一种用于执行矩阵加/减运算的装置和方法与流程
本发明涉及计算机领域,尤其涉及一种用于执行矩阵加减法运算的装置和方法。
背景技术:
当前计算机领域,伴随着大数据、机器学习等新兴技术的成熟,越来越多的任务中包含了各种各样的矩阵加减法运算,尤其是大矩阵的加减法运算,这些往往成为算法速度和效果提高的瓶颈。、
在现有技术中,一种进行矩阵加减法运算的已知方案是使用通用处理器,该方法通过通用寄存器堆和通用功能部件来执行通用指令,从而执行矩阵加减法运算。然而,该方法的缺点之一是单个通用处理器多用于标量计算,在进行矩阵运算时运算性能较低。而使用多个通用处理器并行执行时,处理器的个数较少提升的效果不做够显著;处理器个数较高时它们之间的相互通讯又有可能成为性能瓶颈。
在另一种现有技术中,使用图形处理器(gpu)来进行一系列矩阵加减法运算,其中,通过使用通用寄存器堆和通用流处理单元执行通用simd指令来进行运算。但在上述方案中,gpu片上缓存太小,在进行大规模矩阵运算时需要不断进行片外数据搬运,片外带宽成为了主要性能瓶颈。
在另一种现有技术中,使用专门定制的矩阵运算装置来进行矩阵加减法运算,其中,使用定制的寄存器堆和定制的处理单元进行矩阵运算。然而根据这种方法,目前已有的专用矩阵运算装置受限于寄存器堆的设计,不能够灵活地支持不同长度的矩阵加减法运算。
综上所述,现有的不管是片上多核通用处理器、片间互联通用处理器(单核或多核)、还是片间互联图形处理器都无法进行高效的矩阵加减法运算,并且这些现有技术在处理矩阵加减法运算问题时存在着代码量大,受限于片间通讯,片上缓存不够,支持的矩阵规模不够灵活等问题。
技术实现要素:
基于此,本发明提供了一种执行矩阵加减法运算的装置和方法。
根据本发明一方面,提供了一种用于执行矩阵加减运算的装置,其特征在于,包括:
存储单元,用于存储矩阵运算指令相关的矩阵数据;
寄存器单元,用于存储矩阵运算指令相关的标量数据;
控制单元,用于对矩阵运算指令进行译码,并控制矩阵运算指令的运算过程;
矩阵运算单元,用于根据译码后的矩阵运算指令,对输入矩阵进行矩阵加减运算操作;
其中,所述矩阵运算单元为定制的硬件电路。
根据本发明另一方面,提供了一种用于执行矩阵加减法运算的装置,其特征在于,包括:
取指模块,用于从指令序列中取出下一条要执行的矩阵运算指令,并将该矩阵运算指令传给译码模块;
译码模块,用于对该矩阵运算指令进行译码,并将译码后的矩阵运算指令传送给指令队列模块;
指令队列模块,用于暂存译码后的矩阵运算指令,并从矩阵运算指令或标量寄存器获得矩阵运算指令运算相关的标量数据;获得所述标量数据后,将所述矩阵运算指令送至依赖关系处理单元;
标量寄存器堆,包括多个标量寄存器,用于存储矩阵运算指令相关的标量数据;
依赖关系处理单元,用于判断所述矩阵运算指令与之前未执行完的运算指令之间是否存在依赖关系;如果存在依赖关系,则将所述矩阵运算指令送至存储队列模块,如果不存在依赖关系,则将所述矩阵运算指令送至矩阵运算单元;
存储队列模块,用于存储与之前运算指令存在依赖关系的矩阵运算指令,并且在所述依赖关系解除后,将所述矩阵运算指令送至矩阵运算单元;
矩阵运算单元,用于根据接收到矩阵运算指令对输入矩阵进行矩阵加减法运算操作;
高速暂存存储器,用于存储输入矩阵和输出矩阵;
输入输出存取模块,用于直接访问所述高速暂存存储器,负责从所述高速暂存存储器中读取输出矩阵和写入输入矩阵。
本发明还提供了一种执行矩阵加减法运算的方法。
