一种基于用户名信息的密码猜测集生成方法及密码破解方法与流程
本发明涉及一种基于用户名信息的密码猜测集生成方法及密码破解方法。
背景技术:
长时间以来,破解密码使用传统的暴力破解方法,但这种方法没有对密码进行深入的分析,以至于效果和效率都不尽如人意。
在一些新方法中,自然语言处理的思想和工具被应用到密码分析和破解当中。这种方法将密码也视为某种形式的自然语句,由一系列片段按照一定的层次结构组合而成。出现在密码中的片段通常是字典中的单词、日期或者其他有意义的字符串,而这些片段的组合结构常常体现出某些固定模式。可以使用NLTK(Natural Language Toolkit)以及WordNet工具对密码进行分词、词性标注以及语义类别标注。然后,利用自然语言处理中概率上下文无关文法(Probability Context-Free Grammars,PCFGs)学习生成密码的语法规则,并按照概率降序生成密码猜测集。但是,当被攻击网站含有较多弱密码时,这种方法被证明破解效率较低。另外,当被用于破解中文网站密码时,该方法破解效率也较差,原因在于其分词系统并不能有效为中文拼音分词。
这种方法的主要问题在于未能充分分析密码中的语义内容以及各语义类别之间的语法,也未能给所使用的字典中的单词分配合适的概率。
技术实现要素:
本发明的目的是将自然语言处理领域的思想和工具运用到密码分析和破解领域中来,对用户名分解分析,提取片段和结构特征,利用用户名和密码的片段相似性和结构相似性,理解密码的构成语义,加快密码破解速度,是一种基于用户名信息的密码猜测集生成方法及密码破解方法。
为了利用用户名中包含的信息来提高密码破解效率,本发明提供了一种基于PCFGs并能提取用户名密码间语义相似性的密码猜测生成器,简称基于语义相似性的密码猜测生成器。
本发明的技术方案为:
一种基于用户名信息的密码猜测集生成方法,其步骤为:
1)对泄漏数据训练集中的用户名、密码分别进行分词和语义结构标注,计算用户名、密
码的语义相似性;其中,所述语义相似性包括语义结构相似性和语义片段相似性;
2)将该语义相似性应用到PCFGs语法中,即基于语义相似性构建PCFGs语法;
3)根据步骤2)构建的PCFGs语法,按照概率降序生成密码猜测集。
一种基于用户名信息的密码破解方法,其步骤为:
1)对泄漏数据训练集中的用户名、密码分别进行分词和语义结构标注,计算用户名、密码的语义相似性;其中,所述语义相似性包括语义结构相似性和语义片段相似性;
2)将该语义相似性应用到PCFGs语法中,即基于语义相似性构建PCFGs语法;
3)根据步骤2)构建的PCFGs语法,按照概率降序生成密码猜测集;
4)根据该密码猜测集进行密码破解。
进一步的,基于语义相似性构建PCFGs语法的方法为:根据用户名、密码的语义结构相似性,得到不同语义结构的用户名所选用的分布不同的密码结构,将密码结构作为PCFGs语法的非终端结构;根据用户名、密码的语义片段相似性,选取用户名中的语义片段加入到用来生成密码的PCFGs语法的终端词集合中,得到PCFGs语法的终端词集合。
进一步的,对于密码中的片段,如果该片段出现在泄漏数据训练集的用户名中,则将该片段在泄漏数据训练集中的频数乘以一个概率系数α,并将扩大α倍的频数累加到所述终端词集合中该片段原有的频数上作为该片段的新频数;若所述终端词集合中不含该片段,则将该片段及其频数信息一起加入到所述终端词集合中;然后更新所述终端词集合中终端词的概率分布。
