一种基于Spark与优化MBBO算法的并行虚拟机聚合方法与流程
本发明涉及计算机科学与技术中的虚拟机聚合领域,具体为一种基于Spark与优化MBBO算法的并行虚拟机聚合方法。
背景技术:
虚拟机VM(Virtual Machine)作为统一管理数据中心的硬件资源达到了空前的使用规模,与此带来两大难题,高能耗及负载不均衡。当前解决以上两种问题主要采用虚拟机聚合VMC(Virtual Machine Consolidation)技术,通过重排主机HM(Host Machine)上VM的放置位置,优化数据中心的能耗、负载均衡、网络带宽等多种方面。
VMC通过在拓扑复杂的海量HM和VM中,建立数学模型并提出有效的聚合方案,将VM从源主机动态迁移到目标主机来实现。VMC是一种NP(Non-deterministic Polynomial)问题,难以在多项式时间内取得最优解,目前研究方向包括单目标聚合和多目标聚合。单目标的虚拟机聚合研究侧重在单个目标维度内对数据中心进行优化获取最优解,然而,单目标聚合过分简化了复杂性,使得单目标最优解往往牺牲其他目标为代价,造成数据中心综合性能的下降。多目标虚拟机聚合研究同时考虑多个目标,寻找多目标间的平衡点,提升多个方面的性能指标,当前主要有启发式装箱算法、动态规划算法和仿生学算法三种类型的聚合算法。启发式装箱算法、动态规划算法部署简单,求解速度快,但是只能考虑少数维度的计算资源,不足以解决复杂的虚拟机聚合问题。遗传算法和蚁群算法等仿生学算法能够处理多种资源的限制,但是搜索速度慢,并且存在配置参数复杂,参数对搜索结果影响很大的缺点。
技术实现要素:
针对现有技术中存在的问题,本发明提供一种基于Spark与优化MBBO算法的并行虚拟机聚合方法,通过拓展的Spark并行框架及多目标生物地理学优化MBBO算法,从而能够在比较短的收敛时间内求解VMC问题的最佳迁移方案,为后续的虚拟机并行迁移奠定基础。
本发明是通过以下技术方案来实现:
一种基于Spark与优化MBBO算法的并行虚拟机聚合方法,
步骤1,将虚拟机聚合问题映射到生物地理学优化算法中,确定约束条件,明确求解目标;
步骤2,基于拓展的Spark并行框架,分发满足约束条件的初始栖息地群到各Spark计算节点并迭代执行MBBO并行算法,直到满足终止条件,停止算法执行并获取能够平衡多个优化求解目标的最优解。
优选的,所述的步骤1中进行映射时,每一个栖息地代表符合约束条件的VM与HM的一种位置排列,栖息地由一个长度为VM数量的行向量表示,向量中第i个元素代表第i个VM聚合后对应的HM编号;VM对应的HM编号被映射为该栖息地的适宜性指数变量SIV,由该栖息地内所有SIV共同决定栖息地适宜性指数HSI,即该候选解对VMC该优化目标的匹配程度;众多的栖息地组成一个群岛,表示满足该VMC优化目标的候选解集合;高HSI栖息地的迁出率高,迁入率低;低HSI栖息地迁入率高,迁出率低。
优选的,所述的步骤2,具体包括如下步骤,
步骤2.1,通过添加二级Reduce方法拓展Spark并行框架,使其具有Map-1stReduce-2nd Reduce 3个执行阶段,并采用主从式-细粒度的两层并行化模型;并行框架的上层采用主从式的并行模式,由Master节点将初始栖息地群划分为若干个群岛,分配到不同的Worker节点并行执行;Master节点负责任务分派,结果回收、子问题的切分以及监督算法的执行状态;
步骤2.2,并行框架的下层采用细粒度的并行模式实现各群岛的并行执行过程;各Worker节点采用Map方法接收对应的群岛,并进行群岛内SIV迁移和突变的迭代过程;采用1st Reduce方法获取同一Worker节点上Map方法产生的中间结果,进行子代栖息地群和父代精英解的HSI计算并从高到地排序,替换更新该Worker节点保存的父代精英解并作为下一次迭代过程的初始栖息地群;
步骤2.3,经过设定的迭代间隔,采用2nd Reduce方法获取所有Worker节点1stReduce产生的最新精英解并相互交换,交付给Master节点;