本发明可以应用于以下场景中(包括但不限于):数据处理、机器人、电脑、打印机、扫描仪、电话、平板电脑、智能终端、手机、行车记录仪、导航仪、传感器、摄像头、云端服务器、相机、摄像机、投影仪、手表、耳机、移动存储、可穿戴设备等各类电子产品;飞机、轮船、车辆等各类交通工具;电视、空调、微波炉、冰箱、电饭煲、加湿器、洗衣机、电灯、燃气灶、油烟机等各类家用电器;以及包括核磁共振仪、b超、心电图仪等各类医疗设备。
附图说明
图1是根据本发明实施例的执行矩阵加减法运算的装置的结构示意图。
图2是根据本发明实施例的矩阵运算单元的操作示意图。
图3是根据本发明实施例的指令集的格式示意图。
图4是根据本发明实施例的矩阵运算装置的结构示意图。
图5是根据本发明实施例的矩阵运算装置执行矩阵加法指令的流程图。
图6是根据本发明实施例的矩阵运算装置执行矩阵减标量指令的流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明作进一步的详细说明。
本发明提供了一种矩阵加减法运算装置,包括:存储单元、寄存器单元、控制单元和矩阵运算单元;
所述存储单元存储矩阵;
所述寄存器单元中存储有输入矩阵地址、输入矩阵长度、输出矩阵地 址;
所述控制单元用于对矩阵运算指令执行译码操作,并根据矩阵运算指令控制各个模块,以控制矩阵加减法运算的执行过程;
矩阵运算单元在指令中或寄存器单元中获取输入矩阵地址、输入矩阵长度、输出矩阵地址,然后,根据该输入矩阵地址在存储单元中获取相应的矩阵,接着,根据获取的矩阵进行矩阵运算,得到矩阵运算结果。
本发明将参与计算的矩阵数据暂存在存储单元(例如,高速暂存存储器)上,使得矩阵运算过程中可以更加灵活有效地支持不同宽度的数据,提升包含大量矩阵加减法运算任务的执行性能。
本发明中,所述矩阵加减法运算单元可以实现为定制的硬件电路,包括但不限于fpga、cgra、专用集成电路asic、模拟电路和忆阻器等。
图1是本发明提供的用于执行矩阵加减法运算的装置的结构示意图,如图1所示,该装置包括:
存储单元,用于存储矩阵。在一种实施方式中,该存储单元可以是高速暂存存储器,能够支持不同大小的矩阵数据;本发明将必要的计算数据暂存在高速暂存存储器上(scratchpadmemory),使本运算装置在进行矩阵运算过程中可以更加灵活有效地支持不同宽度的数据。所述高速暂存存储器可以通过各种不同存储器件如sram、dram、edram、忆阻器、3d-dram和非易失存储等实现。
寄存器单元,用于存储矩阵地址,其中,矩阵地址为矩阵在存储单元中存储的地址;在一种实施方式中,寄存器单元可以是标量寄存器堆,提供运算过程中所需的标量寄存器,标量寄存器存储输入矩阵地址、输入矩阵长度、输出矩阵地址。当涉及到矩阵与标量的运算时,矩阵运算单元不仅要从寄存器单元中获取矩阵地址,还要从寄存器单元中获取相应的标量。
控制单元,用于控制装置中各个模块的行为。在一种实施方式中,控制单元读取准备好的指令,进行译码生成多条微指令,发送给装置中的其他模块,其他模块根据得到的微指令执行相应的操作。
矩阵运算单元,用于获取各种加减运算指令,根据指令在所述寄存器单元中获取矩阵地址,然后,根据该矩阵地址在存储单元中获取相应的矩阵,接着,根据获取的矩阵进行运算,得到矩阵运算结果,并将矩阵运算 结果存储于高速暂存存储器中。矩阵运算单元负责装置的所有矩阵加减运算,包括但不限于矩阵加法操作、矩阵减法操作、矩阵加标量操作和矩阵减标量操作。矩阵加减运算指令被送往该运算单元执行,所有的运算部件均是并行的向量运算部件,可以在同一时钟并行地对一整列数据进行相同的运算。
