一种蒙特卡洛逆向求解PageRank问题的加速方法与流程
本发明涉及并行计算领域,更具体地,涉及一种蒙特卡洛逆向求解PageRank问题的加速方法。
背景技术:
随着社会的进步,互联网中产生的网页数量呈现了爆炸式增长。PageRank作为搜索引擎的核心算法,它能有效地根据网页之间的链接关系,对搜索结果按重要性进行合理的排序。因此,在大量的网页中,PageRank在大规模数据处理中如何高效、鲁棒地求解显得尤为重要。此外,在很多的PageRank应用场景中,通常只有很少的页面需要被计算,例如在社交网络中检测高影响力的节点,在TrustRank方法中用于选择高质量的“种子”页面等等,如何针对这些场景对原始PageRank算法进行改良也是一个重点和难点。
目前马尔科夫蒙特卡洛求解PageRank的值主要有以下两种方法:
(1)通过模拟网页前向浏览跳转,使用马尔科夫蒙特卡洛方法来计算PageRank值。该方法与传统的确定性的Power方法相比,一是经过一轮迭代后可以近似获得相对重要的网页的估计,二是可以根据网页间结构的改变做出持续地PageRank值更新。然而自然的web图有着很多高入度的顶点,传统的PageRank方法在计算这些顶点的PageRank开销较大,Ziv Bar-Yossef等人指出在逆向的web图上计算PageRank值比原始的web图更为高效;
(2)模拟目标网页向外扩散,对转置后的图使用马尔科夫蒙特卡洛方法来逆向计算。该方法的优点就是可以只计算一个网页的PageRank值,而不需要计算所有网页的PageRank值。另外一个优点是在GPU上实现了并行化计算。然而该方法在效率性能方面有以下不足:(a)使用的伪随机序列在每个分量的求解时需要重新生成,需要一定量的开销。(b)直接利用GPU的全局内存,而没有使用GPU的共享内存作为缓存,计算速度不佳。
基于现有方法出现的问题,面对互联网数据急速增长的趋势,应该从提高马尔科夫蒙特卡洛求解PageRank的效率出发,加速处理大规模数据。
技术实现要素:
本发明提供一种提高效率的蒙特卡洛逆向求解PageRank问题的加速方法。
为了达到上述技术效果,本发明的技术方案如下:
一种蒙特卡洛逆向求解PageRank问题的加速方法,包括以下步骤:
S1:确定初始方向数,由初始方向数得到拟随机序列的方向数,然后计算得到拟随机数列;
S2:将PageRank迭代公式进行转换,得到新的迭代矩阵G和其对应的线性方程组系数矩阵A,计算矩阵A特征值极值,根据特征值的分布得到松弛因子,利用该松弛因子对PageRank迭代公式进行松弛化处理,再利用S1中得到的拟随机数列,对松弛化后的PageRank迭代公式使用马尔科夫蒙特卡洛方法进行仿真,得到求解的目标分量xi的每条马尔科夫链仿真结果;
S3:对求解的目标分量xi的每条马尔科夫链仿真结果,首先申请分配GPU共享内存进行缓存,接着在GPU共享内存中对各个仿真结果进行归约并行求和,然后将汇总的结果除以仿真的链数,求得目标分量xi的期望值。
进一步地,所述步骤S1的具体过程如下:
S11:使用T个在二元有限域GF(2)上的本原多项式,其中第i维序列使用的本原多项式为:
Pi(x)=xr+t1,ixr-1+tr-1,ix+1,
其中r为Pi的度数,t1,i,t2,i,…,tr-1,i是取值为0或1的本原多项式的系数;
