一种基于相邻数据特征的数据缺失填充方法与流程
本发明属于设备状态诊断领域。
背景技术:
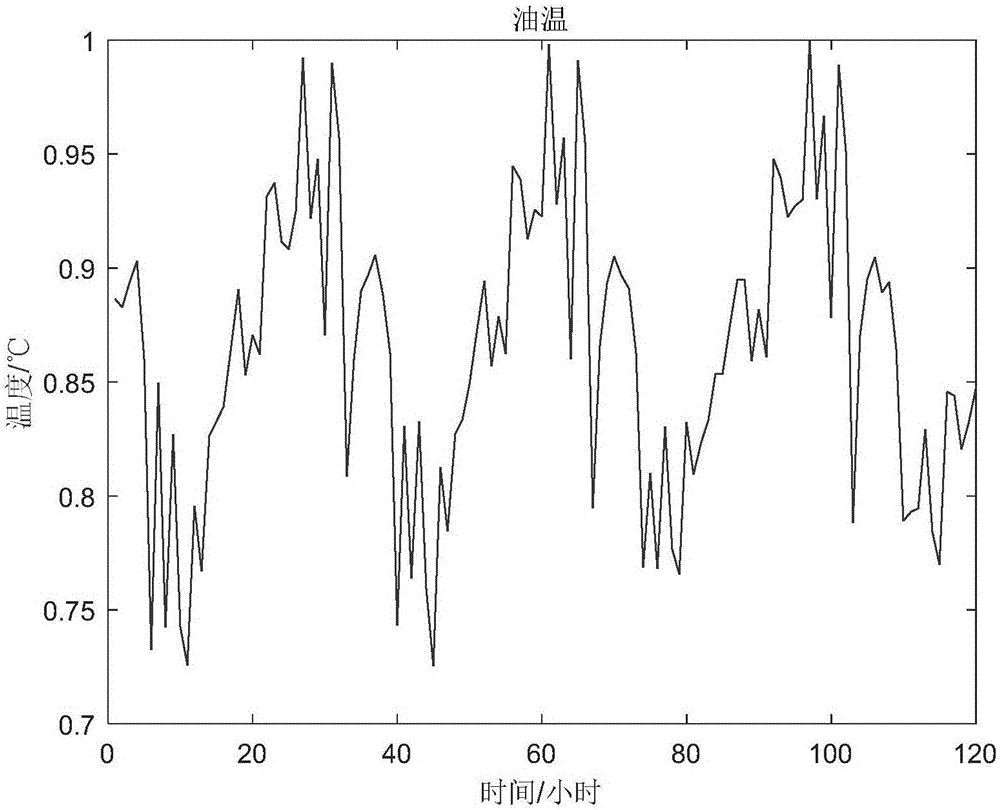
:在线监测数据反映了设备运行状态,常被用来诊断设备故障情况,但由于监测设备在受到外界干扰或设备损坏时,会不可避免地出现数据缺失问题。数据缺失破坏了原数据的完整性和真实性,很多的统计工具直接将缺失数据缺省,这种处理方法虽然效率高,但当使用处理过的数据集进行数据挖掘时,将会使聚类模型产生倾斜,从而使挖掘结果产生偏差。目前比较好的缺失值处理方法是对不完整的数据记录进行填充。数据填充常见算法有KNN、贝叶斯网络、神经网络等。KNN算法计算量较大;贝叶斯网络需要的数据多,分析计算比较复杂,特别在解决复杂问题时,这个矛盾就更为突出;神经网络算法常常会出现局部最优的问题,而且无法用神经网络直观地解释推理过程和推理依据。技术实现要素:本发明的目的是为解决利用数据对设备进行故障诊断时出现数据缺失的问题。为实现本发明目的而采用的技术方案是这样的,一种基于相邻数据特征的数据缺失填充方法,其特征在于:读取一段按照时间顺序排列的数据序列;所述数据序列中,存在n个数据,所述数据序列为data(x1)、data(x2)……data(xn)表示,x1、x2……xn为时间序列Q,n为自然数;所述数据序列中,缺失了编号为i的数据,即data(i),i为等差数列Q中的一个值;填充编号为i的数据,包括以下步骤:1)读取与编号为i的数据相邻的数据data(i-1);在所述数据序列中,从头开始寻找与data(i-1)之差的绝对值小于0.02的数据;如果没有找到这样的数据,则下一步直接进入步骤5);如果找到这样的一个或多个数据,令其中一个数据的序列号为k-1,即该数据记为data(k-1),并进入下一步,k为时间序列Q中的一个值;如果1<i<4,即缺失值处于数据序列左边界位置,则下一步直接进入步骤3)。2)读取data(k)和data(i)左边的三个数据,将data(k-3)、data(k-2)和data(k-1)进行一次拟合,data(i-3)、data(i-2)和data(i-1)进行一次拟合;如果data(k-3)、data(k-2)和data(k-1)的变化趋势与data(i-3)、data(i-2)和data(i-1)的变化趋势相同,则进入下一步;否则,回到步骤1),重新选取data(k-1),但无法通过步骤1)选取data(k-1)时,则进入步骤5);如果i>n-3,即缺失值处于数据序列右边界位置,则下一步直接进入步骤4)。3)读取data(k)和data(i)右边的三个数据,将data(k+3)、data(k+2)和data(k+1)进行一次拟合,data(i+3)、data(i+2)和data(i+1)进行一次拟合;如果data(k+3)、data(k+2)和data(k+1)的变化趋势与data(i+3)、data(i+2)和data(i+1)的变化趋势相同,则进入下一步;否则,回到步骤1),重新选取data(k-1),但无法通过步骤1)选取data(k-1)时,则进入步骤5);4)将data(k)保存到数据集K中,回到步骤1),重新选取data(k-1),直到无法通过步骤1)选取data(k-1)时,进入下一步;5)若被保存数据只有1个数据data(k),则若没有数据被保存下来,则取缺失值data(i)左右两侧数据的平均值。