用于自然语言处理的领域词典生成系统的制作方法
本发明自然语言处理领域,特别涉及用于自然语言处理的领域词典生成系统。
背景技术:
大数据时代的到来为世界创造了新的机会,对大数据进行分析利用体现大数据的价值,自然语言处理在大数据分析中占据重要的地位,面对海量的网络文本资源,通过运用自然语言处理的分析方法自动地、智能提取出有用信息,或者判断出文本或者文本发布者所蕴含的某种情感倾向,无论是在舆情分析还是商业调查中都有着重要的实际应用意义。利用分析结果,可以对事情的发展演变进行或者用户喜好正确的预判,进而提前采取相应的措施来实现更大的正面效果。
自然语言处理中经常需要使用词典来进行对应的特征抽取,以词典中的词作为特征,通过词典匹配来抽取对应的特征词汇,在特征词汇抽取的基础上结合设定的模型或者算法来判定该文本对应的倾向或者性质,分析的可靠性大大增加。
然而现有的领域词典,却缺乏对具体问题的适用性,针对性不强。在分析具体领域或者具体话题时,使用现有的大而宽泛的领域词典,并不能够达到理想的分析效果,构建针对性的领域词典十分必要,然而手动构建词典非常的耗时耗力;不能满足海量文本分析的需求。这样的背景下如果能实现:根据用户具体分析需求快速构建针对性强的领域,将有极大节省全手动构建词典的人力物力,然而现有技术中还缺乏能够实现这类词典快速构建功能的相应工具。
技术实现要素:
本发明的目的在于克服现有技术中所存在的上述不足,提供用于自然语言处理的领域词典生成系统,用户只需将待处理文本和领域种子词输入本系统中所述系统就可以实现在自动区分文本主题领域的基础上,根据种子词进行对应领域词典的自动构建。
为了实现上述发明目的,本发明提供了以下技术方案:用于自然语言处理的领域词典生成系统,所述系统在自动区分文本主题领域的基础上,根据种子词进行对应领域词典的自动构建;
所述词典构建包含以下实现过程:
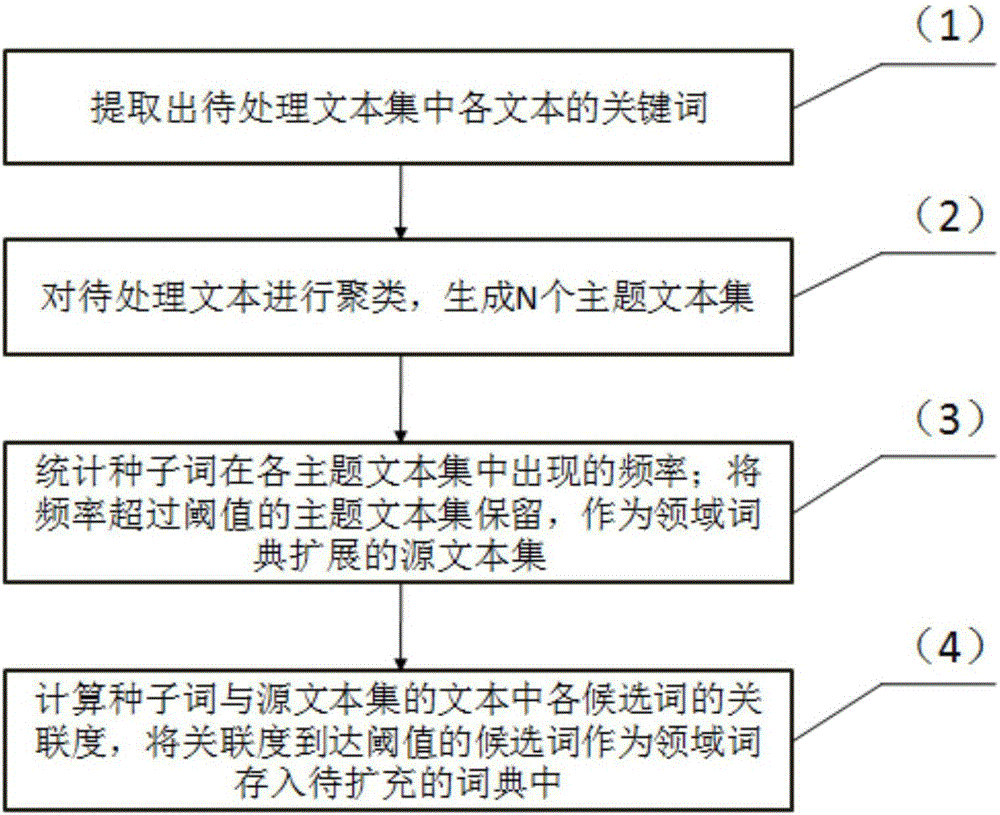
(1)提取出待处理文本集中各文本的关键词;
(2)对待处理文本进行聚类,生成N个主题文本集,其中N为整数且N≥2;
(3)统计种子词在各主题文本集中出现的频率;将频率超过阈值的主题文本集保留,作为领域词典扩展的源文本集;
(4)计算种子词与源文本集的文本中各候选词的关联度,将关联度到达阈值的候选词作为领域词存入待扩充的词典中。
进一步的,所述步骤(1)中采用以下算法公式提取文本中关键词。所述算法的计算公式为:
TR(vi)是文本中词vi的重要性,d是阻尼系数,一般设置为0.85,N是无向图中所有词的个数,relat{vi}是与词vi有共现关系的词集合,vj是relat{vi}中的任意一个词,TR(vj)是vj的重要性,N(pj)是与vj有共现关系的词的个数。
进一步的,所述步骤(2)中对待处理文本聚类包含以下过程:
(2-1)初始时,每个待处理文本各自为一个类;
类间距离定义为两个类中两两文本对间距离的最大值,文本间距离的计算公式如下:
其中C(t1,t2)表示文本1和文本2之间的距离,t1∩t2表示文本1和文本2之间包含相同关键词的个数,mid(t1,t2)表示文本1和文本2中包含关键词的平均个数;类间距离计算公式如下:
Dist(ca,cb)=max{C(ta,tb),ta∈ca,tb∈cb}
其中,Dist(ca,cb)表示任意两个类簇之间的距离,ca和cb分别代表两个类,C(ta,tb)表示两个文本之间的距离,ta和tb分别表示两个文本,并且要求ta∈ca、tb∈cb(2-2)计算所有类两两之间的距离,将距离最小的类进行合并,命名为cnew;
