数据库管理装置及其方法与流程
本发明涉及一种数据库管理装置,特别是涉及一种新的数据结构的数据库管理装置。
背景技术:
以往,基于知识数据库的应用是遵照语法来决定数据的形式并对其进行数据处理的。例如:1)“吃”这一单词是动词,接宾语;2)“苹果”这一单词是名词,作为属性而具有颜色、大小、产地等。将所述数据的形式组织成表,来设为针对每个单词具有项目的关系数据库的数据结构。
在专利文献1(日本特开平08-077013号公报)中公开了一种采用面向对象的数据库来代替所述关系数据库。
技术实现要素:
发明要解决的问题
然而,在关系数据库中,根据所使用的单词,表的列的结构会改变。另外,存在如下问题:为了指定名词的所有属性,不得不增加表中的列的数量。因而,追加新的知识是很麻烦的。
另外,即使是专利文献1的方法,其结果也是每次都需要制作类等。
本发明的目的在于,解决上述问题,提供一种能够简单地使知识数据库成长的数据库管理装置。
用于解决问题的方案
1)本发明所涉及的数据库管理装置是一种数据库管理装置,a)具有以一个记录构成一个元素数据的表,该表至少包括下述四个字段a1)~a4):a1)元素数据id字段,其用于存储该元素数据的元素数据id;a2)上层元素数据字段,其用于存储位于该元素数据的上层的上层元素数据的id即上层元素数据id;a3)连结属性元素数据字段,其用于存储表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的id即连结属性元素数据id;以及a4)内容元素数据指定字段,其用于存储用于指定表示所述连结属性的内容的内容元素数据的内容元素数据id,b)所述表至少具有:b1)元素关联数据存储部,其存储元素关联数据;b2)多元素组数据存储部,其存储多元素组数据;以及b3)多元素组数据连结数据存储部,其存储用于将所述元素关联数据与所述多元素组数据的多元素组最上层元素数据进行连结的多元素组数据连结数据,b1)所述元素关联数据是用于指定主元素数据与从元素数据的关联性的数据,在所述元素关联数据中,所述从元素数据的元素数据id存储于所述内容元素数据指定字段,所述主元素数据的元素数据id存储于所述上层元素数据字段,表示从所述从元素数据来看的所述主元素数据的谓语关系信息即反向谓语关系信息的元素数据id存储于所述连结属性元素数据字段,b2)所述多元素组数据至少具有起点元素数据、终点元素数据及行径元素数据、以及用于将它们进行连结的多元素组最上层元素数据,b21)在所述多元素组最上层元素数据中,该元素数据的id分别存储于所述元素数据id字段和所述内容元素数据指定字段,b22)在所述起点元素数据中,所述主元素数据的元素数据id存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据id存储于所述上层元素数据字段,意味着源点格的元素数据id存储于所述连结属性元素数据指定字段,b23)在所述终点元素数据中,所述从元素数据的元素数据id存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据id存储于所述上层元素数据字段,意味着终点格的元素数据id存储于所述连结属性元素数据指定字段,b24)在所述行径元素数据中,表示从所述主元素数据来看的所述从元素数据的谓语关系信息的元素数据id存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据id存储于所述上层元素数据字段,意味着行径格的元素数据id存储于所述连结属性元素数据指定字段,b3)在所述多元素组数据连结数据中,所述多元素组数据的多元素组最上层元素数据id存储于所述内容元素数据指定字段,所述元素关联数据的元素数据id存储于所述上层元素数据指定字段,表示该多元素组最上层元素数据与该元素关联数据连结着的焦点化属性的连结属性id存储于连结属性元素数据指定字段,c)所述数据库管理装置具备提取单元,当被施加针对所述上层元素数据字段指定了主元素数据id的检索请求时,所述提取单元提取包含该主元素数据的元素关联数据,提取包含所提取出的该元素关联数据的元素数据id的多元素组数据连结数据,提取利用所提取出的多元素组数据连结数据指定的多元素组数据,从而提取相连结的元素数据。
因而,能够提供一种利用所述元素数据id字段、所述上层元素数据字段、所述连结属性元素数据字段以及所述内容元素数据指定字段这样的共通的形式的表来使各种数据连结起来的数据库管理装置。
2)本发明所涉及的数据库管理装置是一种数据库管理装置,a)具有以一个记录构成一个元素数据的表,该表至少包括下述四个字段a1)~a4):a1)元素数据id字段,其用于存储该元素数据的元素数据id;a2)上层元素数据字段,其用于存储位于该元素数据的上层的上层元素数据的id即上层元素数据id;a3)连结属性元素数据字段,其用于存储表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的id即连结属性元素数据id;以及a4)内容元素数据指定字段,其用于存储用于指定表示所述连结属性的内容的内容元素数据的内容元素数据id,b)所述表至少具有:b1)元素关联数据存储部,其存储元素关联数据;b2)多元素组数据存储部,其存储多元素组数据;以及b3)多元素组数据连结数据存储部,其存储用于将所述元素关联数据与所述多元素组数据的多元素组最上层元素数据进行连结的多元素组数据连结数据,b1)所述元素关联数据是用于指定主元素数据与从元素数据的关联性的数据,在所述元素关联数据中,所述从元素数据的元素数据id存储于所述内容元素数据指定字段,所述主元素数据的元素数据id存储于所述上层元素数据字段,表示从所述从元素数据来看的所述主元素数据的谓语关系信息即反向谓语关系信息的元素数据id存储于所述连结属性元素数据字段,b2)所述多元素组数据至少具有起点元素数据、终点元素数据及行径元素数据、以及用于将它们进行连结的多元素组最上层元素数据,b21)在所述多元素组最上层元素数据中,该元素数据的id分别存储于所述元素数据id字段和所述内容元素数据指定字段,b22)在所述起点元素数据中,所述主元素数据的元素数据id存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据id存储于所述上层元素数据字段,意味着源点格的元素数据id存储于所述连结属性元素数据指定字段,b23)在所述终点元素数据中,所述从元素数据的元素数据id存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据id存储于所述上层元素数据字段,意味着终点格的元素数据id存储于所述连结属性元素数据指定字段,b24)在所述行径元素数据中,表示从所述主元素数据来看的所述从元素数据的谓语关系信息的元素数据id存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据id存储于所述上层元素数据字段,意味着行径格的元素数据id存储于所述连结属性元素数据指定字段,b3)在所述多元素组数据连结数据中,所述多元素组数据的多元素组最上层元素数据id存储于所述内容元素数据指定字段,所述元素关联数据的元素数据id存储于所述上层元素数据指定字段,表示该多元素组最上层元素数据与该元素关联数据连结着的焦点化属性的连结属性id存储于连结属性元素数据指定字段,c)所述数据库管理装置具备写入单元,当被提供起点元素数据、终点元素数据以及行径元素数据来作为新的多元素组数据时,该写入单元执行下述步骤:c1)多元素组数据生成步骤,生成起点元素数据、终点元素数据及行径元素数据的多元素组最上层元素数据,并将多元素组最上层元素数据与所提供的起点元素数据、终点元素数据及行径元素数据一起作为多元素组数据写入所述表;c2)元素关联数据生成步骤,生成以下的元素关联数据并将该元素关联数据写入所述表:将该起点元素数据的内容元素数据指定字段的元素数据id写入上层元素数据字段,将该终点元素数据的内容元素数据指定字段的元素数据id写入内容元素数据指定字段,将与该行径元素数据的内容元素数据指定字段的元素数据id处于反向关系的元素数据id写入连结属性元素数据字段;以及c3)多元素组数据连结数据生成步骤,生成以下的多元素组数据连结数据并将该多元素组数据连结数据写入所述表:将所生成的所述多元素组最上层元素数据的元素数据id写入内容元素数据指定字段,将所生成的所述元素关联数据的元素数据id写入上层元素数据字段,将所述焦点化属性的连结属性的元素数据id写入连结属性元素数据指定字段。
因而,能够提供一种利用所述元素数据id字段、所述上层元素数据字段、所述连结属性元素数据字段以及所述内容元素数据指定字段这样的共通的形式的表来使各种数据连结起来的数据库管理装置。
3)本发明所涉及的数据库管理装置是一种数据库管理装置,a)具有以一个记录构成一个元素数据的表,该表至少包括下述四个字段a1)~a4):a1)元素数据指定信息字段,其用于存储用于指定该元素数据的元素数据指定信息;a2)上层元素数据字段,其用于存储用于指定位于该元素数据的上层的上层元素数据的上层元素数据指定信息;a3)连结属性元素数据字段,其用于存储用于指定表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的连结属性元素数据指定信息;以及a4)内容元素数据指定字段,其用于存储用于指定表示所述连结属性的内容的内容元素数据的内容元素数据指定信息,b)所述表至少具有:b1)元素关联数据存储部,其存储元素关联数据;b2)多元素组数据存储部,其存储多元素组数据;以及b3)多元素组数据连结数据存储部,其存储用于将所述元素关联数据与所述多元素组数据的多元素组最上层元素数据进行连结的多元素组数据连结数据,b1)所述元素关联数据是用于指定主元素数据与从元素数据的关联性的数据,在所述元素关联数据中,所述从元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述主元素数据的元素数据指定信息存储于所述上层元素数据字段,表示从所述从元素数据来看的所述主元素数据的谓语关系信息即反向谓语关系信息的元素数据指定信息存储于所述连结属性元素数据字段,b2)所述多元素组数据至少具有起点元素数据、终点元素数据及行径元素数据、以及用于将它们进行连结的多元素组最上层元素数据,b21)在所述多元素组最上层元素数据中,该元素数据的元素数据指定信息分别存储于所述元素数据指定信息字段和所述内容元素数据指定字段,b22)在所述起点元素数据中,所述主元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着源点格的元素数据指定信息存储于所述连结属性元素数据指定字段,b23)在所述终点元素数据中,所述从元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着终点格的元素数据指定信息存储于所述连结属性元素数据指定字段,b24)在所述行径元素数据中,表示从所述主元素数据来看的所述从元素数据的谓语关系信息的元素数据指定信息存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着行径格的元素数据指定信息存储于所述连结属性元素数据指定字段,b3)在所述多元素组数据连结数据中,所述多元素组数据的多元素组最上层元素数据指定信息存储于所述内容元素数据指定字段,所述元素关联数据的元素数据指定信息存储于所述上层元素数据指定字段,表示该多元素组最上层元素数据与该元素关联数据连结着的焦点化属性的连结属性指定信息存储于连结属性元素数据指定字段,c)所述数据库管理装置具备提取单元,当被施加针对所述内容元素数据指定字段指定了第一元素数据指定信息的检索请求时,所述提取单元提取包含所述第一元素数据的元素关联数据,并且提取与该元素关联数据关联的多元素组数据和多元素组数据连结数据,由此提取相连结的元素数据。
因而,能够提供一种利用所述元素数据指定信息字段、所述上层元素数据字段、所述连结属性元素数据字段以及所述内容元素数据指定字段这样的共通的形式的表来使各种数据连结起来的数据库管理装置。
4)本发明所涉及的数据库管理装置是一种数据库管理装置,a)具有以一个记录构成一个元素数据的表,该表至少包括下述四个字段a1)~a4):a1)元素数据指定信息字段,其用于存储用于指定该元素数据的元素数据指定信息;a2)上层元素数据字段,其用于存储用于指定位于该元素数据的上层的上层元素数据的上层元素数据指定信息;a3)连结属性元素数据字段,其用于存储用于指定表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的连结属性元素数据指定信息;以及a4)内容元素数据指定字段,其用于存储用于指定表示所述连结属性的内容的内容元素数据的内容元素数据指定信息,b)所述表至少具有:b1)元素关联数据存储部,其存储元素关联数据;b2)多元素组数据存储部,其存储多元素组数据;以及b3)多元素组数据连结数据存储部,其存储用于将所述元素关联数据与所述多元素组数据的多元素组最上层元素数据进行连结的多元素组数据连结数据,b1)所述元素关联数据是用于指定主元素数据与从元素数据的关联性的数据,在所述元素关联数据中,所述从元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述主元素数据的元素数据指定信息存储于所述上层元素数据字段,表示从所述从元素数据来看的所述主元素数据的谓语关系信息即反向谓语关系信息的元素数据指定信息存储于所述连结属性元素数据字段,b2)所述多元素组数据至少具有起点元素数据、终点元素数据及行径元素数据、以及用于将它们进行连结的多元素组最上层元素数据,b21)在所述多元素组最上层元素数据中,该元素数据的元素数据指定信息分别存储于所述元素数据指定信息字段和所述内容元素数据指定字段,b22)在所述起点元素数据中,所述主元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着源点格的元素数据指定信息存储于所述连结属性元素数据指定字段,b23)在所述终点元素数据中,所述从元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着终点格的元素数据指定信息存储于所述连结属性元素数据指定字段,b24)在所述行径元素数据中,表示从所述主元素数据来看的所述从元素数据的谓语关系信息的元素数据指定信息存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着行径格的元素数据指定信息存储于所述连结属性元素数据指定字段,b3)在所述多元素组数据连结数据中,所述多元素组数据的多元素组最上层元素数据指定信息存储于所述内容元素数据指定字段,所述元素关联数据的元素数据指定信息存储于所述上层元素数据指定字段,表示该多元素组最上层元素数据与该元素关联数据连结着的焦点化属性的连结属性指定信息存储于连结属性元素数据指定字段,c)所述数据库管理装置具备写入单元,当被提供起点元素数据、终点元素数据以及行径元素数据来作为新的多元素组数据时,该写入单元生成多元素组最上层元素数据并将该多元素组最上层元素数据作为多元素组数据进行写入,并且生成并写入元素关联数据和多元素组数据连结数据。
因而,能够提供一种利用所述元素数据指定信息字段、所述上层元素数据字段、所述连结属性元素数据字段以及所述内容元素数据指定字段这样的共通的形式的表来使各种数据连结起来的数据库管理装置。
5)在本发明所涉及的数据库管理装置中,在所述表中还存储有与从元素数据有关的元素关联数据和多元素组数据连结数据,b1)在所述与从元素数据有关的元素关联数据中,所述主元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述从元素数据的元素数据指定信息存储于所述上层元素数据字段,表示从所述主元素数据来看的所述从元素数据的谓语关系信息即谓语关系信息的元素数据指定信息存储于所述连结属性元素数据字段,b2)在所述多元素组数据连结数据中,所述多元素组最上层元素数据指定信息存储于所述内容元素数据指定字段,所述与从元素数据有关的元素关联数据的元素数据指定信息存储于所述上层元素数据指定字段,表示该多元素组最上层元素数据与该元素关联数据连结着的焦点化属性的连结属性指定信息存储于连结属性元素数据指定字段。
