一种面向GPU像素流的自适应Cache写分配方法与流程
本发明涉及计算机硬件技术领域,尤其涉及一种像素Cache的更新方法。
背景技术:
3D图形绘制时颜色缓冲区对DDR的带宽需求极大,设计中往往采用颜色Cache来缓解DDR存储带宽压力,为减少DDR的操作频率,颜色Cache一般采用写回和写分配策略实现更新,而在进行大而简单的图形绘制时颜色写操作往往仅执行一次,Cache进行写分配更新回的内容往往不会再次命中,此时写分配的回读更新其实没有实际意义,连续的写操作会将回读回来的Block数据再次更新。且每次写回都更新相当于占用的DDR3总线带宽翻倍。所以颜色缓冲区的Cache设计时如果能够针对不同的绘制场景,自适应选择采用写分配或写不分配的更新策略,在绘制小而复杂的图形时,采用写分配方式,在绘制大而简单的图形时,采用写不分配方式,这样可以在连续写回时节约大量的DDR3带宽。
技术实现要素:
本发明的发明目的是:
本发明描述了一种面向GPU像素流的自适应Cache写分配方法,能够根据当前访问特征自适应选择Cache的更新流程,当绘制大而简单的图形时Cache使用写不分配的更新策略,能够减少写分配的替换更新操作带来的DDR带宽压力,而在绘制小而复杂的图形场景时Cache采用写分配的更细策略,能够提高Cache的命中率。
本发明的技术方案是:
一种面向GPU像素流的自适应Cache写分配方法,包括:
当绘制简单的图形场景时Cache使用写回加写不分配更新流程;
当绘制复杂的图形场景时Cache使用写回加写分配更新流程。
写回加写分配更新流程具体为:
当Cache发生写缺失时首先将要替换的Block数据写回到DDR中,然后将缺失的Block数据更新到Cache中,最后将写数据写到Cache中完成本次访问。
写回加写不分配更新流程具体为:
当Cache发生写缺失时首先将要替换的Block数据写回到DDR中,然后直接将要写的数据写入当前Block,并设置Block中写入数据位置的屏蔽位Mask有效,减少一次DDR的读更新操作。
将要替换的Block数据写回到DDR中的步骤具体为:
根据Block中写入数据的屏蔽标志Mask有效的数据写回到DDR中;
带Mask的写回需要先将DDR中一个Tile的数据读回并解压,然后与要写数据进行合并后再压缩后写回到DDR中。
所述复杂的图形场景为:GPU的绘制场景中区域三角形重复绘制次数大于Cache的更新块中包含的绘制Tile数量的场景;
所述简单的图形场景为:GPU的绘制场景中区域三角形重复绘制次数小于Cache的更新块中包含的绘制Tile数量的场景。
本发明的优点是:
包括两种Cache的更新流程,写回加写分配更新流程(1)、写回加写不分配更新流程(2),由Cache根据当前访问特征自适应选择Cache的更新流程;所述Cache能够根据当前访问特征自适应选择Cache的更新流程,当绘制大而简单的图形时Cache使用写不分配的更新策略,能够减少写分配的替换更新操作带来的DDR带宽压力,而在绘制小而复杂的图形场景时Cache采用写分配的更细策略,能够提高Cache的命中率。
附图说明
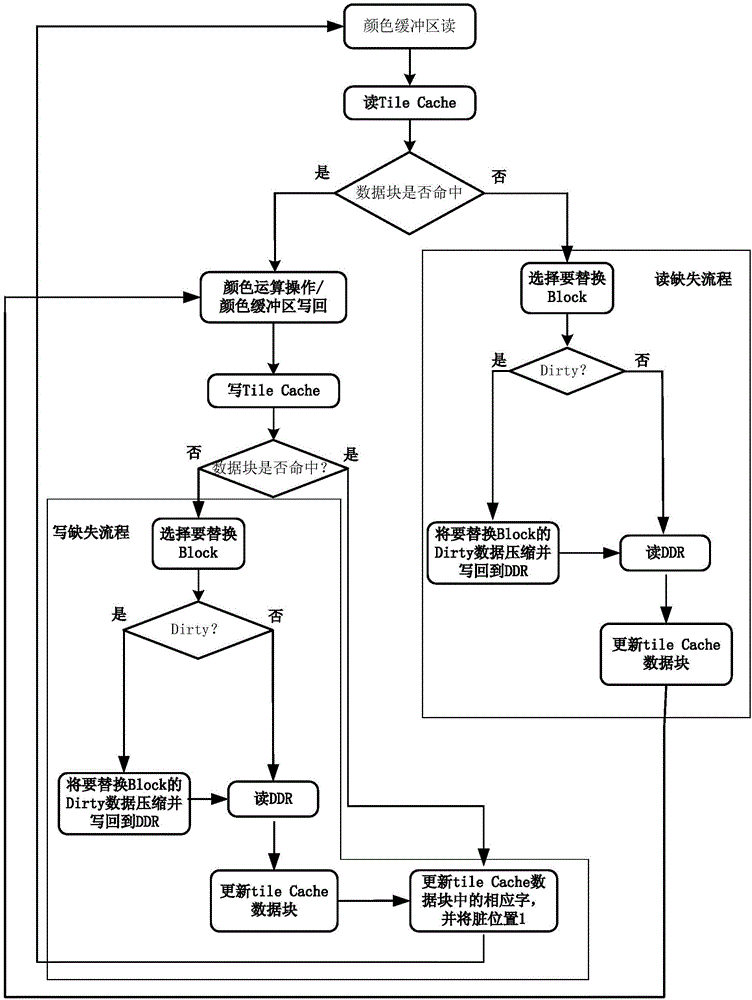
图1是本发明中一种面向GPU像素流的自适应Cache写分配策略流程图;
图2是本发明中写回加写分配策略访问流程图;
图3是本发明中写回加不写分配策略访问流程图;
图4是本发明中写不分配策略中写回操作的流程图。
具体实施方式
下面结合附图和具体实施例,对本发明的技术方案进行清楚、完整地表述。显然,所表述的实施例仅是本发明一部分实施例,而不是全部的实施例,基于本发明中的实施例,本领域技术人员在没有做出创造性劳动前提所获得的所有其他实施例,都属于本发明的保护范围。
