一种基于属性约简的关联规则挖掘方法及装置与流程
本发明涉及数据挖掘技术,具体涉及一种属性约简的关联规则挖掘方法及装置。
背景技术:
KDD一词首次出现在1989年8月举行的第11届国际联合人工智能学术会议。迄今为止,由美国人工智能协会主办的KDD国际研讨会已经召开了13次,规模由原来的专题讨论会发展到国际学术大会,人数由二三十人到超过千人,论文收录数量也迅速增加,研究重点也从发现方法逐渐转向系统应用直到转向大规模综合系统的开发,并且注重多种发现策略和技术的集成,以及多种学科之间的相互渗透。其它内容的专题会议也把数据挖掘和知识发现列为议题之一,成为当前计算机科学界的一大热点。
数据挖掘能够从数据库的大量数据中挖掘出隐含的、先前未知的并有潜在价值的信息,关联规则是数据挖掘算法中的一种,能够发现数据库不同数据之间的隐含关系及关联网,实时高效的关联规则更新对于趋势分析、辅助决策、信息推荐等具有重要的研究意义。
由于数据的急速增长,可利用的数据规模增大,使得对大规模数据挖掘的应用需求日益增强。由于数据挖掘任务和数据挖掘方法的多样性,给数据挖掘提出了许多挑战性的课题。理论研究内容从最初的频繁模式挖掘扩展到闭合模式挖掘、最大模式挖掘,增量挖掘、主题兴趣度度量、隐私保护、数据流等多种类型数据上的关联规则挖掘。关联规则挖掘将向着数据挖掘语言的设计、数据挖掘的可视化、web数据挖掘、高效而有效的数据挖掘方法和系统的开发、交互和集成的数据挖掘环境的建立以及应用数据挖掘技术等大型应用领域。
技术实现要素:
本发明提供了一种基于属性约简的关联规则挖掘方法及装置,采用改进的HEclat算法进行数据关联规则的挖掘,能够提高数据挖掘的效率。
本发明解决上述技术问题的技术方案如下:
本发明提供了一种基于属性约简的关联规则挖掘方法,包括以下步骤:
S1,根据研究对象从数据库中采集对应的数据;
S2,对所述数据进行集成规约;
S3,对集成规约后的数据采用粗糙集理论进行属性约简;
S4,采用改进后的HEclat算法对属性约简后的数据进行关联规则挖掘;
S5,对挖掘出的关联规则进行解读和展示。
在上述技术方案的基础上,本发明还可以作如下改进。
进一步的,所述步骤S3之前还包括:
数据预处理步骤:对集成规约后的数据中存在缺省值的数据记录进行清理或者填充,使得整个数据保持完整性和一致性。
进一步的,所述步骤S3具体包括:
S31,根据处理后的数据建立多个决策表;
S32,根据公式(1)计算每一个决策表中决策属性集的信息熵,以及根据公式(2)计算每一个决策表中决策属性集相对条件属性集的信息熵;
公式(1)为:
式(1)中,D表示决策表中的决策属性集,H(D)表示决策属性集的信息熵,U为决策表的样本对象,Y={Y1,Y2,...,Ym}是决策表的样本对象U中根据决策属性集D分成的等价类的集合;p(Yj)为Yi在样本集上出现的概率;
公式(2)为:
式(2)中,C表示决策表中的条件属性集,H(D|C)表示决策属性集D相对条件属性集C的信息熵,U为决策表的样本对象,X={X1,X2,...,Xn}是决策表的样本对象U中根据条件属性集C分成的等价类的集合,Y={Y1,Y2,...,Ym}是决策表的样本对象U中根据决策属性集D分成的等价类的集合,∩表示同时包含Yj和Xi;p(Xi)为Xi在样本集上出现的概率;p(Yj|Xi)为Xi出现时,Yi会同时出现的概率;
S33,根据公式(3)计算每一个决策表中条件属性集对决策属性集的互信息量;
公式(3)为:
I(C,D)=H(D)-H(D|C);
式(3)中,I(C,D)代表条件属性集C对决策属性集D的互信息量,H(D)代表决策属性集D的信息熵,H(D|C)代表决策属性集D相对条件属性集C的信息熵;
