全精度及部分精度数值的计算方法及装置与流程
本发明涉及一种图形处理单元技术,特别是一种全精度及部分精度数值的计算方法及装置。
背景技术:
图形处理单元的架构通常具有数百个基本着色器处理单元(basicshaderprocessingunits),又称为流处理器(streamprocessors)。每一个流处理器于每个周期处理一个单指令多数据(simd,singleinstructionmultipledata)执行线程的指令,接着于下一个周期处理另一个单指令多数据执行线程。一般而言,为符合ieee754规范,每个流处理器要能计算32比特浮点数(fp32)或整数数值(int32)。32比特数值可称为全精度(fp,fullprecision)数值。然而,于一些应用中,例如,画素着色器(pixelshader)、图像处理(imageprocessing)等,流处理器只要能计算较低精度的数值就能满足需求,例如,16/18/24比特浮点数(fp16/18/24)等。16/18/24比特数值可称为部分精度(pp,partialprecision)数值。因此,本发明提出一种全精度及部分精度数值的计算方法及装置,用以提升流处理器的效能。
技术实现要素:
本发明的实施例提出一种全精度及部分精度数值的计算方法,由指令解码单元执行,包含下列步骤:解码从一编译器传来的一指令请求;以及依据指令请求中的指令模式执行m次循环以产生m个计算第一类型数据的微指令或执行n次循环以产生n个计算第二类型数据的微指令,使得多个算术逻辑组完成一个执行线程的多个通道计算。其中,m小于n,并且上述第一类型数据的精度低于上述第二类型数据的精度。
本发明的实施例提出一种全精度及部分精度数值的计算装置,包含第一类运算通道;及多个第二类运算通道,耦接于第一类运算通道。当运行于第一模式时,第一类运算信道及第二类运算信道中的每一者独立完成一组第一类型数据的计算。当运行于第二模式时,第二类运算通道的每一者计算一组第二类型数据的一部份以产生部分结果,并且第二类运算通道合并第一类运算通道输出的部分结果并使用合并结果完成该组第二类型数据的计算。
附图说明
图1是通用流处理器的流水线示意图。
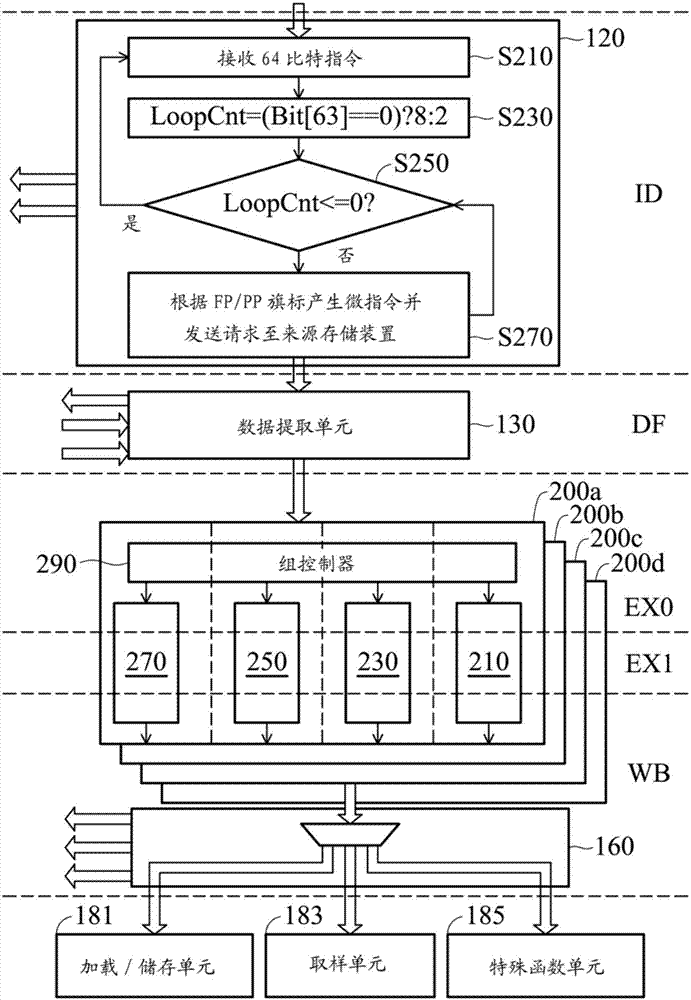
图2是依据本发明实施例的流处理器的流水线示意图。
图3a是依据本发明实施例的fp浮点数示意图。
图3b是依据本发明实施例的pp浮点数示意图。
图4是依据本发明实施例的算术逻辑组的第一类运算通道的硬件架构图。
图5是依据本发明实施例的第二类运算通道的硬件架构图。
具体实施方式
以下说明是完成发明的较佳实现方式,其目的在于描述本发明的基本精神,但并不用以限定本发明。实际的发明内容必须参考之后的权利要求范围。
必须了解的是,使用于本说明书中的“包含”、“包括”等词,是用以表示存在特定的技术特征、数值、方法步骤、作业处理、组件以及/或组件,但并不排除可加上更多的技术特征、数值、方法步骤、作业处理、组件、组件,或以上的任意组合。
在权利要求中使用如“第一”、“第二”、“第三”等词是用来修饰权利要求中的组件,并非用来表示之间具有优先权顺序,先行关系,或者是一个组件先于另一个组件,或者是执行方法步骤时的时间先后顺序,仅用来区别具有相同名字的组件。
图1是通用流处理器的流水线示意图。流处理器的流水线可包含四个顺序性阶段:指令解码(id,instructiondecode);数据提取(df,datafetch);执行(ex,execute)以及回写(wb,writeback)。回写阶段产生的最终结果可储存至通用缓存器(cr,commonregister),或输出至后处理单元。详细来说,指令解码单元120解码从编译器(compiler)传来的指令请求110,并通知需要取得数据或常数的通用缓存器地址121以及/或常数缓存器地址123。指令解码单元120可取得指令请求110中的操作码(opcode,operationcode)。