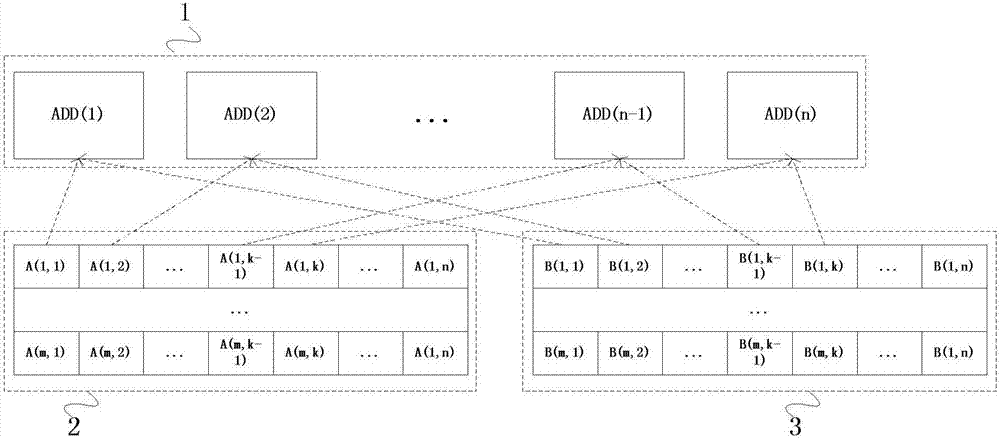
图2示出了根据本发明实施例的矩阵运算单元的操作示意图。其中1是由多个标量运算器构成向量运算器,2表示矩阵a在高速暂存存储器中的存储,3表示矩阵b在高速暂存存储器中的存储。两矩阵均是m*n的大小,向量运算器的宽度为k,即向量运算器可以一次计算出长度为k的向量的加减运算结果。运算器每次分别从a和b中获取长度为k的向量数据,在运算器中执行加减运算,并将结果写回,一个完整的矩阵加减可能需要进行若干次上述计算。如图2所示,矩阵加减部件由多个并行的标量加减运算器构成,在执行矩阵加减运算的过程中,对于指定大小的两矩阵数据,运算单元依次读入一定长度的数据,该长度等于标量加减运算器的个数。对应的数据在对应的标量运算器中执行加减法运算,每次计算矩阵数据中的一部分,并最终完成整个矩阵的加减法运算。
在执行矩阵加减标量的过程中,运算单元会将读入寄存器中的标量数据扩展成与标量运算器个数等宽的向量数据,作为加减法的一个输入,另一输入与前述执行矩阵加减的过程相同,从高速暂存存储器中读取一定长度的矩阵数据,与标量扩展后的向量执行加减法运算。
根据本发明的一种实施方式,所述矩阵加减法运算装置还包括:指令缓存单元,用于存储待执行的矩阵运算指令。指令在执行过程中,同时也被缓存在指令缓存单元中,当一条指令执行完之后,该指令将被提交。
根据本发明的一种实施方式,所述装置中的控制单元还包括:指令队列模块,用于对译码后的矩阵运算指令进行顺序存储,并在获得矩阵运算指令所需的标量数据后,将矩阵运算指令以及标量数据送至依赖关系处理模块。
根据本发明的一种实施方式,所述装置中的控制单元还包括:依赖关系处理单元,用于在矩阵运算单元获取指令前,判断该运算指令与之前未完成运算指令之间是否存在依赖关系,如是否访问相同的矩阵存储地址, 若是,将该运算指令送至存储队列模块中,待前一运算指令执行完毕后,将存储队列中的该运算指令提供给所述矩阵运算单元;否则,直接将该运算指令提供给所述矩阵运算单元。具体地,矩阵运算指令需要访问高速暂存存储器时,前后指令可能会访问同一块存储空间,为了保证指令执行结果的正确性,当前指令如果被检测到与之前的指令的数据存在依赖关系,该指令必须在存储队列内等待至依赖关系被消除。
根据本发明的一种实施方式,所述装置中的控制单元还包括:存储队列模块,该模块包括一个有序队列,与之前指令在数据上有依赖关系的指令被存储在该有序队列内直至依赖关系被消除,在依赖关系消除后,其将运算指令提供给矩阵运算单元。
根据本发明的一种实施方式,装置还包括:输入输出单元,用于将矩阵存储于存储单元,或者,从存储单元中获取运算结果。其中,输入输出单元可直接访问存储单元,负责从内存向存储单元读取矩阵数据或从存储单元向内存写入矩阵数据。
根据本发明的一种实施方式,用于本发明装置的指令集采用load/store(加载/存储)结构,矩阵运算单元不会对内存中的数据进行操作。本指令集采用精简指令集架构,指令集只提供最基本的矩阵运算操作,复杂的矩阵运算都由这些简单指令通过组合进行模拟,使得可以在高时钟频率下单周期执行指令。
