条件编译预处理方法和装置与流程
本发明涉及计算机处理领域,特别是涉及一种条件编译预处理方法和装置。
背景技术:
传统POS应用开发普遍采用C语言进行开发,C语言使一种编译型高级语言,开发人员可以充分利用条件编译的特性,在同一个工程中支持多种软/硬配置,但是当应用在跨平台时必须分别生成各自平台下的版本,而且开发难度较大。解释型语言(比如,WMLScript)可以做到跨平台,而且相对C语言来说,开发难度较低,但是解释型语言不具有条件编译的特性。
在典型的POS软件项目中,往往同一个项目需要支持多种配置,且这些机型应用逻辑差异并不大,有了条件编译就可以实现同一个工程支持不同配置,但是如果选择解释型语言作为开发语言,由于不具有条件编译功能,那么当一套应用要适用多种配置时,要么复制代码,各自建立工程,要么通过变量控制程序流程。而复制代码的做法会造成维护成本高,通过变量控制的做法会增加资源的消耗。因此,亟待需要提出一种使得解释型语言也能够实现条件编译的方法。
技术实现要素:
基于此,有必要针对上述问题,提出一种轻量的使得解释型语言也能实现条件编译的条件编译预处理方法和装置。
一种条件编译预处理方法,所述方法包括:获取待处理的原程序文本;对所述原程序文本进行分析,根据预设的正则表达式匹配出对应的关键字并输出相应的标记;根据所述标记和预设的条件编译语法规则匹配出相应的事件;根据当前状态和所述事件确定相应的处理动作;根据确定的所述处理动作对所述原程序文本进行对应的处理,输出处理后的目标程序文本。
在其中一个实施例中,所述根据当前状态和所述事件确定相应的处理动作的步骤包括:根据当前状态和所述事件确定下一步状态;根据所述下一步状态确定相应的处理动作。
在其中一个实施例中,所述根据确定的所述处理动作对所述原程序文本进行对应的处理,输出处理后的目标程序文本的步骤包括:将确定的所述处理动作添加到动作列表;根据所述动作列表对所述原程序文本执行对应的处理动作,输出处理后的目标程序文本。
在其中一个实施例中,所述根据所述标记和预设的条件编译语法规则匹配出相应的事件的步骤还包括:根据所述标记和预设的条件编译语法规则进行匹配,当匹配到包含宏名称的条件语句时,向宏定义管理器查询与所述宏名称对应的定义及相应的值以进行条件判断,根据所述条件判断的结果匹配出相应的事件。
在其中一个实施例中,所述对所述原程序文本进行分析,根据预设的正则表达式匹配出对应的关键字并输出相应的标记的步骤包括:对所述原程序文本进行分析,根据预设的正则表达式匹配出对应的关键字,记录所述关键字所在的行号,输出相应的标记和对应的行号;所述根据确定的所述处理动作对所述原程序文本进行对应的处理,输出处理后的目标程序文本的步骤包括:根据所述处理动作的类型和对应的行号执行对应的处理动作,输出处理后的目标程序文本。
一种条件编译预处理装置,所述装置包括:获取模块,用于获取待处理的原程序文本;输出模块,用于对所述原程序文本进行分析,根据预设的正则表达式匹配出对应的关键字并输出相应的标记;匹配模块,用于根据所述标记和预设的条件编译语法规则匹配出相应的事件;确定模块,用于根据当前状态和所述事件确定相应的处理动作;处理模块,用于根据确定的所述处理动作对所述原程序文本进行对应的处理,输出处理后的目标程序文本。
在其中一个实施例中,所述确定模块还用于根据当前状态和所述事件确定下一步状态,根据所述下一步状态确定相应的处理动作。
在其中一个实施例中,所述处理模块还用于将确定的所述处理动作添加到动作列表,根据所述动作列表对所述原程序文本执行对应的处理动作,输出处理后的目标程序文本。