S34,计算每一个决策表中条件属性集相对决策属性集的核属性集,并记录保存非核条件属性得到非核条件属性集;
S35,针对非核条件属性集中的任意元素,计算对决策属性集的互信息量,找出使得互信息量最大的非核条件属性作为重要属性,得到重要属性集;
S36,计算所述重要属性集对决策属性集的互信息量,如果所述重要属性集对决策属性集的互信息量的值与条件属性集对决策属性集的互信息量的值相等,则将核属性集作为约简后的决策表,并跳转执行步骤S4;否则继续执行步骤S35。
进一步的,所述步骤S4具体包括:
S41,用垂直结构表示事务数据库;
S42,设定最小支持度minSup,扫描一次事务数据库,并初始化候选1项集C1,将支持度小于minSup的候选1项集去掉,得到频繁1项集L1;
S43,由频繁1项集进行连接步产生候选2项集C2,所有的候选2项集的后缀项相同,然后通过候选2项集C2中各频繁1项子集之间取交集得到事务记录的值与最小支持度minSup比较,滤除小于minSup的候选项集,得到频繁2项集L2;
S44,不断重复步骤S43,直到所得的候选m项集为空或者候选项集所对应的各项频繁1项子集之间取交集得到的值小于minSup,m为大于等于1的正整数,得到频繁k项集Lk;
S45,设定最小置信度minCon,计算各频繁项集的置信度,置信度高于minCon的各频繁项集输出为强关联规则,并将该关联规则存入关联规则数据库;
其中,A=>B中,支持度是指A、B事件同时发生的概率,置信度是指在A事件发生的条件下,B事件发生的概率。
进一步的,所述步骤S5包括:
将挖掘出的关联规则采用可视化界面进行展示。
为了解决本发明的技术问题,还提供了一种基于属性约简的关联规则挖掘装置,包括:
数据采集模块,用于根据研究对象从数据库中采集对应的数据;
集成规约模块,用于对所述数据进行集成规约;
属性约简模块,用于对集成规约后的数据采用粗糙集理论进行属性约简;
关联规则挖掘模块,用于采用改进后的HEclat算法对属性约简后的数据进行关联规则挖掘;
展示模块,用于对挖掘出的关联规则进行解读和展示。
在上述技术方案的基础上,本发明还可以作如下改进。
进一步的,还包括:
预处理模块,用于对集成规约后的数据中存在缺省值的数据记录进行清理或者填充,使得整个数据保持完整性和一致性。
进一步的,所述展示模块具体用于:
将挖掘出的关联规则采用可视化界面进行展示。
本发明的有益效果为:在数据处理的过程中采用粗糙集理论进行属性约简,避免使用大量的不必要属性进行交集运算而增加数据量的计算;在数据挖掘的过程中采用改进的HEclat算法进行关联规则的数据挖掘,只需要扫描一次数据库,减少冗余计算,有效地减少了数据挖掘的时间,降低了系统资源消耗,进而提高了数据挖掘的效率。
附图说明
图1为本发明实施例1的一种基于属性约简的关联规则挖掘方法流程图;
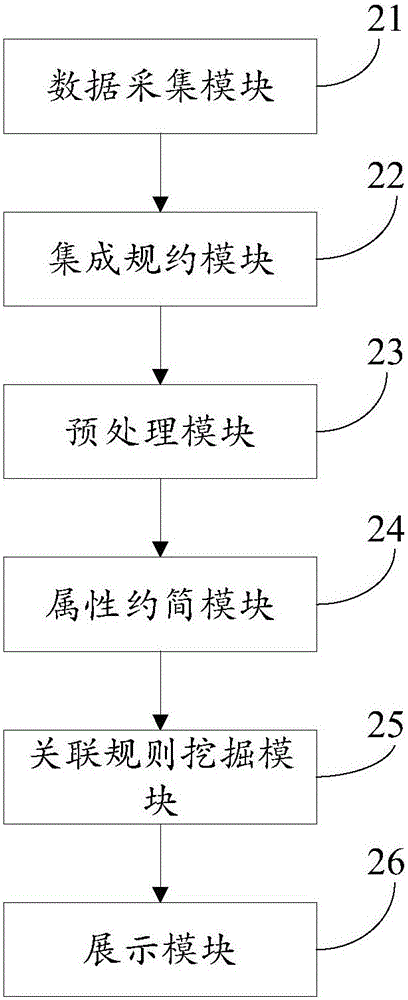
图2为本发明实施例2的一种基于属性约简的关联规则挖掘装置示意图。
具体实施方式
以下结合附图对本发明的原理和特征进行描述,所举实例只用于解释本发明,并非用于限定本发明的范围。
实施例1、一种基于属性约简的关联规则挖掘方法。
参见图1,本实施例提供的关联规则挖掘方法包括:
S1,根据研究对象从数据库中采集对应的数据;
S2,对所述数据进行集成规约;
S3,对集成规约后的数据采用粗糙集理论进行属性约简;
S4,采用改进后的HEclat算法对属性约简后的数据进行关联规则挖掘;
S5,对挖掘出的关联规则进行解读和展示。