一种面向GPU像素流的自适应Cache写分配方法,包括:
当绘制简单的图形场景时Cache使用写回加写不分配更新流程;
当绘制复杂的图形场景时Cache使用写回加写分配更新流程。
写回加写分配更新流程具体为:
当Cache发生写缺失时首先将要替换的Block数据写回到DDR中,然后将缺失的Block数据更新到Cache中,最后将写数据写到Cache中完成本次访问。
写回加写不分配更新流程具体为:
当Cache发生写缺失时首先将要替换的Block数据写回到DDR中,然后直接将要写的数据写入当前Block,并设置Block中写入数据位置的屏蔽位Mask有效,减少一次DDR的读更新操作。
将要替换的Block数据写回到DDR中的步骤具体为:
根据Block中写入数据的屏蔽标志Mask有效的数据写回到DDR中;
带Mask的写回需要先将DDR中一个Tile的数据读回并解压,然后与要写数据进行合并后再压缩后写回到DDR中。
所述复杂的图形场景为:GPU的绘制场景中区域三角形重复绘制次数大于Cache的更新块中包含的绘制Tile数量的场景;
所述简单的图形场景为:GPU的绘制场景中区域三角形重复绘制次数小于Cache的更新块中包含的绘制Tile数量的场景。
实施例1
本发明包括两种Cache的更新流程,写回加写分配更新流程(1)、写回加写不分配更新流程(2),由Cache根据当前访问特征自适应选择Cache的更新流程;所述Cache能够根据当前访问特征自适应选择Cache的更新流程,当绘制大而简单的图形时Cache使用写不分配的更新策略,能够减少写分配的替换更新操作带来的DDR带宽压力,而在绘制小而复杂的图形场景时Cache采用写分配的更细策略,能够提高Cache的命中率。
所述写回加写分配更新流程,当GPU绘制小而复杂的图形场景时,颜色缓冲区的数据需要不停的进行读写,此时需要Cache以较高的命中率以保证图形绘制的速度。Cache采用写回加写分配的更新流程,当Cache发生写缺失时首先将要替换的Block数据写回到DDR中,然后将缺失的Block数据更新到Cache中,最后将写数据写到Cache中完成本次访问。
所述写回加写不分配更新流程,当GPU绘制大而简单的图形场景时,颜色缓冲区的数据是大批量地写操作,此时如果Cache仍然采用写分配策略进行更新,则更新近来的数据往往不会再次被命中,造成了DDR上带宽的巨大浪费。Cache采用写回加写不分配的更新流程,当Cache发生写缺失时首先将要替换的Block数据写回到DDR中,然后直接将要写的数据写入当前Block,并设置Block中的屏蔽位(Mask)表示当前Block中有哪些数据是缺失后已经写入的数据,减少了一次DDR的读更新操作。
所述带Mask的写回操作是当Cache采用写不分配策略时,发生读缺失或写缺失进行Block的写回时,由于某些Block数据已经被之前的写缺失操作写入过数据,所以需要根据Block中写入数据的屏蔽标志Mask决定将那些数据写回到DDR中。由于DDR中颜色数据采用了以Tile为单位的压缩格式存储,所以带Mask的写回往往需要先将DDR中一个Tile的数据读回并解压,然后与要写数据进行合并后再压缩后写回到DDR中。
实施例2
如图1所示,一种面向GPU像素流的自适应Cache写分配方法,模式判断根据当前GPU配置的绘图模式决定选择写分配还是写不分配的Cache更新流程。当GPU绘制复杂场景时,往往会有大量的小三角形被绘制,小三角形之间会有大量的重叠和遮挡,需要进行各种片断裁剪、测试,颜色Cache根据GPU的设置判定当前处于复杂模式,Cache的写缺失采用写回加写分配的方式,在写缺失时不仅将需要替换的Block写回到DDR,同时将缺失的Block替换更新到Cache中,以便下次访问时能够提高Cache的命中率。