在其中一个实施例中,所述匹配模块还用于根据所述标记和预设的条件编译语法规则进行匹配,当匹配到包含宏名称的条件语句时,向宏定义管理器查询与所述宏名称对应的定义及相应的值以进行条件判断,根据所述条件判断的结果匹配出相应的事件。
在其中一个实施例中,所述输出模块还用于对所述原程序文本进行分析,根据预设的正则表达式匹配出对应的关键字,记录所述关键字所在的行号,输出相应的标记和对应的行号;所述处理模块还用于根据所述处理动作的类型和对应的行号执行对应的处理动作,输出处理后的目标程序文本。
上述条件编译预处理方法和装置,通过对原程序文本进行分析,根据预设的正则表达式匹配出对应的关键字并输出相应的标记,然后根据标记和预设的条件编译语法规则匹配出相应的事件,根据当前状态和事件确定相应的处理动作,然后根据确定的处理动作对原程序文本进行对应的处理,输出处理后的目标程序文本。该方法通过模拟条件编译的过程对原程序文本进行条件编译预处理,使得使用解释型语言开发时仍然可以使用条件编译特性,当需要适用多种配置时,通过使用该条件编译预处理方法不仅减少了维护成本,而且减少了资源消耗。
附图说明
图1为一个实施例中终端的内部结构框图;
图2为一个实施例中条件编译预处理方法流程图;
图3为一个实施例中根据当前状态和事件确定相应的处理动作的方法流程图;
图4为一个实施例中根据确定的处理动作对原程序文本进行对应的处理,输出处理后的目标程序文本的方法流程图;
图5为一个实施例中实现条件编译预处理的示意图;
图6为一个实施例中条件编译预处理装置的结构框图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
如图1所示,在一个实施例中,终端102的内部结构如图1所示,包括通过系统总线连接的处理器、内存储器、非易失性存储介质、网络接口、显示屏和输入装置。其中,终端102的非易失性存储介质存储有操作系统,还包括一种条件编译预处理装置,该条件编译预处理装置用于实现一种条件编译预处理方法。该处理器用于提供计算和控制能力,支撑整个终端的运行。终端中的内存储器为非易失性存储介质中的条件编译预处理装置的运行提供环境,该内存储器中存有计算机可读指令,该计算机可读指令被处理器执行时,可使得处理器执行一种条件编译预处理方法。网络接口用于连接到网络进行通信。终端102的显示屏可以是液晶显示屏或者电子墨水显示屏等,输入装置可以是显示屏上覆盖的触摸层,也可以是电子设备外壳上设置的按键、轨迹球或触控板,也可以是外接的键盘、触控板或鼠标等。该终端可以是POS机、平板电脑、笔记本电脑、台式计算机等。本领域技术人员可以理解,图1中示出的结构,仅仅是与本申请方案相关的部分结构的框图,并不构成对本申请方案所应用于其上的终端的限定,具体的移动终端可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
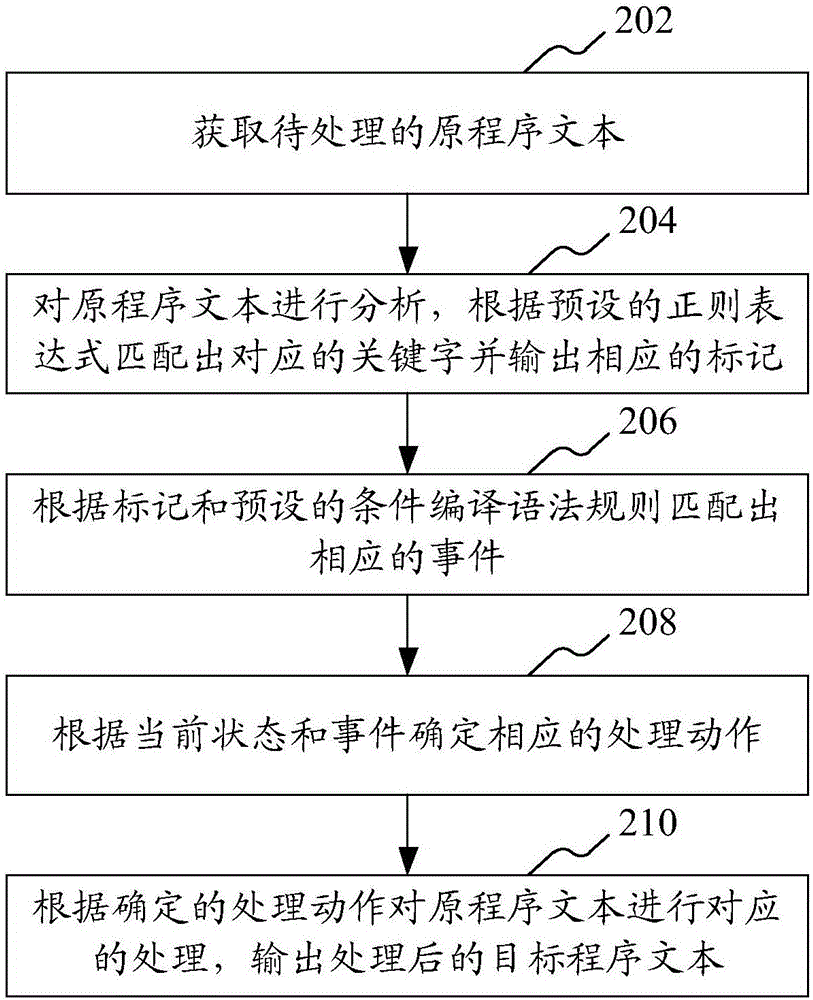
如图2所示,在一个实施例中,提出了一种条件编译预处理方法,该方法包括:
步骤202,获取待处理的原程序文本。
在本实施例中,为了使得解释型语言(比如,WMLScript)也能够实现条件编译的特性,通过模拟C语言进行条件编译的功能,提出一种适用于解释型语言进行条件编译的预处理方法。其中,条件编译的本质可以简单的理解为:分析原程序文本,根据“指定条件”保留或删除某段代码,并输出处理后的程序文本,即根据指定条件从原程序文本中挑选出符合要求的目标程序文本。为了对原程序文本进行筛选,终端首先需要获取待处理的原程序文本,原程序文本是指编写的原程序代码。