因而,关于所述从元素数据,也能够利用所述元素数据指定信息字段、所述上层元素数据字段、所述连结属性元素数据字段以及所述内容元素数据指定字段这样的共通的形式的表来进行管理。
6)在本发明所涉及的数据库管理装置中,所述写入单元针对所生成的用于指定元素关联数据和多元素组数据连结数据的所述元素数据指定信息分别存储加权候选元素数据,作为加权候选元素数据,分别将该加权候选元素数据的元素数据指定信息存储到上层元素数据字段,并将表示权重的元素数据指定信息存储到所述连结属性元素数据字段,并将表示权重的程度的元素数据指定信息存储到内容元素数据指定字段。因而,能够管理附加了权重的元素数据。
7)在本发明所涉及的数据库管理装置中,所述写入单元在所述表中已经存储有与所生成的所述元素关联数据相同的元素关联数据的情况下,针对与所生成的所述元素关联数据相关联的、在所述连结属性元素数据字段中存储有表示权重的元素数据指定信息的元素关联数据,使该元素关联数据的内容元素数据指定字段的元素数据指定信息的权重的程度增加,所述数据库管理装置还具备提取单元,当被施加针对所述内容元素数据指定字段指定了所述第一元素数据指定信息的检索请求时,所述提取单元提取包含所述第一元素数据的元素关联数据,并且提取与该元素关联数据关联的多元素组数据和多元素组数据连结数据,由此提取相连结的元素数据,所述提取单元提取所述检索请求中的所关联的权重重大的元素关联数据。因而,能够提取写入频度高的元素关联数据。
8)在本发明所涉及的数据库管理装置的数据提取方法中,所述数据库管理装置a)具有以一个记录构成一个元素数据的表,该表至少包括下述四个字段a1)~a4):a1)元素数据指定信息字段,其用于存储用于指定该元素数据的元素数据指定信息;a2)上层元素数据字段,其用于存储用于指定位于该元素数据的上层的上层元素数据的上层元素数据指定信息;a3)连结属性元素数据字段,其用于存储用于指定表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的连结属性元素数据指定信息;以及a4)内容元素数据指定字段,其用于存储用于指定表示所述连结属性的内容的内容元素数据的内容元素数据指定信息,b)所述表至少具有:b1)元素关联数据存储部,其存储元素关联数据;b2)多元素组数据存储部,其存储多元素组数据;以及b3)多元素组数据连结数据存储部,其存储用于将所述元素关联数据与所述多元素组数据的多元素组最上层元素数据进行连结的多元素组数据连结数据,b1)所述元素关联数据是用于指定主元素数据与从元素数据的关联性的数据,在所述元素关联数据中,所述从元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述主元素数据的元素数据指定信息存储于所述上层元素数据字段,表示从所述从元素数据来看的所述主元素数据的谓语关系信息即反向谓语关系信息的元素数据指定信息存储于所述连结属性元素数据字段,b2)所述多元素组数据至少具有起点元素数据、终点元素数据及行径元素数据、以及用于将它们进行连结的多元素组最上层元素数据,b21)在所述多元素组最上层元素数据中,该元素数据的元素数据指定信息分别存储于所述元素数据指定信息字段和所述内容元素数据指定字段,b22)在所述起点元素数据中,所述主元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着源点格的元素数据指定信息存储于所述连结属性元素数据指定字段,b23)在所述终点元素数据中,所述从元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着终点格的元素数据指定信息存储于所述连结属性元素数据指定字段,b24)在所述行径元素数据中,表示从所述主元素数据来看的所述从元素数据的谓语关系信息的元素数据指定信息存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着行径格的元素数据指定信息存储于所述连结属性元素数据指定字段,b3)在所述多元素组数据连结数据中,所述多元素组数据的多元素组最上层元素数据指定信息存储于所述内容元素数据指定字段,所述元素关联数据的元素数据指定信息存储于所述上层元素数据指定字段,表示该多元素组最上层元素数据与该元素关联数据连结着的焦点化属性的连结属性指定信息存储于连结属性元素数据指定字段,c)所述数据库管理装置当被施加针对所述内容元素数据指定字段指定了第一元素数据指定信息的检索请求时,提取包含所述第一元素数据的元素关联数据,并且提取与该元素关联数据关联的多元素组数据和多元素组数据连结数据,由此提取相连结的元素数据。
因而,能够实现在利用所述元素数据指定信息字段、所述上层元素数据字段、所述连结属性元素数据字段以及所述内容元素数据指定字段这样的共通的形式的表来使各种数据连结起来的数据库管理装置中的提取。
9)在本发明所涉及的数据库管理装置的数据提取方法中,除了能够提取包含所述第一元素数据的元素关联数据以外,还能够提取与该元素关联数据关联的多元素组数据和多元素组数据连结数据,由此,能够实现连结到相连结的多元素组数据为止的提取。
10)在本发明所涉及的数据库管理装置的数据写入方法中,所述数据库管理装置a)具有以一个记录构成一个元素数据的表,该表至少包括下述四个字段a1)~a4):a1)元素数据指定信息字段,其用于存储用于指定该元素数据的元素数据指定信息;a2)上层元素数据字段,其用于存储用于指定位于该元素数据的上层的上层元素数据的上层元素数据指定信息;a3)连结属性元素数据字段,其用于存储用于指定表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的连结属性元素数据指定信息;以及a4)内容元素数据指定字段,其用于存储用于指定表示所述连结属性的内容的内容元素数据的内容元素数据指定信息,b)所述表至少具有:b1)元素关联数据存储部,其存储元素关联数据;b2)多元素组数据存储部,其存储多元素组数据;以及b3)多元素组数据连结数据存储部,其存储用于将所述元素关联数据与所述多元素组数据的多元素组最上层元素数据进行连结的多元素组数据连结数据,b1)所述元素关联数据是用于指定主元素数据与从元素数据的关联性的数据,在所述元素关联数据中,所述从元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述主元素数据的元素数据指定信息存储于所述上层元素数据字段,表示从所述从元素数据来看的所述主元素数据的谓语关系信息即反向谓语关系信息的元素数据指定信息存储于所述连结属性元素数据字段,b2)所述多元素组数据至少具有起点元素数据、终点元素数据及行径元素数据、以及用于将它们进行连结的多元素组最上层元素数据,b21)在所述多元素组最上层元素数据中,该元素数据的元素数据指定信息分别存储于所述元素数据指定信息字段和所述内容元素数据指定字段,b22)在所述起点元素数据中,所述主元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着源点格的元素数据指定信息存储于所述连结属性元素数据指定字段,b23)在所述终点元素数据中,所述从元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着终点格的元素数据指定信息存储于所述连结属性元素数据指定字段,b24)在所述行径元素数据中,表示从所述主元素数据来看的所述从元素数据的谓语关系信息的元素数据指定信息存储于所述内容元素数据指定字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着行径格的元素数据指定信息存储于所述连结属性元素数据指定字段,b3)在所述多元素组数据连结数据中,所述多元素组数据的多元素组最上层元素数据指定信息存储于所述内容元素数据指定字段,所述元素关联数据的元素数据指定信息存储于所述上层元素数据指定字段,表示该多元素组最上层元素数据与该元素关联数据连结着的焦点化属性的连结属性指定信息存储于连结属性元素数据指定字段,c)所述数据库管理装置当被提供起点元素数据、终点元素数据及行径元素数据来作为新的多元素组数据时,生成多元素组最上层元素数据并将该多元素组最上层元素数据作为多元素组数据进行写入,并且生成并写入元素关联数据和多元素组数据连结数据。
因而,能够实现利用所述元素数据指定信息字段、所述上层元素数据字段、所述连结属性元素数据字段以及所述内容元素数据指定字段这样的共通的形式的表来使各种数据连结起来的数据库管理装置所进行的数据的写入。
11)本发明所涉及的数据库管理装置是一种数据库管理装置,a)具有以一个记录构成一个元素数据的表,该表至少包括下述四个字段a1)~a4):a1)元素数据指定信息字段,其用于存储用于指定该元素数据的元素数据指定信息;a2)上层元素数据字段,其用于存储用于指定位于该元素数据的上层的上层元素数据的上层元素数据指定信息;a3)连结属性元素数据字段,其用于存储用于指定表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的连结属性元素数据指定信息;以及a4)内容元素数据指定字段,其用于存储用于指定表示所述连结属性的内容的内容元素数据的内容元素数据指定信息,所述数据库管理装置的特征在于,b)所述表至少具有存储元素关联数据的元素关联数据存储部,所述元素关联数据是用于指定主元素数据与从元素数据的关联性的数据,在所述元素关联数据中,所述从元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述主元素数据的元素数据指定信息存储于所述上层元素数据字段,表示从所述从元素数据来看的所述主元素数据的谓语关系信息即反向谓语关系信息的元素数据指定信息存储于所述连结属性元素数据字段,
c)所述数据库管理装置当被施加针对所述内容元素数据指定字段指定了第一元素数据指定信息的检索请求时,提取包含所述第一元素数据的元素关联数据,来提取相连结的元素数据。
因而,能够实现利用所述元素数据指定信息字段、所述上层元素数据字段、所述连结属性元素数据字段以及所述内容元素数据指定字段这样的共通的形式的表来使各种数据连结起来的数据库管理装置所进行的数据的读出。
12)本发明所涉及的数据库管理装置是一种数据库管理装置,a)具有以一个记录构成一个元素数据的表,该表至少包括下述四个字段a1)~a4):a1)元素数据指定信息字段,其用于存储用于指定该元素数据的元素数据指定信息;a2)上层元素数据字段,其用于存储用于指定位于该元素数据的上层的上层元素数据的上层元素数据指定信息;a3)连结属性元素数据字段,其用于存储用于指定表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的连结属性元素数据指定信息;以及a4)内容元素数据指定字段,其用于存储用于指定表示所述连结属性的内容的内容元素数据的内容元素数据指定信息,b)所述表至少具有存储元素关联数据的元素关联数据存储部,所述元素关联数据是用于指定主元素数据与从元素数据的关联性的数据,在所述元素关联数据中,所述从元素数据的元素数据指定信息存储于所述内容元素数据指定字段,所述主元素数据的元素数据指定信息存储于所述上层元素数据字段,表示从所述从元素数据来看的所述主元素数据的谓语关系信息即反向谓语关系信息的元素数据指定信息存储于所述连结属性元素数据字段,c)所述数据库管理装置具备写入单元,当被提供指定了起点元素数据、终点元素数据及行径元素数据的多元素组数据时,该写入单元生成并写入所述元素关联数据。
因而,能够实现利用所述元素数据指定信息字段、所述上层元素数据字段、所述连结属性元素数据字段以及所述内容元素数据指定字段这样的共通的形式的表来使各种数据连结起来的数据库管理装置所进行的数据的写入。
13)本发明所涉及的数据库管理装置是一种数据库管理装置,具备:a)存储单元,其存储有以一个记录构成一个元素数据的表,该表至少包括下述5个字段a1)~a5):a1)元素数据id字段,其用于存储该元素数据的元素数据id;a2)上层元素数据字段,其用于存储位于该元素数据的上层的上层元素数据的id即上层元素数据id;a3)连结属性元素数据字段,其用于存储表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的id即连结属性元素数据id;a4)属性值数据字段,其用于存储用于指定表示所述连结属性的值的属性值的属性值指定id;以及a5)参照元素数据字段,其用于存储所述属性值数据字段中存储的属性值指定id所表示的表述数据、或者参照目标的元素数据id;b)关联单元,其针对某个记录,将所述某个记录置于上层记录的位置,而将在上层元素数据字段中存储有所述某个记录的元素数据id字段中存储的id的记录置于所述某个记录的下层记录的位置,并且所述上层记录与所述下层记录之间的关系被关联为是以下关系:所述下层记录的连结属性元素数据字段中存储的连结属性元素数据所表示的属性具有所述下层记录的属性值数据字段中存储的属性值;以及c)读出单元,其使所述关联单元重复进行所述关联,由此读出对所述上层记录连接有多个下层记录所得到的连结知识数据,d)在所述下层记录的属性值数据字段为空的情况下,所述关联单元指定利用所述参照元素数据字段中存储的id来参照的记录,将所指定出的记录的参照元素数据字段中存储的数据关联为所述属性值数据字段为空的记录的标签。因而,能够实现利用标签数据的数据管理。
14)在本发明所涉及的数据库管理装置中,利用所述参照元素数据字段中存储的id来参照的记录在属性值数据字段和元素数据id字段中存储有相同的id,且在所述参照元素数据字段中存储有字符串。因而,能够采用参照元素数据字段的字符串来作为标签数据。
15)本发明所涉及的数据库管理装置是一种数据库管理装置,具备:a)存储单元,其存储有多个利用至少下述四个数据a1)~a4)定义的个别元素数据:a1)该元素数据的元素数据id;a2)位于该元素数据的上层的上层元素数据的id即上层元素数据id;a3)表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的id即连结属性元素数据id;以及a4)用于指定表示所述连结属性的值的属性值的属性值指定id;b)关联单元,其针对所述存储单元中存储的各个别元素数据,将利用某个元素数据id指定的个别元素数据置于上层个别元素数据的位置,将具有与所述上层个别元素数据的元素数据id一致的上层元素数据id的个别元素数据置于下层个别元素数据的位置,并且所述上层个别元素数据与所述下层个别元素数据之间的关系被关联为是以下关系:所述下层个别元素数据的连结属性元素数据字段中存储的连结属性元素数据所表示的属性具有所述下层个别元素数据的属性值数据字段中存储的属性值;以及c)读出单元,其通过重复进行所述关联,来读出对所述上层个别元素数据连结有多个下层个别元素数据所得到的连结知识数据,d)所述个别元素数据还能够存储所述属性值指定id所表示的表述数据、或者参照目标的个别元素数据的元素数据id,e)所述关联单元在所述下层个别元素数据不具有属性值数据且具有通过所述参照目标的个别元素数据的元素数据id来参照的个别元素数据的元素数据id的情况下,指定利用该元素数据id指定的个别元素数据,将所指定出的个别元素数据的表述数据关联为所述个别元素数据的标签。能够将所述个别元素数据的表述数据关联为所述个别元素数据的标签。
16)在本发明所涉及的数据库管理装置中,关于所述多个连结知识数据中的至少两个以上的连结知识数据,下述条件成立的个别元素数据被存储于所述存储单元。第一连结知识数据的与上层个别元素数据相关联的多个下层个别元素数据中的、至少一个下层个别元素数据不具有所述属性值数据,且关联有通过参照目标的个别元素数据的元素数据id来参照的个别元素数据,第二连结知识数据的与上层个别元素数据相关联的多个下层个别元素数据中的、至少一个下层个别元素数据不具有所述属性值数据,且关联有通过所述参照目标的个别元素数据的元素数据id来参照的个别元素数据,被参照的所述个别元素数据是相同的个别元素数据。
因而,能够提供一种对多个个别元素数据对应一个标签的知识数据库。
