一种基于光谱的血液物种识别仪及识别方法与流程
本发明属于模式识别技术领域,涉及一种基于血液光谱数据对血液来源物种进行识别的方法,可用于血液样品来源物种的快速识别。
背景技术:
随着中国医药行业国际化的飞速发展,血液生物材料的出入国境需求日益增加。目前海关对血液来源物种的判断主要依据两方面的信息来源,其一是申报人提供的血样信息,其二是检验机构提供的检验结果,前者的信息真实性难以保证,后者的检验过程则耗时繁多,而且血液样品可能被检测操作污染,或者血液样品自身可能携带致病因子,对检测人员造成职业暴露。因此,尽管生化方法具有很高的检测准确性,但却不便应用于海关等场合,所以,有必要提出一种更便捷的检测方法,相关研究结果表明,光谱检测法具有解决这一问题的潜力。
上世纪70年代,美国杜克大学的fransf.jöbsis首次提出了将血液的近红外光谱用于血液成分含量检测的设想,此后,世界各国的研究人员纷纷展开了对血液光谱的分析研究。匈牙利imrehaynal健康科学大学的istvánvályi-nagy和évagönczöl等人的研究表明红外光谱可用于测定全血和血清中血红蛋白、脂蛋白和血氧等成分的含量,而基于近红外光谱的血糖无创测量则为糖尿病患者带了福音,美国圣地亚国家实验室的m.kathleenalam等人发现可以采用近红外光谱测量血液的ph值,日本欧姆龙生命科学研究所有限公司的toshikazushiga等人设计制作了基于红外光谱分析的便携式组织血氧计,中国科学院长春光机所的陈华才等人利用傅里叶变换近红外透射光谱技术,建立了人血清中胆固醇和甘油三酯的定标模型,此外,美国爱荷华大学的kevinh.hazen和marka.arnold等用红外光谱对人血清中的总蛋白、球蛋白、白蛋白、甘油三酯、胆固醇、尿素、血糖和乳酸盐等进行了定量分析,并构造了相应的光谱预测模型。随着光谱分析技术的进一步发展,临床化学领域发现,通过分析血液的光谱数据,可以快速辨别类风湿性关节炎和糖尿病的发病情况。
上述各类利用红外光谱检测血液成分含量的研究,均采用了基于生化标定法的研究路线:首先,采集血液的红外光谱;其次,利用生化方法测量血液中目标成分的含量,作为标准含量数据,这就是生化标定步骤;之后,利用数学方法构建血液光谱数据与标准含量数据之间的关联模型;最后,利用该模型和血液光谱数据预测血液中目标成分的含量,实现非接触式的血液成分含量检测。其中所用的数学方法主要是统计分析方法,例如偏最小二乘算法和多元线性回归算法等,随着机器学习理论的发展,越来越多机器学习领域的算法被引入光谱预测模型的构建中,例如人工神经网络和支持向量机等。
上述内容表明,光谱法可以定量地分析血液中的生化成分,这是使用光谱法检测血液来源物种的技术理论基础,而使用光谱法检测血样来源的生物学基础则是物种之间的血液差异。物种是生物界发展的连续性与间断性统一的基本间断形式,在有性生物中,物种呈现为统一的繁殖群体,由占有一定空间,具有实际或潜在繁殖能力的种群所组成,而且与其他这样的群体在生殖上是隔离的。
有研究表明,不同物种的血液成分含量有显著差异。中科院动物研究所的董全等,测定了12只大熊猫的血液成分含量,与小熊猫和美洲黑熊的相同血液数据进行对比,结果发现三个物种的血液成分含量存在显著差异。军事医学科学院实验动物中心的王冬平等,比较了食蟹猴与猕猴的多项血液生理指标和生化指标,发现二者血液成分的多项指标均存在显著差异。综上所述,从理论角度分析,利用光谱技术检测血液来源物种是可行的。
技术实现要素:
