卷积运算装置及卷积运算方法与流程
本发明系关于一种卷积运算装置,尤指一种适于数据串流的卷积运算装置。
背景技术:
深度学习(deeplearning)已是开展人工智能(artificialintelligence,ai)的重要应用技术之一。其中,卷积神经网络(convolutionalneuralnetwork,cnn)则是近年来,引起广泛重视的一种深度学习高效识别技术。与其它深度学习架构相比,特别是在模式分类领域的应用,例如图像和语音识别方面,卷积神经网络避免了复杂的前期预处理,且可以直接输入原始图像或原始数据,因而得到了更为广泛的应用并可取得较佳的识别结果。
然而,卷积运算是一种很耗费效能的运算,在卷积神经网络的应用中,特别是卷积运算及连续平行运算,将占据大部分处理器的效能。另一方面,因特网的多媒体应用例如串流媒体也越来越广泛,因此,有必要提出一种卷积运算装置,当用于卷积运算及连续地平行运算的处理数据时,可具有优异的运算性能和低功耗表现,并且能够处理数据串流,实为当前重要的课题之一。
技术实现要素:
有鉴于上述课题,本发明提出一种能够处理数据串流的卷积运算装置以及方法。
一种卷积运算装置包括一卷积运算模块、一内存以及一缓冲装置。卷积运算模块具有多个卷积单元,各卷积单元基于一滤波器以及多个当前数据进行一卷积运算,并于卷积运算后保留部分的当前数据;缓冲装置耦接内存以及卷积运算模块,从内存取得多个新数据,并将新数据输入至卷积单元,新数据不与当前数据重复。
在一实施例中,卷积单元基于滤波器、保留的当前数据以及新数据进行次轮卷积运算。
在一实施例中,滤波器移动的步幅小于滤波器的最短宽度。
在一实施例中,卷积运算装置进一步包括一交错加总单元,其耦接卷积运算模块,依据卷积运算的结果产生一特征输出结果。
在一实施例中,卷积运算装置包括多个卷积运算模块,卷积单元以及交错加总单元系能够选择性地操作在一低规模卷积模式以及一高规模卷积模式;其中,在低规模卷积模式中,交错加总单元配置来对卷积运算模块中对应顺序的各卷积运算的结果交错加总以各别输出一加总结果;其中,在高规模卷积模式中,交错加总单元将各卷积单元的各卷积运算的结果交错加总作为输出。
在一实施例中,卷积运算装置进一步包括一加总缓冲单元,其耦接交错加总单元与缓冲装置,暂存特征输出结果;其中,当指定范围的卷积运算完成后,缓冲装置从加总缓冲单元将暂存的全部数据写入到内存。
在一实施例中,加总缓冲单元包括一部分加总区块以及一池化区块。部分加总区块暂存交错加总单元输出的数据;池化区块对暂存于部分加总区块的数据进行池化运算。
在一实施例中,池化运算为最大值池化或平均池化。
在一实施例中,卷积运算装置进一步包括一数据读取控制器以及一指令译码器,指令译码器从数据读取控制器得到一控制指令并将控制指令译码,藉以得到目前从内存输入数据的大小、输入数据的行数、输入数据的列数、输入数据的特征编号以及输入数据在内存中的起始地址。
在一实施例中,各卷单元包括多个低规模卷积输出以及一高规模卷积输出,低规模卷积输出进行低规模卷积运算以输出低规模卷积结果,高规模卷积输出进行高规模卷积运算以输出高规模卷积结果。
一种数据串流的卷积运算方法,包括:移动一卷积运算窗;从数据串流取得前一轮卷积运算还未处理的数据;基于卷积运算窗的滤波器系数对从卷积运算模块内留存的数据以及数据串流取得的数据进行本轮卷积运算;以及留存本轮卷积运算的部分数据于卷积运算模块内以供次一轮卷积运算。
在一实施例中,卷积运算方法进一步包括对本轮卷积运算的结果进行卷积神经网络的一后续层的部分运算。
在一实施例中,卷积运算窗移动的步幅小于卷积运算窗的最短宽度。
