快速迁移多源异构电网大数据到HBase的方法及系统与流程
本发明涉及电力系统信息与技术通信领域,尤其涉及快速迁移多源异构电网大数据到HBase的方法及系统。
背景技术:
在电网系统中,输变电设备是主要的设备。输变电设备的状态涉及到整个电网系统的安全以及系统的正常运行。电网系统的数据主要为输变电设备的状态数据。与输变电设备状态相关的数据有运行时气数据QX、微气象数据WQX、设备台账数据、EMS数据和GIS数据等。同时,设备的状态数据是时序数据,数据体量将随时间快速增长。因此,电网系统数据具有数据体量巨大,数据类型复杂的特点。并且,电网数据存储方式多样,数据存储在多种类型的数据源当中,如txt文本文件、CSV文件、Oracle数据库中和MySQL数据库中等。现在的智能变电站状态监测系统中存在的一些导入数据库的方法,大多是通过模型解析模块导入变电站模型配置文件,读取变电站状态监测系统模型数据,并转换为数据库表信息和数据库结构信息,随后写入传统关系型数据库。
考虑到电网数据体量不断增长,传统的存储方式对存储服务器造成巨大的压力,因此将数据迁移到统一的HBase分布式平台进行存储管理具有非常重要的意义。然而,电网数据体量大,结构类型复杂,同时存储方式,使得数据迁移工作变得复杂。如何髙效快速地进行数据在新旧平台之间的迁移,是目前亟待解决的技术问题之一。
专利[1](基于HBase的数据导入方法和系统CN104778182A)提出了一种提高导入数据到HBase速度的方法。在该专利中,首先将文件流中的行数据直接转化成json对象,再通过导入线程将json对象构造HBase的row对象,然后将row对象导入到HBase当中。
专利[2](一种将智能变电站状态监测系统模型导入数据库的方法CN102521421A)提出了一种智能变电站状态监测系统模型导入数据库的方法。该方法首先读取智能变电站状态监测系统模型中的信息,然后模型信息与数据库表信息转换模块将所述模型解析模块读取的信息转换为数据库表信息和数据库结构信息。
专利[3](一种基于HBase的输电线路综合数据存储方法CN104216989A)提供了一种基于HBase的输电线路综合数据存储方法。它采集输电线路综合数据,将所述输电线路综合数据进行分类处理,根据分类结果构建HBase表,并将所述HBase表内的输电线路综合数据转换为字节数组;将所述字节数组按照HBase表格式,依次存储至HBase分布式数据库。
专利[1]和专利[2]以及专利[3]提出的方法均本方法不同。在专利[1]中,该方法仅仅将数据进行JSON化,实现了数据的规范化,方便构造row对象。但是在传输的数据量上没有减少,同时因为JSON化,反而需要更多的时间开销;同时该方法并没有考虑到空间效率的问题。专利[2]中提出了数据模型,但是该模型是针对传统数据库的,并没有考虑到大数据HBase平台。专利[3]中虽有提出HBase中列与行键的构成,但在行键的构建上直接采用字符串与编号连接的方法,无法针对更复杂的电力数据格式进行快速迁移。
技术实现要素:
本发明的目的就是为了解决上述问题,提供一种快速迁移多源异构电网大数据到HBase的方法及系统,该方法可以将分布于CSV文件、Oracle数据库等多源的电网大数据快速迁移到HBase大数据平台中。
为了实现上述目的,本发明采用如下技术方案:
快速迁移多源异构电网大数据到HBase的方法,包括如下步骤:
步骤(1):连接电网数据库与HBase数据平台;电网数据库中的每一条数据均存在唯一的标识ID,电网数据库中的每一条数据均由标识ID+数据内容组成;
步骤(2):根据唯一的标识ID建立ID映射表,所述ID映射表包括包括数据类ID映射表和数据类内部ID映射表,将数据类ID映射表和数据类内部ID映射表存储在第二Oracle数据库当中;数据类ID映射表包括:数据类ID、数据类ID编码和数据类ID备注;数据类内部ID映射表包括:数据类内部ID和数据类内部ID编码;