17)在本发明所涉及的数据库管理装置中,关于所述多个连结知识数据中的至少两个以上的连结知识数据,下述条件成立的个别元素数据被存储于所述存储单元。第一连结知识数据的与上层个别元素数据相关联的多个下层个别元素数据中的第一下层个别元素数据和第二下层个别元素数据不具有所述属性值数据,且关联有通过所述参照目标的个别元素数据的元素数据id来参照的参照目标的个别元素数据,所述参照个别元素数据是各不相同的个别元素数据。
因而,能够提供一种对一个个别元素数据对应多个标签的知识数据库。
18)在本发明所涉及的数据库管理装置中,关于所述多个连结知识数据中的至少两个以上的连结知识数据,下述条件成立的个别元素数据被存储于所述存储单元,第一连结知识数据的与上层个别元素数据相关联的多个下层个别元素数据中的第一下层个别元素数据和第二下层个别元素数据不具有所述属性值数据,且关联有通过所述参照目标的个别元素数据的元素数据id来参照的参照目标个别元素数据,所述第一下层个别元素数据、第二下层个别元素数据所关联的参照目标个别元素数据不同,第二连结知识数据的与上层个别元素数据相关联的多个下层个别元素数据中的至少两个下层个别元素数据不具有所述属性值数据,且其一方与所述第一下层个别元素数据所关联的参照目标个别元素数据相关联。
因而,能够提供一种对多个个别元素数据对应多个标签的知识数据库。
19)在本发明所涉及的数据库管理装置中,还存储有与所述参照目标个别元素数据不同的另外的参照目标个别元素数据,所述第二连结知识数据的与上层个别元素数据相关联的多个下层个别元素数据中的与所述一方不同的下层个别元素数据与所述另外的参照目标个别元素数据相关联。因此,还能够提供一种参照了所述另外的参照目标个别元素数据的知识数据库。
20)在本发明所涉及的数据库管理装置中,所述下层个别元素数据还与被定义了同所连结的个别元素数据之间的连结属性及其连结属性的值的叙述节数据相关联,该叙述节数据由从所述下层个别元素数据来看的所述上层个别元素数据的谓语关系信息即反向谓语关系信息构成,所述关联单元将各叙述节数据也一并提取。因而,能够提供一种将所述叙述节数据关联起来的知识数据库。
21)在本发明所涉及的数据库管理装置中,还具备加权单元,当针对读出对象的元素被提供上层元素id以及与该上层元素之间的连结属性中的连结属性元素数据及其属性值时,在将所述上层元素id写入上层元素数据字段、并将所述连结属性元素数据写入连结属性元素数据字段、并将该属性值写入属性值数据字段时,该加权单元还生成并存储以下记录:将所述写入对象的元素数据id写入上层元素数据字段,将表示权重的元素数据id写入所述连结属性元素数据字段,将表示权重的程度的元素数据id写入属性值数据字段。因而,能够管理附加了权重的元素数据。
22)在本发明所涉及的数据库管理装置中,在所述下层记录的属性值数据字段为空的情况下,关于所指定出的记录,所述加权单元生成并存储以下记录:将所指定出的所述记录的元素数据id写入上层元素数据字段,将表示权重的元素数据id写入所述连结属性元素数据字段,将表示权重的程度的元素数据id写入属性值数据字段。因而,能够提取写入频度高的元素关联数据。
23)本发明所涉及的数据库管理装置是一种数据库管理装置,具备:a)存储单元,其存储有以一个记录构成一个元素数据的表,该表至少包括下述5个字段a1)~a5):a1)元素数据id字段,其用于存储该元素数据的元素数据id;a2)上层元素数据字段,其用于存储位于该元素数据的上层的上层元素数据的id即上层元素数据id;a3)连结属性元素数据字段,其用于存储表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的id即连结属性元素数据id;a4)属性值数据字段,其用于存储用于指定表示所述连结属性的值的属性值的属性值指定id;以及a5)参照元素数据字段,其用于存储所述属性值数据字段中存储的属性值指定id所表示的表述数据、或者参照目标的元素数据id;以及b)写入单元,其针对写入对象的元素,当被提供上层元素id以及与该上层元素之间的连结属性中的连结属性元素数据及其属性值时,将所述上层元素id写入上层元素数据字段,将所述连结属性元素数据写入连结属性元素数据字段,将该属性值写入属性值数据字段,c)所述写入单元针对写入对象的元素,当被提供上层元素id以及与该上层元素之间的连结属性中的连结属性元素数据及参照目标的元素数据id时,将所述上层元素id写入上层元素数据字段,将所述连结属性元素数据写入连结属性元素数据字段,将参照目标的元素数据id写入参照元素数据字段。因而,能够实现利用了标签数据的数据管理。
24)本发明所涉及的数据库管理装置是一种数据库管理装置,具备:a)存储单元,存储有以一个记录构成一个元素数据的表,该表至少包括下述5个字段a1)~a4):a1)元素数据指定信息字段,其用于存储该元素数据的元素数据指定信息;a2)上层元素数据字段,其用于存储用于指定位于该元素数据的上层的上层元素数据的指定信息的上层元素数据指定信息;a3)连结属性元素数据字段,其用于存储用于指定表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的连结属性元素数据指定信息;a4)属性值数据字段,其用于存储用于指定表示所述连结属性的值的属性值的属性值指定信息;以及a5)参照元素数据字段,其用于存储所述属性值数据字段中存储的属性值指定指定信息所表示的表述数据、或者参照目标的元素数据指定信息;以及b)写入单元,其针对写入对象的元素,当被提供上层元素指定信息以及与该上层元素之间的连结属性中的连结属性元素数据及其属性值时,将所述上层元素指定信息写入上层元素数据字段,将所述连结属性元素数据写入连结属性元素数据字段,将该属性值写入属性值数据字段,c)所述写入单元针对写入对象的元素,当被提供上层元素指定信息以及与该上层元素之间的连结属性中的连结属性元素数据及参照目标的元素数据指定信息时,将所述上层元素指定信息写入上层元素数据字段,将所述连结属性元素数据写入连结属性元素数据字段,将参照目标的元素数据指定信息写入参照元素数据字段。因而,能够实现利用了所述参照目标的元素数据指定信息的数据管理。
25)在本发明所涉及的数据库管理装置中,当被提供由从所述下层个别元素数据来看的所述上层个别元素数据的谓语关系信息即反向谓语关系信息构成的叙述节数据时,将该叙述节数据分为多个记录来如下述那样相关联地存储。
将子数据作为终点格个别元素数据,并将表示所述反向谓语关系的数据作为行径格个别元素数据,来分别相关联,并且将把这些个别元素数据联系在一起的个别元素数据作为叙述节顶层个别元素数据并利用叙述节连结个别元素数据来与所述下层个别元素数据相连结。
能够实现数据的写入。
26)在本发明所涉及的数据库管理装置中,在利用所述连结属性元素数据来指定的元素数据是归属于标签的元素的情况下,向所述写入单元提供上层元素id、与该上层元素之间的连结属性中的连结属性元素数据及参照目标的元素数据id。因而,能够写入连结属性元素数据及参照目标的元素数据id。
27)在本发明所涉及的数据库管理装置中,所述写入单元针对写入对象的元素,当被提供上层元素id以及与该上层元素之间的连结属性中的连结属性元素数据及参照目标的元素数据id时,在将所述上层元素id写入上层元素数据字段、并将所述连结属性元素数据写入连结属性元素数据字段、并将参照目标的元素数据id写入参照元素数据字段时,还生成并存储以下记录:将所述写入对象的元素数据id写入上层元素数据字段,将表示权重的元素数据id写入所述连结属性元素数据字段,将表示权重的程度的元素数据id写入所述属性值数据字段。因而,能够存储写入频度高的元素关联数据。
28)在本发明所涉及的数据库管理装置中,所述写入单元针对所生成的所述元素关联数据,在所述表中已经存储有相同的元素关联数据的情况下,针对与所生成的所述元素关联数据相关联的、在所述连结属性元素数据字段中存储有表示权重的元素数据id的元素关联数据,使其属性值数据字段的元素数据id的权重的程度增加。因而,能够存储写入频度高的元素关联数据。
在本说明书中,“主元素数据”是指元素关联数据中的、在表述为含义树单体的情况下的位于从元素数据的上层的元素数据,在实施方式中,例如,在图6的a中,对于id161〔51〕(苹果)而言,id61〔61〕(本田里纱)相当于“主元素数据”,在图6的b中,对于id191〔61〕(本田里纱)而言,id51(苹果)相当于“主元素数据”。
另外,“被施加指定了所述主元素数据id的检索请求”是以下概念:当然包括从数据库使用者直接提供指定了主元素数据的检索条件的情况,还包括根据另外的检索条件来进行检索、结果最终探索到主元素数据、再根据主元素数据来进行检索的情况。
另外,元素数据id字段、上层元素数据字段、连结属性元素数据字段、属性值数据字段、参照元素数据字段在实施方式中分别与id字段61、联系字段63、关系字段64、含义字段62、参考字段65相当。
含义元素数据与实施方式中的含义树的顶层单体相当。另外,个别元素数据在实施方式中与各记录相当。连结知识数据在实施方式中与顶层单体及同顶层单体相连结的下层单体的集合相当。
此外,关于所述上层记录与所述下层记录之间的关系,当然包括多个下层记录并列地关联的情况,也包括多个下层记录阶梯状地关联的情况这双方。
标签元素数据与实施方式中的参考树的顶层单体相当。
通过参酌实施方式和附图,本发明的特征、其它目的、用途、效果等会变得更加明确。
附图说明
图1是数据库管理装置1的功能框图。
图2是表示数据库管理装置1中的数据表的数据结构的图。
图3是利用cpu实现数据库管理装置1的情况下的硬件结构。
图4是表示数据库管理装置1的表中存储的数据的一例的图。
图5是表中存储的数据id与词语的对应表。
图6表示在读出了数据库管理装置1的表中存储的数据的情况下能够获取的含义树。
图7是读出处理的流程图。
图8是表示向表中追加的数据的一例的图。
图8a表示将图6的a~c的含义树进一步关联而得到的树。
图9是对表的写入处理的流程图。
图10是图9步骤s41的详细流程图。
图11是图9步骤s43的详细流程图。
图12表示在读出了所追加的数据的情况下能够获取的含义树。
图13表示在读出了所追加的数据的情况下能够获取的含义树。
图14是权重/时间单体的追加(写入)的流程图。
图15表示在权重/时间单体的追加(写入)前能够获取的含义树。
图16表示在权重/时间单体的追加(写入)后能够获取的含义树。
图17是与图16的含义树对应的数据。
图18表示在权重/时间单体的追加(写入)后能够获取的另外的含义树。
图19表示在权重/时间单体的追加(写入)后能够获取的另外的含义树。
图20表示权重/时间单体的追加(读出时)的含义树。
图21是权重/时间单体的追加(读出时)的流程图。
图22是图21步骤s19的详细流程图。
图23是在参考字段中追加有标签的情况下的表的一例。
图24表示在参考字段中追加有标签的情况下的树。
图25是追加参考树之前的含义树的一例。
图26是追加了参考树之后的含义树的一例。
图27是读出处理的流程图。
图28是图27的步骤s123的详细流程图。
图29是存在多对一的参考关系的情况下的表的一例。
图30是读出了图29的表的情况下的树结构。
图31是存在一对多的参考关系的情况下的表的一例。
图32是读出了图31的表的情况下的树结构。
图33是存在多对多的参考关系的情况下的表的一例。
图34是读出了图33的表的情况下的树结构。
图35是写入前的表的一例。
图36是向表中追加的记录的一例。
图37是叙述节数据的输入处理流程图。
图38是叙述节数据的输入画面的一例。
图39是选择了追加按钮的情况下的输入画面的一例。
图40是对表的写入处理的流程图。
图41是图40步骤s41的详细流程图。
图42是接着图41的流程图。
图43是图40步骤s44的详细流程图。
图44是图43步骤s126的详细流程图。
图45是写入图36的记录前的树结构。
图46是写入图36的记录后的树结构。
图47是第三实施方式的功能模块。
附图标记说明
1:数据库管理装置;23:cpu;27:存储器。
具体实施方式
1.功能框图
在图1中示出本发明所涉及的数据库管理装置1的功能框图。数据库管理装置1具备表10、提取单元6以及写入单元7,其中,表10具有元素关联数据存储部3、多元素组数据存储部4以及多元素组数据连结数据存储部5。
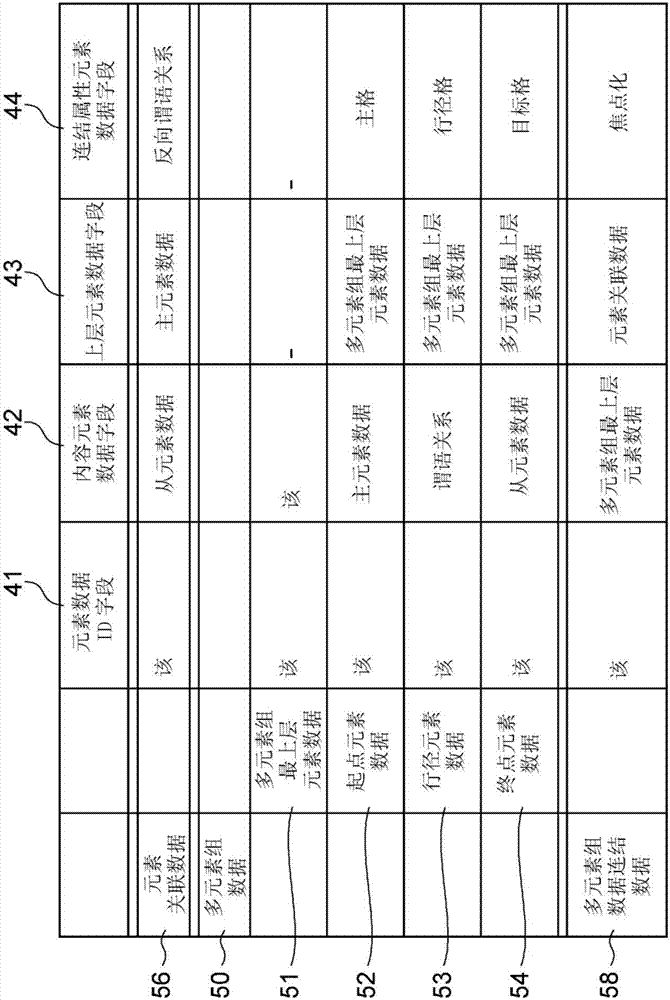
使用图2来说明表10的数据结构。表10由多个记录构成,各记录具有元素数据id字段41、内容元素数据指定字段42、上层元素数据字段43、连结属性元素数据字段44。
元素数据id字段41中存储该元素数据的元素数据id。上层元素数据字段43中存储位于该元素数据的上层的上层元素数据的id即上层元素数据id。连结属性元素数据字段44中存储表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的id即连结属性元素数据id。内容元素数据指定字段42中存储用于指定表示所述连结属性的内容的内容元素数据的内容元素数据id。
对元素关联数据56、多元素组数据50以及多元素组数据连结数据58的各字段中存储的数据进行说明。
元素关联数据56是用于指定主元素数据与从元素数据的关联性的数据,在元素关联数据56中,从元素数据的元素数据id存储于内容元素数据指定字段42,主元素数据的元素数据id存储于上层元素数据字段43,表示从从元素数据来看的主元素数据的谓语关系信息即反向谓语关系信息的元素数据id存储于连结属性元素数据字段44。
多元素组数据50至少具有起点元素数据52、终点元素数据54及行径元素数据53、以及用于将它们进行连结的多元素组最上层元素数据51。
在多元素组最上层元素数据51中,该元素数据的id分别存储于所述元素数据id字段41和内容元素数据指定字段42。在起点元素数据52中,主元素数据的元素数据id存储于内容元素数据指定字段42,最上层元素数据的元素数据id存储于上层元素数据字段43,意味着源点格的元素数据id存储于连结属性元素数据指定字段44。在终点元素数据54中,从元素数据的元素数据id存储于内容元素数据指定字段42,最上层元素数据的元素数据id存储于上层元素数据字段43,意味着终点格的元素数据id存储于连结属性元素数据指定字段44。在行径元素数据53中,表示从主元素数据来看的从元素数据的谓语关系信息的元素数据id存储于内容元素数据指定字段42,最上层元素数据的元素数据id存储于上层元素数据字段43,意味着行径格的元素数据id存储于连结属性元素数据指定字段44。
在多元素组数据连结数据58中,多元素组数据50的多元素组最上层元素数据id存储于内容元素数据指定字段42,元素关联数据的元素数据id存储于上层元素数据指定字段43,表示该多元素组最上层元素数据与该元素关联数据连结着的焦点化属性的连结属性id存储于连结属性元素数据指定字段44。
当被施加了针对上层元素数据字段43指定了主元素数据id的检索请求时,图1所示的提取单元6提取包含该主元素数据的元素关联数据,提取包含所提取出的该元素关联数据的元素数据id的多元素组数据连结数据58,提取利用所提取出的多元素组数据连结数据来指定的多元素组数据50,从而提取相连结的元素数据。
当被提供起点元素数据52、终点元素数据54、行径元素数据53来作为新的多元素组数据时,写入单元7执行下述多元素组数据生成步骤、元素关联数据生成步骤以及多元素组数据连结数据生成步骤。
在多元素组数据生成步骤中,写入单元7生成所提供的起点元素数据52、终点元素数据54、行径元素数据53的多元素组最上层元素数据51,将该多元素组最上层元素数据51与所提供的起点元素数据52、终点元素数据53、行径元素数据54一起作为多元素组数据50写入表10。另外,在元素关联数据生成步骤中,写入单元7生成以下的元素关联数据56并将该元素关联数据56写入表10:将该起点元素数据的内容元素数据指定字段的元素数据id写入上层元素数据字段,将该终点元素数据的内容元素数据指定字段的元素数据id写入内容元素数据指定字段,将与该行径元素数据的内容元素数据指定字段的元素数据id处于反向关系的元素数据id写入连结属性元素数据字段。在多元素组数据连结数据生成步骤中,写入单元7生成以下的多元素组数据连结数据58并将该多元素组数据连结数据58写入表10:将所生成的所述多元素组最上层元素数据的元素数据id写入内容元素数据指定字段42,将所生成的所述元素关联数据的元素数据id写入上层元素数据字段43,将所述焦点化属性的连结属性的元素数据id写入连结属性元素数据指定字段44。
