于繁重任务所需的最强处理器核心的数目大于或等于NHT。根据一些实施例,该多个处理器核心中的每个处理器核心可以是单个核心处理器的处理器核心,因此,这组HT参数可包含这些实施例中的最强处理器的数目。
关于其它类别,举例而言,假定存在NOTH个其它任务,其中,数目NOTH,即上述其它任务的任务数目,为大于或等于0的整数。控制电路120可确定与其它类别有关的一些参数,例如,累加负载参数AccLoadOTH,即对应于其它任务的累加负载。
图4为根据本发明一实施例的结合图3所示方法200的控制机制的示意图。根据繁重任务的任务数目NHT,控制电路120可将最强处理器核心(例如,最强CPU核心)的数目确定为适当的值,以有效地完成NHT个繁重任务。以及每个最强处理器核心可工作在可用的最大工作频率FMAX。如图4所示,高度和半径指示处理器核心CPUT为最强的处理器核心。
该多个任务可包含一组帧产生任务P1,P2和P3,繁重任务P4,以及一个或多个其它任务PN。控制电路120可分配处理器核心CPUT来执行繁重任务P4,其中处理器核心CPUT至少工作在繁重任务P4所需的最小工作频率上。另外,在功率表20的帮助下,控制电路120可分别分配处理器核心CPUX,CPUZ和CPUY来执行帧组帧产生任务P1,P2和P3。另外,控制电路120可分配处理器核心CPUL以及处理器核心CPUX,CPUZ和CPUY的部分能力来执行上述一个或多个其它任务PN。总之,当为一个或多个其它任务PN分配处理资源时,控制电路120可参考功率表20以寻找对应于最小功耗的配置。该方法的原则通常满足以下需求:
(R1),至少NHT个最强处理器核心在线,每个在线的最强处理器核心工作在这些最强处理器核心的可用的最大工作频率FMAX;
(R2),除繁重任务外,装置100处理场景任务或来自应用的任务的累加负载。 通过至少NSCE个处理器核心在线,每个处理器核心工作在所需的工作频率,例如预定的工作频率FSCE或更高的工作频率;以及
(R3),基于电力效率的问题,使用功率表来为一个或多个任务分配处理器核心。
在需求R2中的NSCE个处理器核心中,NHT个最强处理器核心可被排除,这意味着这NHT个最强处理器核心未包含于这组NSCE处理器核心之中。另外,若满足上述需求R1,则在步骤210中,当该任务为繁重任务时,控制电路120可使用多个处理器核心中的一组特定处理器核心,例如,NHT个最强处理器核心,来执行步骤210中的任务,其中,这组特定处理器核心包含该特定处理器核心。例如,该组特定处理器核心中的每个可工作在其最高工作频率,例如,可用的最大工作频率FMAX。通常,这组特定处理器核心可对应于与该多个处理器核心有关的最高计算能力,以及该组特定处理器核心(例如NHT个最强处理器核心)可用于尽快完成繁重任务。在一些实施例中,当步骤210中的任务为繁重任务时,控制电路120可使用该多个处理器核心中的这组特定处理器核心来分别执行一组繁重任务(包含步骤210中所述的任务),例如NHT个繁重任务。举例而言,这组特定处理器核心中的每个可工作在其最高工作频率,例如可用的最高工作频率FMAX。
图5为根据本发明一实施例的图2所示控制电路120的一些具体实施示意图,其中,控制电路120可实施为上述至少一处理器,在该至少一处理器上可运行多个程序模块。例如,这多个程序模块可包含Linux内核程序模块(简洁起见,在图5中标记为“LINUX KERNEL”),库(library)程序模块(简洁起见,在图5中标记为“LIBRARIES”),以及处理器资源分配(Processor Resource Allocation,PRA)程序模块(简洁起见,在图5中标记为“PRA”)。请注意,Linux内核程序模块可作为图2所示实施例中的上述内核程序模块的一个例子,该内核程序模块可从现有的操作系统的内核修改而来。另外,该Linux内核程序模块可包含一些子模块,例如调度器(scheduler)和CPU拓扑单元(简洁起见,在图5中标记为“CPU拓扑”),以及库程序模块可包含一些子模块,例如功率表(例如,功率表20)及图5中的自升压(i-boost)单元(简洁起见,在图5中标记为“iBoost”)。
如图5所示,处理器资源分配程序模块可从库程序模块中获取功率表的内容,并可从嵌入于库程序模块的性能服务单元中的自升压单元中获取数目NSCE (即上述场景任务的任务数目)和预定工作频率FSCE。由于Linux内核程序模块可确定用于执行处理器资源分配操作进一步所需的一些参数,处理器资源分配程序模块可从Linux内核程序模块中获取这些参数,并根据这些参数执行处理器资源分配操作。例如,Linux内核程序模块的调度器可确定数目NHT(即,上述NHT繁重任务的任务数目),累加负载参数AccLoadFPS(即对应于帧产生任务的累加负载),累加负载参数AccLoadOTH(即对应于其它任务的累加负载),以及系统线程级并行处理(Thread-Level Parallelism,TLP)。例如,在步骤230中,控制电路120可检查系统TLP,以确定步骤210是否应重新进入,以及在步骤210重新进入的情形下,可能需要再次执行关于处理器资源分配的一些操作(例如,从步骤210开始的工作流程操作)。此处仅用于说明目的,并非用以限制本发明。另外,CPU拓扑单元可确定关于拓扑和效率的信息,例如,CPU拓扑信息和CPU效率信息。