(2-3)在待处理文本集中将已被合并的初始类簇删除,并将新类簇cnew加入到聚类结果中;
(2-4)重复步骤(2-1)至(2-3),直到待处理文本集中仅包含N个类簇时,停止聚类。此时待处理文本集中包含的是经过聚类后形成的N个主题,其中N的具体个数,根据实际应用所而自行设定。
作为一种优选:所述步骤(4)中候选词与种子词的关联度计算公式为:
其中p(word1,word2)为词word1和词word2共同出现的概率,p(word1)和p(word2)表示词word1和词word2分别出现的概率。
作为一种优选,所述步骤(2)中,N=3。
作为一种优选,所述步骤(3)中,仅保留种子词出现频率最高的主题文本集作为词典扩充的源文本集。
作为一种优选,所述步骤(4)中候选词与种子词的阈值设置为MI(word1,word2)=0.2,当文本集中词汇与种子词的关联度≥0.2时,就将该词作为扩展词汇添加到所要构建的词典中。
进一步的,所述词典生成系统为加载有上述功能的计算机或者服务器。
与现有技术相比,本发明的有益效果:本发明提供用于自然语言处理的领域词典生成系统,用户只需将待处理文本和领域种子词输入本系统中所述系统就可以实现在自动区分文本主题领域的基础上,根据种子词进行对应领域词典的自动构建。本发明系统自动区分待处理文本的主题类型,并根据种子词实现主题文本集与对应领域的自动匹配,在关系密切的主题文本集中来实现词典的词汇的扩展,词典构建的准确性更高。
本发明系统的种子词根据用户需要自行选取,种子词的选取可根据分析的具体方向而定,因此更加具有针对性,更加符合用户使用的需要。相比于普通的领域词典,本发明系统所构建的领域词典具有更强灵活。词典的实用性更强,更加适应于具体问题或者主题的文本分析。为自然语言处理提供可靠的词典自动生成工具。
附图说明:
图1为本发明系统的系统结构图。
图2为本发明系统词典构建的实现过程示意图。
图3为本发明系统词典构建步骤(4)的实现过程示意图。
具体实施方式
下面结合试验例及具体实施方式对本发明作进一步的详细描述。但不应将此理解为本发明上述主题的范围仅限于以下的实施例,凡基于本发明内容所实现的技术均属于本发明的范围。
提供用于自然语言处理的领域词典生成系统,所述系统在自动区分文本主题领域的基础上,根据种子词进行对应领域词典的自动构建。如图1所示,包括文本预处理系统和词典构建系统,所述文本预处理系统对待处理的文本进行包括分词、去高频词和去停用词的处理;所述词典构建系统根据领域种子词对领域词典进行自动扩充,构建出对应的领域词典。
为了实现上述发明目的,本发明提供了以下技术方案:用于自然语言处理的领域词典生成系统,词典包含如图2所示的以下实现步骤:
(1)提取出待处理文本集中各文本的关键词;待处理文本通过文本输入端口输入到预处理系统中进行预处理后,输入到词典构建系统中。
(2)对待处理文本进行聚类,形成N个主题文本集,其中N为≥2的整数。
(3)根据用户所选取的种子词,统计种子词在各主题文本集中出现的频率;将种子词出现频率超过阈值的主题文本集保留,作为领域词典扩展的源文本集。通过聚类对待处理文本集进行分类,形成了不同主题的文本集合,同一主题内的文本之间的关联程度更高,为后续的词典扩展进行了语料的准备和筛选。
通过聚类形成不同主题文本集后,经过计算种子词在主题文本关键词的出现频率,进而分析出不同主题与所构建词典领域之间的关系远近,将关系较远的文本集舍弃,这样在进行词典扩展时,只在领域较近的主题中进行,大大提高了词典扩展来源语料的质量,词典扩展的准确性显著提升,同时由于仅在于所扩展的领域最近的文本集中进行词典扩展,缩小了词典扩展时计算的范围,减少了词典扩展的计算量,提高了词典扩展的效率。