由此,能够以简易的数据结构来得到多个知识连结起来的数据。
2.硬件结构
使用图3来说明图1所示的数据库管理装置1的硬件结构。该图是使用cpu来构成数据库管理装置1的硬件结构的一例。
数据库管理装置1具备cpu23、存储器27、硬盘26、监视器30、光学式驱动器25、输入装置28、通信板31以及总线29。cpu23按照硬盘26中存储的各程序,经由总线29对各部进行控制。
硬盘26用于存储操作系统程序26o(以下略称为os)、主程序26p。
在主程序26p的处理中,关于一般的数据库管理处理中的处理,除了数据写入处理和检索(提取)处理以外均与以往是同样的。在后面叙述所述写入和检索处理。在数据存储部26k中存储如图4所示的表。
说明所述表的结构。id字段61、含义字段62、联系字段63、关系字段64分别相当于图2的元素数据id字段41、内容元素数据指定字段42、上层元素数据字段43、连结属性元素数据字段44。参考字段65是表示参照目标的字段。
在本实施方式中,将由所述五维的数据构成的各记录命名为单体(monad)。并非在五维中全部存储有数据,也存在空的字段。
在图4中,记录r4~r72是定义单体。定义单体是指以下单体:id字段61和含义字段62存储有相同的id,除此以外的字段为空。
图5中示出含义字段62中的各id的对应。例如,id26与“地点”对应。因而,图4中的记录r26的单体意味着在含义字段62中存储有“地点”的单体。
记录r161是主从单体。主从单体是指,在联系字段中存储与两个定义单体有关的上层下层的连结关系,在关系字段中存储所述连结关系中的连结属性。主从单体相当于图2的元素关联数据56。
记录r131~135分别是叙述节构成单体,相当于图2的多元素组数据50。记录r131是最上层单体,记录r132是起点单体,记录r133是行径单体,记录r134是终点单体。起点单体、行径单体、终点单体分别相当于图2的起点元素数据52、行径元素数据53、终点元素数据54。记录r135是记录132的单体(起点单体)所连结的叙述节构成单体。
记录r162是叙述节连结单体,相当于图2的多元素组数据连结数据58。
主程序能够读出所述记录r131~r135、r161~r164并将各单体进行连结,由此生成如图6的a所示的树结构的数据(以下称为含义树)。在后面叙述所述处理。
另外,同样地,能够读出记录r131~r135、r191、r192并将各单体进行连结,由此生成如图6的b所示的含义树,并且能够读出记录r131~r135、r193、r194并将各单体进行连结,由此生成如图6的c所示的含义树。
说明图6中的表述。将含义树中的最上层的单体称为顶层单体。在图6的a中,顶层单体被表述为“61〔61〕(本田里纱)”。这示出了id61的记录的含义字段是“61”。另外,关于括弧内的(本田里纱),为了易于理解含义树中的单体的关系而根据图5的对应表来表述了与“61”对应的词语。
id61的单体的下层连结有id161的单体。id161的单体被表述为“161〔51〕(苹果)”。这示出了id161的记录的含义字段62是“51”。另外,关于括弧内的“苹果”,根据图5的对应表来表述了与“51”对应的词语(苹果)。另外,“〔34〕(-吃)”示出了id61〔61〕(本田里纱)与id61〔51〕(苹果)之间的关系,因此以该方式表述。
在本实施方式中,采用了linux(注册商标或商标)作为操作系统程序(os)26o,但并不限定于此。
此外,上述各程序是借助光学式驱动器25从存储有程序的cd-rom25a读出后安装到硬盘26中的。此外,除了cd-rom以外,也可以从软盘(fd)、ic卡等能够由计算机读取程序的记录介质安装到硬盘。并且,还可以使用通信线路来下载。
在本实施方式中,从cd-rom将程序安装到硬盘26,由此间接地使计算机执行cd-rom中存储的程序。但是,并不限定于此,也可以从光学式驱动器25直接执行cd-rom中存储的程序。此外,作为能够由计算机执行的程序,当然包括仅通过原样安装就能够直接执行的程序,但也包括需要暂时变换为其它形态等的程序(例如,对进行了数据压缩的程序进行解压缩等),还包括能够与其它模块部分相组合地执行的程序。
3.流程图
3.1关于读出处理
使用图7来说明读出各单体来生成含义树的主程序26p的处理。在该情况下,说明利用与“本田里纱”对应的“61”来进行读出的情况。
cpu23提取在联系字段63中存储有检索对象id的记录来作为主从单体(步骤s1)。在该情况下,“本田里纱”的id为“61”,因此在联系字段63中具有“61”的记录被提取。在图4的情况下,记录r161、r163符合该情况。
cpu23提取主从单体的上层单体来作为顶层单体(步骤s2)。在图4的情况下,在记录r161和记录r163的联系字段63中存储有“61”。因而,记录r61作为顶层单体而被提取。
cpu23对处理编号i进行初始化(步骤s3),将所提取的第i个主从单体的叙述节连结单体全部提取(步骤s4)。在本实施方式中,是否为叙述节连结单体是通过是否为以下记录来判断的:在联系字段63中存储有主从单体的记录id,且在关系字段中存储有“焦点化”。在该情况下,参照图5,“24”意味着“焦点化”。
在该情况下,提取出在联系字段63中存储有所提取出的第0个主从单体r161的记录id“161”、关系字段64为“24”的记录即记录r162来作为叙述节连结单体。
cpu23对处理编号j进行初始化(步骤s5)。
cpu23提取所提取出的叙述节连结单体中的第j个叙述节连结单体的叙述节构成单体的最上层单体(步骤s7)。在该情况下,作为第0个叙述节连结单体的记录r162的含义字段存储有“131”。因而,提取出记录r131来作为对应的叙述节构成单体的最上层单体。
cpu23判断所提取出的最上层单体的id是否已经提取过(步骤s9)。在该情况下,该最上层单体的id尚未提取过,因此cpu23提取在联系字段63中存储有所提取出的最上层单体的id的记录,并决定连结关系(步骤s11)。
具体地说,cpu23提取在联系字段63中存储有记录r131的含义字段62中存储的“131”的记录r132~r134。记录r132~r134的联系字段63为“131”,因此可知各自位于记录r131的下层。另外,记录r132的关系字段64为“4”,含义字段62为“61”。因而,参照图5,在记录131的下层以源点格s的关系连接有“本田里纱”。关于记录r133、r134也是,在记录r131的下层以行径格p的关系连接有“吃”,以终点格g的关系连接有“苹果”。
cpu23判断是否存在与所提取出的叙述节构成单体连接的单体(图7步骤s13)。具体地说,判断是否存在以下记录:在联系字段63中存储有作为叙述节构成单体提取出的记录r132~r134中的任一记录的id。
在该情况下,在图4中,存在在联系字段63中存储有“132”的记录r135。因此,cpu23提取记录r135,并且决定连结关系(步骤s15)。在该情况下,作为连结关系,记录r135的联系字段63为“132”,因此可知记录r135位于记录r132的下层。另外,记录r135的关系字段64为“26”,含义字段62为“71”。因而,参照图5,在记录131的下层以“地点”的关系连接有“自助餐厅(cafeteria)”。
cpu23判断对全部叙述节连结单体的处理是否均已结束(步骤s16)。在该情况下,对全部叙述节连结单体的处理均已结束,因此cpu23判断对全部主从单体的处理是否均已结束(步骤s17)。在该情况下,对记录163的处理尚未结束,因此cpu23将处理编号i加1(步骤s18),进入步骤s4。
cpu23将第1个主从单体的叙述节连结单体全部提取(步骤s4)。在该情况下,提取出在联系字段63中存储有所提取出的第1个主从单体r163的记录id“163”、关系字段64为“24”的记录即记录r164来作为叙述节连结单体。
cpu23对处理编号j进行初始化(步骤s5),提取所提取出的叙述节连结单体中的第0个叙述节连结单体的叙述节构成单体的最上层单体(步骤s7)。在该情况下,作为第0个叙述节连结单体的记录r164的含义字段存储有“131”。因而,提取出记录r131来作为对应的叙述节构成单体的最上层单体(步骤s7)。
cpu23判断所提取出的最上层单体的id是否已经提取过(步骤s9)。在该情况下,记录r131已经提取过,因此cpu23不进行步骤s11、步骤s13、步骤s15的处理,判断对全部叙述节连结单体的处理是否均已结束(步骤s16)。在该情况下,对全部叙述节连结单体的处理均已结束,因此cpu23判断对全部主从单体的处理是否均已结束(步骤s17)。
在该情况下,对全部主从单体的处理均已结束,因此cpu23生成将所提取出的单体进行连结而得到的知识数据库(步骤s20)。
具体地说,只要利用步骤s11、步骤s15中决定的连结关系来将所提取出的记录进行连接即可。由此,能够得到图6的a所示的含义树。
此外,通过利用所述读出处理使连结关系进一步继续,还能够不断地进行联想。
例如,id161的记录的含义字段62是id51。当提取在联系字段63中存储有id51的记录时,记录id191符合该条件。只要将所提取出的记录作为主从单体来进行图7步骤s2以下的处理即可。由此,能够得到如图8a所示的与多个含义树有关的连结关系的数据。
3.2写入处理
使用图9来说明主程序26p进行的各单体的写入处理。下面说明以下情况:在对“本田里纱在自助餐厅吃桔子”这一文章进行分析来提供了数据“本田里纱”(源点格)、“桔子”(终点格)及“吃”(行径格)、“自助餐厅”(地点)的情况下,生成图8的a、b、c所示的叙述节构成数据、叙述节连结单体以及主从单体。
3.2.1叙述节构成单体的写入处理
cpu23生成叙述节构成单体并进行写入(图9步骤s41)。图10中示出步骤s41的详细内容。cpu23决定起点单体、行径单体以及终点单体(图10步骤s51)。具体地说,提取所提供的数据“本田里纱”、“桔子”、“吃”、“自助餐厅”中的、作为属性附加有“源点格”、“终点格”以及“行径格”的数据。
cpu23判断是否存在除“源点格”、“终点格”以及“行径格”以外的单体候选的数据(步骤s53)。在该情况下,除“本田里纱”(源点格)、“桔子”(终点格)及“吃”(行径格)以外存在单体候选的数据,因此将“自助餐厅”决定为spg连结单体。cpu23进入步骤s57,生成最上层单体,并写入叙述节构成单体。
具体地说,cpu23进行下述的处理。首先,决定最上层单体的id。关于所述id,使用空闲的id。在此,设为id“125”。cpu23向id字段61和含义字段62写入“125”。接着,cpu23决定起点单体的id。关于该id,也使用空闲的id。在此,设为id“126”。cpu23参照图5可知,“本田里纱”、“源点格”分别与“61”、“4”对应。因而,cpu23向id字段61写入“126”,向含义字段62写入“61”,向联系字段63写入最上层单体的id“125”,向关系字段64写入“4”。
对于“桔子”(终点格)和“吃”(行径格)也是同样的。
另外,关于未作为“源点格”、“终点格”及“行径格”提取出的单体,基于规定的规则来设为与起点单体、行径单体及终点单体中的任一个单体连结的单体。
在本实施方式中,设为“地点”与起点单体和终点单体连结,“时间”和“工具”与行径单体连结。此外,也可以设为能够变更所连结的单体。在此,“时间”是与日期时间、时刻有关的属性信息。“工具”例如是“用菜刀”这样的属性信息。
此外,在本实施方式中,为了省略冗长,设“地点”仅与起点单体关联。
因而,由于“自助餐厅”表示“地点”,因此与起点单体关联。具体地说,存储为以下记录:将与“自助餐厅”对应的“71”存储到含义字段62,将记录126的含义字段62中存储的id“126”存储到联系字段63,将与“地点”对应的“26”存储到关系字段64。所述记录的记录id与上述相同,是任意的,但是在此设存储为id“129”。
由此,图8的a所示的叙述节构成单体作为记录r129被写入表。
3.2.2含义树单体和叙述节连结单体的写入
接着,cpu23生成含义树单体和叙述节连结单体并将这些单体写入表(图9步骤s43)。使用图11来说明步骤s43的详细内容。
cpu23决定含义树单体的候选(图11步骤s61)。在本实施方式中,作为含义树单体的候选,将两种单体作为候选。其一是主从单体。主从单体是表示利用叙述节构成单体的起点单体的含义字段62中存储的id来指定的单体与利用终点单体的含义字段62中存储的id来指定的单体之间的关联的单体。进一步来说,生成两种所述主从单体。第1种主从单体是表示在“本田里纱”的上层连结有“桔子”、其关系处于从“本田里纱”来看“桔子”时的“吃”的谓语关系的单体。另外,另一种与其相反,是表示在“桔子”的上层连结有“本田里纱”、其关系处于从“桔子”来看“本田里纱”时的“负(以下略称为“-”)吃”的反向谓语关系的单体。
在此,谓语关系信息是表示从利用起点单体的含义字段62中存储的id来指定的定义单体来看的、利用终点单体的含义字段62中存储的id来指定的定义单体的谓语关系的信息。与此相对地,反向谓语关系信息是表示从利用终点单体的含义字段62中存储的id来指定的定义单体来看的、利用起点单体的含义字段62中存储的id来指定的定义单体的谓语关系的信息。即,“-吃”表示“吃”的反向的谓语关系。
在本实施方式中,联系字段63中存储的单体位于比含义字段62中存储的单体更靠上层的位置,关系64中存储的单体表示从含义字段62中存储的单体来看的情况下的两者的关系。因而,在以谓语关系进行定义的情况下,当将上下关系变为反向时,变成以反向谓语关系来进行定义,从而能够生成两种主从单体。
作为含义树单体的候选,除主从单体以外的单体为详细单体。详细单体是与构成所述叙述节构成单体的所述起点单体、所述行径单体及所述终点单体中的任一单体关联的单体。例如,后述的图16中的id365~id368分别符合该条件。
在本实施方式中,将在关系字段中存储“地点”、“时间”、“工具”作为属性的单体作为详细单体。在该情况下,“自助餐厅”具有属性“地点”。在本实施方式中,如已经说明的那样,“地点”设为与起点单体相关联,因此,表示“自助餐厅”通过“地点”来与利用起点单体的含义字段62指定的单体即“本田里纱”相关联的单体也被作为含义树单体的候选。关于这样关联的单体,也与主从单体同样地生成“本田里纱”与“自助餐厅”通过“-地点”进行关联这样的从反向来看的含义树单体候选。因而,在该情况下,合计决定四个候选。
cpu23对处理编号i进行初始化(图11步骤s63),根据第0个含义树单体候选生成含义树单体(步骤s65)。在该情况下,生成表示在步骤s61中决定的单体候选“桔子”相对于“本田里纱”处于“-吃”的关系的单体。具体地说,在含义字段62中存储表示“桔子”的id,在联系字段63中存储表示“本田里纱”的id,在关系字段64中存储表示“-吃”的id。由此生成含义树单体。
cpu23判断所生成的含义树单体在表中是否已经存在(图11步骤s67)。在该情况下,所生成的含义树单体在表中不存在,因此cpu23向表进行写入(步骤s69)。关于所写入的id,使用空闲的id。在此,设为id“166”。cpu23参照图5可知,“本田里纱”、“桔子”、“-吃”分别与“61”、“72”、“34”相对应。因而,cpu23向id字段61写入“166”,向含义字段62写入“72”,向联系字段63写入“61”,向关系字段64写入“34”。
cpu23生成叙述节连结单体并将该叙述节连结单体写入表(步骤s70)。叙述节连结单体是将叙述节构成单体的最上层单体与含义树单体进行连结的单体。在该情况下,叙述节构成单体的最上层单体是“125”,所连接的含义树单体是“166”。另外,在本实施方式中,采用“焦点化”这一属性来作为表示它们的关系的属性。因而,cpu23向空闲的id61“167”的含义字段62写入“125”,向联系字段63写入“166”,向关系字段64写入“24”。
cpu23判断针对步骤s61中决定的全部候选是否处理均已结束(图11步骤s72)。在该情况下,尚未全部结束,因此将处理编号i加1(步骤s73),针对第1个候选生成含义树单体(步骤s65)。
在该情况下,生成表示在步骤s61中决定的单体候选“本田里纱”相对于“桔子”处于“吃”的关系的单体。具体地说,在含义字段62中存储表示“本田里纱”的id,在联系字段63中存储表示“桔子”的id,在关系字段64中存储表示“吃”的id。由此生成含义树单体。