在一实施例中,卷积运算方法进一步包括:决定在一低规模卷积模式以及一高规模卷积模式其中一个之中进行卷积运算;当在低规模卷积模式中,将各输入信道中对应顺序的各卷积运算的结果交错加总以各别输出一加总结果。
在一实施例中,卷积运算方法进一步包括对卷积运算的结果进行池化运算。
在一实施例中,池化运算为最大值池化或平均池化。
承上所述,因卷积运算装置的各卷积单元于卷积运算后保留部分的当前数据,缓冲装置从内存取得多个新数据并将新数据输入至卷积单元,新数据不与当前数据重复,因此卷积运算的处理效率得以提升,适合用于数据串流的卷积运算。因此,当用于卷积运算及连续地平行运算的处理数据时,可具有优异的运算性能和低功耗表现,并且能够处理数据串流。
附图说明
图1为依据本发明一实施例的一卷积运算装置的区块图。
图2为图1的卷积运算装置对一二维数据进行卷积运算的示意图。
图3为图1的卷积运算模块的卷积单元的示意图。
图4为图1所示的卷积运算装置的部分示意图。
图5为依据本发明一实施例卷积单元的功能方块图。
具体实施方式
以下将参照相关附图,说明依本发明较佳实施例的一种卷积运算装置,其中相同的组件将以相同的参照符号加以说明。
请先参考图1所示,图1为依据本发明一实施例的一卷积运算装置的区块图。卷积运算装置包括一内存1、一缓冲装置2、一卷积运算模块3、一交错加总单元4、一加总缓冲单元5、一系数截取控制器6以及一控制单元7。卷积运算装置可用在卷积神经网络(convolutionalneuralnetwork,cnn)的应用。
内存1储存待卷积运算的数据或数据,可例如为影像、视频、音频、统计、卷积神经网络其中一层的数据等等。以影像数据来说,其例如是像素(pixel)数据;以视频数据来说,其例如是视频视框的像素数据或是移动向量、或是视频中的音讯;以卷积神经网络其中一层的数据来说,其通常是一个二维数组数据,以影像数据而言,则通常是一个二维数组的像素数据。另外,在本实施例中,系以内存1为一静态随机存取内存(staticrandom-accessmemory,sram)为例,其除了可储存待卷积运算的数据或数据之外,也可以储存卷积运算完成的数据或数据,并且可以具有多层的储存结构并分别存放待运算与运算完毕的数据,换言之,内存1可做为如卷积运算装置内部的高速缓存(cachememory)。
实际应用时,全部或大部分的数据可先储存在其它地方,例如在另一内存中,另一内存可选择如动态随机存取内存(dynamicrandomaccessmemory,dram)或其它种类的内存。当卷积运算装置要进行卷积运算时,再全部或部分地将数据由另一内存加载至内存1中,然后通过缓冲装置2将数据输入至卷积运算模块3来进行卷积运算。若输入的数据是串流数据,内存1随时会写入最新的串流数据以供卷积运算。
缓冲装置2耦接有内存1、卷积运算模块3以及部分加总缓冲单元5。并且,缓冲装置2也与卷积运算装置的其它组件进行耦接,例如交错加总单元4以及控制单元7。此外,对于影像数据或视频的视框数据运算来说,处理的顺序是逐行(column)同时读取多列(row),因此在一个时序(clock)中,缓冲装置2系从内存1输入同一行不同列上的数据,对此,本实施例的缓冲装置2系作为一种行缓冲(columnbuffer)的缓冲装置。欲进行运算时,缓冲装置2可先由内存1截取卷积运算模块3所需要运算的数据,并于截取后将这些数据调整为可顺利写入卷积运算模块3的数据型式。另一方面,由于缓冲装置2也与加总缓冲单元5耦接,加总缓冲单元5运算完毕后的数据,也将透过缓冲装置2暂存重新排序(reorder)后再传送回内存1储存。换言之,缓冲装置2除了具有行缓冲的功能之外,其还具有类似中继暂存数据的功能,或者说缓冲装置2可做为一种具有排序功能的数据缓存器。