进一步的,所述步骤3)的实现方法为:为每一非终端结构建立一个优先级队列,该优先级队列用于存储对应的非终端结构按概率降序生成的密码猜测;然后对所有优先级队列的第一个元素进行遍历,找出概率最大的密码,将该密码出队列输出到密码猜测集,再进行下一次密码查找,直到密码猜测集中密码数量达到规定值。
进一步的,对用户名、密码按照语义类别分词和语义结构标注;其中,所述语义类别包括拼音姓名、拼音姓名缩写、拼音名、拼音姓、拼音短语、其他拼音、英文短语、英文姓名、英文单词、其他字母、数字日期、其他数字、单个字符重复、字符串重复、键盘等间距跳跃、键盘上同一行字符相邻、键盘上不同行字符相邻和其他特殊符号。
进一步的,所述语义片段相似性的衡量指标包括#1至#7七项衡量指标;其中,#1指标表示用户名中含有所述语义类别;#2指标表示用户密码中含有该语义类别;#3指标表示用户名和密码中该语义类别的字符内容完全相同;#4指标代表在用户名和密码中该语义类别的字符内容相同但有大小写区别;#5指标代表用户名字符是密码字符的子串;#6指标代表密码是用户名的子串;#7指标代表满足#2指标却不满足#3至#6指标。
进一步的,所述泄漏数据训练集选自于互联网公开泄漏数据集。
本发明主要包含两个方面:(1)首先对互联网公开泄漏数据集进行用户名密码相似性的分析和提取;(2)改进PCFGs算法,将用户名和密码间语义结构和片段相似性利用在密码猜测生成中,并按概率严格降序生成密码猜测集。
通常情况下,泄露的密码集中通常还伴随着其他的一些用户信息的泄露,比如用户名。用户名被看做代表用户在网络世界中身份的一种抽象符号,它和对应的密码一起构成了网络世界中保护用户隐私的一道屏障。用户名的创建可以体现出用户在创建网络口令时的一些习惯和倾向。在对泄露密码集进行分析后我们发现,中文在线社区用户在用户名和密码中都倾向于使用拼音和数字,而其中拼音姓名在用户名中出现的十分普遍。例如:一位用户的用户名是“xiaoming19860805”,密码是“xm0805”(xm是xiaoming的拼音缩写)。这位用户在其用户名中使用了拼音姓名,并且将对应缩写用在了密码中。用户名中出现了日期“19860805”,而密码中则使用了部分日期“0805”。而从结构上来说,该用户的用户名和密码都使用了拼音姓名后加日期的模式。由于一组用户名和密码是由同一个用户所创建,这种习惯和倾向很可能也被使用在密码的创建中,所以深入分析用户名的构成可以帮助我们更好的了解密码的创建过程,从而更有效的进行密码破解。
本发明以PCFG语法为基础,提出了能够提取并利用用户名和密码间语义结构和片段相似性的密码生成算法。该发明密码破解方法流程如图1,其包括以下内容:
1)对用户名、密码分别进行了分词和语义结构标注,给出了用户名与密码语义相似性的衡量指标。定义了两种语义相似性:语义结构相似性和语义片段相似性;
2)基于语义相似性构建PCFGs语法,严格按照概率降序生成密码猜测集;
4)根据该密码猜测集进行密码破解。
基于大规模公开数据集上的实验结果,证明了提出的基于语义相似性的密码猜测生成器的有效性。
针对中文拼音、英文单词、数字和特殊符号定义了18种语义类别(如表1)。基于Contemporary Corpus of American English语料集、紫光拼音输入法拼音字典、韦氏英文大字典以及31个提取数字日期的正则表达式对用户名和密码进行分词,之后对分词结果进行了语义类别标注。
表1为18种语义类别及其简化表示