步骤2.4,由Master节点收集各Worker节点的精英解,判断终止条件,若不满足终止条件,则将收集的精英解重新分发到各Worker节点,作为新栖息地群参加下一次迭代过程。
进一步,各Worker节点采用Map方法接收对应的群岛,并进行群岛内SIV迁移和突变的迭代过程时;运行于各Worker节点上的Map方法接收以键值对表示的群岛作为初始输入数据,经过群岛内SIV迁移、变异迭代过程,输出以Worker编号为变量名保存所有子代候选解的新列表。
与现有技术相比,本发明具有以下有益的技术效果:
本发明一种基于Spark与优化MBBO算法的并行虚拟机聚合方法,利用拓展的Spark并行框架的同时,将生物地理学概念映射到优化问题中。其中,每一个栖息地就是解决问题的一个解,由栖息地中的所有适宜性指数变量SIV(Suitability Index Variable)决定栖息地的适宜度HSI(Habitat Suitability Index),HSI代表该候选解对问题的匹配程度。众多的栖息地组成一个群岛(Archipelago),表示虚拟机聚合问题的候选解。每个群岛代表一种优化目标,由所有群岛组成多目标优化的解空间。MBBO算法通过模拟物种在栖息地内,栖息地间,群岛内和群岛间的产生、灭绝和迁徙的过程,以迭代进化的方式寻找能够平衡多个优化目标的适应度最高的栖息地,该栖息地就是VMC的最优解。其中,Apache Spark是基于MapReduce的分布式计算原理,采用内寸存储及运算的技术,将栖息地群的大规模操作分发给集群上的多个Worker节点并行执行,周期性更新各节点状态,实现海量数据的高并发处理,非常适合迭代计算较多的任务。通过设计拓展了Spark平台的并行框架,以Map-1st Reduce-2nd Reduce 3个执行阶段,使其能够适合并行MBBO算法并高效求解,缩短计算时间,提高机器执行效率,出色完成虚拟机整合任务。
与传统串行的MBBO算法相比较,并行MBBO算法求解时阻塞于局部最优解的概率更小,因此更加通用。同时增添2nd Reduce阶段,拓展原有Spark并行框架使其能够更好的发挥并行MBBO算法的求解性能。由于采用并行计算,因此能够非常有效缩减求解时间,既保证服务水平协议SLA,也为实际问题的解决提供及时有效的方案。
附图说明
图1为本发明实例中所述的VMC问题到MBBO算法的映射。
图2为本发明实例中所述的MBBO算法串行执行过程。
图3为本发明实例中所述的MBBO算法的两层并行模式。
图4为本发明实例中所述的拓展的Spark并行框架。
图5为本发明实例中所述的MBBO算法的并行执行过程。
具体实施方式
下面结合具体的实施例对本发明做进一步的详细说明,所述是对本发明的解释而不是限定。
本发明一种基于Spark与优化MBBO算法的并行虚拟机聚合方法,其涉及到的MBBO算法的基本执行流程和对MBBO算法隐含并行性的分析分别如下。
第一部分,MBBO算法的基本执行流程。
MBBO算法采用仿生学算法通用的迭代进化的方式对复杂问题的最优解逐渐逼近,以不断迭代更新初始种群的方式寻找虚拟机聚合问题的有效解。在初始化的栖息地种群基础上,每一次迭代都以上一次迭代的计算结果为基础,经过约束条件的限制和挑选,不断地对生物种群进行优化,寻找最好的解决方案。
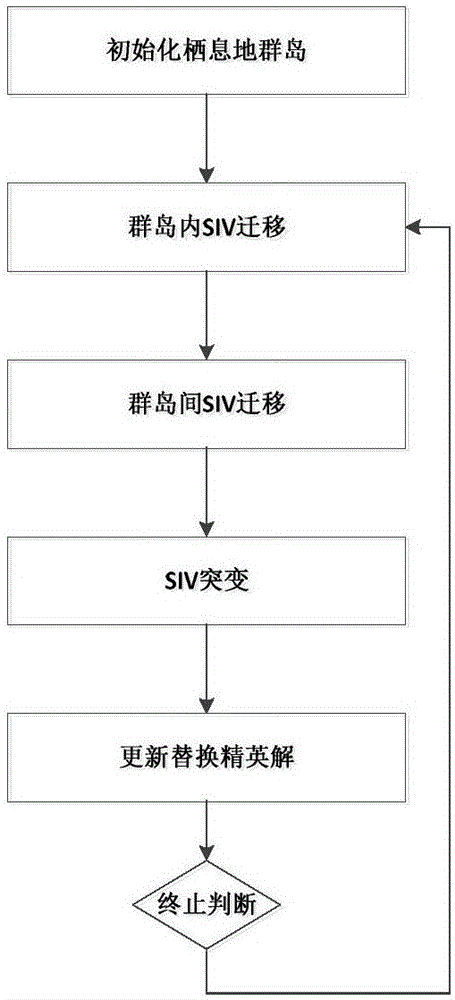
如图2所示,MBBO算法采用串行的迭代进化的方式对复杂问题的最优解逐渐逼近,以不断迭代更新初始种群的方式寻找虚拟机聚合问题的有效解。算法在具体执行迭代操作时包含如下的六个步骤:初始化栖息地群岛,群岛内SIV迁移,群岛间SIV迁移,SIV突变,更新替换精英解,终止判断。
(1)初始化栖息地群岛。
首先,确定优化目标及约束条件,初始化首批规模较大的群岛。群岛内栖息地规模为N,即一次迭代所处理的候选解数量。初始化所有栖息地,构造长度为所有VM数量的行向量,依据所有约束条件,初始生成栖息地内每个VM所能对应的HM,即初始化SIV,其中第i个元素代表第i个VM聚合后对应的HM编号。