步骤204,对原程序文本进行分析,根据预设的正则表达式匹配出对应的关键字并输出相应的标记。
在本实施例中,终端获取到待处理的原程序文本后,为了能够精确地判断是否符合“指定条件”。首先,通过对原程序文本进行分析,根据预设的正则表达式匹配对应的关键字,然后输出与该匹配到的关键字相应的标记(token)。其中,预先设置了正则表达式和关键字之间的匹配关系以及关键字与标记之间的对应关系。具体地,可用采用lex生成的词法分析器对原程序文本进行分析,其中,lex是词法扫描代码生成器,它根据定义的模式文件生成词法扫描代码,模式文件中主要使用正则表达式来定义匹配规则,以及匹配后执行的动作,比如,执行返回标记(token)。在另一个实施例中,在使用词法分析器对原程序文本进行分析时还需要解决以下几个问题,一是忽略注释,对注释中的所有文本均需忽略。二是忽略字符串中的任何数据,即忽略引号“”包围的字符串。三是记录当前所在行号,记录行号对后续处理非常重要,因为最终进行处理依赖于行号对原程序文本进行处理的。四是返回与关键字对应的标记(token),便于后续根据标记进行语法的匹配。其中,关键字包括#if,#ifdef,#ifndef,#elif,#else,#defined,#endif,#define,#undef等,相应的标记可以设置为:IF,IFDEF,IFNDEF,ELIF,ELSE,DEFINED,ENDIF,DEFINE等。五是返回宏名称和宏值,当词法分析器匹配到#define、#undef关键字时,将对应的宏名称及宏值进行保存,并返回与宏的名称和宏值对应的标记:NAME、MACROVALUE,便于后续语法分析器根据匹配到的宏名称和值进行宏操作,比如,在宏定义管理器中增加或删除对应的宏定义。
步骤206,根据标记和预设的条件编译语法规则匹配出相应的事件。
在本实施例中,终端中预先设置了条件编译语法规则与事件之间的对应关系,即当匹配到相应的语法规则时,输出对应的事件,便于后续根据事件确定相应的处理动作。具体地,终端可以通过使用语法分析器根据标记和预设的条件编译语法规则匹配出相应事件的。在一个实施例中,终端首先启动语法分析器,语法分析器内部调用词法分析器,利用词法分析器输出的标记(token)和预先定义的条件编译语法规则,产生相应的事件。其中,语法分析器可以采用Yacc来实现,Yacc是语法分析代码生成器,它根据定义的语法文件生成语法分析器。语法文件采用巴科斯范式(Backus-Naur Form)来描述语法规则,它使用lex输出的标记(token)以及自身定义的语法规则来匹配并执行相应的动作(比如,执行一段C代码)。如表1中所示,展示了事件与对应的条件编译语法规则的说明。
表1
步骤208,根据当前状态和事件确定相应的处理动作。
在本实施例中,终端根据标记和预设的条件编译语法规则匹配出相应的事件后,获取当前状态,根据当前状态和事件确定相应的处理动作。在一个实施例中,可以预先存储处理动作与当前状态和事件的关系表,当获取到当前状态和事件后可以确定相应的处理动作,其中,处理动作可以为删除或保留某段代码。在另一个实施例中,首先需要根据当前状态和事件确定下一步的状态,继而根据下一步的状态确定对应的处理动作。具体地,首先,终端通过语法分析器匹配到事件后,输出事件到状态处理器中,驱动状态处理器中的状态进行跳转,即从一个状态跳转到另一个状态。然后根据跳转到的另一个状态确定对应的处理动作。其中,语法分析器、状态处理器等都是终端内部的软件实现。在一个实施例中,根据条件编译语法特性,状态处理器采用栈的方式来存储和管理状态(即维护了一个状态栈)。如表2中所示,展示了预定义的状态以及相应的状态说明。通过获取当前状态和匹配到的事件确定下一步状态(参考表3),进而确定对应的处理动作。