语义相似性分析:针对语义结构相似性,对用户名按照语义结构分组,统计不同组用户其密码语义结构的选择情况,得到不同用户名密码结构的概率分布。进一步对用户名及密码进行语义片段相似性分析,定义了#1至#7七种衡量语义片段相似性的指标,按照每个指标计算其相应的比例见表2;其中,#1指标表示用户名中含有左栏语义类别,其比例为符合指标的用户数量占所有用户数量的百分比,#2指标表示用户密码中也含有该语义类别,其比例为符合指标的用户数量占用户名中含有该语义类别用户数量的百分比。对满足#2指标的用户,即用户名和密码中都含有相应的语义类别,#3至#7四个指标对其用户名和密码内容进行了进一步的相似性分析。#3指标表示用户名和密码中该语义类别的字符内容完全相同,其比例为符合指标的用户数量占满足#2指标用户数量的百分比;#4指标代表在用户名和密码中该语义类别的字符内容只有大小写的区别,其比例为符合指标的用户数量占满足#2指标用户数量的百分比;#5指标代表用户名字符是密码字符的子串,其比例为符合指标的用户数量占满足#2指标用户数量的百分比;#6指标反之,代表密码是用户名的子串,其比例为符合指标的用户数量占满足#2指标用户数量的百分比;#7指标代表满足#2指标却不满足#3至#6指标,其比例为符合指标的用户数量占满足#2指标用户数量的百分比。
表2为泄漏数据集语义片段相似性的7种指标分析
本发明基于语义相似性的密码猜测生成器主要包括以下几个步骤:
1)对用户名和密码都按照语义类别分词,得到用户名和密码的结构和片段,分别统计用户名的结构和片段、密码的结构和片段的频数后除以各自的总数计算概率。
2)将语义相似性应用到PCFGs语法中:针对语义结构相似性,训练得到不同语义结构的用户名所选用的分布不同的密码结构,在生成密码猜测时,按照待破解的用户名结构调整为其对应的密码结构,得到PCFGs的非终端结构;针对语义片段相似性,将步骤1得到的用户名的语义片段与密码的语义片段进行合并,并对用户名中的终端词概率设置可调节的权重参数,得到PCFGs的终端词集合;权重参数是实验得出来的,比如遍历1到500,选取最好实验效果的参数。
3)在PCFGs语法建立完成之后,下一步工作即按概率降序生成密码猜测集。本发明设计了一种新的密码猜测生成函数Generating_Guesses。主要思想是为每一个非终端结构建立一个优先级队列(priority queue),该优先级队列可为对应的非终端结构严格按概率降序生成密码猜测并储存,在最终生成密码猜测时,对所有优先级队列的第一个元素(即该队列中概率最大的密码)进行遍历,找出概率最大的密码,将该密码出队列输出到密码猜测集,再进行下一次密码查找,直到密码猜测集中密码数量达到规定值,猜测集便构建完成。
上述步骤(2)“将语义相似性应用到PCFGs语法中”是本发明的核心。下面将对语义结构相似性和语义内容相似性的应用进行详细描述。
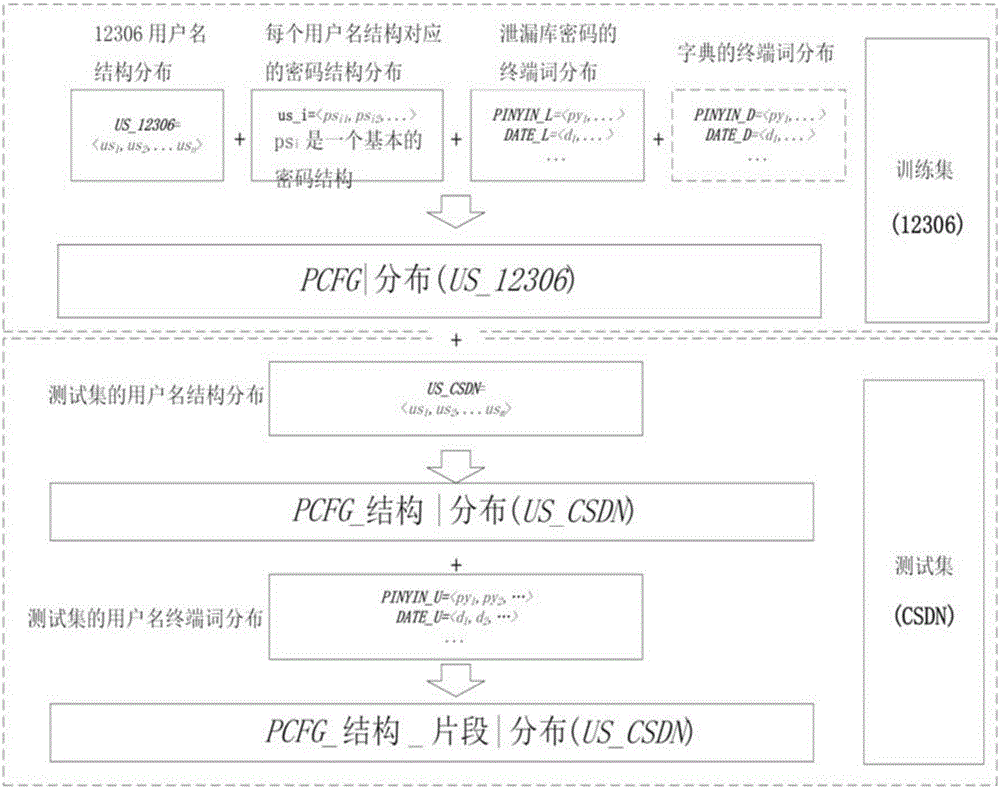
语义结构相似性是指:不同用户名结构的用户在密码结构选择上存在差异,使用相同用户名结构的用户倾向于选择相似的密码结构;用户在其用户名和密码间倾向于使用相同的语义类别,甚至用户名和密码有着完全相同的语义结构。在进行交叉网站攻击时,攻击者拥有泄露网站A的用户名和密码,以及被攻击网站B的用户名。所以为应用语义结构相似性,在A数据集上训练完成的PCFGs应利用B网站的用户名信息,对用户名推导规则和概率做修正:用户名非终端结构概率分布应在B网站用户名数据上进行训练。而由用户名非终端结构推导出密码的非终端结构概率分布,以及密码的终端词语概率分布则在数据集A上完成。