当GPU绘制简单场景时,绘制的图形之间重叠较少,也较少出现遮挡、裁剪等,此时如果仍然采用写回加写分配的策略处理Cache的写操作,则写分配带来的缺失Block的更新操作往往是浪费了DDR的带宽。颜色Cache根据当前配置判定为简单场景绘制模式时,采用写回加写不分配策略进行Cache的缺失更新。则直接将要写的数据写入到Cache的Block中,并设置相应的脏位和屏蔽位,可以减少一次DDR的读操作,降低DDR的带宽需求。
如图2所示,当进行复杂的图形场景绘制时,颜色Cache采用写回加写分配的更新策略。GPU首先对颜色缓冲区发起读操作,如果读命中则直接送去颜色缓冲区运算,否则进入读缺失流程进行读缺失更新。首先根据替换算法选择一个要替换的Block,检查该Block的脏位是否有效,如果该Block的脏位无效,则直接从DDR中将缺失的Block替换进来。如果当前要替换出去的Block的脏位有效,则需要先将当前要被替换出去的Block的数据压缩并写回到DDR中,然后再从DDR中将缺失的Block替换进来。
GPU在完成颜色缓冲区运算后将结果通过颜色Cache写回到颜色缓冲区,如果写操作命中,则直接将数据写入到Cache并完成本次写操作,否则进入写缺失流程。首先根据替换算法选择一个要替换的Block,检查该Block的脏位是否有效,如果该Block的脏位无效,则直接从DDR中将缺失的Block替换进来。如果当前要替换出去的Block的脏位有效,则需要先将当前要被替换出去的Block的数据压缩写回到DDR中,然后再从DDR中将缺失的Block替换进来。当缺失的Block数据被替换进来之后再将要写入的数据写入到Cache的Block中,并设置相应的脏位。
如图3所示,当进行简单的图形场景绘制时,颜色Cache采用写回加写不分配更新策略。GPU首先对颜色缓冲区发起读操作,如果读命中则直接送去颜色缓冲区运算,否则进入读缺失流程进行读缺失更新。首先根据替换算法选择一个要替换的Block,检查该Block的脏位是否有效,如果该Block的脏位无效,则直接从DDR中将缺失的Block替换进来。如果当前要替换出去的Block的脏位有效,则需要先将当前要被替换出去的Block的数据压缩并写回到DDR中,然后再从DDR中将缺失的Block替换进来。
GPU在完成颜色缓冲区运算后将结果通过颜色Cache写回到颜色缓冲区,如果写操作命中,则直接将数据写入到Cache并完成本次写操作,否则进入写缺失流程。首先根据替换算法选择一个要替换的Block,检查该Block的脏位是否有效,如果该Block的脏位无效,则直接将要写的数据写入到Cache的Block中,并设置相应的脏位和屏蔽位。如果要替换的Block的脏位有效,则需要按屏蔽写的方式将该Block的数据写回到DDR,然后再将要写的数据写入到Cache的Block中,并设置相应的脏位和屏蔽位。
如图4所示,在Cache使用写回加写不分配的更新策略时,由于写缺失时不进行缺失Block的回读更新操作,导致当前Cache中的Block数据与DDR中数据不一致,使用屏蔽位Mask表示。而DDR中的数据是采用压缩模式存储的,所以当当前使用了Mask的Block需要被写回DDR时需要将DDR中对应的Block数据读回并与要写的Block数据中数据按Mask进行合并,合并后的数据再进行压缩并写回到DDR中。如果当前Block的Mask为全0,说明当前Block已经都被更改过,此时不需要合并,直接将当前Block通过压缩后写回DDR。
最后应说明的是,以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解;其依然可以对前述各实施例记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!