在本装置执行矩阵运算的过程中,装置取出指令进行译码,然后送至指令队列存储,根据译码结果,获取指令中的各个参数,这些参数可以是直接写在指令的操作域中,也可以是根据指令操作域中的寄存器号从指定的寄存器中读取。这种使用寄存器存储参数的好处是无需改变指令本身,只要用指令改变寄存器中的值,就可以实现大部分的循环,因此大大节省了在解决某些实际问题时所需要的指令条数。在全部操作数之后,依赖关系处理单元会判断指令实际需要使用的数据与之前指令中是否存在依赖关系,这决定了这条指令是否可以被立即发送至矩阵运算单元中执行。一旦发现与之前的数据之间存在依赖关系,则该条指令必须等到它依赖的指令执行完毕之后才可以送至矩阵运算单元执行。在定制的矩阵运算单元中,该条指令将快速执行完毕,并将结果,即生成的结果矩阵写回至指令提供 的地址,该条指令执行完毕。
图3是本发明提供的矩阵加减运算指令的格式示意图,如图3所示,矩阵加减运算指令包括一操作码和至少一操作域,其中,操作码用于指示该矩阵运算指令的功能,矩阵运算单元通过识别该操作码可进行不同的矩阵运算,操作域用于指示该矩阵运算指令的数据信息,其中,数据信息可以是立即数或寄存器号,例如,要获取一个矩阵时,根据寄存器号可以在相应的寄存器中获取矩阵起始地址和矩阵长度,再根据矩阵起始地址和矩阵长度在存储单元中获取相应地址存放的矩阵。
有下列几种矩阵加减运算指令:
矩阵加法指令(ma),根据该指令,装置从高速暂存存储器的指定地址取出指定大小的矩阵数据,在矩阵运算单元中进行矩阵加法运算,并将计算结果写回至高速暂存存储器的指定地址;值得说明的是,向量可以作为特殊形式的矩阵(只有一行元素的矩阵)存储于高速暂存存储器中。
矩阵减法指令(ms),根据该指令,装置从高速暂存存储器的指定地址取出指定大小的矩阵数据,在矩阵运算单元中进行矩阵减法运算,并将计算结果写回至高速暂存存储器的指定地址;值得说明的是,向量可以作为特殊形式的矩阵(只有一行元素的矩阵)存储于高速暂存存储器中。
矩阵加标量指令(mas),根据该指令,装置从高速暂存存储器的指定地址取出指定大小的矩阵数据,从标量寄存器堆的指定地址中取出标量数据,在矩阵运算单元中进行矩阵加标量的运算,并将计算结果写回至高速暂存存储器的指定地址,需要说明的是,标量寄存器堆不仅存储有矩阵的地址,还存储有标量数据。
矩阵减标量指令(mss),根据该指令,装置从高速暂存存储器的指定地址取出指定大小的矩阵数据,从标量寄存器堆的指定地址中取出标量数据,在矩阵运算单元中进行矩阵减标量的运算,并将计算结果写回至高速暂存存储器的指定地址,需要说明的是,标量寄存器堆不仅存储有矩阵的地址,还存储有标量数据。
图4是本发明一实施例提供的矩阵运算装置的结构示意图,如图4所示,装置包括取指模块、译码模块、指令队列模块、标量寄存器堆、依赖关系处理单元、存储队列模块、矩阵运算单元、高速暂存器、io内存存取 模块;
取指模块,该模块负责从指令序列中取出下一条将要执行的指令,并将该指令传给译码模块;
译码模块,该模块负责对指令进行译码,并将译码后指令传给指令队列;
指令队列,用于暂存译码后的矩阵运算指令,并从矩阵运算指令或标量寄存器获得矩阵运算指令运算相关的标量数据;获得所述标量数据后,将所述矩阵运算指令送至依赖关系处理单元;
标量寄存器堆,提供装置在运算过程中所需的标量寄存器;标量寄存器堆包括多个标量寄存器,用于存储矩阵运算指令相关的标量数据;