cpu23判断所生成的含义树单体在表中是否已经存在(图11步骤s67)。在该情况下,所生成的含义树单体在表中不存在,因此cpu23向表中写入所生成的含义树单体(步骤s69)。关于所写入的id,同样使用空闲的id。在此,设为id“195”。cpu23参照图5可知,“桔子”“本田里纱”“吃”分别与“72”“61”“31”对应。因而,cpu23向id字段61写入“195”,向含义字段62写入“61”,向联系字段63写入“72”,向关系字段64写入“31”。
接着,cpu23生成叙述节连结单体,针对在步骤s69中写入的含义树单体生成并写入叙述节连结单体(步骤s70)。
在该情况下,叙述节构成单体的最上层单体是“125”,前述所生成的含义树单体是“195”。因而,cpu23向id字段61写入空闲的“196”,向含义字段62写入“125”,向联系字段63写入“195”,向关系字段64写入“24”。
cpu23判断针对步骤s61中决定的全部候选是否处理均已结束(图11步骤s72)。在该情况下,尚未全部结束,因此将处理编号i加1(步骤s73),针对第2个候选生成含义树单体(步骤s65)。
在该情况下,生成表示在步骤s61中决定的单体候选“自助餐厅”相对于“本田里纱”处于“地点”的关系的单体。
具体地说,生成在含义字段62中存储有表示“自助餐厅”的id、在联系字段63中存储有表示“本田里纱”的id、在关系字段64中存储有表示“地点”的id的含义树单体。
cpu23判断所生成的含义树单体在表中是否已经存在(图11步骤s67)。在该情况下,所生成的含义树单体(含义字段62中为“71”、联系字段63中为“61”、关系字段64中为“26”)在表中存在(记录r163),因此cpu23不将所述含义树单体写入表,而生成将前述已经存在的含义树单体(记录r163)与叙述节构成单体进行连结的叙述节连结单体,并进行写入处理(步骤s77)。
在该情况下,叙述节构成单体的最上层单体是“125”,前述已经存在的含义树单体是“163”。因而,cpu23向id字段61写入空闲的“197”,向含义字段62写入“125”,向联系字段63写入“163”,向关系字段64写入“24”。
cpu23将前述已经存在的含义树单体(记录r163)的省略标志设为开启(步骤s78)。在后面叙述所述省略标志。
cpu23判断针对步骤s61中决定的全部候选是否处理均已结束(图11步骤s72)。在该情况下,尚未全部结束,因此将处理编号i加1(步骤s73),针对第3个候选生成含义树单体(步骤s65)。
在该情况下,生成表示在步骤s61中决定的单体候选“本田里纱”相对于“自助餐厅”处于“-地点”的关系的单体。
具体地说,生成在含义字段62中存储有表示“本田里纱”的id、在联系字段63中存储有表示“自助餐厅”的id、在关系字段64中存储有表示“-地点”的id的含义树单体。
cpu23判断所生成的含义树单体在表中是否已经存在(图11步骤s67)。在该情况下,关于所生成的含义树单体(含义字段62中为“61”、联系字段63中为“71”、关系字段64中为“42”),在表10中已经存在存储有相同的数据的记录r193。因而,cpu23不将所生成的含义树单体写入表,而生成将前述已经存在的含义树单体(记录r193)与叙述节构成单体进行连结的叙述节连结单体,并进行写入处理(步骤s77)。
在该情况下,叙述节构成单体的最上层单体是“125”,前述已经存在的含义树单体是“193”。因而,cpu23向id字段61写入空闲的“198”,向含义字段62写入“125”,向联系字段63写入“193”,向关系字段64写入“24”。
cpu23将前述已经存在的含义树单体(记录r163)的省略标志设为开启(步骤s78)。
cpu23判断针对步骤s61中决定的全部候选是否处理均已结束(图11步骤s72)。在该情况下,针对所生成的四个候选,处理均已结束,因此cpu23结束写入处理。
这样,在本实施方式中,在表中已经存储有相同的含义树单体的情况下,不将该含义树单体重复写入表中。这是因为,与相同组合的含义树单体存在多个相比,如后述那样以权重的方式进行处理能够排除重复数据,并且能够实现检索速度的提高、数据容量的降低。
通过对所生成的表的数据进行已经说明那样的读出处理,能够得到新的含义树。例如,通过利用“本田里纱”进行检索,能够得到如图12所示的含义树。这是在图6的a的含义树中追加了关于“桔子”的信息而得到的含义树。
另外,通过利用“桔子”进行检索,能够得到如图13的a所示的含义树。
另外,通过利用“自助餐厅”进行检索,能够得到如图13的b所示的含义树。这是在图6的c的含义树中追加了关于“自助餐厅”与“本田里纱”之间的关联的叙述节数据而得到的含义树。
此外,在本实施方式中,设为“源点格”与“终点格”通过“行径格”进行连接,来决定主从单体,并且,关于详细单体,在表中仅存储相连接的关系、即能够生成如图6所示的含义树的记录,但是如果有三个单体,则也能够根据它们生成以下记录:该记录能够生成定义了三个单体的关系性的含义树单体。例如,也可以将作为“行径格”的“吃”设为顶层单体并通过“地点”来连接“自助餐厅”,进一步来说,还可以生成能够生成将不直接连接的“苹果”与“自助餐厅”通过“地点”进行连接的含义树的记录。
4.第二实施方式
在上述实施方式中,在写入含义树单体时,设为在已经存在的情况下使用已经存在的单体,设为不重复进行写入。即,即使要写入相同的单体,也不知道其频度。
与此相对地,在第二实施方式中,设为在写入时和读出时对各单体赋予权重单体和时间单体。这样,事前对各单体赋予权重,提取权重大的单体或被赋予了新的日期的单体,由此能够得到考虑到时代的变迁等的知识数据。
附带权重的单体、时间单体的写入处理是通过在第一实施方式中的图9步骤s43之后执行图14的流程图来执行的。在说明所述处理之前,说明在附带权重的情况下与不附带权重的情况下,作为含义树读出的情况的不同。
在图15中,与第一实施方式相同地,将不附带权重的情况下的含义树单体相关联地进行显示。在图17的a、b中示出与图15对应的各记录数据的各字段中存储的数据。关于各个记录的数据,与第一实施方式相同。另外,如已经说明的那样,各记录的id意味着什么含义存储在图5中,在此省略。下面使用图15的含义树来进行说明。
简单地说明图15的含义树,id304[81](达菲(tamiflu))与id73〔73〕(流行性感冒)通过〔74〕(治疗药物)相关联。另外,id374[67](高桥四郎)与id73〔73〕(流行性感冒)通过〔77〕(-生病)相关联。另外,作为叙述节连结单体的id305〔361〕与id304[81](达菲)通过〔24〕(焦点化)相关联。对于叙述节构成单体的最上层单体id361,通过“4〔4〕(s)”的关系关联有id362〔62〕(村上三郎),通过“5〔5〕(p)”的关系关联有id363〔35〕(治疗),通过“6〔6〕(g)”的关系关联有id364〔67〕(高桥四郎)。
另外,对于id362〔62〕(村上三郎),通过〔26〕(地点)的关系关联有id365〔68〕(京都医院)。对于id363〔35〕(治疗),通过〔74〕(治疗药物)的关系关联有id366〔81〕(达菲),并且通过〔25〕(时间)的关系关联有id367〔91〕(2014/11/5)。对于id364〔67〕(高桥四郎),通过〔75〕(生病)的关系关联有id368〔73〕(流行性感冒)。
即,所述叙述节构成单体所意味的是,“村上三郎于2014/11/5在京都医院使用达菲作为治疗药物来对流行性感冒的高桥四郎进行了治疗”。通过所述叙述节连结单体,id304[81](达菲)与叙述节构成单体相关联。
图16中示出对图15所示的含义树单体赋予了权重单体和时间单体的含义树。在图16中,对除叙述节构成单体以外的单体赋予有权重单体和时间单体。在此,作为时间单体,设为数据写入时的2014/11/6。
如果在该情况下,则对于id374[67](高桥四郎),通过[27](权重)连结作为权重单体的id505[43](权重1),通过[25](时间)连结作为时间单体的id404[92](2014/11/6)。关于id73〔73〕(流行性感冒)、id304[81](达菲)、id305〔361〕也是同样的。
使用图17的c来说明权重单体和时间单体的具体的记录的结构。在作为权重单体的记录r505中,在联系字段63中存储有“374”,在含义字段62中存储有“43”,在关系字段64中存储有“27”。作为时间单体的记录r404也同样,在记录r404中,在联系字段63中存储有“374”,在含义字段62中存储有“92”,在关系字段64中存储有“25”。
使用图14来说明在追加图16所示的权重单体和时间单体的情况下的含义树的生成处理。
首先,通过图9步骤s41、步骤s43的处理,在图15的含义树的情况下,生成如图17的a、b所示的数据。图17的a是叙述节构成单体,图17的b是主从单体、详细单体以及叙述节连结单体。
此外,在第一实施方式中,关于含义树单体,说明了仅生成限定的含义树单体的情况,而在本实施方式中设为,针对叙述节构成单体的关联生成去掉了制约的组合,并且仅在定义了其关联的情况下允许生成。即,如果是图15所示的叙述节构成单体的关系,则[62](村上三郎)与[81](达菲)不直接关联。但是,能够存在例如构成[62](村上三郎)与[81](达菲)通过[74](治疗药物)相关联的含义树的记录等各种组合。在本实施方式中,设为生成所有的生成这些组合的含义树单体的记录。并且,事前设定为组合被允许的定义,仅针对被设定的组合生成与含义树单体对应的记录。图15是定义了通过[74](治疗药物)将[81](达菲)与[73](流行性感冒)进行关联的情况。
cpu23提取所写入的单体中的所有主从单体、详细单体及叙述节连结单体以及顶层单体(图14步骤s81)。在该情况下,根据图17的a、b,id304、id305、id374、id73的各单体被提取。
cpu23判断是否存在省略标志(图14步骤s83)。由于在图11步骤s77中,在是已经存在的单体的情况下不生成重复的单体,因此为了对该单体也进行权重/时间单体的附加处理而进行该判断。
在该情况下,不存在省略标志开启的单体,因此进入到步骤s87,cpu23对处理编号p进行初始化(图14步骤s87),判断第0个单体是否为所写入的单体(步骤s89)。在该情况下,第0个单体是id304的单体,不是在步骤s85中追加为处理对象的单体,因此cpu23生成以下记录:将联系字段设为第0个单体的id304,将关系字段设为“27”,将含义字段设为“43”(权重1)。关于所述记录的id,只要使用空闲记录即可。在此,设采用了id503。
cpu23生成以下记录:向联系字段63写入第0个单体的id“304”,向关系字段64写入“25”,向含义字段62写入表示日期时间的单体的id(步骤s95)。
cpu23判断处理对象单体是否全部讨论完成(步骤s97)。在该情况下,尚未全部结束,因此将处理编号p加1,重复步骤s89以下。
第1个单体是id305的单体,是所写入的单体,因此cpu23生成以下记录:将联系字段设为第1个单体的id305,将关系字段设为“27”,将含义字段设为“43”(权重1)(步骤s91)。在此,设采用了id504。
生成以下记录:向联系字段63写入第1个单体的id“305”,向关系字段64写入“25”,向含义字段62写入表示日期时间的单体的id(步骤s95)。
cpu23判断处理对象单体是否全部讨论完成(步骤s97)。在该情况下,尚未全部结束,因此将处理编号p加1,重复进行步骤s89以下。
以下同样地附加权重单体和时间单体。
图17的c中示出所追加的权重单体和时间单体的记录。通过追加这些单体,当利用id73进行读出时,能够读出如图16那样的含义树单体。
另外,当在存储有与图16对应的记录的状态下提供了与“木村五郎于2015/6/10在大阪医院使用达菲作为治疗药物对流行性感冒的铃木次郎进行了治疗”对应的叙述节构成单体的数据时,同样地通过图9、图11以及图14的处理,如成为图18所示的状态那样向表中追加记录。
此外,在从图16的状态起提供了与“木村五郎于2015/6/10在大阪医院使用达菲作为治疗药物对流行性感冒的铃木次郎进行了治疗”对应的叙述节构成单体的数据的情况下,单体id304[81](达菲)已经存在,因此在写入时从图11步骤s67进入到步骤s77。在步骤s77中,生成已经存在的含义树单体的叙述节连结单体,并写入为记录。在该情况下,生成id370的单体。cpu23将单体id304的省略标志设为开启(步骤s78)。
由于像这样省略了写入的省略标志成为开启,因此在图14中,从步骤s83进入到步骤s85,单体id304被追加为处理对象。另外,在单体id304成为处理对象单体时,从步骤s89进入到步骤s93,将在联系字段63中存储有该单体的id、关系字段64为“27”的记录的权重加1(+1)。例如,在该情况下,id503成为表示“权重2”的“44”。此外,关于所述处理,只要预先决定表示将权重+1时的结果的权重(例如权重2)的单体的id即可。
由此,如图18所示,能够对表中存储的单体中的除叙述节构成单体以外的单体赋予权重。例如,对于id73〔73〕(流行性感冒)和id304[81](达菲),权重分别增加为id501〔44〕(权重2)、id503〔44〕(权重2)。
另外,当在表中存储有与如图18所示的树结构对应的记录的状态下针对id73〔73〕(流行性感冒)提供了id330[82](瑞乐沙(relenza))作为治疗药物时,如图19所示,id73〔73〕(流行性感冒)的权重增加为502〔45〕(权重3)。
在本实施方式中,表示权重的id不变更,将含义字段62的数据变更为+1的权重的记录id,由此变更权重,但是也可以生成新的记录并删除以前的id。
说明读出处理中的权重单体和时间单体的追加处理流程图。当在图16的状态下在2015年12月6日利用“流行性感冒”and“达菲”的检索条件来进行读出时,如图20所示,权重单体的权重增加,并且追加时间单体。例如,对于id73〔73〕(流行性感冒),id501〔43〕(权重1)变为id501〔44〕(权重2),并追加了id422〔97〕(2015/12/6)。
使用图21和图22来说明所述处理。在图21中,在图7的步骤s17与步骤s20之间追加了步骤s19。
在图22中示出步骤s19的详细内容。
cpu23从所读出的单体中提取除叙述节构成单体以外的全部单体(步骤s101)。在该情况下,图20所示的单体被提取,因此id305、id304、id43的单体被读出。
cpu23进行对关系字段64为“27”的记录的权重加1(+1)的处理(步骤s103)。具体地说,只要将含义字段62的数据变更为+1的权重的记录id即可。在该情况下,id501、id505、id503、id504全部被变更为意味着“权重2”的id44。
cpu23将关系字段64为“25”的记录全部提取出,对利用各记录的联系字段63指定的记录追加时间单体(步骤s105)。在该情况下,id73、id374、id304、id305分别被追加表示进行读出时的“2015年12月6日”的时间单体。
通过存储这样的“权重”和“时间”,存在如下优点。例如,针对如图17所示的“流行性感冒”使用了“达菲”的使用实例越增加,则其频度越高。因此,能够了解整体性的趋势。另外,作为其详细内容,还连结有叙述节构成单体,因此通过参照该详细内容,还能够了解到在存在略微不同的使用例的情况下根据特性而区分进行着使用等,例如,如果作为属性而存储有年龄,则能够了解到在流行性感冒的治疗中对成人经常使用“达菲”,对儿童使用另外的药等。
另外,通过参照时期,关于仿制药品等,还能够了解到某个药品大概从何时起针对哪种症状进行了使用等。另外,在提取时,在利用“流行性感冒”、“治疗药物”进行了检索时,也会了解如下趋势等:以前曾以高的频度使用“达菲”,而最近使用新药“瑞乐沙”。
通过将这种关于治疗药物的实际使用情况数据库化,即使是在某个领域不太具有知识的医生,通过参照该数据库,也能够进行准确的判断。还能够进行自动诊断。例如,医疗的进步非常快,即使打算创建组入有自动诊断所需的医疗数据的系统,系统制作也追赶不上医疗的进步。如果是本系统,则只要加入60%左右的基本的信息,就能够利用大量的用户的使用例来使本系统成长,能够实现接近100%的自动诊断。
在本实施方式中,设为在基于检索的读出和写入时均赋予权重单体和时间单体。另外,关于权重单体,设为使权重以每次+1的方式增加,但是也可以变更在读出和写入时要增加的权重。