数据提取单元130取得通用缓存器地址121的数据133以及/或常数缓存器地址123的常数135,如果需要,通知欲写回的通用缓存器地址131。取得的数据133以及/或常数135又可称为操作数(operand),可为全精度数值及部分精度数值。执行单元140可从数据提取单元130接收操作数以及/或从通用缓存器或常数缓存器(cb,constantbuffer)接收数据或常数141。可依据操作码控制解多任务器(demux,de-multiplexer)151将数据提取单元130连接上算术单元(arithmeticunit)153、比较/逻辑单元(compare/logicunit)155及选择/旁路单元(selection/branchunit)157中之一者,用以将操作码及操作数从数据提取单元130传送至连接上的单元。此外,可依据操作码控制控制多任务器(mux,multiplexer)159将算术单元153、比较/逻辑单元155及选择/旁路单元157中之连接一者连接上回写单元(writebackunit)160,用以将执行结果传送至回写单元160。算术单元153可依据操作码对操作数进行数学计算。数学计算包含加、减、乘、除、四舍五入等。比较/逻辑单元155可依据操作码对操作数进行比较或逻辑操作。比较操作包含取大值、取小值、数值比较等,逻辑操作包含及(and)、或(or)、非(not)、或非(nor)、互斥或(xor)等。算术单元153及比较/逻辑单元155可统称为算术逻辑单元(alu,arithmeticlogicunit)。回写单元160可将运算后的结果161写回至通用缓存器,或者传送至加载/储存单元181、取样单元183以及特殊函数单元185中之一者。详细来说,判断单元171依据操作数中的目的地地址决定将运算结果输出至通用缓存器,或者加载/储存单元181、取样单元183以及特殊函数单元185中的一者。此外,可依据操作数中的目的地地址控制解多任务器173将运算结果输出至加载/储存单元181、取样单元183以及特殊函数单元185中之一者。特殊函数单元185实施复杂数学运算,例如正弦(sin)、余弦(cos)、根数(sqrt)等。加载/储存单元181、取样单元183以及特殊函数单元185可统称为后处理单元(post-processingunit)。
一个执行线程(thread)包含可合并执行的32个通道(lanes),或称为simd32。图2是依据本发明实施例的流处理器的流水线示意图。一个流处理器可包含多个算术逻辑组(alg,arithmeticlogicgroups),例如四个算术逻辑组200a至200d。每个算术逻辑组(简称为alu-quad)可包含组控制器290及四个运算单元(computationunits)210、230、250及270,用以于一个周期(cycle)并行执行4组部分精度(pp,partialprecision)数据的运算或执行1组全精度(fp,fullprecision)数据的运算。所以,每个流处理器可支持4组fp或16组pp数据的运算。运算单元210、230、250及270中之任一者可执行24比特数值(或可称为pp数值)的运算,并且结合运算单元210、230、250及270可执行32比特数值(或可称为fp数值)的运算。
图3a是依据本发明实施例的fp浮点数示意图。fp浮点数以32比特表示,而最高比特(第31比特)为符号位(signbit)310a。fp浮点数另包含23比特的尾数310b(第8至30比特)及8比特的指数310c(第0至7比特)。图3b是依据本发明实施例的pp浮点数示意图。pp浮点数以24比特表示,而最高比特(第23比特)为符号位330a。pp浮点数另包含16比特的尾数330b(第7至22比特)及7比特的指数330c(第0至6比特)。
运算单元210、230、250及270中的每一者可独立完成pp数值的fmad操作,或者运算单元210、230、250及270合并完成fp数值的fmad操作。fmad操作(=axb+c)的方程式如下:
dest=src0xsrc1+src2,