用户自行选取种子词的方式,对于具体领域或者问题的针对性更强,所构建的词典的适用更加灵活。
(4)计算种子词与源文本集的各词的关联度,将关联度到达设定阈值的词作为领域词存入待扩充的词典中。
进一步的,所述步骤(1)中采用以下算法公式提取文本中关键词。所述算法的计算公式为:
TR(vi)是文本中词vi的重要性。d是阻尼系数,一般设置为0.85。N是无向图中(将文本分词后,抽象成一个无向图,其中文本中的每个词是图中的一个节点)所有词的个数。relat{vi}是与词vi有共现关系的词集合。vj是relat{vi}中的任意一个词,TR(vj)是vj的重要性,N(pj)是与vj有共现关系的词的个数。
通过本计算公式进行迭代计算,抽取TR(vi)大于阈值的对应词作为该文本的关键词;通过关键词的自动抽取,为文本聚类进行准备。
进一步的,所述步骤(2)中对待处理文本聚类包含以下过程:
(2-1)初始时,每个待处理文本各自为一个类;
类间距离定义为两个类中两两文本对间距离的最大值,文本间距离的计算公式如下:
其中C(t1,t2)表示文本1和文本2之间的距离,t1∩t2表示文本1和文本2之间包含相同关键词的个数,mid(t1,t2)表示文本1和文本2中包含关键词的平均个数;类间距离计算公式如下:
Dist(ca,cb)=max{C(ta,tb),ta∈ca,tb∈cb}
其中,Dist(ca,cb)表示任意两个类簇之间的距离,ca和cb分别代表两个类,C(ta,tb)表示两个文本之间的距离,ta和tb分别表示两个文本,并且要求ta∈ca、tb∈cb(2-2)计算所有类两两之间的距离,将距离最小的类进行合并,命名为cnew;
(2-3)在待处理文本集中将已被合并的初始类簇删除,并将新类簇cnew加入到聚类结果中;
(2-4)重复步骤(2-1)至(2-3),直到待处理文本集中仅包含N个类簇时,停止聚类。此时待处理文本集中包含的是经过聚类后形成的N个主题,其中N的具体个数,根据实际应用而自行设定。
作为一种优选,所述步骤(2-4)N=3,将待处理文本集仅分为三个主题,方便后续计算。
作为一种优选;所述步骤(3)中,仅保留种子词出现频率最高的主题文本集作为词典扩充的源文本集;本步骤从个主题文本集中选取与种子词关系最密切的文本集,使得词典扩展的语料集更加符合领域的特点,词典的扩展质量更高,针对性更强。
作为一种优选:所述步骤(4)中词汇与种子词的关联度计算采用互信息的计算思想,所采用的计算公式为:
其中p(word1,word2)为词word1和词word2共同出现的概率,p(word1)和p(word2)表示词word1和词word2分别出现的概率。互信息算法对于分析词汇之间的关联度,算法简洁容易实现,计算效率较高;互信息是计算语言学模型的分析方法,它度量两个对象之间的相互性。在过滤问题中用于度量特征对于主题的区分度。在进行领域词典构建时,在用户自行选取种子词的基础上,利用互信息的方法来计算待扩充的词汇和现有种子词的相关性,相关度越高表示该词与种子词的关联性越高。
作为一种优选,所述步骤(4)的阈值设置为MI(word1,word2)=0.2,当文本集中候选词与种子词的关联度≥0.2时,就将该词作为扩展词汇添加到所要构建的词典中,所述步骤(4)的计算过程如图3所示。
进一步的,所述用于自然语言处理的领域词典生成系统为加载有上述功能的计算机或服务器。
- 还没有人留言评论。精彩留言会获得点赞!