值得一提的是,缓冲装置2还包括一内存控制单元21,当缓冲装置2在进行与内存1之间的数据截取或写入时可经由内存控制单元21控制。另外,由于其与内存1之间具有有限的一内存存取宽度,或又称为带宽或频宽(bandwidth),卷积运算模块3实际上能进行得卷积运算也与内存1的存取宽度有关。换言之,卷积运算模块3的运算效能会受到前述存取宽度而有所限制。因此,如果内存1的输入有频颈,则卷积运算的效能将受到冲击而下降。
卷积运算模块3具有多个卷积单元,各卷积单元基于一滤波器以及多个当前数据进行一卷积运算,并于卷积运算后保留部分的当前数据。缓冲装置2从内存1取得多个新数据,并将新数据输入至卷积单元,新数据不与当前数据重复,新数据例如是前一轮卷积运算还未用到但是本轮卷积运算要用到的数据。卷积运算模块3的卷积单元基于滤波器、保留的当前数据以及新数据进行次轮卷积运算。交错加总单元4耦接卷积运算模块3,依据卷积运算的结果产生一特征输出结果。加总缓冲单元5耦接交错加总单元4与缓冲装置2,暂存特征输出结果;其中,当指定范围的卷积运算完成后,缓冲装置2从加总缓冲单元5将暂存的全部数据写入到内存1。
系数截取控制器6耦接卷积运算模块3,而控制单元7则耦接缓冲装置2。实际应用时,对于卷积运算模块3而言,其所需要的输入来源除了数据本身以外,还需输入有滤波器(filter)的系数,始得进行运算。于本实施例中所指即为3×3的卷积单元数组30的系数输入。系数截取控制器6可藉由直接内存存取dma(directmemoryaccess)的方式由外部的内存,直接输入滤波器系数。除了耦接卷积运算模块3之外,系数截取控制器6还可与缓冲装置2进行连接,以接受来自控制单元7的各种指令,使卷积运算模块3能够藉由控制单元7控制系数截取控制器6,进行滤镜系数的输入。
控制单元7可包括一指令译码器71以及一数据读取控制器72。指令译码器71系从数据读取控制器72得到控制指令并将指令译码,藉以得到目前输入数据的大小、输入数据的行数、输入数据的列数、输入数据的特征编号以及输入数据在内存1中的起始地址。另外,指令译码器71也可从数据读取控制器72得到有关滤镜的种类信息以及输出特征的编号,并输出适当的空置讯号到缓冲装置2。缓冲装置2则根据指令译码后所提供的信息来运行,也进而控制卷积运算模块3以及加总缓冲单元5的运作,例如数据从内存1输入到缓冲装置2以及卷积运算模块3的时序、卷积运算模块3的卷积运算的规模、数据从内存1到缓冲装置2的读取地址、数据从加总缓冲单元5到内存1的写入地址、卷积运算模块3及缓冲装置2所运作的卷积模式。
另一方面,控制单元7则同样可藉由直接内存存取dma的方式由外部之内存提取所需的控制指令及卷积信息,指令译码器71将指令译码之后,这些控制指令及卷积信息由缓冲装置2截取,指令可包含移动窗的步幅大小、移动窗的地址以及欲提取特征的影像数据行列数。
加总缓冲单元5耦接交错加总单元4,加总缓冲单元5包括一部分加总区块51以及一池化区块52。部分加总区块51暂存交错加总单元4输出的数据。池化区块52对暂存于部分加总区块51的数据进行池化运算。池化运算为最大值池化或平均池化。
举例来说,加总缓冲单元5可将经由卷积运算模块3的卷积计算结果及交错加总单元4的输出特征结果予以暂存于部分加总区块51。接着,再透过池化区块52对暂存于部分加总区块51的数据进行池化(pooling)运算,池化运算可针对输入数据某个区域上的特定特征,取其平均值或者取其最大值作为概要特征提取或统计特征输出,此统计特征相较于先前的特征而言不仅具有更低的维度,还可改善运算的处理结果。