步骤(3):对数据源进行选择识别,选定数据源后,读取第二Oracle数据库当中的数据类ID映射表和数据类内部ID映射表,将数据类ID映射表和数据类内部ID映射表写入内存,数据类ID映射表和数据类内部ID映射表常驻内存;
步骤(4):将数据类ID映射表中的数据类ID编码和数据类内部ID映射表中的数据类内部ID编码分别进行编码压缩,分别形成数据类ID行键和数据类内部ID行键;
步骤(5):将数据类ID行键和数据类内部ID行键转化为字节数组;
步骤(6):将数据类ID行键和数据类内部ID行键以及HBase的列名称qualifier按字节形式写入HBase表中。
所述步骤(1)电网数据库包括:CSV文件、txt文本文件和第一Oracle数据库;
所述步骤(2)的唯一的标识ID由数据类ID和数据类内部ID组成;数据类ID为表类型,数据类内部ID为表内部数据列的字段;
所述步骤(2)的数据类ID编码的取值范围是1~13;数据类内部ID编码的取值范围是1~19;
所述步骤(3)的数据源包括CSV文件、txt文本文件和第一Oracle数据库。
所述步骤(4)的步骤为:
根据数据类ID,查找步骤(3)存储的数据类ID映射表,得到数据类ID的编码;
根据数据类内部ID,查找步骤(3)读入内存的数据类内部ID映射表,得到数据类内部ID的编码;
根据数据类ID的取值范围,截取有意义的字节数组,将无意义的字段舍弃;
同理,根据数据类内部ID的取值范围,截取有意义的字节数组,将无意义的字段舍弃。
数据类ID取值范围为1~256,有意义的字节数组为最低位的8个bit。
数据类内部ID取值范围根据需要设定,有意义的字节数组根据需要设定。
截取最低位的8个bit,所需存储字节由int型的4字节减少为1个字节,节省75%的空间。
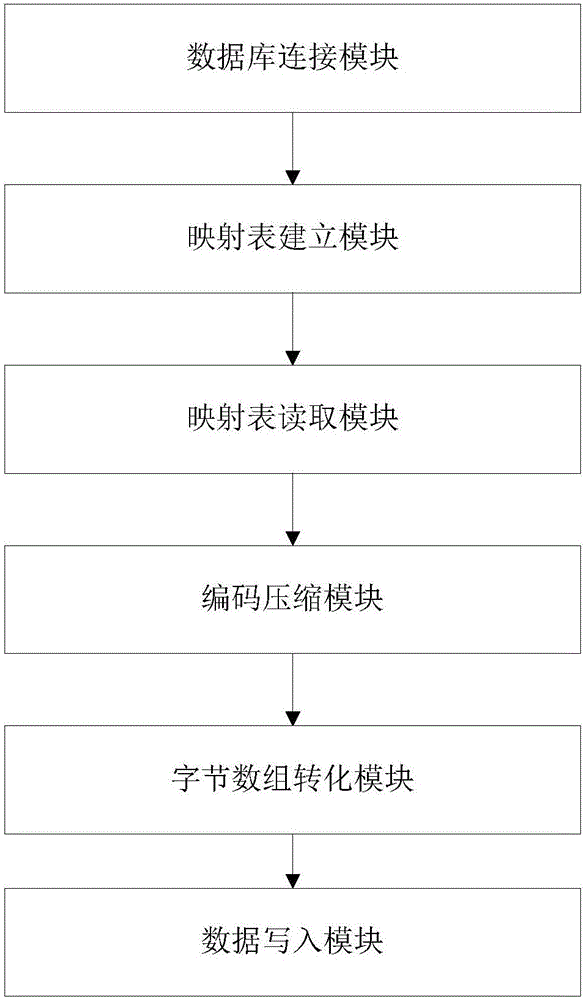
快速迁移多源异构电网大数据到HBase的系统,包括:
数据库连接模块:连接电网数据库与HBase数据平台;电网数据库中的每一条数据均存在唯一的标识ID,电网数据库中的每一条数据均由标识ID+数据内容组成;
映射表建立模块:根据唯一的标识ID建立ID映射表,所述ID映射表包括包括数据类ID映射表和数据类内部ID映射表,将数据类ID映射表和数据类内部ID映射表存储在第二Oracle数据库当中;数据类ID映射表包括:数据类ID、数据类ID编码和数据类ID备注;数据类内部ID映射表包括:数据类内部ID和数据类内部ID编码;
映射表读取模块:对数据源进行选择识别,选定数据源后,读取第二Oracle数据库当中的数据类ID映射表和数据类内部ID映射表,将数据类ID映射表和数据类内部ID映射表写入内存,数据类ID映射表和数据类内部ID映射表常驻内存;
编码压缩模块:将数据类ID映射表中的数据类ID编码和数据类内部ID映射表中的数据类内部ID编码分别进行编码压缩,分别形成数据类ID行键和数据类内部ID行键;
字节数组转化模块:将数据类ID行键和数据类内部ID行键转化为字节数组;
数据写入模块:将数据类ID行键、数据类内部ID行键以及HBase的列名称qualifier按字节形式写入HBase表中。
所述编码压缩模块被配置为:
根据数据类ID,查找数据类ID映射表,得到数据类ID的编码;
根据数据类内部ID,查找读入内存的数据类内部ID映射表,得到数据类内部ID的编码;
根据数据类ID的取值范围,截取有意义的字节数组,将无意义的字段舍弃;
同理,根据数据类内部ID的取值范围,截取有意义的字节数组,将无意义的字段舍弃。
数据类ID取值范围为1~256,有意义的字节数组为最低位的8个bit。
数据类内部ID取值范围根据需要设定,有意义的字节数组根据需要设定。
本发明的有益效果:
为了进行新旧平台之间的数据迁移,首先需要支持多数据源的快速访问,以针对不同数据源进行迁移方法的特异性设计;其次需要设计髙效的数据传输方式,以减小数据传输过程中的带宽,使得在相同的带宽下能够传输更多的数据;最后则是尽可能减少与数据源的交互,节省IO开销。通过以上多种优化方式,实现了电网大数据的快速迁移方法。