表2
步骤210,根据确定的处理动作对原程序文本进行对应的处理,输出处理后的目标程序文本。
在本实施例中,终端当确定完处理动作后,根据该确定的处理动作对原程序文本进行对应的处理,并输出处理后的目标程序文本,该输出的目标程序文本就是根据指定条件筛选出来的需要用到的目标程序代码,后续使用编译器对该目标程序文本进行编译即可实现对应的条件编译功能。具体地,终端通过状态处理器根据下一步状态向动作处理器的动作列表中添加相应的处理动作,然后动作处理器会根据动作列表中的处理动作进行对应的处理,比如,删除相应的一行或多行代码,之后输出处理后的目标程序文本,其中,状态处理器、动作处理器是终端内部的软件实现,可以理解为功能实现模块。
在本实施例中,通过对原程序文本进行分析,根据预设的正则表达式匹配出对应的关键字并输出相应的标记,然后根据标记和预设的条件编译语法规则匹配出相应的事件,根据当前状态和事件确定相应的处理动作,然后根据确定的处理动作对原程序文本进行对应的处理,输出处理后的目标程序文本。该方法通过模拟条件编译的过程对原程序文本进行条件编译预处理,使得使用解释型语言开发时仍然可以使用条件编译特性,当需要适用多种配置时,通过使用该条件编译预处理方法不仅减少了维护成本,而且减少了资源消耗。
如图3所示,在一个实施例中,根据当前状态和事件确定相应的处理动作的步骤包括:
步骤208A,根据当前状态和事件确定下一步状态。
在本实施例中,当根据预设的条件编译语法规则匹配到相应的事件后,获取当前状态,通过查询状态表查找与当前状态和事件对应的下一步状态。如表3中所示,为一个实施例中的状态表。表3中纵轴第1列代表的是当前状态,横轴第1行为事件,其他单元格表示当前状态接收到事件时的下一步状态。比如,当前状态为初始态,即STATE_INITIAL,而发生的事件为EVENT_IF_TRUE,通过查询状态表,即表3,可以得到对应的下一步状态为STATE_IF_TRUE(即第3行第2列对应的单元格)。
表3
步骤208B,根据下一步状态确定相应的处理动作。
在本实施例中,当确定了下一步状态后,根据该下一步状态确定相应的处理动作。具体地,根据下一步的状态,可以区分出下一步采取的动作。预先定义动作的类型,比如,动作分为两类,一种是删除当前行(比如,if,else,elif自己所在行),对应的下一步状态为:STATE_IF_TRUE,STATE_ELSE_TRUE,STATE_ELIF_TRUE,STATE_ENDIF;一种是删除多行,对应的下一步状态为:STATE_IF_FALSE,STATE_IF_INHERIT_FALSE,STATE_ELSE_FALSE,STATE_ELIF_FALSE。
如图4所示,在一个实施例中,根据确定的处理动作对原程序文本进行对应的处理,输出处理后的目标程序文本的步骤包括:
步骤210A,将确定的处理动作添加到动作列表。
在本实施例中,根据当前状态和事件确定相应的处理动作后,将确定的动作添加到动作列表。具体地,终端首先通过语法分析器匹配到事件,然后由该事件驱动状态处理器的跳转,之后状态处理器通过查询状态表根据当前状态和事件确定下一步状态,然后根据下一步状态确定对应的处理动作,进而将确定的动作添加到动作处理器的动作列表,便于后续动作处理器根据动作列表中的动作进行相应的处理,其中,语法分析器、状态处理器、动作处理器等都是终端内部的软件实现。