须说明者,此处的暂存,仍系将输入数据中的部分运算结果相加(partialsum)后才将其于部分加总区块51之中暂存,因此称其为部分加总区块51与加总缓冲单元5,或者可将其简称为psum单元与psumbuffer模块。另一方面,本实施例的池化区块52的池化运算,系采用最大池化(maxpooling)的方式取得统计特征输出,在别的实施态样中,也可选择平均池化(avgpooling)的计算方式取得统计特征输出,端看使用需求决定何种池化方式。待所输入的数据全部均被卷积运算模块3及交错加总单元4处理计算完毕后,加总缓冲单元5输出最终的数据处理结果,并同样可透过缓冲装置2将结果回存至内存1,或者再透过内存1输出至其它组件。与此同时,卷积单元数组30与交错加总单元4仍持续地进行数据特征的取得与运算,以提高卷积运算装置的处理效能。
卷积运算装置可包括多个卷积运算模块3,卷积运算模块3的卷积单元以及交错加总单元4系能够选择性地操作在一低规模卷积模式以及一高规模卷积模式。在低规模卷积模式中,交错加总单元4配置来对卷积运算模块3中对应顺序的各卷积运算的结果交错加总以各别输出一加总结果。在高规模卷积模式中,交错加总单元4将各卷积单元的各卷积运算的结果交错加总作为输出。
举例来说,控制单元7可接收一控制讯号或模式指令,并且根据这个控制讯号或模式指令来决定其它模块以及单元要在哪一种模式运算。这个控制讯号或模式指令可从其它控制单元或处理单元而得。
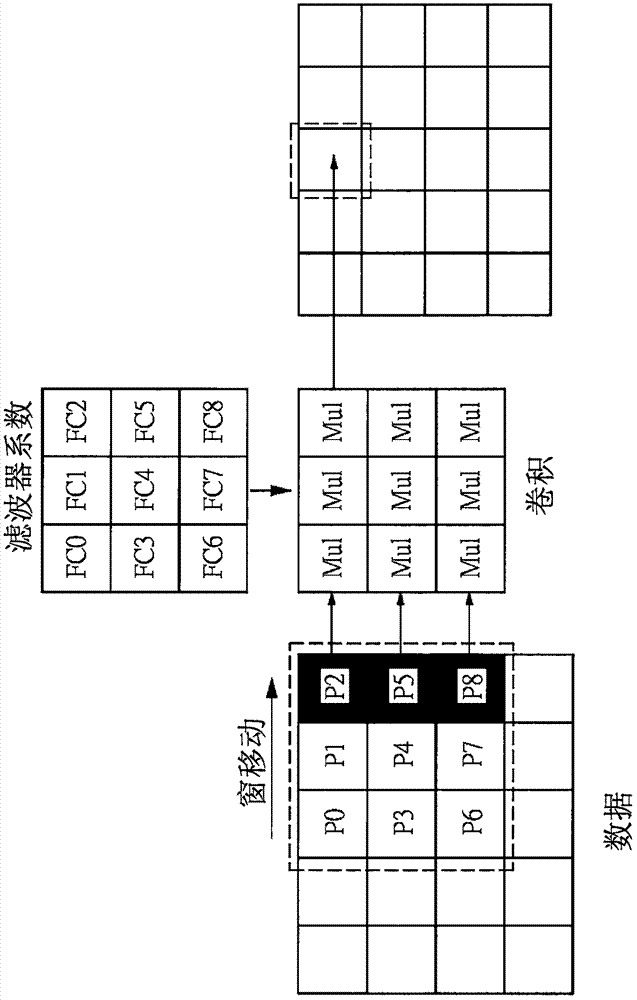
请参考图2,图2为图1的卷积运算装置对一二维数据进行卷积运算的示意图。二维数据具有多行多列,其例如是影像,于此仅示意地显示其中5×4的像素。一3×3矩阵大小的滤波器用于二维数据的卷积运算,滤波器具有系数fc0~fc8,滤波器移动的步幅小于滤波器的最短宽度。滤波器的规模与移动窗(slidingwindow)或卷积运算窗相当。移动窗可在5×4的影像上间隔移动,每移动一次便对窗内对应的数据p0~p8进行一次3×3卷积运算,卷积运算后的结果可称为特征值。移动窗s每次移动的间隔称为步幅(stride),由于步幅(stride)的大小并不会超过移动窗s(slidingwindow)的大小或是卷积运算的尺寸(convolutionsize),因此以本实施例的移动窗步幅来说,将会小于3个像素的移动距离。而且,相邻的卷积运算往往会有重迭的数据。以步幅等于1来说,数据p2、p5、p8是新数据,数据p0、p1、p3、p4、p6、p7是前一轮卷积运算已经输入过的数据。对于一般卷积神经网络的应用来说,常用的移动窗尺寸为1×1、3×3、5×5、7×7不等,其中又以本实施例的移动窗尺寸较为常用(3×3)。
图3为图1的卷积运算模块的卷积单元的示意图。请参照图3所示,卷积单元具有3×3数组的9个乘法器mul_0~mul_8,各乘法器具有一数据输入、一滤波器系数输入以及一乘法输出out,数据输入及滤波器系数输入是各乘法器的二个乘法运算输入。各乘法器的输出out分别连接到加法器的输入#0~#8,加法器将各乘法器的输出相加后产生一卷积输出out。进行完一轮的卷积运算后,乘法器mul_0、mul_3、mul_6会将当下在其内的数据(本轮输入的q0、q1、q2)输入到次一级的乘法器mul_1、mul_4、mul_7,乘法器mul_1、mul_4、mul_7会将当下在其内的数据(相当于前一轮输入的q0、q1、q2)输入到次一级的乘法器mul_2、mul_5、mul_8,这样就可以把部分已经输入到卷积单元内的数据保留以供次一轮的卷积运算。乘法器mul_0、mul_3、mul_6则在次一轮接收新数据q0、q1、q2。前一轮、本轮、以及次一轮的卷积运算彼此间隔至少一个频率。