附图说明
图1为本发明的方法流程图;
图2为本发明的系统功能模块图。
具体实施方式
下面结合附图与实施例对本发明作进一步说明。
Oracle数据库是甲骨文公司的一款关系数据库,主要针对企业,具有极高的稳定性,支持复杂的查询等操作。MySQL是甲骨文公司旗下的一款开源的关系型数据库,具有免费、小巧易用、稳定性高的优点。CSV文件是字符分割值文件,常用语表达数据表格。txt文件是文本文件,具有数据结构简单、跨平台等优点。同时,HBase是基于Hadoop平台的高稳定、高可靠性、面向列的可升缩分布式数据库。利用HBase技术,可以利用廉价服务器搭建超大容量的存储集群。
本发明提出的快速迁移方法,考虑到了数据传输量的问题,以及存储空间的问题。因此,在映射压缩方法下,所需的传输时间更少,存储空间也更少。本方法有更好的时间性能和空间性能。
本发明的数据模型针对HBase更优化,同时针对电力行业繁杂的数据类型进行更高效的迁移和存储。
本专利的数据迁移方法基于Oracle数据库、MySQL数据库、CSV文件和txt文件等多个数据源组成的数据平台和HBase集群组成的数据平台之上,并基于以上方法开发了界面友好的图形化转换工具。
一种快速导入迁移多源数据到HBase数据平台的方法,所述方法包括:(1)数据字符串ID到数字ID的映射方法;(2)利用映射表对字符ID进行数字压缩的方法;(3)针对大量导入数据的频繁映射需求的优化;
(1)(2)主要针对电网的复杂数据进行数字化标识,对传输数据量进行编码压缩。
(3)特征在于,对于大量导入时的映射操作,避免了频繁的访问映射关系,节省映射时间开销。
电网数据以多种组织形式存储,并且数据量巨大。为了实现数据的快速迁移,首先需要针对数据进行区分,对Oracle数据、CSV数据和txt文件数据进行数据源的识别。
电网数据中,每一条数据均存在唯一的标识ID以识别数据,因此电网中的每条数据均由ID+数据内容组成。为了实现快速迁移,则必须对数据进行压缩。数据的内容必须保持原数据,数据压缩主要针对标识ID进行压缩。同时,结合HBase存储数据的模型,建立了一套编码压缩机制。该编码压缩机制为:对数据源中的数据,针对唯一标识ID建立一个ID映射表,然后根据ID进行映射压缩。ID映射表主要分两个部分,数据类ID映射表和数据类内部ID映射表。其中数据类ID映射表可如下所示:
表1
然后针对数据类内部ID进行编码,举例如下:
表2
如表2所示,每一条的数据ID通过编码,可以将字符串映射为数字编码,从而大量节省数据传输量。
同时,为了加速映射,首先将对应的映射表存储在Oracle数据库当中。在导入数据时,将对应的映射表读入内存,并且在整个数据表导入期间,使该映射表常驻内存。
最后将映射编码后的row_key以及qualifier按字节写入构建的HBase表。
根据分析,为实现数据迁移,首先对数据源进行选择识别。选定数据源之后,将ID映射表读映射表读入内存,避免每次映射都需要访问Oracle数据库中的映射表,以加速映射过程。
映射表读入完成之后,针对每一条数据,进行ID映射,映射的过程即为压缩过程。
具体过程如图1所示:根据上述流程,设计并实现了图形界面导入工具。
如表1和表2的设计中,通过数据的ID映射,使得所需传输的数据从字符串变为整数ID,节省了数据传输量。当所需传输的数据量非常大时,节省的数据传输量非常巨大,从而可以非常快速地实现数据迁移。
同时,如图1所示,在映射之前,首先将映射表载入内存,并且在整个导入过程中,使其常驻。这样的好处,是避免每次插入数据,都需要从Oracle数据表中查询映射的ID。当迁移的数据量巨大的时候,频繁的查询操作会产生大量的时间开销,导致迁移速度变慢。因此,将映射表载入内存常驻,能够加速数据的迁移。