步骤210B,根据动作列表对原程序文本执行对应的处理动作,输出处理后的目标程序文本。
在本实施例中,终端通过状态处理器将处理动作添加到动作处理器的动作列表后,根据动作列表对原程序文件进行处理的方式有两种,一种是,将所有的处理动作都添加到动作列表后,动作处理器根据保存的一系列处理动作对原程序文本执行对应的操作;一种是,每当有动作添加到动作列表,动作处理器便开始执行对应的处理动作,然后输出处理后的程序文本,即目标程序文本。举个例子,根据典型的条件编译处理#if true…#else…#endif,最终采取的处理动作为1)删除#if true这一行本身;2)删除#else(含)到endif(含)之间的所有行。考虑到待删除的代码本身对程序员有参考价值,动作处理器并不真正删除代码行,而是在这些代码前加上行注释“//”。终端完成处理动作后,输出处理后的目标程序文本,如果后面还有编译过程,则输出到编译器进行处理,从而实现了条件编译。
在一个实施例中,根据标记和预设的条件编译语法规则匹配出相应的事件的步骤包括:根据标记和预设的条件编译语法规则进行匹配,当匹配到包含宏名称的条件语句时,向宏定义管理器查询与宏名称对应的定义及相应的值以进行条件判断,根据条件判断的结果匹配出相应的事件。
在本实施例中,宏定义管理器用于管理宏定义,条件编译的条件判断有时需要基于宏定义的内容。当匹配到包含宏名称的条件语句时,需要向宏定义管理器中查询与匹配到的宏名称对应的宏值,便于根据该宏值进行条件判断,即判断该条件是TRUE还是FALSE。其中,宏定义包含两大类,一种是通过命令行参数传入的全局宏定义-D,一种是文件局部使用#define定义的宏。局部定义的宏会覆盖全局定义,而且只会影响本文件该行后面的行为,对其他文件不产生作用。另外,宏记录的信息除了包括宏类型,即全局宏和局部宏外,还记录了宏的状态、宏名称、宏值以及宏行号。宏状态包括可用的、暂时失效的、无效的。其中,暂时失效状态适用于全局宏,表示使用-D定义过但是在某个文件中被取消(#undef)了,这个状态只影响该文件本身,处理另一个文件时,-D仍然恢复为可用状态;无效状态适用于局部宏,表示在某个文件中被取消(#undef)了。宏定义管理器中的宏行号仅对局部宏有效,它主要用于当检测到同一文件中出现两次相同的宏定义时,给出警告,提示当前的定义在哪一行,在做查询操作时,先检测局部宏,如果不存在,在检查全局宏。在一个实施例中,当碰到以下语句#ifdef NAME,#ifndef NAME,#if NAME,#elif NAME,#if defined(NAME)时,需要查询宏定义管理器,看是否定义以及对应的值是什么,如果查找不到,则返回NULL表示找不到定义。
在一个实施例中,当匹配到包含宏名称的定义语句时,根据定义语句的类型在宏定义管理器中增加或删除相应的宏定义。