因为无法获取B网站的密码信息,做这种训练时基于这样的语义相似性结论:使用相同用户名结构的用户倾向于选择相似的密码结构。则A网站某类用户其密码的使用情况能够一定程度上反映B网站该类用户密码的使用情况。例如:将在12306数据集上训练好的PCFGs记为PCFGs|Dist.(US_12306),利用12306的泄露数据集信息对CSDN进行攻击时,用户名非终端结构概率分布,用户名终端词语的概率分布应该使用CSDN用户名数据重新计算。所得到的新PCFGs记为PCFGs|dist(US_CSDN),流程见图2。
定义PWi=<psi1,psi2,...>。PWi代表用户名结构为usi的用户所使用的密码结构的集合。根据语义结构相似性,相同用户名结构的用户倾向于选择相似的密码结构,可以认定用户名结构为usi的用户其密码结构服从usi的密码结构分布psi。则若用户名结构usi在被攻击网站用户名中使用频率高于训练集中频率,相关的密码结构psij将被赋予更高的概率。具体的密码结构概率计算公式如下(以12306攻击CSDN为例):
F(psj)|dist(USCSDN)=∑iF(usi)*F(psj|(US_12306,usi)) (1)
在公式(1)中,F(.)表示概率函数,F(psj|(US_12306,usi))表示在12306数据集中用户名结构为usi的用户群,选择密码结构psj的概率(即优先级队列中非终端结构的概率),psj为全局的密码结构分布。
语义片段相似性是指用户倾向于在用户名和密码中使用相同或者相似的语义内容。首先,将训练集用户名中的语义片段词,其频数乘以一个概率系数α,并将扩大α倍的频数累加到密码终端词集合∑集中该词原有的频数上作为该词的新频数。若密码终端词集合∑中不含该语义片段词,则该词作为一个新的终端词,连同频数信息一起加入到∑中。α值越大,代表密码终端词集合Σ中该词被增加的频数越大,导致在生成密码时该词的频率被扩大。上述操作使得密码终端词集合Σ词语数量和频数都产生了变化,之后进行概率归一化可得到最终集合Σ中终端词的概率分布。
与现有技术相比,本发明的效果:
为评估本发明借助用户名密码语义相似性的破解方法,我们与Weir构建的传统PCFG语法以及目前主流密码破解软件John the Ripper在不同数据集上进行了对比实验。实验数据集来源包含CSDN、新浪微博、嘟嘟牛、178、7k7k、17173泄露账号密码集共计五千一百万账户。由于计算机性能限制,每个实验中的密码猜测次数限定为1亿次。
图3给出了语义结构相似性对密码破解效率的影响。所有方法都采用CSDN泄露密码集作为训练集,并对新浪微博密码集进行攻击。在前1千万次猜测中,虽然最终猜出的密码比例相近,本发明方法Sim_PCFG_on_LD的猜测成功率增长速度明显高于Weir的PCFG(Weir_PCFG_on_LD)以及John the Ripper软件(JtR_with_Mangling)。要猜出31.3%的密码,方法JtR_with_Mangling、Weir_PCFG_on_LD以及本发明Sim_PCFG_on_LD所需的猜测次数依次为:1.73*106,2.32*106以及1.30*106。本实验说明,使用了语义结构相似性的方法能够提高密码破解的速度。
图5为比较概率系数α的实验结果图,同样采用CSDN泄露密码集作为训练集,并对新浪微博密码集进行攻击。选取α值为1、4、15和500的结果进行展示。从图中可以看出,当α值为4时,在效率和效果方面都具有最好的性能。