src0、src1及scr2代表三个来源存储装置(sourcememories)中的pp/fp数值,dest代表即将储存于目的地存储装置的pp/fp数值。运算单元210、230、250及270中的每一者包含一个乘法器,用以将pp/fp数值src0乘以pp/fp数值src1。运算单元210、230、250及270中之每一者另包含一个加法器,用以将乘法器的输出加上pp/fp数值scr2,用以产生fmad操作的运算结果。
流处理器的流水线可包含五个顺序性阶段:指令解码;数据提取;零级执行(ex0);一级执行(ex1)以及回写。指令解码单元120可执行解码流程,用以侦测指令模式,例如fp或pp,以及根据指令模式产生m个计算第一类型数据的微指令,或者产生n个计算第二类型数据的微指令。于一些实施例中,m为2,n为8,第一类型数据为pp数据,而第二类型数据为fp数据。详细来说,指令解码单元120可从编译器接收64比特指令,包含操作码(opcode)、来源(source)、目的地(destination)及断言(predicate)操作数(operands)及fp/pp旗标等(步骤s210)。指令的最高比特(msb,mostsignificantbit,bit63)存放fp/pp旗标。例如,如果fp/pp旗标为0,代表此指令为fp指令。如果fp/pp旗标为1,代表此指令为pp指令。于此须注意的是,熟习此技艺人士可颠倒fp/pp旗标代表的模式,本发明并不因此受限。如果fp/pp旗标为1,循环次数loopcnt设为2;如果fp/pp旗标为0,循环次数loopcnt设为8(步骤s230)。当循环次数loopcnt小于或等于0时(步骤s250中“是”的路径),从编译器接收下一个64比特指令(步骤s210)。当循环次数loopcnt大于0时(步骤s250中“否”的路径),根据fp/pp旗标产生微指令,产生来源存储装置(sourcememory)的地址,依据产生的地址发送数据请求给来源存储装置,并更新loopcnt(步骤s270)。来源存储装置可为通用寄存器(cr,commonregister)或常数缓存器(constantbuffer)。举例来说,当fp/pp旗标为1时,产生simd16指令,产生16个通道的来源存储装置的地址,依据产生的地址发送数据请求给来源存储装置,以及将循环次数loopcnt减1。当fp/pp旗标为0时,产生simd4指令,产生4个通道的fp数值scr0及scr1的来源存储装置的地址,并且依据产生的地址发送数据请求给来源存储装置,以及将循环次数loopcnt减1。于pp模式,通过如上所述的解码流程,执行阶段于第1个周期可实施执行线程中的第0个通道(lane0)至第15个通道(lane15),并且于第2个周期可实施执行线程中的第16个通道(lane16)至第31个通道(lane31)。于fp模式,通过如上所述的解码流程,执行阶段于第1个周期可实施执行线程中的第0个通道(lane0)至第3个通道(lane3),于第2个周期可实施执行线程中的第4个通道(lane4)至第7个通道(lane7),依此类推。
数据提取单元130从来源存储装置提取来源数据(sourcedata)scr0及scr1。数据提取单元130另可从断言存储装置(predicatememory)接收断言数据(predicatedata),以及产生通道掩码(lanemask)。断言存储装置可为断言寄存器(pr,predicateregister)。
在零级执行(ex0)阶段,算术逻辑组200a至200d中的每一者中的群控制器290可依据微指令类型指示运算单元210、230、250及270运行于pp模式或fp模式。当微指令为simd16指令时,指示运算单元210、230、250及270运行于pp模式。当微指令为simd4指令时,指示运算单元210、230、250及270运行于fp模式。算术逻辑组200a至200d可并行执行simd4fp通道,或simd16pp通道的来源数据scr0及scr1的乘法运算。