在本实施例中,由于有时进行条件判断需要基于宏定义管理器中的宏定义,所以首先需要在宏定义管理器中添加宏定义,添加后如果在后面发现被取消了,还需要在宏定义管理器中删除相应的宏定义。具体地,首先是终端通过词法分析器根据预设的正则表达式进行匹配,并输出相应的标记,其中,标记中包含了代表宏名称的标记。比如,当匹配到关键字#define NAME VALUE、#defineNAME或#undef NAME时,返回宏的名称。也就是说,当匹配到define,undef关键字时,将对应的文本存储(将真实的宏名称存储),并返回标记NAME。然后通过语法分析器根据标记和预设的条件编译语法规则进行匹配,当匹配到包含宏名称的定义语句时,则根据该定义语句的类型在宏定义管理器中增加或删除相应的宏定义。其中,宏定义语句是指包含#define,#undef等定义性词语的语句。根据定义语句的类型,将语句分为定义和取消定义两种,其中,包含#define的语句表示定义类型的语句,包含#undef的语句表示取消定义类型的语句。在一个实施例中,当碰到以下语句时对宏定义管理器进行添加操作#define NAME,#define NAME VALUE,当碰到#undef NAME时会对宏定义管理器进行删除操作。通过在宏定义管理器中添加或删除宏定义,便于后续当匹配到含有宏名称的条件语句时,通过查询相应的宏定义来进行条件判断,即判断是TRUE还是FALSE。
在一个实施例中,对原程序文本进行分析,根据预设的正则表达式匹配出对应的关键字并输出相应的标记的步骤204包括:对原程序文本进行分析,根据预设的正则表达式匹配出对应的关键字,记录关键字所在的行号,输出相应的标记和对应的行号。
在本实施例中,为了便于执行确定的处理动作,在对原程序文本进行分析,匹配出对应的关键字后,不仅需要输出与关键字对应的标记(token),而且需要记录每个匹配到的关键字所在的行号并输出。记录行号对后续的处理非常重要,因为动作处理器最终是依赖行号对程序文本进行处理的。具体实现的手段可以通过定义一个用于增加行号的c函数,然后由词法分析器通过调用这个函数来增加全局行号。比如,每当碰到“\n”时,调用c函数增加全局行号。
在一个实施例中,根据确定的处理动作对原程序文本进行对应的处理,输出处理后的目标程序文本的步骤210包括:根据处理动作的类型和对应的行号执行对应的处理动作,输出处理后的目标程序文本。
在本实施例中,终端通过状态处理器将对应的处理动作添加到动作处理器的动作列表后,使动作处理器根据处理动作的类型和对应的行号执行对应的处理动作,然后输出处理后的目标程序文本。处理动作的类型可以分为两类:一种是删除当前行;一种是删除多行。在进行动作处理时,每个处理动作都对应一个起始行号和结束行号信息。第I类动作可以当成起始行号和结束行号相同的特例。对于第II类动作,由于在匹配到删除多行的事件时,还不知道结束行号是多少,可以暂时将结束行号与起始行号写成相同的值,当下一个事件产生新的动作后,在添加新动作之前,将之前的结束行号更新为当前行号-1即可。具体地,处理动作是与状态处理器确定的下一步状态对应的,当下一步状态为:STATE_IF_TRUE,STATE_ELSE_TRUE,STATE_ELIF_TRUE,STATE_ENDIF时,则对应的动作为:删除当前行。当下一步状态为:STATE_IF_FALSE,STATE_IF_INHERIT_FALSE,STATE_ELSE_FALSE,STATE_ELIF_FALSE时,对应的动作为:删除多行。举例说明,当确定的下一步状态为STATE_IF_TRUE时,那么只需要删除当前行,即起始行号和结束行号相同。当确定的下一步状态为:STATE_IF_FALSE时,说明需要删除多行,但是具体删除几行还不知道,即还不知道结束行号是多少,当出现下一个事件时,假设出现的新事件为EVENT_ELSE_TRUE,那么其对应的下一个状态为STATE_ELSE_TRUE,表示删除当前行,在删除当前行之前,将当前行号减去1,作为上一事件的结束行号。
