一种软件算法模拟同步总线产生时钟信号的方法与流程
本发明涉及一种软件算法模拟同步总线产生时钟信号的方法。
背景技术:
在电子产品中,有大量需要主处理器将处理好的数据发给外设的操作。在进行信息传递时,采用的数据总线方式有两种:同步总线方式与异步总线方式。同步总线方式需要CLK时钟信号来同步传输,例如SDIO接口有1根CLK线,4根数据线;LCM接口有1根CLK线。一般这些CLK线都是通过物理芯片控制并产生的。通过硬件的物理接口,数据从处理器传送给外部设备,从而实现外部设备的驱动。
随着电子产品的不断发展,产品功能的不断增加,现有的硬件平台的接口往往是不够的。例如,有手机需要支持2个屏幕,就需要2个显示模块;有的相机需要2个存储卡,就需要2个SDIO模块;为了解决上述硬件平台接口不够用的问题,现有的做法是重新设计芯片或者更换硬件平台,这将导致成本大幅增加。
技术实现要素:
本发明所要解决的技术问题是,克服上述背景技术的不足,提供一种可有效节约成本的软件算法模拟同步总线产生时钟信号的方法。
本发明解决其技术问题采用的技术方案是,一种软件算法模拟同步总线产生时钟信号的方法,包括以下步骤:
(1)初始化算法的变量值,重置算法存储数组buff的初始值;
(2)获取需要传输的原始数据的长度Dlen以及原始数据的起始地址Data[];
(3)根据原始数据的长度Dlen,启动循环操作,根据循环步进次数i和原始数据的起始地址Data[],获取原始数据中的第i个数据Data[i];将10000000B左移8位,将左移8位后的结果与Data[i]进行逻辑或操作,生成一个新的16位长的数据Data1;将00000000B左移8位,将左移8位后的结果与Data[i]进行逻辑或操作,再次生成一个新的16位长的数据Data2;
(4)将Data1左移16位,将左移16后的结果与Data2进行逻辑或操作,生成一个新的32位长的数据,然后存储到算法存储数组buff中;
(5)利用循环操作,依次对原始数据中的每个数据进行步骤(3)、(4)的操作;直至循环结束;
(6)启动系统的DMA传输功能,将算法存储数组buff中存储的数据传输出去,即得到所需的时钟信号。
进一步, 步骤(6)中,先将算法存储数组buff中存储的数据写入LCM接口或者并行接口的写地址中,再传输给外部设备。
与现有技术相比,本发明的优点如下:通过算法将数据进行加工改造,控制数据流规律输出0,1,0,1,0,1,0,1的序列,模拟输出时钟信号,输出的时钟信号可模拟同步总线驱动外部器件,极大程度上拓展硬件功能接口,能够外接基于同步总线的外部设备,成本较低。
附图说明
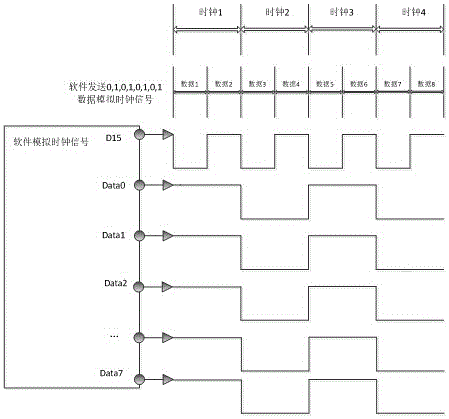
图1是本发明实施例的输出时钟信号波形示意图。
图2是本发明实施例的方法流程图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步详细描述。
本实施例包括以下步骤:
(1)建立好硬件环境,软件环境,初始化算法的变量值,变量包括i、Dlen、Data1和Data2,重置算法存储数组buff的初始值;
(2)获取需要传输的原始数据的长度Dlen以及原始数据的起始地址Data[];
(3)根据原始数据的长度Dlen,启动循环操作,根据循环步进次数i和原始数据的起始地址Data[],获取原始数据中的第i个数据Data[i];将10000000B左移8位,将左移8位后的结果与Data[i]进行逻辑或操作,生成一个新的16位长的数据Data1;将00000000B左移8位,将左移8位后的结果与Data[i]进行逻辑或操作,再次生成一个新的16位长的数据Data2;
(4)将Data1左移16位,将左移16后的结果与Data2进行逻辑或操作,生成一个新的32位长的数据,然后存储到算法存储数组buff中;
步骤(4)的目的在于将两个16位长数据(Data1和Data2)拼接为一个32位长的数据,以利用 32位DMA(Direct Memory Access,直接内存存取)总线的带宽。
