一种改进的不确定连续属性决策树的构建方法与流程
本发明涉及机器学习、人工智能以及数据挖掘领域,具体涉及一种改进的不确定连续属性决策树的构建方法。
背景技术:
决策树研究是数据挖掘和机器学习中的一项重要和积极的研究课题。其所提出的算法被广泛地应用于实际问题当中,如ID3,CART和C4.5,此类算法主要是研究准确率的问题。随着科学技术的进步,近年来,不确定数据频繁地出现在现实应用中,包括无线传感器网络、无线射频识别、隐私保护等领域。其数据特点是数据值并非是确定的,即表示一个数据点,其表示方式是将多种取值作为一个整体,按照某种概率分布作为每个取值对应出现可能性,其越来越频繁的出现促使相关的研究得到了广泛关注和快速发展。而传统数据挖掘技术中往往忽略了数据中的不确定性,其研究模型与客观世界不符。所以不确定数据挖掘技术对数据挖掘技术的实际应用有着重要意义。属性的不确定性包括离散属性和连续属性,在训练和测试的过程中,为了保证有效的评估模型,验证分类器的性能,数据集中的类别都是已知的。这里主要是针对于不确定连续属性的分类与预测,另外由于测量仪器受精度的影响,采集的数据往往包含一定的误差,不是完全准确的。
在树的生长过程中,一个不确定连续用例在节点属性上测试时被分配到多个节点中,覆盖了多个分支,然而确定用例只会按照属性取值被确定地分配到相应的分支,另外在建树过程中,为了更好的避免决策树中存在的过度拟合问题,本发明提出了一种改进的不确定连续属性决策树的构建方法。
技术实现要素:
针对于解决不确定连续属性分类与预测的问题以及提高对其分类、预测的准确率问题、类的判定问题以及决策树中过度拟合问题,提出了一种改进的不确定连续属性决策树的构建方法。
为解决上述问题,本发明是通过以下技术方案实现的:
一种改进的不确定连续属性决策树的构建方法,包括如下步骤:
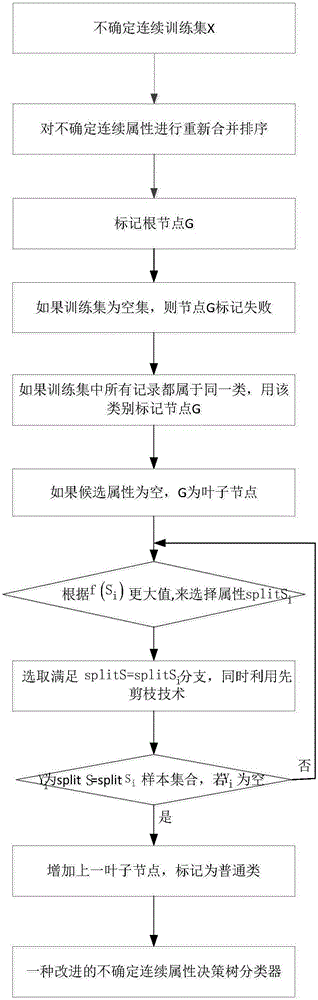
步骤1:设不确定连续属性训练集中有X个样本,属性个数为n,即n=(S1,S2,…Sn),同时分裂属性Si对应了m个类L,其中Lr∈(L1,L2…,Lm),i∈(1,2…,n),r∈(1,2…,m)。Si∈(S1,S2,…Sn),其中属性值具有连续不确定性。
步骤2:把不确定连续数据属性Si的属性值Sij合并排序,根据类对不确定性数据属性Si进行属性值Sij运算,记为概率和P(Sij),对类进行处理得每一分支属性值的概率势P(Sij,Lr)。
步骤3:创建根节点G。
步骤4:如果训练数据集为空,则返回节点G并标记失败。
步骤5:如果训练数据集中所有记录都属于同一类别,则该类型标记节点G。
步骤6:如果候选属性为空,则返回G为叶子结点,标记为训练数据集中最普通的类。
步骤7:由于连续属性值的不确定性,根据目标函数f(Si)从候选属性中选择splitSi。
步骤8:标记节点G为属性splitSi。
步骤9:由节点延伸出满足条件为splitS=splitSi分支以及splitSi=splitSij子分支,如果满足以下两条件之一,就停止建树,同时利用先剪支技术对决策树实施进一步优化操作。
9.1这里假设Yi为训练数据集中splitS=splitSi的样本集合,如果Yi为空,加上一个叶子结点,根据设定的算法将此叶子结点标记为训练数据集中最普通的类。
9.2此节点中所有例子属于同一类。
步骤10:非9.1与9.2中情况,则递归调用步骤7至步骤9。
步骤11:保存改进的连续不确定性属性的决策树分类器。
本发明的有益效果是:
1、构成的决策树更好的规避了信息偏置为数量级大的问题。
2、可以实现对象为不确定连续属性的归类和预测功能。
3、此构建的决策树相比较之前技术具有更高的分类精度。
4、此构建的决策树更适用于对实际数据挖掘问题的应用。
5、构建的决策树可以更好判定不确定属性多分支下的从属类。
6、构建的决策树更好的避免了过渡拟合问题。
附图说明
图1为一种改进的不确定连续属性决策树的构建流程图。
具体实施方式
为解决不确定连续属性分类与预测的问题以及提高对其分类、预测的准确率问题、类的判定问题以及决策树中过渡拟合问题,结合图1对本发明进行了详细说明,其具体实施步骤如下:
步骤1:设不确定连续属性训练集中有X个样本,属性个数为n,即n=(S1,S2,…Sn),同时分裂属性Si对应了m个类L,其中Lr∈(L1,L2…,Lm),i∈(1,2…,n),r∈(1,2…,m)。Si∈(S1,S2,…Sn),其中属性值具有不确定性。
步骤2:把不确定连续数据属性Si的属性值Sij合并排序,根据类对不确定连续数据属性Si进行属性值Sij运算,记为概率和P(Sij),对类进行处理得每一分支属性值的概率势P(Sij,Lr)。其具体运算过程如下:
不确定连续属性Si,其取值P(Sij)为一个概率向量,记为
P(Sij)∈(P(Si1),P(Si2),…,P(Sik)),且所以之前那些确定的连续属性可以看作为这一特殊情况,即属性Si中属性值P(Sij)=1,其他概率为0的情形。
不确定连续属性值在每个区间上都存在最大值和最小值端点。这种数值表示方式是出于保护客户隐私为目的。不确定连续属性的处理过程是将所有出现的关键点按升序排列,合并重复点,这样属性整个取值区间就被分割成多个子区间。每个用例的取值区间会覆盖一个或多个子区间。
假设任意一子集区间为[α,β],则其在区间[α,β]的概率分布为:
上式f(x)为此事件发生的概率分布,具体事件具体分析,这个由相应的专家确定,每个不确定连续属性的概率分布函数普遍相同。
属性Si在区间[α,β]的概率和P(Sij)为:
上式j∈(1,2,…,k),k为属性Si对应的属性值个数。
根据属性值Sij对应的类Lr在区间[α,β]的概率势P(Sij,Lr)为:
上式为属性值Sij对应的类的种类,为在属性值Sij对应的类中为Lr类。
P(Sij)为属性值Sij根据类来取概率和,类L总共为m个。
步骤3:创建根节点G。
步骤4:如果训练数据集为空,则返回节点G并标记失败。
步骤5:如果训练数据集中所有记录都属于同一类别,则该类型标记节点G。
步骤6:如果候选属性为空,则返回G为叶子结点,标记为训练数据集中最普通的类。
步骤7:由于连续属性值的不确定性,根据下面目标函数f(Si)从候选属性中选择splitSi。其具体计算过程如下:
目标函数f(Si):
上式Lr∈(L1,L2,…,Lc),c<m。P(Sij,Lr)为步骤2中属性Si的属性值Sij对应类为Lr的概率势,j为属性值个数。
当选择属性splitSi满足目标函数f(Si)越大时,则找到标记节G。
步骤8:标记节点G为属性splitSi。
步骤9:由节点延伸出满足条件为splitS=splitSi分支以及splitSi=splitSij子分支,如果满足以下两条件之一,就停止建树,同时利用先剪支技术对决策树实施进一步优化操作,其具体计算过程如下:
在建树过程中,顺序利用下列规则对树进行剪枝操作:
(1)
(2)P(Sij,Lr)<ε
上式为属性值Sij中类为L的个数,10%、ε为用户设定的一个阈值,只有满足用户需求,才能更好的提高决策树模型分类以及预测精度。
9.1这里假设Yi为训练数据集中splitS=splitSi的样本集合,如果Yi为空,加上一个叶子结点,根据设定的算法将此叶子结点标记为训练数据集中最普通的类,其具体实现算法如下:
对于不确定连续属性最终树中类的确定算法:
根据步骤2中得到的P(Sij,Lr),对splitSi=splitSij子分支按P(Sij,Lr)值从大到小进行从右到左排序,从右至左进行下列运算,
上式h为树的深度,h<k,c<k。
9.2此节点中所有例子属于同一类,其具体实现过程如下:
分支叶子节点的确定先对比训练集再由P(Sij,Lr)值大小确定,即
通过上式就可以确定叶子节点。
步骤10:非9.1与9.2中情况,则递归调用步骤7至步骤9。
步骤11:保存改进的连续不确定性属性的决策树分类器。
一种改进的不确定连续属性决策树的构建方法,其伪代码计算过程如下:
输入:不确定连续数据训练样本集X。
输出:一种改进的不确定连续属性决策树分类器。
- 还没有人留言评论。精彩留言会获得点赞!