S12:选取初始方向数,对于一个度数为r的本原多项式Pi有r个初始方向数:v1,i,…,vr,i,其中mj,i为一个小于2j的正奇数;
S13:由初始方向数计算出方向数,公式如下:
S14:初始化序列起始值根据求得的方向数,以及使用格雷码方法求得第i维的序列,公式如下:
进一步地,所述步骤S2中计算松弛因子并应用松弛法求解PageRank迭代公式的过程包括以下步骤:
S21:将PageRank迭代公式进行转化:
由公式得,记为x=Gx+b,得到对应的线性方程组为Ax=b。其中相关参数说明如下:x是求解的PageRank值目标向量,α是阻尼系数,M是PageRank迭代矩阵,N是结点个数,E是元素全为1的矩阵,e是元素全为1的列向量,G为αM,b为A=(I-G);
S22:计算矩阵A特征值极值,其中为A的对角矩阵的逆矩阵,得到特征值最大值λmax和特征值最小值λmin,根据求出的特征值极值算出松弛因子ω;
S23:应用松弛法求解PageRank迭代公式:
DωAx=Dωb,其中Dω为对角矩阵,对角线的元素为其中ai,j为矩阵A的元素,得到松弛化后的迭代矩阵Gω=I-DωA;
S24:使用步骤S1中得到的拟随机序列来模拟马尔科夫链,将模拟过程分配到GPU的多个线程束warp执行,线程束warp里面的每个线程执行一条马尔科夫链的随机游走,多个线程同时执行,各自求解目标分量的一个解,得到求解的目标分量xi的每条马尔科夫链仿真结果。
进一步地,所述步骤S3的具体过程如下:
S31:首先申请分配GPU共享内存,用于保存每个目标分量的一个仿真结果;
S32:将S2中计算得到的各个马尔科夫链随机游走的仿真结果存放在GPU的共享内存中,存放的位置为当前线程独有的线程id对应的共享内存数组下标;
S33:在GPU的共享内存对各个部分解进行reduce并行化求和:
首先在第一轮迭代中,根据GPU的线程块block数blockDimX将归约求解数据分为两个子集,子集大小为然后将线程id=i保存的值与线程id=i+size的值求和,结果保存到线程id=i的对应的共享内存上,接着在下一轮迭代中,将步长size减半,继续进行归约求和;
重复以上过程,直至步长为0时结束,并将最终结果sum除以马尔科夫链的数目求解期望值,即返回该期望值,并将求解结果由GPU内存复制回CPU内存。
与现有技术相比,本发明技术方案的有益效果是:
本发明使用拟随机序列代替伪随机序列进行PageRank仿真求解,拟随机序列一次生成后,可以用于每个分量的求解过程中,而使用伪随机序列则需要在每个分量的求解过程中重新生成,另外,拟随机序列可以在GPU上高效并行的生成,在随机序列的生成上可以节约不少时间;引入松弛法进行求解,通过将目标函数进行转换,并进行松弛化,减少迭代矩阵的谱半径来加快收敛速度;充分利用GPU的共享内存作为缓存,并在累积汇总每个马尔科夫链计算的结果时进行高效地reduce并行化操作,无需多次访问读取速度较慢的全局内存,从而提高效率。
附图说明
图1为本发明基于马尔科夫蒙特卡洛逆向蒙特卡洛逆向求解PageRank问题的加速方法的流程示意图;
图2为本发明生成拟随机序列的任务分配示意图;
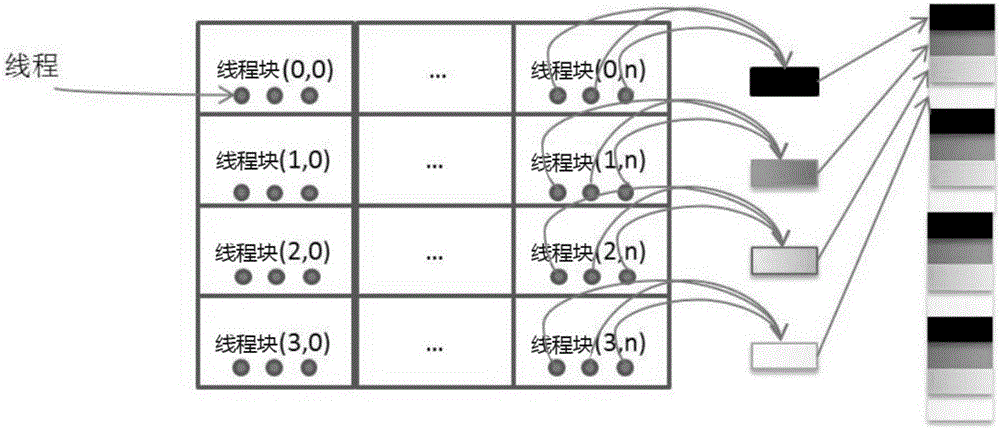
图3为本发明使用GPU求解PageRank分量结果的线程分配示意图;
图4为本发明对每个仿真结果进行并行化reduce求和示意图。