于一级执行(ex1)阶段,于pp模式,算术逻辑组200a至200d可并行执行乘法运算结果及来源数据scr2的加法运算,接着,输出加法运算结果。于fp模式,算术逻辑组200a至200d中的每一者的运算单元210可合并运算单元230、250及270及自己的乘法运算结果,执行乘法运算结果及来源数据scr2的加法运算,接着,输出加法运算结果。
于回写阶段,于pp模式,算术逻辑组200a至200d的运算单元210、230、250及270中的每一者执行归一化(normalization)及数据格式转换(dataformatting),用以产生即将储存至目的地存储装置(destinationmemory)或输出至后处理单元的pp数据。于fp模式,算术逻辑组200a至200d的运算单元210中之每一者执行归一化及数据格式转换,用以产生即将储存至目的地存储装置或输出至后处理单元的fp数据。目的地存储装置可为通用寄存器。
此外,运算单元210、230、250及270中的每一者可使用如上所述的fmad架构独立完成pp数值的其它基本运算,例如乘法、加法等。或者,运算单元210、230、250及270可使用如上所述的fmad架构合并完成fp数值的其它基本操作。
例如,fmul操作(=axb)相当于:
dest=src0xsrc1+0,
于指令解码阶段,指令解码单元120可更将来源数据src2=0储存至指定的来源存储装置。最后,输出为fmul操作的运算结果。
例如,fadd操作(=a+b)相当于:
dest=src0x1.0+src2,
于指令解码阶段,指令解码单元120可更将来源数据src1=1.0储存至指定的来源存储装置。最后,输出为fadd操作的运算结果。
例如,fcmp_gt操作(=a>b)相当于:
dest=src0x1.0+(-src2),
于指令解码阶段,指令解码单元120可更将来源数据src2转为-src2,并将转换结果储存至指定的来源存储装置。最后,输出的符号位为fcmp_gt操作的运算结果。
例如,min操作(=min(a,b))相当于:
dest=src0x1.0+(-src2),
于指令解码阶段,指令解码单元120可更将来源数据src2转为-src2,并将转换结果储存至指定的来源存储装置。最后,依据计算后的符号位输出来源数据src0或src2,作为min操作的运算结果。
图4是依据本发明实施例的算术逻辑组的第一类运算通道的硬件架构图。第一类运算通道可实施于运算单元210,包含ex0;ex1以及wb阶段的硬件,其中每阶段的硬件通过延迟电路(delaycircuit)(以“d”表示)耦接至上一阶段的硬件。运算单元210可根据组控制器290的指示,运行于pp模式或fp模式。ex0阶段的硬件包含17比特乘法器411及10比特加法器413,ex1阶段的硬件包含位移选择器431、32比特加法器432、多任务器433及434、34比特位移器435、34比特加法器436及10比特选择器437。
以下说明运算单元210当从组控制器290接收到pp模式的指示时,运行于pp模式的处理:于ex0阶段,为完成src0xsrc1的计算,17比特乘法器411将pp数值src0的尾数(表示为src0_mant)乘以pp数值src1的尾数(表示为src1_mant)以产生32比特的结果,而10比特加法器413将pp数值src0的指数(表示为src0_exp)加上pp数值src1的指数(表示为src1_exp)以产生10比特的结果。于ex1阶段,为完成(src0xsrc1)+src2的计算,10比特选择器437比较pp数值src2的指数(表示为src2_exp)与10比特加法器413的输出结果,并且输出较大者作为指数的最终结果。于此须注意的是,于pp模式中,由于不需要合并其它运算单元230、250及270的结果,位移选择器431及32比特加法器会直接向下传递17比特乘法器的输出。此外,10比特选择器437更依据比较结果控制多任务器433及434,用以将17比特乘法器411的输出及pp数值src2的尾数(表示为src2_mant)中的一者输出至34比特位移器435,并且将另一者输出至34比特加法器436。34比特加法器436将34比特位移器435的输出加上多任务器434的输出,用以产生尾数的最终结果。