在本实施方式中,设为对于预先设定的组合,不仅针对叙述节构成单体中的直接连结的单体、还针对间接连结的单体也生成与含义树单体对应的记录。但是不限定于此,也可以不受所述设定的制约地针对存在可能性的组合生成所有的相关联的单体。
在第二实施方式中,设为追加权重单体。此时,在写入时已经存在主从单体的情况下不写入所生成的单体,而是通过叙述节连结单体来利用单体〔24〕(焦点化)将主从单体与叙述节构成单体的最上层单体进行连接。因而,即使不存储权重,通过对利用所述焦点化单体连接的叙述节构成单体的最上层单体的个数进行计数,也可知写入频度。
另外,即使存储了相矛盾的数据,也能够不发生矛盾地作为知识数据库进行使用。例如,当提供了“本田里纱讨厌青椒”这一叙述节构成单体时,生成在含义字段中存储表示青椒的id、在联系字段中存储表示本田里纱的id、在关系字段中存储表示“-讨厌(被讨厌)”的id的单体,利用叙述节连结单体与所提供的叙述节构成单体进行连结。
在此,当提供了叙述节“本田里纱喜欢青椒”时,同样地生成在含义字段中存储表示青椒的id、在联系字段中存储表示本田里纱的id、在关系字段中存储表示“-喜欢(被喜欢)”的id的单体,利用叙述节连结单体与所提供的叙述节构成单体进行连结。在该状态下,成为存储有相矛盾的知识的状态。
之后,当又提供了叙述节“本田里纱喜欢青椒”时,针对在含义字段中存储表示青椒的id、在联系字段中存储表示本田里纱的id、在关系字段中存储表示“-喜欢(被喜欢)”的id的单体,利用叙述节连结单体进行连结的叙述节构成单体增加。
在该状态下,利用“本田里纱”*“青椒”进行检索的情况下,读出利用叙述节连结单体进行连结的叙述节构成单体多的一方,由此能够防止读出相矛盾的含义树。
在附加有所述权重单体的情况下,只要读出所述权重单体所表示的权重大的含义树即可。
通过像这样读出写入频度高的一方,能够对相矛盾的概念进行处理。另外,关于读出也是同样的。
关于时间单体也同样,只要设为读出时间上新的一方,就能够适当地操作相矛盾的数据。
在本实施方式中,采用了年月日来作为时间单体,但是也可以一直存储到时刻。
在本实施方式中,作为权重单体,设为在写入和读出时权重+1,但是也可以利用时间单体来进行附带权重。例如,在写入时,在原来的权重为2的情况下,如果与最接近的时间单体的时间之间的差大,则将系数k设为0.3,来设为2+0.3*1=2.3等。也可以动态地变更所述系数。另外,也可以是,不仅是最接近的、而是对所有时间单体与写入时的差进行总计,在该总计大的情况下,权重变轻。也可以是相反地,在最近经常被使用的情况下将权重变大。关于读出时也是同样的。
5.其它实施方式
在上述各实施方式中,在关系字段64中存储从主从单体的下层单体向上层单体连结的情况下的关系。这是为了与详细单体中的关系性一致。
在第一实施方式中,设为在写入时对“本田里纱在自助餐厅吃桔子”这一文章进行分析来提供了数据“本田里纱”(源点格)、“桔子”(终点格)及“吃”(行径格)、“自助餐厅”(地点)的情况,但是也可以在作为模板而各数据的连结状态已指定的状态下提供数据。
在上述实施方式中,说明了作为1台装置来应用的情况,但是也能够通过汇集多个计算机的表数据来得到更加准确的知识数据库。
只要如以下那样进行这种多个数据库的整合即可。1)将含义树单体的顶层单体全部提取。2)选出一个顶层单体,将以该顶层单体为主单体的从单体全部提取。3)关于从单体中的相同的从单体,仅追加叙述节。4)对所有从单体进行这些处理。5)对所有顶层单体重复进行这些处理。
另外,在存在权重单体的情况下,只要还设为将两者合体后的值,时间单体则原封不动地增加连结即可。
在上述实施方式中,为了实现图1所示的功能,使用cpu并利用软件来实现了图1所示的功能。但是,也可以利用逻辑电路等硬件来实现图1所示的功能的一部分或全部。
此外,也可以使操作系统(os)进行上述程序的一部分的处理。
在本说明书中,设为在读出时一直读出至叙述节构成单体为止,但是并不是必须读出叙述节构成单体。究其原因,是因为即使仅不断地进行含义树中的联想,作为知识数据库就有意义。例如,当在图12中进一步将各种信息进行连结时,能够进行“本田里纱”→“苹果”→“水果”→“果汁”→“健康”等的联想。
另外,即使在写入中,也并不是必须写入叙述节连结单体和叙述节构成单体。例如,如果是简易的数据库,则也可以不写入叙述节连结单体和叙述节构成单体。
6.第三实施方式
6.1〈与第一实施方式的不同〉
在上述实施方式中,为了易于理解,将以下内容作为前提进行了说明(参照图5):对于如图5所示的一个标签对应一个实体,具体地说,图12的含义树中指定的id61的实体与“本田里纱”这一标签一对一地对应。
关于所述标签数据,也能够如图23所示,生成该标签数据并且将该标签数据存储到参考字段65(参照图4),通过进行该记录id的参照处理来读出这些标签数据。
在图25中,直线箭头表示连结关系,曲线箭头表示参照关系。作为所述参照关系,存在不同的含义树间的参照、含义树与参考树间的参照以及参考树间的参照这三种。在后面叙述这些参照关系。
另外,在图26中,与第一实施方式同样地,用〔〕表示含义字段62中存储的id,在()内表示其对应字符串。另外,关于关系字段64的id,在直线箭头附近用〔〕来表示。另外,在《》内表示参考字段65中存储的字符串。
下面,说明id61的实体具有连结属性“是姓名”、其属性值为“本田里纱”的情况下的数据结构。此外,像这样,作为属性值,既包括是标签的情况,也包括是含义的情况。
在图23中,记录r80、r81以及r641是参照定义单体。参照定义单体是指以下单体:id字段61和含义字段62存储有相同的id,联系字段63和关系字段64为空,在参考字段65中存储有被参照的数据。在本实施方式中,参考字段65中被参照的数据设为字符串,但是并不限定于此。并且,所述字符串也可以如uri那样是表示指定的图像数据、或声音数据等的保存目的地的文件指定id。
记录r640是参照主从单体。参照主从单体是指如下单体:在联系字段63中存储与两个定义单体有关的上层下层的连结关系,存储用于指定表示所述连结属性的值的属性值的属性值指定id的含义字段62为空,在关系字段64中存储所述连结关系中的属性,在参考字段65中存储所述连结关系的表述数据的id。
此外,在第一实施方式中,定义单体定义为以下单体:在id字段61和含义字段62中存储有相同的id,除此以外的字段为空。与此相对地,在利用全部五维的情况下,参考字段65也不为空的情况也包含在定义单体中。即,利用r641指定的个别元素数据是定义单体。
此外,记录r691~694是叙述节构成单体,记录r700是叙述节连结单体。这些与第一实施方式是同样的。
6.2〈读出处理〉
主程序能够读出图23的a、b的各记录并将各单体进行连结,由此生成如图24所示的含义树和参考树。
例如,如在第一实施方式中说明的那样,在表中存储有图4所示的记录,当读出该记录时构建起如图25那样的含义树。下面,进一步说明除此以外还存储有图23所示的记录、读出这些记录来构建图26所示的含义树和参考树的情况。另外,硬件结构与第一实施方式相同,因此省略说明。
在图26中,用虚线围起来的区域β1是向图25的树状态追加的树。另外,在图26中,与第一实施方式同样地,关于id51记载着51〔51〕(苹果),关于id163记载着163〔71〕(自助餐厅),但这是为了易于理解,实际上,与标签“本田里纱”同样,利用参考树来参照该标签。
在图27中示出所述处理的流程图。cpu23提取在联系字段63中存储有检索对象id的记录来作为主从单体(图27步骤s101)。在该情况下,检索对象是id“61”,因此提取出在联系字段63中具有“61”的记录、即图4的记录r161、r163,并且提取出图23的记录r640。
cpu23对处理编号i进行初始化(步骤s103),针对第i个主从单体,判断是否已经提取过联系字段的id的记录(步骤s105)。当设记录r161是第0个主从单体时,其联系字段的id“61”未提取,因此提取联系字段的id的记录来作为顶层单体(步骤s107)。
cpu23将记录r161与r61决定为是位置连结关系(步骤s108)。
cpu23判断第0个主从单体是否为参照主从单体(步骤s109)。关于是否为参照主从单体,只要根据该记录的含义字段62是否为空来进行判断即可。在该情况下,记录r161的含义字段62不为空,因此cpu23提取含义字段的id“51”的记录来作为连结对象,决定为含义连结关系(步骤s111)。
cpu23提取构成第0个主从单体的叙述节的记录(步骤s123)。
在图28中示出步骤s123的处理的详细内容。图28与图7步骤s7~步骤s22大致相同,下面简单地进行说明。
cpu23对叙述节处理编号j进行初始化(步骤s130)。
cpu23提取第i个主从单体的第j个叙述节连结单体(步骤s131)。是否为叙述节连结单体的判断与第一实施方式相同。在该情况下,提取出在联系字段63中存储所提取出的第0个主从单体r161的记录id“161”、关系字段64为“24”的记录即记录r162来作为叙述节连结单体。
cpu23提取关于该叙述节连结单体的叙述节构成单体的最上层单体(步骤s133)。在该情况下,作为第0个叙述节连结单体的记录r162的含义字段存储有“131”。因此,提取出记录r131来作为对应的叙述节构成单体的最上层单体。
cpu23判断所提取出的最上层单体的id是否已经提取过(步骤s135)。在该情况下,所提取出的最上层单体的id尚未提取过,因此cpu23提取在联系字段63中存储所提取出的最上层单体的id的记录,并决定连结关系(步骤s137)。
cpu23判断是否存在与所提取出的叙述节构成单体连接的单体(步骤s139)。在该情况下,在图4中,存在在联系字段63中存储“132”的记录r135。因此,cpu23提取记录r135并且决定连结关系(步骤s141)。
cpu23针对第i个主从单体,判断是否已提取出全部叙述节连结单体(步骤s145),在还有残存的情况下,将叙述节处理编号j加1(步骤s147),重复进行步骤s131以下的处理。在该情况下,已提取出全部叙述节连结单体,因此,当构成叙述节的记录提取处理结束时,cpu23判断针对全部主从单体的处理是否均已结束(图27步骤s125)。
此外,在本实施方式中,说明了作为叙述节构成单体仅存在记录r135这1级的情况,但是如后述那样,也存在进一步对各记录进行修饰从而由多级构成的情况。在这种情况下,要决定全部的连结关系。
在图27步骤s125中,在该情况下,针对记录r163的处理尚未结束,因此cpu23将处理编号i加1(步骤s127),进入步骤s105。
cpu23针对第1个主从单体的记录r163进行步骤s105以下的处理。在该情况下,作为处理,除了以下方面以外,与记录r161是同样的。
在图27步骤s105中联系字段的id“61”已经提取过,因此不执行步骤s107的处理。另外,在图28步骤s135中,记录r131已经提取过,因此不进行步骤s137~步骤s141就决定叙述节连结单体与叙述节构成单体之间的连结关系(步骤s143)。
当构成叙述节的记录提取处理结束时,cpu23判断针对全部主从单体的处理是否均已结束(图27步骤s125)。在该情况下,针对记录r640的处理尚未结束,因此cpu23将处理编号i加1(步骤s127),进入步骤s105。
cpu23针对第2个主从单体的记录r640进行步骤s105以下的处理。
cpu23针对第2个主从单体判断是否已经提取过联系字段的id的记录(步骤s105)。在该情况下,记录r640的联系字段的id“61”已经提取过,因此进入到步骤s108,决定第2个主从单体与提取过的顶层单体之间的位置连结关系。
cpu23判断该主从单体是否为参照主从单体(步骤s109)。在该情况下,记录r640的含义字段62为空。因而,cpu23进入步骤s115,判断是否提取过参考字段65的id的记录。在该情况下,参考字段65的id“641”的记录尚未提取过,因此cpu23提取参考字段65的id“641”的记录作为顶层单体(步骤s117)。cpu23将所提取出的顶层单体与所述参照主从单体决定为是参照连结关系(步骤s119)。
cpu23提取在联系字段中保持所述提取出的顶层单体id641的记录来作为追加主从单体,来追加该单体(步骤s121)。在该情况下,提取出记录r642(参照图23的b)来追加为追加主从单体。
cpu23提取构成以记录r640为主从单体的叙述节的记录(步骤s123)。所述步骤如以下那样执行。cpu23对叙述节处理编号j进行初始化(图28步骤s130)。
cpu23针对第2个主从单体,提取第0个叙述节连结单体(图28步骤s131)。在该情况下,提取出在联系字段63中存储id640、且关系字段64为“24”的记录即记录r700(参照图23的a)来作为第0个叙述节连结单体。
cpu23提取关于该叙述节连结单体的叙述节构成单体的最上层单体(步骤s133)。在该情况下,记录r700的含义字段存储有“691”。因此,提取出记录r691来作为对应的叙述节构成单体的最上层单体。
cpu23判断所提取出的最上层单体的id是否已经提取过(步骤s135)。在该情况下,所提取出的最上层单体的id尚未提取过,因此cpu23提取在联系字段63中存储所提取出的最上层单体的id的记录,并决定连结关系(步骤s137)。
cpu23判断是否存在与所提取出的叙述节构成单体相连接的单体(步骤s139)。在该情况下,cpu23判断为不存在在联系字段63中存储有所提取出的叙述节构成单体的id的记录。因此,叙述节处理结束。
当构成叙述节的记录提取处理结束时,cpu23决定连结关系(步骤s141)。
cpu23针对第i个主从单体,判断是否已提取出全部叙述节连结单体(步骤s145),在有残存的情况下,将叙述节处理编号j加1(步骤s147),重复进行步骤s131以下的处理。在该情况下,已提取出全部叙述节连结单体,因此,当构成叙述节的记录提取处理结束时,cpu23判断关于全部主从单体的处理是否均已结束(图27步骤s125)。在该情况下,关于在步骤s115中追加的记录r642的处理尚未结束,因此cpu23将处理编号i加1(步骤s123),进入步骤s105。
由于记录r642的联系字段的id“641”已提取过,因此cpu23将记录r641与r642决定为是位置连结关系(步骤s108)。
cpu23判断第3个主从单体是否为参照主从单体(步骤s109)。在该情况下,记录r642的含义字段62不为空,因此cpu23提取含义字段的id“61”的记录来作为连结对象,决定为是含义连结关系(步骤s111)。
cpu23提取构成以记录r642为主从单体的叙述节的记录(步骤s123)。具体地说,cpu23提取第3个主从单体的叙述节连结单体(图28步骤s131)。在该情况下,提取出在联系字段63中存储id642、关系字段64为“24”的记录即记录r703来作为叙述节连结单体。
cpu23提取关于该叙述节连结单体的叙述节构成单体的最上层单体(步骤s133)。在该情况下,记录r703的含义字段存储有“691”。因此,记录r691被提取为对应的叙述节构成单体的最上层单体。
cpu23判断所提取出的最上层单体的id是否已经提取过(步骤s135)。在该情况下,所提取出的最上层单体的id已经提取过,因此决定叙述节连结单体与叙述节构成单体的连结关系(步骤s143)。
此外,在本实施方式中,设为参考树也全部提取,但是也可以仅提取参考树的顶层单体的记录。例如,在图26中,也可以不提取id642和id703。这是由于还存在以下情况:只要知道根据id640来参照的id641的标签就足够了。在该情况下,只要去除图27步骤s121的处理,并且,在是参考树的情况下不进行步骤s123~127的处理而进行步骤s129的处理即可。
此外,也能够从最初起利用参考字段的标签来进行联想检索。例如,在输入“honda”来进行联想检索的情况下,指定在参考字段65中存储有“honda”的记录,提取在联系字段64中存储该记录的id的记录。根据提取出的记录来提取含义树,由此能够进行从参考树向含义树的联想。
此外,也可以不提取联系字段64中存储的记录而提取参考字段65中存储的记录。
当结束叙述节处理时,cpu23判断针对全部主从单体的处理是否均已结束(图27步骤s125)。在该情况下,全部处理均已结束,因此cpu23生成将提取出的单体进行连结而成的知识数据库(步骤s129)。