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
为了更好说明本实施例,附图某些部件会有省略、放大或缩小,并不代表实际产品的尺寸;
对于本领域技术人员来说,附图中某些公知结构及其说明可能省略是可以理解的。
下面结合附图和实施例对本发明的技术方案做进一步的说明。
实施例1
如图1所示,本发明先读取输入的图数据,然后预生成拟随机序列,接着使用松弛法对转换后的PageRank迭代公式进行预处理,并在GPU进行马尔科夫蒙特卡洛多线程并行化仿真。最后在共享内存上对目标分量xi的每个仿真结果进行并行化reduce求和。
本发明一种蒙特卡洛逆向求解PageRank问题的加速方法的实现步骤如下:
1.首先对输入的图数据进行预处理。具体步骤如下:读取图文件,将数据保存到邻接矩阵数组中,统计各个顶点的出度和入度。过滤筛选出悬停结点,将悬停结点为所在行元素置为1。根据顶点的出度值将邻接矩阵表示为所有元素非负且列和为1的马尔科夫迭代矩阵。
2.然后在GPU上生成拟随机序列。首先选取初始方向数v1,i,…,vr,i,由初始方向数应用以下公式到拟随机序列的方向数,由于在拟随机序列生成过程中,方向数需要频繁的访问,因此在实现过程中将其存储在共享内存中加快计算。如图2所示,对于拟随机序列的每一个维度,用一个block对应生成。对于第i个序列,提前生成序列前M个数,然后不断迭代生成接下来的数。
3.重新表示PageRank迭代公式并计算松弛因子。对于转化后的PageRank迭代公式,求解矩阵A的特征值极值,根据特征值极值的分布,得到松弛因子ω。
4.根据松弛因子ω以及矩阵A的对角元素计算出对角矩阵Dω,将松弛法应用到PageRank迭代公式,得到迭代矩阵Gω;
5.模拟马尔科夫链随机游走。使用生成的拟随机序列来模拟马尔科夫链,将模拟过程分配到GPU的多个warp执行,warp里面的每个线程执行一条马尔科夫链的随机游走,多个线程同时执行,各自求解目标分量的一个解,具体线程分配示意图如图3所示。
6.如图4所示,在共享内存对马尔科夫链模拟结果进行并行化求和。首先根据预先设定的马尔科夫链的数目,申请分配GPU共享内存的大小。在所有线程仿真结束后,将每一个线程id对应的求解结果保存在共享内存中。然后求解的目标分量的各个部分解进行reduce并行化求和。具体步骤如下:
a.首先在第一轮迭代中,根据GPU的block数blockDimX将reduce求解数据分为两个子集,子集大小为
b.然后将线程id=i保存的值与线程id=i+size的值求和,结果保存到线程id=i的对应的共享内存上。
c.将步长size减半,判断步长size的大小。如果步长大于0,则跳到步骤b继续进行reduce求和。如果步长等于0,则结束reduce迭代。
d.将最终结果sum除以马尔科夫链的数目求解期望值,即
e.返回该期望值,并将求解结果由GPU内存复制回CPU内存。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相同或相似的标号对应相同或相似的部件;
附图中描述位置关系的用于仅用于示例性说明,不能理解为对本专利的限制;
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!