因此,处理器资源分配程序模块可根据从Linux内核程序模块所获取的参数和功率表,以及根据从库程序模块所获取的其它参数,来执行处理器资源分配操作,以动态确定多个处理器资源分配控制参数。举例而言,多个处理器资源分配控制参数可包含用于每个类别(更具体地,多个分类中的每个类别)的核心的数目,例如用于繁重任务类别的最强处理器核心的数目(例如,等于NHT的数目)以及用于场景任务类别的帧产生任务所需的最小在线核心数目(例如,大于或等于NSCE的数目)。另外,多个处理器资源分配控制参数可进一步包含有关的每个处理器核心的对应频率(便于理解起见,在图5中标记为“每个CPU的对应频率”),例如关于用于繁重任务类别的最强处理器核心的可用的最大工作频率(例如,FMAX)以及这些在线核心所需的最小频率(例如,预定工作频率FSCE)。根据一些实施例,有关的每个处理器核心的对应频率的实施例可进一步包含大于预定工作频率FSCE的上述其它预定工作频率,即在图5所示实施例中确定用于具有较低DMIPS的处理器核心的其它预定工作频率。简洁起见,对于本实施例的类似描述此处不再重复。
根据一些实施例,当一个或多个数目NSCE(即,上述场景任务的任务数目),这些在线核心所需的最小频率(例如,预定工作频率FSCE),以及数目NHT(即,上述NHT个繁重任务的任务数目)发生变化时,处理器资源分配程序模块可根据最新的参数和功率表再次执行处理器资源分配操作,以更新多个处理器资源分配控制参数。简洁起见,有关本实施例的类似描述此处不再重复。
图6为根据本发明一实施例的结合图3所示方法200的时序图。根据本实 施例,在执行处理器资源分配操作期间,控制电路120(更具体地,处理器资源分配程序模块)不仅控制处理器资源110以响应具有繁重负载的任务和用于帧产生的任务,而且关注系统TLP。
例如,图6所示的调度标记(schedule tick)可以是Linux定义的用于检查的时段(例如,10毫秒或另一预定长度的时间),以及在本实施例中,图6所示的曲线,从顶部开始到底部,可称为第一曲线至第六曲线。如图6所示,使用加重粗线所显示的曲线,例如第一曲线(即最顶部的曲线),可指示对应的任务在图6所示的调度标记期间运行。类似地,使用加重粗线显示的部分曲线,例如第二曲线的右半部分,可指示对应的任务在该粗线所显示的较短时间期间运行,而非加重粗线显示的部分曲线,例如第二曲线的左半部分,可指示对应任务在非粗线显示的时间期间并未被唤醒(便于理解起见,在一些实施例中可视为“睡眠”状态),其中,曲线的阴影部分,例如第二曲线的阴影部分,可指示对应任务在该阴影部分所显示的时间期间已被唤醒但没有处理器核心被分配用以执行该任务。
在现实世界中,系统TLP通常随着装置100调度任务的入队(enqueues)和出队(dequeues)而时刻发生变化,而任务调度的行为太过频繁,则装置100无法对每次改变均作出反应。一种通用的妥协方式为基于样本的追踪(sample-based tracking)。另外,当通过参考系统TLP来尝试增加CPU资源时,基于样本的方法可带来一些问题。例如,最严重的一个问题在于暂态(transient state)可能被采样,因而发生虚警(false alarm)。考虑一个刚刚被唤醒的任务,在到达采样时间点进行采样之前,系统TLP在该采样时间点上将增加,但装置100有可能在接下来下一毫秒放弃运行该任务。
根据本实施例,可引入“可运行期间”TLP以用作系统TLP,用以反映CPU资源是否充足。例如,在控制电路120(更具体地,处理器资源分配程序模块)的控制下,除繁重任务以及帧生成任务以外,任何满足以下函数的任务均可出发处理器资源分配程序以重新分配CPU资源:
((TRUNNABLE*NONLINE_CPU)/TACC_ONLINE_CPU)>X%;
其中,符号“TRUNNABLE”可代表可运行时间(例如,在该时段期间没有处理器核心运行该任务),符号“NONLINE_CPU”可代表在线处理器核心的数目,符号“TACC_ONLINE_CPU”可代表整个系统的在线处理器核心的累加时间,以及符号“X%”可代表预定百分比。预定百分比(即X%)可作为预定比率阈值的实施 例。简洁起见,有关本实施例的类似描述此处不再重复。
本发明的优点之一在于,对于给定的一组处理器资源,例如上述多个处理器核心,本发明所提供的处理器资源分配方法和装置可基于与能量有关的性能需求来分配必要的处理器核心。例如,通过执行处理器热插拔(例如,CPU热插拔或CPU核心热插拔)以及DVFS,本发明所提供的处理器资源分配方法和装置可在具有不同的计算能力和电源效率等物理特性的群集和CPU之间尽量作出最佳抉择,以满足对于能效系统的性能需求。由于用户体验和省电均对于毫秒级敏感,因此,本发明所提供的处理器资源分配方法及装置可以更灵敏的方式来执行热插拔和DVFS,以响应可变化的性能需求及回应以有关能量的适当调节。另外,本发明所提供的处理器资源分配方法及装置可以较少的负面效应实现适当的功率控制。与现有技术相比,本发明可防止或极大地减少不当的核心分配及/或不当的频率分配的机率。因此,可实现电子装置的最佳总体性能。
虽然本发明已以较佳实施例揭露如上,然其并非用以限定本发明,任何熟习此技艺者,在不脱离本发明的精神和范围内,当可作些许的更动与润饰,因此本发明的保护范围当视后附的权利要求所界定者为准。
- 还没有人留言评论。精彩留言会获得点赞!