举例来说,在一般的情况下,滤波器系数不需要时常更新,系数fc0~fc8输入到乘法器mul_0~mul_8后可以留存在乘法器mul_0~mul_8中以利乘法运算;或者是系数fc0~fc8要一直持续输入到乘法器mul_0~mul_8。
在别的实施态样中,卷积单元也可以是不同于3×3大小的数组,例如5×5、7×7大小的数组,本发明并不限制。而卷积单元pe亦可分别平行处理不同组输入数据的卷积运算。
请参照图4所示,图4为图1所示的卷积运算装置的部分示意图。系数截取控制器6系透过滤波器系数fc以及控制讯号ctrl的线路耦接卷积运算模块3中的各个3×3卷积单元。当缓冲装置2取得指令、卷积信息以及数据后,其控制各卷积单元进行卷积运算。
交错加总单元4耦接卷积运算模块3,由于卷积运算模块3可针对输入数据的不同特征对其进行运算,并输出特征运算结果。而对于多个特征的数据写入来说,卷积运算模块3则可对应输出多笔的运算结果。交错加总单元4的功能则在于可将卷积运算模块3多笔的运算结果,结合后再得出一输出特征结果。当交错加总单元4取得输出特征结果后,再将该输出特征结果传送至加总缓冲单元5,以利进行下一阶段的处理。
举例来说,卷积神经网络具有多个运算层,例如卷积层、池化层等,卷积层以及池化层的层数可以是多层,各层的输出可以当作另一层或后续层的输入,例如第n层卷积层的输出是第n层池化层的输入或是其它后续层的输入,第n层池化层的输出是第n+1层卷积层的输入或是其它后续层的输入,第n层运算层的输出可以是第n+1层运算层的输入。
为了提升运算效能,进行第n层运算层的运算时,可以视运算资源(硬件)的使用情况来进行第n+i(i>0,n、i为自然数)层运算层的部分运算,有效运用运算资源并且能降低实际在第n+i层运算层时的运算量。
在本实施例中,在一种运算情况下,例如3×3卷积运算,卷积运算模块3进行卷积神经网络的某一层卷积层的运算,交错加总单元4没有进行卷积神经网络的后续层的部分运算,加总缓冲单元5进行卷积神经网络的同一阶池化层的运算。在另一种运算情况下,例如1×1卷积运算,卷积运算模块3进行卷积神经网络的某一层卷积层的运算,交错加总单元4进行卷积神经网络的后续层的部分运算,部分运算例如是相加加总,加总缓冲单元5进行卷积神经网络的同一阶池化层的运算。在其它实施例中,加总缓冲单元5除了进行池化层的运算,也可进行卷积神经网络的后续层的部分运算。前述的部分运算例如是将后续层的加总运算、平均运算、取最大值运算或其它运算等先在卷积神经网络的目前这一层做运算。
图5为依据本发明一实施例卷积单元的功能方块图,如图5所示,卷积单元9包括9个处理单位pe0~pe8(processengine)、一地址译码器91及一加法器92。卷积单元9可以作为前述卷积单元。
在3×3卷积运算模式下,待卷积运算的输入数据系经由线路data[47:0]输入至处理单位pe0~pe2,处理单位pe0~pe2会将当前频率的输入数据在之后的频率输入至处理单位pe3~pe5以供下一轮卷积运算,处理单位pe3~pe5会将当前频率的输入数据在之后的频率输入至处理单位pe6~pe8以供下一轮卷积运算。3×3滤波器系数透过线路fc_bus[47:0]输入至处理单位pe0~pe8。在步幅为1时,3个新数据会输入至处理单位,已经输入的6个旧数据会移到其它处理单位。执行卷积运算时,处理单位pe0~pe8透过地址译码器91将选定地址的滤波器系数与输入至处理单位pe0~pe8的输入数据做乘法运算。当卷积单元30进行3×3卷积运算时,加法器92会将各乘法运算的结果相加以得到卷积运算的结果作为输出psum[35:0]。