本发明的目的在于为了解决上述问题而提供一种既能够对血样来源进行快速检测,又能够对大量不同物种来源的血样进行模式识别的识别仪,检测箱可以检测盛放于抗凝管内血样光谱的数据,该识别仪可以采集200-1750nm波长范围的可见光和近红外光谱,上位机可以采集大量常见物种的2000个血样的光谱数据,并提供了一套完整详实的光谱数据库,使光谱数据与血样物种之间建立一个关联模型,当检测箱检测数据给出,上位机能够立即给出该血样的物种来源,实现快速检测的目的,该模型对随机抽取盲样的识别率可以达到95%,针对后续物种的血样来源检测可定制和改性,改装版本的设备同样适用于物种识别,应用范围广泛。
本发明通过以下技术方案来实现上述目的,本发明的基于光谱的血液物种识别仪,其特征在于,
包括检测箱和上位机,所述检测箱包括第一发光系统,第一光检测系统,存储器,信号输入/输出系统,
上位机包括血液采集系统,第二发光系统,第二光检测系统,信号预处理系统,阵列信号预处理系统以及模式识别系统。
所述第一、第二发光系统由激光光源模块、第一反射镜、第一透镜构成,所述第一光检测系统由第二透镜、衍射元件、狭缝、第二反射镜、图像拾取器件构成,所述第二光检测系统由光学谐振腔、薄膜压力传感器和光电倍增管构成。
本发明的基于光谱的血液物种识别仪的识别方法,其特征在于,包括如下步骤:
(1)获得目标血样的光谱数据,包含可见光谱,近红外光谱,其中每种光谱数据又包含前向和后向散射的光谱,前向散射光谱也称为透射光谱,后向散射光谱也称为反射光谱。获取数据的同时采用正则化方法对数据进行预处理;
(2)将每个血样的光谱串联成一条一维数组,那么多个样本的光谱数据并列在一起,就可以组成二维数组,该二维数组的两个维度分别是,光谱波长和样本编号;
(3)将血样光谱数据分成
(4)对于
(5)对步骤(4)中得到的
(6)重复循环执行步骤(5)。当重复次数达到
(7)经过步骤(6)之后,可以得到了
其中步骤(4)中的基准样本分割比例可以选择的比例包括但不限于,9:1,3:2和1:1,其关键在于,用包含样本数量较多的部分作为训练集,用数量较少的部分作为测试集;
其中步骤(4)流式训练法的流程为:降维滤波方法à模式识别方法,其中的降维滤波方法可以是但不限于:小波分析,主成分分析,随机投影。其中的模式识别方法可以是但不限于:人工神经网络,决策树,支持向量机,贝叶斯分类器,聚类法;
步骤(5)包括:
第5.1步用流式训练法在第
第5.2步用
第5.3步找到
其中第5.2步的
其中步骤(6)中
其中步骤(7)中的综合判断方法可以是但不限于:投票法;加权投票法(权值根据各个模型的
附图说明
图1是血液光谱的物种识别方法示意图。
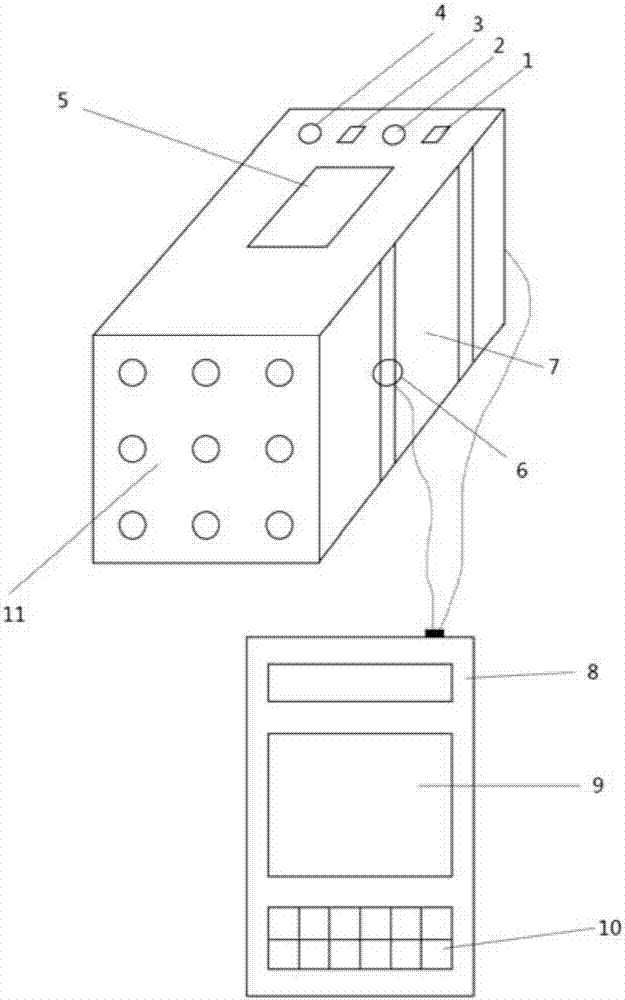
图2是血液光谱的物种识别仪结构示意图。
图3是本发明中构建逻辑驱动模型的流程图。
图4是本发明将逻辑驱动模型转化为数据驱动模型的演化过程图。
图5是本发明中迭代循环步骤的流程图。
1.电源接口;2.电源开关;3.usb接口;4.wifi模块接口;5.血样输送口;6.数据传输装置;7.检测箱;8.上位机;9.显示器;10.血样送检盒;11.激光光源模块。
具体实施方式
下面结合附图对本发明作进一步说明:
如图1所示,上位机8的血样送检盒10一次接收12盒送检样品,样本可同时进行血液的光谱采集,其中发光系统由光学谐振腔、薄膜压力传感器和光电倍增管构成,光学谐振腔具有两个输入端和两个输出端,第一输入端和激光光源模块连接,用于接收发射光,第二输入端和样本采集装置连接,用于采集血样信息,两个输出端分别和薄膜压力传感器的输入端和光电倍增管的输入端连接,光电倍增管的输入端和模数转换器的输入端连接,模数转换器的输出端和处理器的输入端连接,处理器将信号经过预处理并输入到阵列信号预处理模块中,经过预处理后的数据是矩阵化的阵列,将阵列输入到模式识别引擎,根据建立的知识库模块进行训练,给出血样光谱的表达,在模式识别过程中不断的对阵列的某一组测试值进行测试。