如图1所示,快速迁移多源异构电网大数据到HBase的方法,包括如下步骤:步骤(1):连接电网数据库与HBase数据平台;电网数据库中的每一条数据均存在唯一的标识ID,电网数据库中的每一条数据均由标识ID+数据内容组成;步骤(2):根据唯一的标识ID建立ID映射表,所述ID映射表包括包括数据类ID映射表和数据类内部ID映射表,将数据类ID映射表和数据类内部ID映射表存储在第二Oracle数据库当中;数据类ID映射表包括:数据类ID、数据类ID编码和数据类ID备注;数据类内部ID映射表包括:数据类内部ID和数据类内部ID编码;步骤(3):对数据源进行选择识别,选定数据源后,读取第二Oracle数据库当中的数据类ID映射表和数据类内部ID映射表,将数据类ID映射表和数据类内部ID映射表写入内存,数据类ID映射表和数据类内部ID映射表常驻内存;步骤(4):将数据类ID映射表中的数据类ID编码和数据类内部ID映射表中的数据类内部ID编码分别进行编码压缩,分别形成数据类ID行键和数据类内部ID行键;步骤(5):将数据类ID行键和数据类内部ID行键转化为字节数组;步骤(6):将数据类ID行键和数据类内部ID行键以及HBase的列名称qualifier按字节形式写入HBase表中。
所述步骤(1)电网数据库包括:CSV文件、txt文本文件和第一Oracle数据库;所述步骤(2)的唯一的标识ID由数据类ID和数据类内部ID组成;数据类ID为表类型,数据类内部ID为表内部数据列的字段;所述步骤(2)的数据类ID编码的取值范围是1~13;数据类内部ID编码的取值范围是1~19;所述步骤(3)的数据源包括CSV文件、txt文本文件和第一Oracle数据库。
所述步骤(4)的步骤为:根据数据类ID,查找步骤(3)存储的数据类ID映射表,得到数据类ID的编码;根据数据类内部ID,查找步骤(3)读入内存的数据类内部ID映射表,得到数据类内部ID的编码;根据数据类ID的取值范围,截取有意义的字节数组,将无意义的字段舍弃;同理,根据数据类内部ID的取值范围,截取有意义的字节数组,将无意义的字段舍弃。数据类ID取值范围为1~256,有意义的字节数组为最低位的8个bit。数据类内部ID取值范围根据需要设定,有意义的字节数组根据需要设定。截取最低位的8个bit,所需存储字节由int型的4字节减少为1个字节,节省75%的空间。
如图2所示,快速迁移多源异构电网大数据到HBase的系统,包括:
数据库连接模块:连接电网数据库与HBase数据平台;电网数据库中的每一条数据均存在唯一的标识ID,电网数据库中的每一条数据均由标识ID+数据内容组成;映射表建立模块:根据唯一的标识ID建立ID映射表,所述ID映射表包括包括数据类ID映射表和数据类内部ID映射表,将数据类ID映射表和数据类内部ID映射表存储在第二Oracle数据库当中;数据类ID映射表包括:数据类ID、数据类ID编码和数据类ID备注;数据类内部ID映射表包括:数据类内部ID和数据类内部ID编码;映射表读取模块:对数据源进行选择识别,选定数据源后,读取第二Oracle数据库当中的数据类ID映射表和数据类内部ID映射表,将数据类ID映射表和数据类内部ID映射表写入内存,数据类ID映射表和数据类内部ID映射表常驻内存;编码压缩模块:将数据类ID映射表中的数据类ID编码和数据类内部ID映射表中的数据类内部ID编码分别进行编码压缩,分别形成数据类ID行键和数据类内部ID行键;字节数组转化模块:将数据类ID行键和数据类内部ID行键转化为字节数组;数据写入模块:将数据类ID行键、数据类内部ID行键以及HBase的列名称qualifier按字节形式写入HBase表中。
上述虽然结合附图对本发明的具体实施方式进行了描述,但并非对本发明保护范围的限制,所属领域技术人员应该明白,在本发明的技术方案的基础上,本领域技术人员不需要付出创造性劳动即可做出的各种修改或变形仍在本发明的保护范围以内。
- 还没有人留言评论。精彩留言会获得点赞!