wb阶段的硬件包含归一化单元(normalizationunit)450。为了让运算单元210可输出pp数值的结果,指令解码单元120发出讯号out_pp给34比特位移器451及10比特加法器453,使得34比特位移器451将34位加法器436的输出(亦即是尾数)舍弃7比特成为27比特,以及使得10比特加法器453将10比特选择器437的输出(亦即是指数)舍弃1比特成为9比特。接着,比较器455、34比特位移器451及10比特加法器453形成一个回路,用以进行浮点数的归一化。比较器455持续比较34比特位移器451的输出的最高位是否为1,直到34比特位移器451的输出的最高位为1为止。于比较的每一回合,如果不是,比较器455输出致能讯号en给34比特位移器451及10比特加法器453,使得34比特位移器451将27比特的结果左移1个比特,以及使得10比特加法器453将9比特的结果加上-1。合并器457合并1比特的符号位、16比特的尾数(34比特位移器451的最终输出)及7比特的指数(10比特加法器453的最终输出),并输出合并结果(如图3b所示)。合并结果可写入目的地存储装置,或输出至后处理单元。
由于fmad操作及如上所述的其它基本操作的结果常接着与0比较,编译器可于fmad操作或如上所述的其它基本操作后加上一个后逻辑指令,例如:
alu-instrdest,src1,src0
+pxxxdstprf,dest.cmp0,[!]srcp0
其中,alu-instr代表fmad操作或如上所述的其它基本操作,src0及src1代表来源数据,dest代表目的地数据,dest.cmp0代表目的地数据与0的比较结果及[!]srcp0代表来源断言寄存器里的数据,作为后逻辑操作的一个来源操作数,xxx代表指定的比较操作,罗列如下表:
为提升效能,运算单元210可于wb阶段加上后逻辑单元470,而后逻辑单元470包含比较器471。当指令解码单元120解译到后逻辑指令时,输出3比特的比较操作码pcmp_op给比较器471,用以驱动比较器471依据比较操作码进行目的地数据与零间的指定比较操作,并且输出比较结果。于此须注意的是,此目的地数据可为浮点数并且未进行归一化。
当pcmp_op为0时,比较器471直接输出0。
当pcmp_op为1时,比较器471判断运算结果的符号位、34比特加法器436及10比特选择器437的输出。当符号位为0且34比特加法器436及10比特选择器437的输出皆不为0时,输出1;否则,输出0。
当pcmp_op为2时,比较器471判断运算结果的符号位、34比特加法器436及10比特选择器437的输出。当符号位、34比特加法器436及10比特选择器437的输出皆为0时,输出1;否则,输出0。
当pcmp_op为3时,比较器471只需判断运算结果的符号位。当符号位为0时,输出1;否则,输出0。
当pcmp_op为4时,比较器471只需判断运算结果的符号位。当符号位为1时,输出1;否则,输出0。
当pcmp_op为5时,比较器471判断运算结果的符号位、34比特加法器436及10比特选择器437的输出。当符号位、34比特加法器436及10比特选择器437的输出中的至少一者不为0时,输出1;否则,输出0。
当pcmp_op为6时,比较器471判断运算结果的符号位、34比特加法器436及10比特选择器437的输出。当符号位、34比特加法器436及10比特选择器437的输出皆为0,或者符号位为1时,输出1;否则,输出0。
当pcmp_op为7时,比较器471直接输出1。
藉由后逻辑单元470,可于输出fmad操作或如上所述的其它基本操作的运算结果时,同时输出针对运算结果的逻辑比较结果。