具体地说,只要基于位置连结关系、含义连结关系以及参照连结关系来将各元素进行连结即可。在本实施方式中,关于位置连结关系,以直线连结,关于含义连结关系和参照连结关系,以曲线连结。由此,能够得到图26所示的连结关系。在图26中,将顶层单体设为双重圆圈,将参考树的顶层单体设为在双重圆圈中表述文字“r”,但是不限定于此。
位置连结关系是指以下关系:两个元素被指定为上下关系来相连接,且其连结属性是确定的,且含义字段或参考字段中加入有值。
含义连结关系是指利用含义字段的id来连结的关系,参照连结关系是指利用参考字段的id来连结的关系。
该知识数据库利用位置连结关系、含义连结关系以及参照连结关系来进行连结。因而,通过依次地逐渐探索这些连结关系,能够依次读出相关联的记录信息。
6.3〈关于参考关系〉
在图23中说明了id61的实体的标签为“本田里纱”的情况,但是关于所述标签,在对于多个实体具有一个标签的情况(多对一)、对于一个实体具有多个标签的情况(一对多)、对于多个实体具有多个标签的情况(多对多)下,也能够从某个含义树起探索标签单体,进一步从该标签单体逐步联想到另外的含义树。
6.3.1〈关于多对一的参考关系〉
说明多对一的情况。在表中存储有图29所示的记录、两个实体id61和实体id1061的标签为“本田里纱”的情况下,通过图27所示的读出处理来构建如图30那样的含义树和参考树。
在图30中,对于一个参考树,从多个实体构建有一个参照连结关系。具体地说,在图30中,从id640和id1062的单体参照连结id641。
即,在本实施方式中,与第一连结知识数据的上层个别元素数据相关联的多个下层个别元素数据中的至少一个下层个别元素数据(id640)不具有所述属性值数据,并且与利用所述参照目标的个别元素数据的元素数据id来参照的个别元素数据(单体id641)相关联,与第二连结知识数据的上层个别元素数据相关联的多个下层个别元素数据中的至少一个下层个别元素数据(单体id1062)不具有所述属性值数据,并且与利用所述参照目标的个别元素数据的元素数据id来参照的个别元素数据(单体id641)相关联,该参照目标的个别元素数据是相同的个别元素数据(i单体d641)。
在含义树和参考树处于这种关系的情况下,能够从以id61的单体为顶层的含义树参照id641的单体,并从该单体联想以id1061的单体为顶层的含义树。
6.3.2〈关于一对多的参考关系〉
说明一对多的情况。在表中存储有图31所示的记录的情况下,在一个实体id61具有“本田”和“honda”这两个标签时,从一个id61的实体对如图32那样的两个参考树构建参照连结关系。
具体地说,在图32中,id61具有两个单体id1100和id1110,从单体id1100和id1110分别参照连接有id632和id631。由此,能够表示id61的实体具有两个标签。
即,在本实施方式中,关于多个连结知识数据(在该情况下,以单体id61为顶层的含义树、以单体id632和单体id631为顶层的参考树)中的至少两个以上的连结知识数据(在该情况下,以单体id632和单体id631为顶层的参考树),在所述存储单元中存储有下述条件成立的个别元素数据。
第一连结知识数据(以单体id61为顶层的含义树)的与上层个别元素数据关联的多个下层个别元素数据中的第一下层个别元素数据(单体id1100)和第二下层个别元素数据(单体id1110)不具有所述属性值数据,并且与利用所述参照目标的个别元素数据的元素数据id来参照的参照目标的个别元素数据(单体id632、单体id631)相关联,所述参照个别元素数据是各不相同的个别元素数据(单体id632、单体id631)。
在含义树与参考树处于这种关系的情况下,例如能够从id632的单体连结以id61的单体为顶层的含义树,进一步从其下层的单体参照id631的单体。
6.3.3〈关于多对多的参考关系〉
说明多对多的情况。在表中存储有图31和图33所示的记录的情况下,关于作为实体的单体id61、id656,从id61和id656的实体对如图34那样的两个参考树(“本田”和“honda”)分别构建参照连结关系。具体地说,在图34中,除了图32以外,id656也具有两个单体id1131和id1141,从单体id1131和id1141分别参考连结有id632和id631。由此,能够表示id61和id656的实体分别具有相同的两个标签。
此外,图34的树α1、α2以及α3是基于图33所示的记录构建的部分。树α1、α2是参考树,树α3是含义树。
此外,在图34中仅显示叙述节构成数据的最上层的单体,其它省略显示。另外,表示来自id631、632的下层单体1125、1223、1121、1211的参照的曲线箭头省略表述。
即,在本实施方式中,关于所述多个连结知识数据中的至少两个以上的连结知识数据(以单体id61为顶层的含义树、以id656为顶层的含义树),在存储单元中存储有下述条件成立的个别元素数据。第一连结知识数据(以单体id61为顶层的含义树)的与上层个别元素数据(单体id61)关联的多个下层个别元素数据中的第一和第二下层个别元素数据(单体id1100、id1110)不具有所述属性值数据,并且与利用所述参照目标的个别元素数据的元素数据id来参照的个别元素数据(单体id632、id631)相关联,所述第一、第二下层个别元素数据参照着互不相同的个别元素数据(单体id632、id631)。另外,第二连结知识数据(以单体id656为顶层的含义树)的与上层个别元素数据(单体id656)关联的多个下层个别元素数据中的至少两个下层个别元素数据(单体id1131、单体id1141)不具有所述属性值数据,并且一方是与所述第一下层个别元素数据(单体id1100)所关联的个别元素数据(单体id632)关联的第三下层个别元素数据(单体id1131),另一方是与所述第二下层个别元素数据(单体id1110)所关联的个别元素数据(单体id631)关联的第四下层个别元素数据(单体id1141)。
此外,在上述各实施方式中也是,可以仅提取参考树的顶层单体的记录。
在含义树与参考树处于这种关系的情况下,能够得到以下知识数据:从以id61的单体为顶层的含义树参照id631的单体,再从该单体连结以id656的单体为顶层的含义树。
另外,能够得到以下知识数据:从id632的单体连结以id61的单体为顶层的含义树,进一步从其下层的id1110的单体参照id631的单体。
此外,在图34中,以还从id656的含义单体参照从id61的单体的下层单体进行参照的id632、id631的参考单体的情况为例进行了说明,但是也可以是id656的含义单体的下层单体中的仅一方进行参照的情况。另外,也可以是id656的含义单体的下层单体中的一方参照除id61的含义单体所参照的id632、id631以外的参考单体的情况。
6.4〈关于应用〉
若应用以上所说明的、实体与标签的对应、一对多、多对一、或多对多的关系,则能够处理同音异意语。例如,关于一个读音“くも”,既存在实体“云”也存在实体“蜘蛛”。在英语的情况下,“bean”和“been”符合该情况。
另外,也能够实现不同的语言间的翻译处理。究其原因,是由于若语言不同则关于一个实体存在多个表述。例如,关于相同的水果,在日语中表述为“リンゴ”,在英语中表述为“apple”。此外,在尽管语言相同但根据地域不同而称呼不同那样的情况下也是同样的。
在本实施方式中,说明了实体的标签已判明、利用其id来读出的情况,但是在实体的标签的id未判明的情况下,只要首先读出在参考字段65中存储有符合的字符串的记录,利用其id如上述那样检索联系字段63即可。
例如,在存储有图29的记录的情况下,当利用字符串“本田里纱”来检索参考字段65时,能够提取出id641。当提取在联系字段63中存储该id641的记录时,能够提取出记录r642、r1066。通过逐渐探索这些记录的含义字段63的id,能够最终探索到id61和id1061。
此外,也可以提取在参考字段65中存储该id641的记录。
此外,在利用参照连结关系进行连接的情况下,由于含义字段62为空,因此通过限定成含义字段62为空的记录,能够在更短的时间内最终探索到作为目标的顶层单体。
6.5〈写入处理〉
说明由主程序26p进行的各单体的写入处理。下面,说明以下情况:在存储有图35所示的表的情况下,提供了叙述节“本田是作为丰田一郎的下属的本田里纱的姓的日语表述”的数据。在该情况下,通过以下的处理来追加图36所示的记录。
6.5.1叙述节数据的输入处理
首先,使用图37来说明叙述节数据“‘本田’是作为丰田一郎的下属的本田里纱的姓的日语表述”的输入方法。
cpu23显示输入用的模板输入画面(图37步骤s151)。在图38中示出其一例。在这种情况下,事先存储有表示“姓○○是姓保持者xx的姓的日语表述”这种关系的模板。只要读出该模板来由用户输入作为主语的字符串和宾语即可。关于模板,也可以事先存储多个候选,由用户来选择。
用户在输入栏151中输入姓“本田”,在输入栏153中输入对象“本田里纱”。另外,对象“本田里纱”具有“是丰田一郎的下属”这一修饰语,因此用户选择图标154。
cpu23判断是否选择了结束按钮159(步骤s153),在该情况下未选择结束按钮159,因此进入到步骤s155,判断是否选择了追加按钮。在该情况下,选择了图标154,因此督促要进行修饰的输入栏的指定(步骤s157)。在本实施方式中,设为进行“请选择修饰对象的输入栏”的画面显示,但不限定于此。
在该情况下,希望进行修饰的输入栏是输入栏153中输入的“本田里纱”,因此用户选择输入栏153。
由此,cpu23显示用于表示所指定的输入栏的修饰关系的、追加的输入栏(步骤s159)。在图39中示出该情况的一例。
在该情况下,“主语(○○)对于对象(xx)而言是下属”这样的三个输入栏中的尚未决定关系的输入栏是输入栏163。用户在输入栏163中输入“丰田一郎”,并选择结束按钮。
cpu23判断是否选择了结束按钮159(步骤s153),在该情况下选择了结束按钮159,因此进行标签检索(步骤s161),来判断输入栏中输入的标签是否存在(步骤s163)。具体地说,只要判断表的参考字段65中是否存在所述字符串即可。
在该情况下,输入栏153中输入的“本田里纱”已经存在,但输入栏151中输入的“本田”还不存在。因而,cpu23新登记标签“本田”(步骤s165)。由此,在空闲的id的记录中生成在含义字段62中存储相同的id、在参考字段65中存储“本田”的记录。在该情况下,设登记为记录id“632”。
如果存在多个要新登记的标签的情况,只要重复进行步骤s165即可。
cpu23进行标签与实体的对应(步骤s167)。这是由于存在以下情况:“本田里纱”这样的一个标签如图30所示那样与id61、id1061那样的多个实体对应。在本实施方式中,设为在存在多个实体的情况下,cpu23在画面上显示利用双方的含义树表现的实体的连结属性,来作为用户进行选择时的参考,但不限定于此。
如果是该情况,则由用户选择id61的记录的单体。另外,作为模板采用的“是姓的日语表述”这一动词中的源点格s是当输入标签时就被决定了的,因此关于标签“本田”,未进行与实体的对应。另外,关于“丰田一郎”,也与上述同样地进行与实体的对应。在该情况下,设为选择了id63的记录的单体。
这样,关于叙述节数据“‘本田’是作为丰田一郎的下属的本田里纱的姓的日语表述”的数据输入完成。
此外,在本实施方式中,设为在选择了结束按钮的情况下判断是否存在具有参考字段65的字符串的记录,但是判断时期不限定于此,例如,也可以当在输入栏进行了输入时进行所述存在判断。另外,关于与实体的对应也是同样的。
6.5.2〈表写入处理〉
关于之后的写入处理,除向参考字段的写入处理以外,与第一实施方式大致相同。此外,在图40中,为了更易于理解内容,与第一实施方式相比替换了处理的顺序。
6.5.3叙述节构成单体写入处理
cpu23生成叙述节构成单体并进行写入(图40步骤s41)。使用图41来说明叙述节构成单体的生成处理。cpu23决定起点单体、行径单体以及终点单体(图41步骤s171)。在本实施方式中,在用户输入叙述节数据时,是决定了源点格s、行径格p、终点格g地进行了输入的。因而,不用如第一实施方式那样进行词素分析就能够决定起点单体、行径单体以及终点单体。在该情况下,所提供的数据“本田”是源点格s,“是姓的日语表述”是行径格p,“本田里纱”是终点格g。
cpu23生成并写入最上层单体的id(步骤s173)。关于所述id,使用空闲的id。在此,设为id“1102”。cpu23向记录“1102”的含义字段62写入“1102”。
cpu23判断源点格s是否应该被输入标签(步骤s175)。是否应该被输入标签是通过以下方式来判断的:是否通过作为源点格p的动词(在该情况下,“是姓的日语表述”)决定为源点格s被输入标签。因此,对各动词存储有针对源点格s或终点格g是否输入标签(未图示)。
在该情况下,该动词决定为向源点格s加入标签,因此cpu23将其它参照单体标志(表示是对参考单体进行参照的单体的标志)设为开启,并且生成并写入利用参考字段65指定的单体(步骤s177)。在该情况下,cpu23向空闲的id“1103”的含义字段62写入“-(空)”,向联系字段63写入上层单体的id“1102”,向关系字段64写入“源点格”的id“4”,向参考字段65写入“本田”的id“632”。此外,关于“本田”的id,只要利用字符串“本田”来检索参考字段65即可。
cpu23写入行径格p的记录(步骤s181)。在该情况下,“是姓的日语表述”为id“82”,行径格p为id“5”,上层单体为id“1102”。因而,向接下来的空闲id“1104”的含义字段62写入“82”,向联系字段63写入上层单体id“1102”,向关系字段64写入“行径格p”的id“5”,向参考字段65写入“-(空)”。
cpu23判断终点格g是否应该被输入标签(步骤s183)。关于是否应该被输入标签,如已经叙述的那样是根据动词来决定的。在该情况下,决定为终点格g不加入标签,因此cpu23生成并写入利用含义字段62指定的单体(步骤s187)。在该情况下,向空闲的id“1105”的含义字段62写入表示本田里纱的实体的id“61”,向联系字段63写入上层单体的id“1102”,向关系字段64写入终点格g的id“6”,向参考字段65写入“-(空)”。
cpu23进入到图42,在存在扩展单体的期间,重复进行步骤s193~步骤s199(步骤s191~步骤s199)。此外,扩展单体是指除源点格、终点格以及行径格以外的单体候选。
在该情况下,除“本田”(源点格)、“本田里纱”(终点格)以及“是姓的日语表述”(行径格)以外存在单体候选的数据,因此判断为存在扩展单体。具体地说,cpu23判断为修饰本田里纱的“丰田一郎”和“是下属”中的作为源点格的“丰田一郎”是扩展单体。
在本实施方式中,“丰田一郎”作为源点格处理。这是由于以下那样的理由。关于这种扩展单体,行径格“是下属”可能存在以下两个情况:作为修饰对象的“本田里纱”是“丰田一郎”的下属的情况;以及“丰田一郎”是作为修饰对象的“本田里纱”的下属的情况。在本系统中,设为前者来规则化。
cpu23针对扩展单体判断是否应该被输入标签(步骤s193)。在该情况下,作为扩展单体“丰田一郎”所对应的行径格p的“是下属”被设定为不输入标签,因此进入到步骤s195,cpu23生成并写入利用含义字段62指定的单体。
在此,在“本田里纱”是“丰田一郎”的下属的情况下,若从“丰田一郎”来看,则“本田里纱”处于“-是下属”这样的关系。因而,向空闲的id“1106”的含义字段62写入表示丰田一郎的实体的id“63”,向联系字段63写入上层单体的id“1102”,向关系字段64写入“-是下属”的id“53”,向参考字段65写入“-(空)”。
cpu23判断在步骤s199中是否不再存在扩展单体,在该情况下,扩展单体为一个,因此结束叙述节构成单体的写入处理。
通过所述处理来写入图36的记录r1102~r1106。
在本实施方式中,如已经说明的那样,针对构成行径格p的动词事先存储有是否输入标签的信息,由此,是含义具有值的单体还是参考具有值的单体,能够相区别地写入。作为其前提,视为动词至少具有源点格、终点格以及行径格。在此,在一般的语法中存在不具有宾语的自动词和be动词。在本说明书中,关于这些动词,以接宾语的形式来处理。例如,在“本田里纱奔跑”这一自动词的情况下,作为“本田里纱使本田里纱奔跑”来操作。另外,在“苹果是红的”这一be动词的情况下,如“红对于苹果而言是颜色”那样,采用是颜色这一动词来处理。