由于这两种情况出现概率较小,在流程图中舍去对这两种情况的介绍。如果数据集K存在j-1(j>2)个数据,则将数据集K里面的数据拟合为f(x),令M=f(j)。6)将数值M填充到data(i)的位置上。进一步,步骤1)开始前,对data(x1)、data(x2)……data(xn)归一化处理。本发明的技术效果是毋庸置疑的,利用此方法,不必知道数据的具体周期,不仅有效得到非边界缺失值的填充值,也有效得到其他方法不易得到的边界缺失值的填充值。附图说明图1为本发明的流程图,部分流程省略。图2实施例中的某地区变压器A相油温归一化数据。图3实施例中的有缺失值的某地区变压器A相油温数据。图4实施例中的填充缺失值后的油温曲线与原始油温曲线对比图。具体实施方式下面结合实施例对本发明作进一步说明,但不应该理解为本发明上述主题范围仅限于下述实施例。在不脱离本发明上述技术思想的情况下,根据本领域普通技术知识和惯用手段,做出各种替换和变更,均应包括在本发明的保护范围内。下面将结合本发明实例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。本说明书以某地区变压器A相温度油温120个数据为例,现将数据归一化,如图2所示。分别剔除了第3、53、61、85、117位数据,模拟缺失值问题,如图3所示。在本实施例中,采用了上述基于相邻数据特征的缺失值填充方法,具体计算过程如下:1、读取数据,检测出第3、53、61、85、117位数据缺失,最大值为50.21。2、将数据都除以50.21,进行归一化。3、以处于第3位的缺失值为例,第17、18、30、35、36、38、51、52、54、69、72、86、90、100、108位数据与之近似相等,但符合要求的是第36、69、90位数据,目标数据为第37、70、91位数据,分别是0.90565624、0.90517825、0.86108345,横坐标数量级太小就会致使拟合效果很差,所以,横坐标第一个数据为1,第二个数据为400,第j个数据为398+j的形式。用最小二乘法拟合得到f(x)=-5.659×10-5x+0.9058,可预测出归一化后的第四个数据为f(402)=0.88305082,还原得44.33798。4、得到上述缺失值对应填充值分别为(44.32205,43.13566,50.2100,43.34584,43.22929)。5、将填充值放回对应缺失位置上,如图4所示,红色为原数据,绿色为填充值数据。利用此方法计算的填充值与原数据对比,求出的误差如表1所示。由表1可以看出,本方法计算误差普遍较小,验证了算法的可行性。表1缺失值计算值及其误差原数据位置序号缺失值计算值绝对误差相对误差44.8470344.33798-0.50902-0.0113543.03205343.135661.305980.0024150.12106150.2100-5.78302-0.0017744.32098543.345840.017080.0113142.381011743.229291.956980.020016当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1