图5是依据本发明实施例的算术逻辑组的第二类运算通道的硬件架构图。第二类运算通道可实施于运算单元230、250及270中的每一者,包含ex0;ex1以及wb阶段的硬件,其中每阶段的硬件通过延迟电路(以“d”表示)耦接至上一阶段的硬件。运算单元230、250及270中的每一者可根据组控制器290的指示,运行于pp模式或fp模式。ex0阶段的硬件包含17比特乘法器511及9比特加法器513,ex1阶段的硬件包含多任务器531及532、22比特位移器533、22比特加法器535及9比特选择器537。
以下说明运算单元230、250及270中的每一者当从组控制器290接收到pp模式的指示时,运行于pp模式的处理:于ex0阶段,为完成src0xsrc1的计算,17比特乘法器511将pp数值src0的尾数(表示为src0_mant)乘以pp数值src1的尾数(表示为src1_mant)以产生34比特的结果,而9比特加法器513将pp数值src0的指数(表示为src0_exp)加上pp数值src1的指数(表示为src1_exp)以产生9比特的结果。于此须注意的是,9比特加法器513只运行于pp模式,并且,当从组控制器290接收到运行于fp模式的指示时,9比特加法器513不运行。于ex1阶段,当从组控制器290接收到运行于pp模式的指示时,解多任务器539将17比特乘法器511连接至多任务器531及532。为完成(src0xsrc1)+src2的计算,9比特选择器537比较pp数值src2的指数(表示为src2_exp)与9比特加法器513的输出结果,并且输出较大者作为指数的最终结果。9比特选择器537更依据比较结果控制多任务器531及532,用以将17比特乘法器511的输出及pp数值src2的尾数(表示为src2_mant)中的一者输出至22比特位移器533,并且将另一者输出至22比特加法器535。22比特加法器535将22比特位移器533的输出加上多任务器532的输出,用以产生尾数的最终结果。
wb阶段的硬件包含归一化单元550。比较器555、22比特位移器551及9比特加法器553形成一个循环,进行归一化。比较器555持续比较22比特位移器551的输出的最高位是否为1,直到22比特位移器551的输出的最高位为1为止。于比较的每一回合,如果不是,比较器555输出讯号en给22比特位移器551及9比特加法器553,使得22比特位移器551将22比特的结果左移1个比特,以及使得9比特加法器553将9比特的结果加-1。合并器557合并1比特的符号位、16比特的尾数(22比特位移器551的最终输出)及7比特的指数(9比特加法器553的最终输出),并输出合并结果(如图3b所示)。合并结果可写入目的地存储装置,或输出至后处理单元。
为提升效能,运算单元230、250及270中的每一者可于wb阶段加上后逻辑单元570,而后逻辑单元570包含比较器571。比较器571的技术细节可参考如上所述比较器471的说明,为求简洁不再赘述。
此外,运算单元210、230、250及270可合并完成fp数值的fmad操作。当运行于fp模式,运算单元230、250及270只计算src0xsrc1的尾数部分,运算单元210合并运算单元230、250及270的结果,并完成src0xsrc1+src2的剩余部分。
以下说明运算单元230当从组控制器290接收到fp模式的指示时,运行于fp模式的处理:于ex0阶段,为完成src0xsrc1的尾数计算,17比特乘法器511将fp数值src0的尾数的高8比特(表示为src0_h8)乘以fp数值src1的尾数的低16比特(表示为src1_l16)。于ex1阶段,解多任务器539将17比特乘法器511连接至运算单元210中的位移选择器431,用以输出17比特乘法器511的计算结果至位移选择器431。
以下说明运算单元250当从组控制器290接收到fp模式的指示时,运行于fp模式的处理:于ex0阶段,为完成src0xsrc1的尾数计算,17比特乘法器511将fp数值src0的尾数的低16比特(表示为src0_l16)乘以fp数值src1的尾数的高8比特(表示为src1_h8)。于ex1阶段,解多任务器539将17比特乘法器511连接至运算单元210中的位移选择器431,用以输出17比特乘法器511的计算结果至位移选择器431。