下面进行具体的说明,步骤S1中首先明确研究对象并分析,从数据库中采集与研究对象对应的数据,这些数据可能来自不同的来源,这时需要将不同来源的数据在物理或者逻辑上进行集中,以便于数据共享,即称为数据的集成;并在不影响数据挖掘结果的情况下,尽可能的对数据进行压缩,减小数据的大小,即对数据进行规约。随后,对集成规约后的数据进行预处理,这些数据的数据记录中的某些项可能存在缺省值,会造成数据的不完整和不一致,因此,将这些存在缺省值的数据记录直接删除清理或者将这些缺省项填充,确保整个数据的完整性和一致性。
步骤S3对预处理后的数据采用粗糙集理论进行属性约简,采用基于粗糙集理论的属性约简方法将对数据挖掘无关的属性删除,避免产生大量无效的候选项集,减少系统的资源消耗。
所述步骤S3对集成规约后的数据采用粗糙集理论进行属性约简具体包括:
S31,根据处理后的数据建立多个决策表;
S32,根据公式(1)计算每一个决策表中决策属性集的信息熵,以及根据公式(2)计算每一个决策表中决策属性集相对条件属性集的信息熵;
公式(1)为:
式(1)中,D表示决策表中的决策属性集,H(D)表示决策属性集的信息熵,U为决策表的样本对象,Y={Y1,Y2,...,Ym}是决策表的样本对象U中根据决策属性集D分成的等价类的集合;p(Yj)为Yi在样本集上出现的概率;
公式(2)为:
式(2)中,C表示决策表中的条件属性集,H(D|C)表示决策属性集D相对条件属性集C的信息熵,U为决策表的样本对象,X={X1,X2,...,Xn}是决策表的样本对象U中根据条件属性集C分成的等价类的集合,Y={Y1,Y2,...,Ym}是决策表的样本对象U中根据决策属性集D分成的等价类的集合,∩表示同时包含Yj和Xi;p(Xi)为Xi在样本集上出现的概率;p(Yj|Xi)为Xi出现时,Yi会同时出现的概率;
S33,根据公式(3)计算每一个决策表中条件属性集对决策属性集的互信息量;
公式(3)为:
I(C,D)=H(D)-H(D|C);
式(3)中,I(C,D)代表条件属性集C对决策属性集D的互信息量,H(D)代表决策属性集D的信息熵,H(D|C)代表决策属性集D相对条件属性集C的信息熵;
S34,计算每一个决策表中条件属性集相对决策属性集的核属性集,并记录保存非核条件属性得到非核条件属性集;
S35,针对非核条件属性集中的任意元素,计算对决策属性集的互信息量,找出使得互信息量最大的非核条件属性作为重要属性,得到重要属性集;
S36,计算所述重要属性集对决策属性集的互信息量,如果所述重要属性集对决策属性集的互信息量的值与条件属性集对决策属性集的互信息量的值相等,则将核属性集作为约简后的决策表,并跳转执行步骤S4;否则继续执行步骤S35。
本实施例采用粗糙集理论对数据进行属性约简,将对数据挖掘无关的属性删除,避免后续产生大量无效的候选项集,减少系统的资源消耗。
将属性约简后的数据转换为数据挖掘的形式,通常转化为二进制数据,然后采用改进的HEclat算法对形式转换后的数据进行关联规则挖掘,上述步骤S4中关联规则挖掘具体为:
S41,用垂直结构表示事务数据库;
S42,设定最小支持度minSup,扫描一次事务数据库,并初始化候选1项集C1,将支持度小于minSup的候选1项集去掉,得到频繁1项集L1;
S43,由频繁1项集进行连接步产生候选2项集C2,所有的候选2项集的后缀项相同,然后通过候选2项集C2中各频繁1项子集之间取交集得到事务记录的值与最小支持度minSup比较,滤除小于minSup的候选项集,得到频繁2项集L2;
S44,不断重复步骤S43,直到所得的候选m项集为空或者候选项集所对应的各项频繁1项子集之间取交集得到的值小于minSup,m为大于等于1的正整数,得到频繁k项集Lk;
S45,设定最小置信度minCon,计算各频繁项集的置信度,置信度高于minCon的各频繁项集输出为强关联规则,并将该关联规则存入关联规则数据库;
其中,A=>B中,支持度是指A、B事件同时发生的概率,置信度是指在A事件发生的条件下,B事件发生的概率。