(2)群岛内SIV迁移。
MBBO算法中不同栖息地间SIV的迁入、迁出实现了优秀特性的共享,促进MBBO算法在聚合问题解空间的嗅探和查找。
在群岛内,对每个栖息地进行约束条件匹配和优化目标代价函数计算,并以此进行排名,排名越靠前说明越优秀。排名靠后的栖息地被选中作为SIV迁入栖息地的概率更大,同理,排名靠前的被选中作为SIV迁出栖息地的概率也更大。
被选中的SIV迁入、迁出栖息地一一对应,每个迁入栖息地的SIV都有一定概率被来自迁出栖息地的SIV代替。
(3)群岛间SIV迁移。
只有被选中且成对的群岛才会进行群岛间迁移。
从一个选中的群岛以一定的概率选出作为SIV迁入的栖息地,分别与另一个群岛内所有栖息地距离匹配,选出作为迁出的栖息地,进行两个群岛间SIV的迁移。
(4)SIV突变。
MBBO算法以一种均匀分布方式在所有栖息地中选择突变对象,通过SIV突变的方式生成新的候选解,从而增强算法跳出局部最优解的能力。
(5)更新替换精英解。
每次迭代完成SIV迁移、突变后,调用优化目标代价函数,分别计算群岛内新产生的子代栖息地以及父代精英解的HSI值,依据HSI值从大到小排序挑选出最优秀候选解作为当前代的精英解。
由当前代精英解替换父代精英解,并参与下一轮的迭代过程。
(6)终止判断。
迭代完成后,判断是否满足终止条件。若满足则退出,并以最新精英解作为最优解;若不满足,则迭代继续直到满足终止条件。
第二部分,在MBBO算法的基本执行流程基础上,分析MBBO算法隐含的并行性。
(1)子代栖息地生成过程的并行性。
MBBO算法以初始栖息地群岛为起点,每迭代一次生成新一代的候选解。若初始群岛数量为N且以串行方式迭代进化,则需经过N次相同形式的迁移、突变等操作,才能生成N个群岛的子代群体。子代个体的生成过程不存在依赖关系,可独立地同时进行。因此,N个群岛并行完成迁移、突变等操作,一次迭代即产生子代群体规模N。
多个CPU核心或多台计算机上,并行执行子代群体的产生过程,可以减少生成子代群体的时间开销,从而减少整体执行时间。
(2)适应度评价的并行性。
子代群体生成之后,所有父代精英解和子代个体可以同时调用优化目标代价函数并行执行HSI的计算。相对而言,适应度评价消耗时间比率高于迁移、突变等操作,实现HIS的并行计算,可以在很大程度上提高算法的迭代效率。
(3)子代群体选择更新的并行性。
在MBBO算法每次迭代并计算HSI后,依据HSI从高到低排序的子代群体和父代精英解中选择最优秀的候选解作为当前代的精英解,并更新替换上一代的精英解。
MBBO算法采用一对一的替换形式同时执行N个群岛内精英解的更新操作,提高算法的执行速度。
(4)分组迭代的并行性。
初始MBBO栖息地分组为不同的群岛,独立执行迁移、突变、选择更新等操作,在满足预先设定的条件时,不同群岛之间再进行精英解交换,从而在整体上降低算法的执行时间。
由以上的分析能够得到MBBO算法的并行性是可行的,并且能够从整体上降低算法执行的时间,极大的提高效率。
从而能够得到本发明所述的基于SPark与优化MBBO算法的并行虚拟机聚合方法,其包括如下步骤。
1)VMC问题到MBBO算法的映射。
VMC问题是已知聚合前集群中所有VM与HM的对应位置,提出降低数据中心能耗、均衡主机负载等聚合目标,依据数据中心网络拓扑、带宽等资源的约束条件和以上优化目标的代价函数,对数据中心的VM与HM对应位置进行重新分派,在所有可能的解空间找出最适合或者能够有效均衡各优化目标的最优解。
MBBO算法模拟生物地理学中群岛Archipelago、栖息地Habitats、栖息地适宜性指数HSI、适宜性指数变量SIV、种群迁移、突变、生物种群迭代等概念,通过整个生态系统内部种群间的迁移、突变、迭代实现物种进化,使得不同物种能够选择生存在最适宜的群岛。