以下说明运算单元270当从组控制器290接收到fp模式的指示时,运行于fp模式的处理:于ex0阶段,为完成src0xsrc1的尾数计算,17比特乘法器511将fp数值src0的尾数的高8比特(表示为src0_h8)乘以fp数值src1的尾数的高8比特(表示为src1_h8)。于ex1阶段,解多任务器539将17比特乘法器511连接至运算单元210中的位移选择器431,用以输出17比特乘法器511的计算结果至位移选择器431。
以下说明运算单元210当从组控制器290接收到fp模式的指示时,运行于fp模式的处理:于ex0阶段,为完成src0xsrc1的计算,17比特乘法器411将fp数值src0的尾数的低16比特(表示为src0_l16)乘以fp数值src1的尾数的低16比特(表示为src1_l16),而10比特加法器413将fp数值src0的指数(表示为src0_exp)加上fp数值src1的指数(表示为src1_exp)以产生10比特的结果。于ex1阶段,为合并运算单元210、230、250及270于ex0阶段的src0xsrc1的尾数运算结果,位移选择器431将17比特乘法器411的运算结果右移16比特并输出至32比特加法器432,将运算单元230的17比特乘法器511的运算结果输出至32比特加法器432,将运算单元250的17比特乘法器511的运算结果输出至32比特加法器432,及将运算单元270的17比特乘法器411的运算结果左移16比特并输出至32比特加法器432。32比特加法器432加总四个值以产生src0xsrc1的尾数运算结果。为完成(src0xsrc1)+src2的计算,10比特选择器437比较fp数值src2的指数(表示为src2_exp)与10比特加法器413的输出结果,并且输出较大者作为指数的最终结果。此外,10比特选择器437更依据比较结果控制多任务器433及434,用以将32比特加法器432的输出及fp数值src2的尾数(表示为src2_mant)中的一者输出至34比特位移器435,并且将另一者输出至34比特加法器436。34比特加法器436将34比特位移器435的输出加上多任务器434的输出,用以产生尾数的最终结果。
为了让运算单元210可输出fp数值的结果,指令解码单元120发出讯号out_fp给34比特位移器451及10比特加法器453,使得34比特位移器451保留并处理34位加法器436的原始输出,以及使得10比特加法器453保留并处理10比特选择器437的原始输出。接着,比较器455、34比特位移器451及10比特加法器453形成一个循环,进行归一化。于每一回合,比较器455比较34比特位移器451的输出的最高位是否为1。如果不是,比较器455输出致能讯号en给34比特位移器451及10比特加法器453,使得34比特位移器451将27比特的结果左移1个比特,以及使得10比特加法器453将9比特的结果加上-1。34比特位移器451及10比特加法器453的调整持续进行到比较器455侦测到34比特位移器451的输出的最高位为1为止。合并器457合并1比特的符号位、23比特的尾数(34比特位移器451的最终输出)及7比特的指数(10比特加法器453的最终输出),并输出合并结果(如图3a所示)。
由于比较器471于fp模式的运作类似于pp模式,因此,可参考比较器471于pp模式的描述,为求简洁不再赘述。
从一个面向来说,为了让四个算术逻辑组200a至200d中的每一者可以并行执行4组部分精度数据的运算或执行1组全精度数据的运算。本发明的实施例提出一种全精度及部分精度数值的计算装置,包含第一类运算通道(如运算单元210);及多个第二类型通道(如运算单元230、250及270),耦接于第一类运算通道。当运行于第一模式(例如,pp模式)时,第一类运算通道及第二类运算通道中的每一者独立完成一组第一类型数据(例如,pp数据)的计算。当运行于第二模式(例如,fp模式)时,第二类运算通道的每一者计算一组第二类型数据(例如,fp数据)的一部份以产生部分结果,并且第二类运算通道合并第一类运算通道输出的部分结果并使用合并结果完成该组第二类型数据的计算。