如图5所示,在一个实施例中,实现上述条件编译的方法具体是通过词法分析器、语法分析器、状态处理器、动作处理器以及宏定义管理器相互配合来完成的。首先,如果命令行参数中有-D,主程序会将全局宏添加到宏定义管理器中,接下来,终端中的主程序对每个原程序文本,循环执行如下操作,a),主程序启用语法分析器,语法分析器内部调用词法分析器,通过词法分析器对原程序文本进行分析匹配出相应的关键字并输出相应的标记(token),然后语法分析器利用词法分析器输出的标记(token)及事先定义的语法规则,产生相应的事件,在此过程中,根据匹配到的包含宏名称的语句对宏定义管理器进行相应的增、删、查的操作;b)语法分析器输出事件到状态处理器,驱动状态机的跳转,状态处理器根据下一步状态确定相应的处理动作,并将处理动作添加到动作处理器中。c)主程序按顺序执行处理器中的动作列表,输出处理后的程序文本,即目标程序文本。上述词法分析器、语法分析器、状态处理器、动作处理器以及宏定义管理器通过相互配合实现了对条件编译的预处理,实现该条件编译的预处理方法所对应的条件编译预处理器的执行文件仅36k左右,是一种轻量级的条件编译预处理器,且如果有后续编译过程,只需在标准编译流程前添加条件编译预处理器命令即可,方便集成。此外,该方法适用于多种语言,比如,WMLScript,JavaScript,Java、Python等,由于不同程序语言有不同的规范,可根据需要微调词法、语法规则文件就可以快速适应任何语言。因此,还具有通用性,易扩展的特点。
如图6所示,在一个实施例中,提出了一种条件编译预处理装置,该装置包括:
获取模块602,用于获取待处理的原程序文本。
输出模块604,用于对原程序文本进行分析,根据预设的正则表达式匹配出对应的关键字并输出相应的标记。
匹配模块606,用于根据标记和预设的条件编译语法规则匹配出相应的事件。
确定模块608,用于根据当前状态和事件确定相应的处理动作。
处理模块610,用于根据确定的处理动作对原程序文本进行对应的处理,输出处理后的目标程序文本。
在一个实施例中,确定模块还用于根据当前状态和事件确定下一步状态,根据下一步状态确定相应的处理动作。
在一个实施例中,处理模块还用于将确定的处理动作添加到动作列表,根据动作列表对原程序文本执行对应的处理动作,输出处理后的目标程序文本。
在一个实施例中,匹配模块还用于根据标记和预设的条件编译语法规则进行匹配,当匹配到包含宏名称的条件语句时,向宏定义管理器查询与宏名称对应的定义及相应的值以进行条件判断,根据条件判断的结果匹配出相应的事件。
在一个实施例中,输出模块还用于对原程序文本进行分析,根据预设的正则表达式匹配出对应的关键字,记录关键字所在的行号,输出相应的标记和对应的行号。处理模块还用于根据处理动作的类型和对应的行号执行对应的处理动作,输出处理后的目标程序文本。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,该计算机程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,前述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)等非易失性存储介质,或随机存储记忆体(Random Access Memory,RAM)等。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!