依赖关系处理单元,该模块处理处理指令与前一条指令可能存在的存储依赖关系。矩阵运算指令会访问高速暂存存储器,前后指令可能会访问同一块存储空间。即该单元会检测当前指令的输入数据的存储范围和之前尚未执行完成的指令的输出数据的存储范围是否有重叠,有则说明该条指令在逻辑上需要使用前面指令的计算结果,因此它必须等到在它之前的所依赖的指令执行完毕后才能够开始执行。在这个过程中,指令实际被暂存在下面的存储队列中。为了保证指令执行结果的正确性,当前指令如果被检测到与之前的指令的数据存在依赖关系,该指令必须在存储队列内等待至依赖关系被消除。
存储队列模块,该模块是一个有序队列,与之前指令在数据上有依赖关系的指令被存储在该队列内直至存储关系被消除;
矩阵运算单元,该模块负责执行矩阵的加减运算;
高速暂存存储器,该模块是矩阵数据专用的暂存存储装置,能够支持不同大小的矩阵数据;主要用于存储输入矩阵数据和输出矩阵数据;
io内存存取模块,该模块用于直接访问高速暂存存储器,负责从高速暂存存储器中读取数据或写入数据。
图5是本发明实施例提供的运算装置执行矩阵加法指令的流程图,如图5所示,执行矩阵加法指令的过程包括:
s1,取指模块取出该条矩阵加法指令,并将该指令送往译码模块。
s2,译码模块对该矩阵加法指令译码,并将该矩阵加法指令送往指令 队列。
s3,在指令队列中,该矩阵加法指令从矩阵加法指令本身或从标量寄存器堆中获取指令中四个操作域所对应的标量数据,包括输入矩阵地址、输入矩阵长度、输出矩阵地址。
s4,在取得需要的标量数据后,该指令被送往依赖关系处理单元。依赖关系处理单元分析该指令与前面的尚未执行结束的指令在数据上是否存在依赖关系。如果存在依赖关系,则该条指令需要在存储队列中等待至其与前面的未执行结束的指令在数据上不再存在依赖关系为止。
s5,依赖关系不存在后,该条矩阵加法指令被送往矩阵运算单元。
s6,矩阵运算单元根据输入矩阵的地址和长度从高速暂存器中取出输入矩阵数据,每次分别读入两输入矩阵中一定位宽的对应数据,在矩阵加减运算器中对对齐的两列数据进行加法运算,不断重复,在矩阵运算单元中完成整个矩阵加法的运算。
s7,运算完成后,将运算结果写回至高速暂存存储器的指定地址。
图6是本发明实施例提供的运算装置执行矩阵减标量指令的流程图,如图6所示,执行矩阵减标量指令的过程包括:
s1’,取指模块取出该条矩阵减标量指令,并将该指令送往译码模块。
s2’,译码模块对该矩阵减标量指令译码,并将指令送往指令队列。
s3’,在指令队列中,该矩阵减标量指令从指令本身或从标量寄存器堆中获取指令中四个操作域所对应的标量数据,包括输入矩阵地址、输入矩阵长度、输入标量和输出矩阵地址。
s4’,在取得需要的标量数据后,该指令被送往依赖关系处理单元。依赖关系处理单元分析该指令与前面的尚未执行结束的指令在数据上是否存在依赖关系。如果存在依赖关系,则该条指令需要在存储队列中等待至其与前面的未执行结束的指令在数据上不再存在依赖关系为止。
s5’,依赖关系不存在后,该条矩阵减标量指令被送往矩阵运算单元。s6’,矩阵运算单元每次依次读入矩阵数据的一部分,在矩阵加减标量部件中进行一列数据同时减去寄存器中存储的标量数据的操作,不断重复,完成整个矩阵减标量的运算。
s7’,运算完成后,将运算结果写回至高速暂存存储器的指定地址。
综上所述,本发明提供矩阵运算装置,并配合相应的指令,能够很好地解决当前计算机领域越来越多的算法包含大量矩阵加减运算的问题,相比于已有的传统解决方案,本发明可以具有指令精简、使用方便、支持的矩阵规模灵活、片上缓存充足等优点。本发明可以用于多种包含大量矩阵加减运算的计算任务。
以上所述的具体实施例,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!