由于数学运算结果常接着与0比较,从另一个面向来说,本发明的实施例提出一种整合算术及逻辑处理的装置,包含计算装置(例如,包含图4及图5中ex0及ex1阶段的装置)及后逻辑单元470或570。计算装置计算多个来源数据(例如,pp/fp数据src0、src1及src2)以产生第一目的地数据并输出第一目的地数据(包含浮点数的符号位、尾数及指数)。后逻辑单元,耦接至计算装置,用以进行第一目的地数据与零之间的比较操作,以及输出比较结果。
为了让四个算术逻辑组200a至200d中的每一者可以输出部分精度数据或全精度数据的运算结果,从更另一个面向来说,本发明的实施例另提出一种整合算术及逻辑处理的装置,包含计算装置及归一化单元。计算装置计算多个来源数据以产生第一目的地数据并输出第一目的地数据。归一化单元,耦接至计算装置,当接收到输出为第一类型数据的指示out_pp时,将第一目的地数据进行归一化以产生第一类型的第二目的地数据(例如,pp数据);当接收到输出为第二类型数据的指示out_fp时,将第一目的地数据进行归一化以产生第二类型的第二目的地数据(例如,fp数据)。
虽然图2、4及5中包含了以上描述的组件,但不排除在不违反发明的精神下,使用更多其它的附加组件,已达成更佳的技术效果。此外,虽然附图的处理步骤采用特定的顺序来执行,但是在不违反发明精神的情况下,熟习此技艺人士可以在达到相同效果的前提下,修改这些步骤间的顺序,所以,本发明并不局限于仅使用如上所述的顺序。
虽然本发明使用以上实施例进行说明,但需要注意的是,这些描述并非用以限缩本发明。相反地,此发明涵盖了熟习此技艺人士显而易见的修改与相似设置。所以,申请权利要求范围须以最宽广的方式解释来包含所有显而易见的修改与相似设置。
【符号说明】
id指令解码阶段;
df数据提取阶段;
ex执行阶段;
ex0零级执行阶段;
ex1一级执行阶段;
wb回写阶段;
110指令请求;
120指令解码单元;
121通用缓存器地址;
123常数缓存器地址;
130数据提取单元;
131通用缓存器地址;
133数据;
135常数;
140执行单元;
141数据或常数;
151解多任务器;
153算术单元;
155比较/逻辑单元;
157选择/旁路单元;
160回写单元;
171判断单元;
173解多任务器;
181加载/储存单元;
183取样单元;
185特殊函数单元;
s210~s270方法步骤;
200a~200d算术逻辑组;
210(第一类)运算单元;
230、250、270(第二类)运算单元;
290组控制器;
310a、330a符号位;
310b、330b尾数;
310c、330c指数;
src0_mant、src1_mant、src2_mant来源数据的尾数;
src0_exp、src1_exp、src2_exp来源数据的指数;
sign符号位;
d延迟电路;
mul_lan1、mul_lan2、mul_lan3尾数的乘法部分结果;
out_fp/pp输出模式;
en致能讯号;
41117比特乘法器;
41310比特加法器;
431位移选择器;
43232比特加法器;
433、434多任务器;
43534比特位移器;
43634比特加法器;
43710比特选择器;
450归一化单元;
45134比特位移器;
45310比特加法器;
455比较器;
457合并器;
470后逻辑单元;
471比较器;
51117比特乘法器;
5139比特加法器;
531、532解多任务器;
53322比特位移器;
53522比特加法器;
5379比特选择器;
550归一化单元;
55122比特位移器;
5539比特加法器;
555比较器;
557合并器;
570后逻辑单元;
571比较器。
- 还没有人留言评论。精彩留言会获得点赞!