生成VMC到MBBO映射,也就是虚拟机聚合问题到生物地理学优化算法的映射时;对应于具体的VMC问题,每一个栖息地代表所有VM与HM的一种位置排列,栖息地由一个长度为VM数量的行向量表示,向量中第i个元素代表第i个VM聚合后对应的HM编号;VM对应的HM编号被映射为该栖息地的适宜性指数变量SIV,由该栖息地内所有SIV共同决定栖息地适宜性指数HSI,即该候选解对VMC某个优化目标的匹配程度;众多的栖息地组成一个群岛,表示满足某个VMC优化目标的候选解集合。
高HSI栖息地由于生存环境适宜、物种丰富,因此迁出率高,迁入率低;而低HSI栖息地迁入率高,迁出率低。物种由高HSI栖息地迁移到低HSI栖息地,能够给低HSI栖息地带去优秀特性,可能提高其HSI。同时,不排除极端自然因素造成的栖息地某些种群灭绝,栖息地内SIV突变的可能。迁移和突变是栖息地物种间交换、产生SIV的重要途径,对应于具体VMC聚合问题,迁移能够使优秀候选解中某些恰当的VM与HM位置排列分享给较差的候选解;SIV突变能够产生新的候选解,避免候选解重复性及局部最优解的阻塞性。
2)采用拓展的Spark并行框架,执行优化的MBBO算法。
MBBO算法具有隐含的并行性,其迭代过程包含众多相互独立的子过程。为了最大化算法并行性,本文拓展原Spark并行框架添加二级Reduce方法,使其具有Map-1st Reduce-2nd Reduce 3个执行阶段,并采用主从式-细粒度的两层并行化模型。
并行框架的上层采用主从式的并行模式,由Master主节点将初栖息地群划分为若干个群岛,分配到不同的Worker从节点并行执行。Master节点负责任务分派,结果回收、子问题的切分以及监督算法的执行状态。
并行框架的下层采用细粒度的并行模式实现各群岛的并行执行过程。每个群岛对应分派到一个Worker节点,由Worker节点负责具体的任务执行过程,并向主节点反馈计算的结果。每个Worker节点对应由多台计算机组成的一个计算机集群,该集群独立地执行群岛内SIV迁移、SIV突变和精英解的更新替换,并将计算的中间结果存储到该集群的弹性分布式数据集RDD(Resilient Distributed Dataset)中。经过设定的迭代间隔,各群岛交换其存储的精英解和淘汰最差的个体,从而实现优秀特性的共享,扩大算法的搜索范围。具体算法中的并行执行过程如下。
本文通过在一定迭代间隔后,在迭代结束后添加一个各群岛间精英解交换阶段,拓展Spark平台原Map-Reduce 2层阶段为Map-1st Reduce-2nd Reduce 3层执行阶段,使其更加适合并行MBBO算法。
栖息地群岛初始化后,Master节点将群岛划分为与Worker节点同数量的群岛组,并分派到对应的Worker节点。运行于各Worker节点上的Map方法接收以键值对,
<Key:Value>(<0:individual0>,<1:individual1>,…,<n:individualn>)
表示的群岛作为初始输入数据,经过群岛内SIV迁移、突变迭代过程,输出以Worker编号为变量名保存所有子代候选解的新列表<Workeri:[individual0,individual1,…,individualn]>。
1st Reduce方法获取同一Worker节点上Map方法产生的中间结果,即存储于该节点RDD中的列表作为输入数据,进行子代栖息地群和父代精英解的HSI计算并从高到地排序,替换更新该节点保存的父代精英解并输出新的子栖息地群作为下一次迭代过程的初始栖息地群。
经过设定的迭代间隔,2nd Reduce方法获取所有Worker节点1st Reduce产生的最新精英解并相互交换,交付给Master节点。由Master节点将交换后的精英解重新分发到各Worker节点,作为新栖息地群参加下一次迭代过程。并且,每经过设定的迭代间隔,执行一次2nd Reduce方法进行精英解交换,以达到多个优化目标均衡的目的。
针对具体的VMC问题,如图1所示,VMC问题到MBBO算法的映射包括:
MBBO算法模拟生物地理学中群岛Archipelago、栖息地Habitats、栖息地适宜性指数HSI、适宜性指数变量SIV、种群迁移、突变、生物种群迭代等概念。映射到具体的VMC问题:
(1)每一个栖息地代表所有VM与HM的一种位置排列,[x1 x2 … xi … xN];
(2)栖息地由一个长度为VM数量的行向量表示,向量中第i个元素代表第i个VM聚合后对应的HM编号;
(3)第i个VM聚合后对应的HM编号映射为一个SIV,由该栖息地内所有SIV共同决定栖息地适宜性指数HSI,即该候选解对某个VMC优化目标的匹配程度;
(4)众多的栖息地组成群岛,表示满足某个VMC优化目标的候选解集合;
(5)高HSI栖息地SIV趋向于迁入低HSI栖息地,能够使优秀候选解中某些合理的VM与HM位置排列分享给较差的候选解;栖息地内SIV突变,能够产生新的候选解,避免候选解重复性及局部最优解的阻塞性。
如图3,MBBO算法采用的两层并行模型。
由于MBBO算法具有子代栖息地生成过程的并行性、适应度评价的并行性、子代群体选择更新的并行性、分组迭代的并行性,因此。MBBO算法的并行实现可以采用Spark主从式-细粒度的两层并行化模型。
其中,子代栖息地生成过程的并行性指子代个体的迁移、突变过程不存在依赖关系,可独立地同时进行;适应度评价的并行性指子代群体生成之后,所有父代精英解和子代个体可以同时调用优化目标代价函数并行执行HSI的计算;子代群体选择更新的并行性指各群岛每次迭代后新选出的精英解能够并行执行更新替换;分组迭代的并行性指在满足预设条件前,各群岛独立迭代进化,无需通信交流。
并行框架的上层采用主从式的并行模式,由Master主节点将初栖息地群划分为若干个群岛,分配到不同的Worker从计算节点并行执行。Master节点负责任务分派,结果回收、子问题的切分以及监督算法的执行状态。
并行框架的下层采用细粒度的并行模式实现各群岛的并行执行过程。每个群岛对应分派到一个Worker节点,由Worker节点负责执行具体的SIV迁移、突变和精英解替换任务,并将计算的中间结果存储到该集群的弹性分布式数据集RDD(Resilient Distributed Dataset)中,执行后向主节点反馈计算的结果。
如图4、图5,拓展的spark并行框架与MBBO算法的并行执行过程:
为了更好的均衡多个优化目标,通过在一定迭代间隔后,添加一次各群岛间精英解交换阶段,拓展原Spark平台Map-Reduce 2级阶段为Map-1st Reduce-2nd Reduce 3级执行阶段。
(1)栖息地群岛初始化后,Master节点将群岛划分为与Worker节点同数量的群岛组,并分派到对应的Worker节点。运行于各Worker节点上的Map方法接收以键值对
<Key:Value>(<0:individual0>,<1:individual1>,…,<n:individualn>)
表示的群岛作为初始输入数据,经过群岛内SIV迁移、突变迭代过程,输出一个以Worker编号为变量名保存所有子代候选解的新列表。<Workeri:[individual0,individual1,…,individualn]>。
(2)1st Reduce方法获取同一Worker节点上Map方法产生的中间结果,即存储于该节点RDD中的列表作为输入数据,进行子代栖息地群和父代精英解的HSI计算并从高到地排序,替换更新该节点保存的父代精英解并输出新的子栖息地群作为下一次迭代过程的初始栖息地群。
(3)经过设定的迭代间隔,2nd Reduce方法获取所有Worker节点1st Reduce产生的最新精英解并相互交换,交付给Master节点。由Master节点将交换后的精英解重新分发到各Worker节点,作为新栖息地群参加下一次迭代过程。并且,每经过设定的迭代间隔,执行一次2nd Reduce方法进行精英解交换,以达到多个优化目标均衡的目的。
- 还没有人留言评论。精彩留言会获得点赞!