图4为语义片段相似性对密码破解效率影响的实验图。17173和新浪微博的泄露密码集分别作为被攻击的目标,所有方法分别在其它四个数据集上做训练后对17173及新浪微博进行交叉攻击。从针对17173进行的攻击图中可以看出,根据所选训练集的不同,利用了两种语义相似性的方法Sim_PCFG_on_LDU4比Weir的PCFG方法猜测成功的密码数提高了大约14.0%至25.5%,比John the Ripper提高了大约55.3%至81.6%。在对新浪微博进行的四个攻击中,方法Sim_PCFG_on_LDU4在三个攻击里的破解效率都优于Weir和John the Ripper。例外发生在用嘟嘟牛网站泄露的密码做训练集的攻击中。在对比了嘟嘟牛和新浪微博的泄露密码集之后发现,二者数据集高达有88.8%的相同用户名和密码。如此高的重合度使得Weir的方法在该攻击中效率较高,因为Weir的PCFG方法相较方法Sim_PCFG_on_LDU4所生成的不同于训练集的新密码数量较少,从而密码猜测集的分布跟原始训练集更相近。
附图说明
图1为本发明的密码破解方法流程图;
图2为基于语义相似性的PCFG(Sim_PCFG)在12306数据集上的训练过程;
图3为语义片段相似性对密码破解效率的影响;
图4为不同训练集对17173和新浪微博进行攻击
(a)训练集178与测试集17173,(b)训练集7k7k与测试集17173,(c)训练集csdn与测试集17173,(d)训练集dodonew与测试集17173,(e)训练集178与测试集sinaweibo,(f)训练集7k7k与测试集sinaweibo,(g)训练集csdn与测试集sinaweibo,(h)训练集dodonew与测试集sinaweibo;
图5为不同概率系数α值的性能比较。
具体实施方式
以CSDN泄漏密码库作为训练集,12306泄漏数据库作为目标集,LDU4方法(概率系数α值为4)为例:
1)从CSDN库提取密码的结构S1和片段T1,从12306库提取用户名结构S2和片段T2;
2)将S2添加到S1中,S1直接加上S2中每个结构的频数,再全局统计每个结构的概率;
3)将T2添加到T1中,T1直接加上T2中每个终端词的频数乘以4,再全局统计每个终端词的概率;
4)将Contemporary Corpus of American English语料集、紫光拼音输入法拼音字典、韦氏英文大字典等字典添加到T1中。此时,生成好了PCFGs的S和T,再按概率从大到小进行排序。
S的结果举例如下:
T的结果举例如下:
5)生成全局优先级队列,计算每种结构选取最大概率终端词组合之后的概率,队列中最大的为概率最高的密码猜测。全局优先级队列中最大概率的结构为“K_CONTINUOUS”,最大概率的终端词为“123456789”,输出的第一个密码猜测的概率为0.0567154276067*0.217089432985=0.012312320020632619。接着按照概率降序依次输出密码猜测。
6)生成1亿个密码猜测集,并同时对目标集12306进行比对,查看是否能命中,每隔10000个密码猜测输出次数和命中率作为实验结果。如:
10000,0.153374333063
20000,0.177067680864
……
99990000,0.538215278411
100000000,0.538219720953。
- 还没有人留言评论。精彩留言会获得点赞!