从逻辑推理的角度分析,如果能得到每个物种血液中每种成分的光谱预测模型,则可以由血液光谱快速得知其血液成分含量,从而推测出血液来源物种的类别。为了设计这个逻辑驱动模型,需要为每个物种血液中的每种成分都建立一个基于生化标定法的光谱预测模型,然后将每个物种的所有光谱预测模型与物种类别相关联,从而建立一个从血液光谱到血液成分含量再到血液来源物种类别的预测模型,如图3所示。
从图3中可以看出,该逻辑驱动模型的输入端是血液光谱数据,输出端是血液来源物种,中间部分则是,基于生化标定法的数学建模过程,和血液成分含量与血液来源物种类别的关联过程。由于需要构建光谱预测模型的血液成分类别非常多,这种逻辑驱动模型的构建难度非常大。受到近年来机器学习和大数据分析领域的发展启示,本实施例用一个黑箱过程来替代逻辑驱动模型中生化标定法建模过程,如图3所示,然后,通过数学建模的方法对黑箱过程进行合理化描述,使其能够根据血液光谱数据预测血液来源物种的类别。
如图2所示,物种识别仪的检测箱7包括激光光源模块,第二透镜、衍射元件、狭缝、第二反射镜、图像拾取器件、存储器,信号输入/输出系统,血样通过血样输送口5送入到检测箱7中,打开电源开关2,检测箱开始工作,将所检测数据存储到存储器当中,通过数据传输装置6传输到上位机8当中进行模式识别检测。可以通过有线/无线方式进行数据的传输,为了方便在现场工作,检测箱7配备有usb接口3和wifi模块接口4。
用数据驱动模型替换逻辑驱动模型的合理性在于,这两种模型的实质都是数学建模过程,从结构形式的角度来看,这两种类同的过程可以彼此趋近。其中逻辑驱动模型实质为数学建模过程的原因为:逻辑驱动模型包含两个过程,第一个过程是根据生化标定法建立血液成分含量的光谱预测模型,这个过程通过统计分析和机器学习领域的数学建模方法实现;第二个过程是建立多个血液成分含量与物种类别的关联模型,该过程需要利用模式识别领域的数学建模方法。因此逻辑驱动模型实质上是多个数学建模过程的组合。
这种数据驱动的血液物种光谱预测模型,将逻辑驱动模型中的繁复的逻辑推理过程简化为一个黑箱,由于这个黑箱中的过程是不可知的,因此需要利用数据处理和数理统计的方法寻找输入与输出之间的关系,也就是寻找血液光谱数据和血液来源物种之间的关系,然后,利用这种关系,来预测任意输入所对应的输出。
在上述数据驱动模型的设计思想指导之下,本方法的实现过程为:
(1)获取数据:获得目标血样的光谱数据,包含可见光谱,近红外光谱,其中每种光谱数据又包含前向和后向散射的光谱,前向散射光谱也称为透射光谱,后向散射光谱也称为反射光谱。获取数据的同时采用正则化方法对数据进行预处理。
(2)组织数据:将每个血样的光谱串联成一条一维数组,那么多个样本的光谱数据并列在一起,就可以组成二维数组,该二维数组的两个维度分别是,光谱波长和样本编号。
(3)分组数据:将血样光谱数据分成
(4)迭代循环:
4.1对于
4.2对于
1)用流式训练法在第
2)用
3)找到
4.3重复步骤4.2进行迭代循环,直到满足条件:(1)步骤2重复了
(5)识别判断:经过步骤四的迭代处理,得到了
本发明方法的变种之一可以是,对光谱中的不同波段分别采用上述实现流程进行处理,最后将多个波段的判断结果进行综合。
本发明方法的变种之二可以是,在迭代循环步骤中不对数据集进行分割,直接在原数据集上进行模型训练,在后续的互相预测阶段,直接用
本发明方法的变种之三可以是,用不同类型的流式训练法得到多个不同的整体预测模型,然后对这些多个整体预测模型的判断结果进行综合。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!