下面具体介绍一下利用改进后的HEclat算法来进行数据挖掘的过程,HEclat算法的垂直结构表如下表1:
表1
先设置最小支持度minSup=0.6
1、由数据表可以看出,频繁1项集L1为L1={{I1},{I2},{I3},{I5},{I6}}。
令C1={I1},
2、由L1通过运算可以得到C2={I1,I2},由P(C2)=0.4<minSup可知,{I1,I2}不是频繁项集,由剪枝定理可知,所有{I1,I2}的超集都是非频繁项集,例如{I1,I2,I3}这个超集就是非频繁项集;
3、由数据表得到C3={{I1,I3},{I2,I3},{I1,I2,I3}},其中候选项集合中的每一项集的最后一项不变,即最后一项均为I3,称为集合后缀不变,由剪枝定理可知{I1,I2,I3}是非频繁项集,因此可以滤掉,通过计算只P({I1,I3})=0.8>minSup;P({I2,I3})=0.6>=minSup,则L3={{I1,I3},{I2,I3}};
4、由数据表可得C4={{I1,I5},{I2,I5},{I3,I5},{I1,I2,I5},{I1,I3,I5},{I2,I3,I5},{I1,I2,I3,I5}},由剪枝原理可知,{I1,I2,I5},{I1,I2,I3,I5}是非频繁项集,可以直接滤掉,计算方法同上,由此可知L4={{I1,I5},{I2,I5},{I3,I5},{I1,I3,I5},{I2,I3,I5}}。
5、由数据表可得C5={{I1,I6},{I2,I6},{I3,I6},{I5,I6},{I1,I2,I6},
{I1,I3,I6},{I1,I5,I6},{I2,I3,I6},{I2,I5,I6},{I3,I5,I6},{I1,I2,I3,I6},{I1,I2,I5,I6},{I1,I3,I5,I6},{I2,I3,I5,I6},{I1,I2,I3,I5,I6}},由剪枝原理可知{I1,I2,I6},{I1,I2,I3,I6},{I1,I2,I5,I6},{I1,I2,I3,I5,I6}均为非频繁项集,通过计算得L5={{I1,I6},{I3,I6},{I1,I3,I6}}。
由以上改进后的HEclat算法得到频繁项集,然后设定最小置信度minCon,计算各频繁项集的置信度,高于minCon的各频繁项集输出为强关联规则。本实施例采用改进后的HEclat算法对数据关联规则进行挖掘,通过垂直结构一次性扫描数据库,很好的改善了Eclat算法消耗时间长、占用内存大的问题,改进的HEclat算法(集合后缀)主要是通过改变传统的Eclat算法的搜索方式(集合前缀)来进行频繁模式挖掘,提高数据挖掘的效率。通过改进后的HEclat算法挖掘出关联规则,最后将挖掘出的关联规则以可视化的界面展示。
实施例2、一种基于属性约简的关联规则挖掘装置。
参见图2,本实施例提供的装置包括数据采集模块21、集成规约模块22、预处理模块23、属性约简模块24、关联规则挖掘模块25和展示模块26。
其中,数据采集模块21,用于根据研究对象从数据库中采集对应的数据。
集成规约模块22,用于对所述数据进行集成规约。
预处理模块23,用于对集成规约后的数据中存在缺省值的数据记录进行清理或者填充,使得整个数据保持完整性和一致性。
属性约简模块24,用于对完整性和一致性处理后的数据采用粗糙集理论进行属性约简,并将属性约简后的数据的形式进行转换。
关联规则挖掘模块25,用于采用改进后的HEclat算法对形式转换后的数据进行关联规则挖掘。
展示模块26,用于对挖掘出的关联规则进行解读和展示。
其中,属性约简模块24采用粗糙集理论对数据进行属性约简的具体过程为:
S31,根据处理后的数据建立多个决策表;