另外,在该情况下,与第一实施方式同样地,动词作为从下层个别元素数据来看的“行径格”。
6.5.4〈树单体和叙述节连结单体的写入处理〉
接着,cpu23进行树单体和叙述节连结单体的写入处理(图40步骤s44)。树单体是含义树单体和参考树单体的统称。在本实施方式中,在判断是否写入对参考单体进行参照的单体(以下成为其它参照单体)的方面,如以下那样与第一实施方式不同。
使用图43来说明步骤s44的详细。cpu23决定树单体的候选(图43步骤s201)。作为树单体的候选,存在两种主从单体。在该情况下,作为两种主从单体,存在顶层单体为实体的情况和顶层单体为标签的情况。前者是含义树单体,后者是参考树单体。前者进一步分为两种,存在参照标签的情况和不参照标签的情况。不参照标签的情况以及此时存在详细单体的情况的处理与第一实施方式相同,因此省略说明。
下面,首先说明作为含义树单体的、参照标签的树单体的写入处理,并且说明参考单体的写入处理。
cpu23对处理编号i进行初始化(图43步骤s203),针对第0个树单体候选,判断对参考单体进行参照的标志(其它参照单体标志)是否开启(步骤s205)。在该情况下,在图42的步骤s197中,第0个树单体候选“本田”的其它参照单体标志被设定为开启,因此生成利用参考字段65来参照其它单体的单体(图43步骤s209)。具体地说,在含义字段62中存储“-”,在联系字段63中存储“61”,在关系字段64中存储表示“是姓的日语表述”的id“82”,在参考字段65中存储表示标签“本田”的“632”。由此生成对参考单体进行参照的含义树单体(其它参照单体)。
cpu23判断所生成的其它参照单体在表中是否已经存在(步骤s211)。在该情况下,所生成的其它参照单体在表中不存在,因此cpu23向表进行写入(步骤s213)。关于所写入的id,使用空闲的id。在此,设为id“1100”。
cpu23生成叙述节连结单体并将其写入表(步骤s215)。关于叙述节连结单体的写入,与第一实施方式相同。在该情况下,在步骤s213中决定的是id“1100”,所连接的叙述节构成单体的最上层单体是“1102”。因而,cpu23向空闲的id“1101”的含义字段62写入“1102”,向联系字段63写入“1100”,向关系字段64写入“24”。
cpu23生成反向树单体(步骤s216)。如在第一实施方式中也说明过的那样,反向树单体是指与第i个树单体候选为反向谓语关系的单体。例如,在第一实施方式中,生成了与“本田里纱”“吃”“苹果”为“苹果”被“本田里纱”“吃(-吃)”的反向关系的树单体。与此相同地,在该情况下,生成作为实体的“本田里纱”对于标签“本田”而言是“-是姓的日语表述”。在该情况下,作为其它参照单体标志的含义树的反向谓语关系的单体,成为以参考单体为顶层的参考树单体。
在图44中示出步骤s216的详细。
cpu23指定源点格s、行径格p、终点格g中的行径格p“是姓的日语表述”的反向关系的“-是姓的日语表述”(步骤s231)。cpu23生成将源点格s与终点格g交换而得到的单体(步骤s233)。如果是该情况,则在含义字段62中存储“61”,在联系字段63中存储“632”,在关系字段64中存储表示“-是姓的日语表述”的id“83”,在参考字段65中存储“-”。
cpu23判断所述单体是否已经存在(步骤s235)。在该情况下,不存在,因此向表进行写入(步骤s237)。具体地说,cpu23向空闲的id“1121”的含义字段62写入“61”,向联系字段63写入“632”,向关系字段64写入“83”。由此生成参考树单体。
cpu23生成将在图43步骤s215中生成的叙述节连结单体进行连结的叙述节连结单体并进行写入(步骤s239)。所述处理与步骤s215相同,因此省略具体的说明,而在该情况下,在步骤s213中决定的是id“1121”,所连接的叙述节构成单体的最上层单体是“1102”。因而,cpu23向空闲的id“1122”的含义字段62写入“1102”,向联系字段63写入“1121”,向关系字段64写入“24”。
此外,在步骤s235中已经存在的情况下,将权重标志设为开启(步骤s238)。所述处理与图43步骤s221相同,因此省略说明。
cpu23判断针对图43步骤s201中决定的候选是否处理均已结束(图43步骤s217)。在该情况下,已全部结束,因此cpu23返回到图40,结束写入处理。在该情况下,图36的记录r1100、r1101、r1121、r1122被写入。
若将追加图36所示的记录之前的记录设为图35,则当通过图27所示的读出流程图来读出该记录时,得到图45所示的含义树和参考树。在此,当通过所述写入处理追加记录了图36所示的记录且一并读出这些记录时,得到图46所示的树结构。
此外,为了易于理解所追加的参考树以外的标签,在图45、图46中设为与第一实施方式相同。
另外,图43步骤s221与图11的步骤s78相同。
此外,在图35中,r4~r72、r80~83、r641、r643是预先存储的,但仅在与其它单体连结的情况下在图44中进行显示。另外,图35的记录r63是“丰田一郎”的含义单体的顶层单体,但在图35中省略了所述含义单体的记录。
在本实施方式中,设为在图44步骤s216中生成反向关系的单体。但并不限定于此,也可以如第一实施方式那样,关于反向关系的单体,也作为树单体来通过重复处理生成。另外,也可以相反地在第一实施方式中设置如步骤s216那样的处理来进行处理。
6.6〈其它实施方式〉
在上述实施方式中,说明了含义树与参考树间的参照,但是也能够是参考树间的参照。例如,在图32中,在存在表示标签“honda”的id631的单体的情况下,当追加了“honda是honda的大写字母表述”这一叙述节时,成为如下那样的参照关系。
关于“是大写字母表述”这一行径格p,源点格s和终点格g均被决定为是标签。因而,在图41步骤s177和步骤s185中,均进行利用参考字段65指定的写入。
首先,作为定义单体,设为:作为单体id1201,在含义字段中存在“1201”,在参考字段65中存在“honda”,作为单体id1202,在含义字段存在“1202”,在含义字段62中存在“是大写字母表述”。以参照该单体的形式,作为单体id1203,追加含义字段62为空、在联系字段63中记载有“631”、在关系字段64中记载有“1202”、在参考字段65中记载有“1201”的单体。
此外,也可以与上述实施方式同样地生成反向关系的单体(参照图44步骤s216)。
关于权重和时间单体,对第三实施方式也能够同样地应用。由此,例如在用于翻译等的情况下,与在第二实施方式中说明过的同样,能够得到与其频度、最近的使用趋势等相应的翻译结果。关于所述权重和时间单体,不仅能够对含义树应用,也能够对参考树同样地应用。
另外,在本实施方式中,针对构成行径格p的单体,按每个单体事先存储有源点格s和/或终点格g是标签这样的规则,并在符合该规则的情况下判断为不存在与实体的对应。但是并不限定于此,例如也可以根据是否进行了与实体的对应来变更是利用含义字段的id进行连结还是利用参考字段的id进行连结。当然,关于所述属性,只要利用同样的树结构来存储即可。
7.1〈功能框图〉
在图47中示出第三实施方式所涉及的数据库管理装置1的功能框图。数据库管理装置1具备存储部203、关联部205、读出部207以及写入部209。
存储部203存储有以一个记录来构成一个元素数据的表,该表至少包括下述5个字段a1)~a5)。a1)元素数据id字段,其用于存储该元素数据的元素数据id;a2)上层元素数据字段,其用于存储位于该元素数据的上层的上层元素数据的id即上层元素数据id;a3)连结属性元素数据字段,其用于存储表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的id即连结属性元素数据id;a4)属性值数据字段,其用于存储用于指定表示所述连结属性的值的属性值的属性值指定id;以及a5)参照元素数据字段,其用于存储所述属性值数据字段中存储的属性值指定id所表示的表述数据、或者参照目标的元素数据id。
关联部205针对某个记录,将所述某个记录置于上层记录的位置,而将在上层元素数据字段中存储该某个记录的含义字段中存储的id的记录置于该某个记录的下层记录的位置,并且设为由所述下层记录的连结属性元素数据字段中存储的连结属性元素数据表示的连结属性是所述下层记录的属性值数据字段中存储的属性值来使所述上层记录与所述下层记录相关联。另外,关联部205在所述下层记录的属性值数据字段为空的情况下,指定利用所述参照元素数据字段中存储的id来参照的记录,将所指定的记录的参照元素数据字段中存储的数据关联为所述含义字段为空的记录的标签。
读出部207使关联部205重复进行所述关联,由此读出对所述上层记录连结了多个下层记录而成的连结知识数据。
写入部209当针对写入对象的元素被提供上层元素id以及与该上层元素之间的连结属性中的连结属性元素数据及其属性值时,将所述上层元素id写入上层元素数据字段,将所述连结属性元素数据写入连结属性元素数据字段,将其属性值写入属性值数据字段。另外,所述写入单元当针对写入对象的元素被提供上层元素id、与该上层元素之间的连结属性中的连结属性元素数据以及参照目标的元素数据id时,将所述上层元素id写入上层元素数据字段,将所述连结属性元素数据写入连结属性元素数据字段,将参照目标的元素数据id写入参照元素数据字段。
由此,能够以简易的数据结构得到多个知识相连结的数据。
也能够通过下述内容指定第一实施方式的发明。
本发明所涉及的数据库管理装置是一种数据库管理装置,a)具有以一个记录构成一个元素数据的表,该表至少包括下述四个字段a1)~a4):a1)元素数据指定信息字段,其用于存储用于指定该元素数据的元素数据指定信息;a2)上层元素数据字段,其用于存储用于指定位于该元素数据的上层的上层元素数据的上层元素数据指定信息;a3)连结属性元素数据字段,其用于存储用于指定表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的连结属性元素数据指定信息;以及a4)属性值数据字段,其用于存储用于指定表示所述连结属性的值的属性值的属性值指定id,b)所述表至少具有:b1)元素关联数据存储部,其存储元素关联数据;b2)多元素组数据存储部,其存储多元素组数据;以及b3)多元素组数据连结数据存储部,其存储用于将所述元素关联数据与所述多元素组数据的多元素组最上层元素数据进行连结的多元素组数据连结数据,b1)所述元素关联数据是用于指定主元素数据与从元素数据的关联性的数据,在所述元素关联数据中,所述从元素数据的元素数据指定信息存储于所述属性值数据字段,所述主元素数据的元素数据指定信息存储于所述上层元素数据字段,表示从所述从元素数据来看的所述主元素数据的谓语关系信息即反向谓语关系信息的元素数据指定信息存储于所述连结属性元素数据字段,b2)所述多元素组数据至少具有起点元素数据、终点元素数据及行径元素数据、以及用于将它们进行连结的多元素组最上层元素数据,b21)在所述多元素组最上层元素数据中,该元素数据的元素数据指定信息分别存储于所述元素数据指定信息字段和所述属性值数据字段,b22)在所述起点元素数据中,所述主元素数据的元素数据指定信息存储于所述属性值数据字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着源点格的元素数据指定信息存储于所述连结属性元素数据指定字段,b23)在所述终点元素数据中,所述从元素数据的元素数据指定信息存储于所述属性值数据字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着终点格的元素数据指定信息存储于所述连结属性元素数据指定字段,b24)在所述行径元素数据中,表示从所述主元素数据来看的所述从元素数据的谓语关系信息的元素数据指定信息存储于所述属性值数据字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着行径格的元素数据指定信息存储于所述连结属性元素数据指定字段,b3)在所述多元素组数据连结数据中,所述多元素组数据的多元素组最上层元素数据指定信息存储于所述属性值数据字段,所述元素关联数据的元素数据指定信息存储于所述上层元素数据指定字段,表示该多元素组最上层元素数据与该元素关联数据连结着的焦点化属性的连结属性指定信息存储于连结属性元素数据指定字段,
c)所述数据库管理装置具备提取单元,当针对所述属性值数据字段提供指定了第一元素数据指定信息的检索请求时,所述提取单元提取包含所述第一元素数据的元素关联数据,并且提取与其关联的多元素组数据和多元素组数据连结数据,由此,提取相连结的元素数据。
因而,能够提供一种利用所述元素数据指定信息字段、所述上层元素数据字段、所述连结属性元素数据字段以及所述属性值数据字段这样的共通的形式的表使各种数据连结起来的数据库管理装置。
本发明所涉及的数据库管理装置是一种数据库管理装置,a)具有以一个记录构成一个元素数据的表,该表至少包括下述四个字段a1)~a4):a1)元素数据指定信息字段,其用于存储用于指定该元素数据的元素数据指定信息;a2)上层元素数据字段,其用于存储用于指定位于该元素数据的上层的上层元素数据的上层元素数据指定信息;a3)连结属性元素数据字段,其用于存储用于指定表示该元素数据与所述上层元素数据之间的连结属性的连结属性元素数据的连结属性元素数据指定信息;以及a4)属性值数据字段,其用于存储用于指定表示所述连结属性的值的属性值的属性值指定id,b)所述表至少具有:b1)元素关联数据存储部,其存储元素关联数据;b2)多元素组数据存储部,其存储多元素组数据;以及b3)多元素组数据连结数据存储部,其存储用于将所述元素关联数据与所述多元素组数据的多元素组最上层元素数据进行连结的多元素组数据连结数据,b1)所述元素关联数据是用于指定主元素数据与从元素数据的关联性的数据,在所述元素关联数据中,所述从元素数据的元素数据指定信息存储于所述属性值数据字段,所述主元素数据的元素数据指定信息存储于所述上层元素数据字段,表示从所述从元素数据来看的所述主元素数据的谓语关系信息即反向谓语关系信息的元素数据指定信息存储于所述连结属性元素数据字段,b2)所述多元素组数据至少具有起点元素数据、终点元素数据及行径元素数据、以及用于将它们进行连结的多元素组最上层元素数据,b21)在所述多元素组最上层元素数据中,该元素数据的元素数据指定信息分别存储于所述元素数据指定信息字段和所述属性值数据字段,b22)在所述起点元素数据中,所述主元素数据的元素数据指定信息存储于所述属性值数据字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着源点格的元素数据指定信息存储于所述连结属性元素数据指定字段,b23)在所述终点元素数据中,所述从元素数据的元素数据指定信息存储于所述属性值数据字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着终点格的元素数据指定信息存储于所述连结属性元素数据指定字段,b24)在所述行径元素数据中,表示从所述主元素数据来看的所述从元素数据的谓语关系信息的元素数据指定信息存储于所述属性值数据字段,所述最上层元素数据的元素数据指定信息存储于所述上层元素数据字段,意味着行径格的元素数据指定信息存储于所述连结属性元素数据指定字段,b3)在所述多元素组数据连结数据中,所述多元素组数据的多元素组最上层元素数据指定信息存储于所述属性值数据字段,所述元素关联数据的元素数据指定信息存储于所述上层元素数据指定字段,表示该多元素组最上层元素数据与该元素关联数据连结着的焦点化属性的连结属性指定信息存储于连结属性元素数据指定字段,c)所述数据库管理装置具备写入单元,当被提供起点元素数据、终点元素数据及行径元素数据来作为新的多元素组数据时,该写入单元生成多元素组最上层元素数据并将该多元素组最上层元素数据作为多元素组数据进行写入,并且生成并写入元素关联数据和多元素组数据连结数据。
因而,能够提供一种利用所述元素数据指定信息字段、所述上层元素数据字段、所述连结属性元素数据字段以及所述属性值数据字段这样的共通的形式的表来使各种数据连结起来的数据库管理装置。
在上述内容中作为优选的实施方式说明了本发明,但并不用于限定,而是用于说明,能够不脱离本发明的范围和精神地、在附带的权利要求的范围内进行变更。
- 还没有人留言评论。精彩留言会获得点赞!