(5)利用循环操作,依次对原始数据中的每个数据进行步骤(3)、(4)的操作;直至循环结束;
(6)启动系统的DMA传输功能,将算法存储数组buff中存储的数据传输出去,即得到所需的时钟信号,时钟信号如图1所示;传输起始地址为算法存储数组buff的起始地址,目的地址为LCM (LCD Module,液晶模块)接口的写地址,或者其他的并行接口(如:SDIO接口)的写地址,LCM接口或并行接口的一个信号线连接到外部设备的CLK端,这个信号线上将产生连续0,1高低电平规律变化的数据,
写地址收到数据后,会立即通过信号线发送给外部设备,外部设备即接收到时钟信号。
本实施通过一个16位的并行接口输出数据,其中Data0~Data7为传输数据端口,D15为模拟时钟信号端口。通过本发明方法模拟,传输的时钟信号与物理芯片产线的信号一致。
DMA是目前芯片中较为常见的功能,主要特点就是不通过CPU而直接与系统内存交换数据的接口技术;为满足某些外部设备特殊的时序要求,特别是指定频率的要求,本发明使用DMA来传输数据,调节DMA的参数,控制数据流的读写速度,实现外部设备的频率要求。
相对于硬件同步总线来说,一个完整时钟信号需要2个信号来模拟完成(一个数据0,一个数据1组合)。因此要在总线上传输的次数及数据量也相应的翻倍。
DMA传输的数据需要处理器在数据缓冲区内先进行填写,目前主流的处理器都是32位总线,我们在算法上根据同一时钟内两次16位数据的相关性,能够一次生成32位的数据。这样可以用32位总线的方法来存储DMA的缓冲区数据,这样一次处理可以存储2个模拟总线的数据,这个处理能抵消算法产生的2次16位数据存储操作,降低双倍数据量增加导致的耗时后果,而DMA输出仍然为16位总线,从而达到与硬件同步总线同样的效率。
参照图2,本实施例的具体流程如下:
S1:初始化算法变量值;重置算法存储数组buff的初始值;
S2:获取需要传输的原始数据的长度Dlen;获取原始数据的起始地址Data[];
S3:判定传输参数是否合法,若是,转到步骤S4;若否,结束算法运行;
S4:设置步进变量i,开始for循环依次取待传输数据;
S5:判定待传输数据是否全部处理完,若是,转到步骤S9;若否,转到步骤S6;
S6:将取出的数据进行以下逻辑运算操作:0x80<<8|data[i];0x00<<8|data[i];0x80<<8|data[i];0x00<<8|data[i]的含义为:将10000000B左移8位,将左移8位后的结果与Data[i]进行逻辑或操作,生成一个新的16位长的数据Data1;将00000000B左移8位,将左移8位后的结果与Data[i]进行逻辑或操作,再次生成一个新的16位长的数据Data2;
S7:将步骤S6中的Data1和Data2再次逻辑运算拼接成32位数据:buff[i]=(0x80<<8|data[i])<<16|(0x00<<8|data[i]);
buff[i]=(0x80<<8|data[i])<<16|(0x00<<8|data[i])的含义为:将Data1左移16位,将左移16后的结果与Data2进行逻辑或操作,生成一个新的32位长的数据,然后存储到算法存储数组buff中;
S8:步进变量加1;返回步骤S5;
S9:配置DAM传输参数,启动DAM将buff中生成的数据写入LCM接口或者其他并行接口的写地址中;
S10:外部设备接收写地址中的数据。
本发明通过算法将数据进行加工改造,控制数据流规律输出0,1,0,1,0,1,0,1的序列,模拟输出时钟信号,输出的时钟信号可模拟同步总线驱动外部器件,极大程度上拓展硬件功能接口,能够外接基于同步总线的外部设备,成本较低。
本领域的技术人员可以对本发明进行各种修改和变型,倘若这些修改和变型在本发明权利要求及其等同技术的范围之内,则这些修改和变型也在本发明的保护范围之内。
说明书中未详细描述的内容为本领域技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!