S32,根据公式(1)计算每一个决策表中决策属性集的信息熵,以及根据公式(2)计算每一个决策表中决策属性集相对条件属性集的信息熵;
公式(1)为:
式(1)中,D表示决策表中的决策属性集,H(D)表示决策属性集的信息熵,U为决策表的样本对象,Y={Y1,Y2,...,Ym}是决策表的样本对象U中根据决策属性集D分成的等价类的集合;p(Yj)为Yi在样本集上出现的概率;
公式(2)为:
式(2)中,C表示决策表中的条件属性集,H(D|C)表示决策属性集D相对条件属性集C的信息熵,U为决策表的样本对象,X={X1,X2,...,Xn}是决策表的样本对象U中根据条件属性集C分成的等价类的集合,Y={Y1,Y2,...,Ym}是决策表的样本对象U中根据决策属性集D分成的等价类的集合,∩表示同时包含Yj和Xi;p(Xi)为Xi在样本集上出现的概率;p(Yj|Xi)为Xi出现时,Yi会同时出现的概率;
S33,根据公式(3)计算每一个决策表中条件属性集对决策属性集的互信息量;
公式(3)为:
I(C,D)=H(D)-H(D|C);
式(3)中,I(C,D)代表条件属性集C对决策属性集D的互信息量,H(D)代表决策属性集D的信息熵,H(D|C)代表决策属性集D相对条件属性集C的信息熵;
S34,计算每一个决策表中条件属性集相对决策属性集的核属性集,并记录保存非核条件属性得到非核条件属性集;
S35,针对非核条件属性集中的任意元素,计算对决策属性集的互信息量,找出使得互信息量最大的非核条件属性作为重要属性,得到重要属性集;
S36,计算所述重要属性集对决策属性集的互信息量,如果所述重要属性集对决策属性集的互信息量的值与条件属性集对决策属性集的互信息量的值相等,则将核属性集作为约简后的决策表,并跳转执行步骤S4;否则继续执行步骤S35。
关联规则挖掘模块24采用改进后的HEclat算法对数据进行关联规则挖掘的具体过程为:
S41,用垂直表示法来表示事务数据库;
S42,设定最小支持度minSup,扫描一次事务数据库,并初始化候选1项集C1,将支持度小于minSup的候选1项集去掉,得到频繁1项集L1;
S43,由频繁1项集进行连接步产生候选2项集C2,所有的候选2项集的后缀项相同,然后通过候选2项集C2中各频繁1项子集之间取交集得到事务记录的值与最小支持度minSup比较,滤除小于minSup的候选项集,得到频繁2项集L2;
S44,不断重复步骤S43,直到所得的候选m项集为空或者候选项集所对应的各项频繁1项子集之间取交集得到的值小于minSup,m为大于等于1的正整数,得到频繁k项集Lk;
S45,设定最小置信度minCon,计算各频繁项集的置信度,置信度高于minCon的各频繁项集输出为强关联,并将强关联规则存入关联规则数据库;
其中,A=>B中,支持度是指A、B事件同时发生的概率,置信度是指在A事件发生的条件下,B事件发生的概率。
本发明提供的一种基于属性约简的关联规则挖掘方法和装置,在数据处理的过程中采用粗糙集理论进行属性约简,避免使用大量的不必要属性进行交集运算而增加数据量的计算;在数据挖掘的过程中采用改进的HEclat算法进行关联规则的数据挖掘,只需要扫描一次数据库,减少冗余计算,有效地减少了数据挖掘的时间,降低了系统资源消耗,进而提高了数据挖掘的效率。
在本说明书的描述中,参考术语“实施例一”、“示例”、“具体示例”、或“一些示例”等的描述意指结合该实施例或示例描述的具体方法、装置或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必须针对的是相同的实施例或示例。而且,描述的具体特征、方法、装置或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!