当卷积单元9进行1×1卷积运算时,待卷积运算的输入数据系经由线路data[47:0]输入至处理单位pe0~pe2,三个1×1滤波器系数透过线路fc_bus[47:0]输入至处理单位pe0~pe2。在步幅为1时,3个新数据会输入至处理单位。执行卷积运算时,处理单位pe0~pe2透过地址译码器91将选定地址的滤波器系数与输入至处理单位pe0~pe2的输入数据做乘法运算。当卷积单元9进行1×1卷积运算时,加法器92会直接将处理单位pe0~pe2的卷积运算的结果作为输出pm_0[31:0]、pm_1[31:0]、pm_2[31:0]。另外,由于处理单位pe3~pe8没有实际参与卷积运算,这些处理单位pe3~pe8可以先关闭以节省电力。另外,虽然卷积单元30有三个1×1卷积运算的输出,但可以只有其中二个输出连接到交错加总单元4;或是三个1×1卷积运算的输出都连接到交错加总单元4,藉由控制处理单位pe0~pe2的关闭与否来决定输出到交错加总单元4的1×1卷积运算结果的数量。
待影像的所有数据已分别由卷积运算模块3、交错加总单元4及加总缓冲单元5运算完毕后,且最终的数据处理结果也已回存至内存1时,将由缓冲装置2传送一停止讯号至指令译码器71与控制单元7,通知控制单元7目前已运算完毕且等候下一个处理指令。
另外,一种数据串流的卷积运算方法包括以下步骤:移动一卷积运算窗;从数据串流取得前一轮卷积运算还未处理的数据;基于卷积运算窗的滤波器系数对从卷积运算模块内留存的数据以及数据串流取得的数据进行本轮卷积运算;留存本轮卷积运算的部分数据于卷积运算模块内以供次一轮卷积运算;以及再回到移动卷积运算窗的步骤再依序进行后续的步骤。例如,卷积运算模块包括卷积运算单元或数组、或是卷积运算模块包括能够进行卷积运算的数学运算单元以及内部缓存器,内部缓存器可留存本轮卷积运算的部分数据于卷积运算模块内以供次一轮卷积运算。数据串流储存在内存中,卷积运算窗移动的步幅小于卷积运算窗的最短宽度。
另外,卷积运算方法进一步包括对本轮卷积运算的结果进行卷积神经网络的一后续层的部分运算,例如将后续层的加总运算、平均运算、取最大值运算或其它运算等先在卷积神经网络的目前这一层做运算。
另外,卷积运算方法进一步包括:决定在一低规模卷积模式以及一高规模卷积模式其中一个之中进行卷积运算;当在低规模卷积模式中,将各输入信道中对应顺序的各卷积运算的结果交错加总以各别输出一加总结果。
另外,卷积运算方法进一步包括对卷积运算的结果进行池化运算。池化运算为最大值池化或平均池化。
卷积运算方法可应用或实施在前述实施例的卷积运算装置,相关的变化及实施方式故于此不再赘述。卷积运算方法亦可应用或实施在其它计算装置。举例来说,数据串流的卷积运算方法可用在能够执行指令的处理器,配置以执行卷积运算方法的指令是储存在内存,处理器耦接内存并执行这些指令以进行卷积运算方法。例如,处理器包括高速缓存、数学运算单元以及内部缓存器,高速缓存储存数据串流,数学运算单元能够进行卷积运算,内部缓存器可留存本轮卷积运算的部分数据于卷积运算模块内以供次一轮卷积运算。
综上所述,因卷积运算装置的各卷积单元于卷积运算后保留部分的当前数据,缓冲装置从内存取得多个新数据并将新数据输入至卷积单元,新数据不与当前数据重复,因此卷积运算的处理效率得以提升,适合用于串流数据的卷积运算。因此,当用于卷积运算及连续地平行运算的处理数据时,可具有优异的运算性能和低功耗表现,并且能够处理数据串流。
以上所述仅为举例性,而非为限制性者。任何未脱离本发明的精神与范畴,而对其进行的等效修改或变更,均应包含于后附的权利要求中。
- 还没有人留言评论。精彩留言会获得点赞!