一种基于关联矩阵的不确定数据连接合并算法的制作方法
本发明涉及计算机软件技术领域,具体地,涉及一种基于关联矩阵,确定数据表的连接合并规则,解决不确定数据表的连接合并问题的算法。
背景技术:
随着互联网技术的蓬勃发展,我们已经进入了大数据时代,要从海量的数据中提取出有价值的信息变得更加复杂。在网络中存在许多看似相互独立的数据,实际上他们都是对同一类对象从不同方面的描述,例如同一个人或同一件商品在不同的网站,由于网站关注的角度不同,其存储的关于人或商品对象的属性信息也不完全相同。如果能够找到一种方法,整合多个不同来源且数据项含义不明确、数据对象不明确的数据,得到数据描述对象的详细信息,则对人们了解对象全貌有很大的帮助。
其中,不确定数据连接合并算法本质是在数据项含义不明确的数据表间找出关联记录,并将关联记录进行连接合并。对于多个不同来源且数据项含义不明确、数据对象不明确的数据表,要将各表中表示同一对象的记录合并在一起得到对象的全息影像,需要解决两个主要问题,首先如何确定数据表的连接合并顺序,避免可以进行合并的记录被遗漏;其次如何降低大数据应用场景下,表关联操作的计算复杂性问题,对于两个不确定数据表如果直接进行连接匹配计算量非常大,如两个维度分别为m维和n维的数据表,进行连接合并时需要进行m*n次属性值相似匹配。
技术实现要素:
为了克服现有技术的不足,本发明提供一种基于关联矩阵的不确定数据连接合并算法,以解决数据项含义不明确、数据对象不明确的数据难以进行连接合并的问题。
本发明为解决上述技术问题所采用的技术方案是:一种基于关联矩阵的不确定数据连接合并算法,包括以下步骤:
步骤1:引入属性重要度,数据表中数据对象的某一属性的重要度越高则表示该属性对该类数据对象的区分度越大;计算数据表中各属性的重要度,找出数据表所有属性重要度的最大值;
假设对象r1{P1,P2}和r2{P1,P2},对应的属性值分别为r1(p11,p12)和r2(p21,p22),r1和r2表示同一实体时,记为:当对象r1在属性P1上的取值p11和对象r2在属性P1上的取值p21相同时,r1和r2表示同一实体的概率为同样
若说明属性P1相对属性P2对该类对象具有更大的区分度,则可以将条件概率作为属性P1的重要度,记为
为了方便计算,我们可以采用以下思路来计算属性重要度:当r1和r2为不同的对象,p11=p21相等的概率为P(p11=p21|r1≠r2),由条件概率知,P(p11=p21|r1≠r2)与存在反比关系,因此属性P1的重要度
针对数据表T={P1,P2,...,Pn},Pi的取值为统计Pi中每个不同属性值的出现次数,如表1所列:
表1属性Pi的取值分布
由于同一数据表中存在同一对象的概率很小,因此在大数据表中可以认为每一条记录代表一个不同的对象,基于该假设,其值相等的概率为由于可得则属性Pi的重要度为:
由于此值范围较大,不利于后期记录相似度的计算,因此对其进行平滑化处理和归一化处理,得到:
其中Wp max表示数据表T所有属性重要度的最大值。
步骤2:确定数据表之间的关联度,并建立关联矩阵;
步骤201,采用杰卡德相似系数来计算属性相似度,并以此确定表间关联属性
杰卡德相似系数是衡量两个集合相似度的一种指标,设表Ti、Tj在某个属性上取值集合分别为PVia和PVjb,它们的交集元素在并集中所占的比例,称为两个集合的杰卡德相似系数,即为属性值集合PVia和PVjb的相似度:
SP(PVia,PVjb)=|PVia∩PVjb|/|PVia∪PVjb|
SP(PVia,PVjb)取值范围为[0,1],当两个属性越相似,该值越接近1;反之,接近0;因此可以认为当SP(PVia,PVjb)>CP时,CP为关联属性阈值,Pia和Pjb即为关联属性,记为J(Pia,Pjb);
步骤202,确定表间关联度
对于表Ti与表Tj,其表关联度计算公式为:
其中t为表Ti与表Tj关联属性对数目,表示关联属性Pia、Pjb在Ti和Tj的属性重要度平均值;
步骤203,确定关联矩阵
根据步骤201和步骤202得到的表间关联属性及表间关联度,建立如下关联矩阵Mnn:
其中:Cij(i,j∈{1,...,n}且i<j)表示集合;J(Pia,Pjb)表示关联属性Pia和Pjb,
步骤3:根据关联矩阵,按表关联度从大到小选取未连接的数据表在关联属性上连接合并,同时综合属性重要度、属性值相似度计算记录相似度合并关联记录进而合并关联表。
步骤301,按数据表之间的关联度Sij从大到小排序,依次取关联度最大且未进行连接合并的两个表Ti和Tj进行连接合并,合并两表中的关联记录过程如步骤302;
步骤302,确定关联记录
对于记录ri{pi1,pi2,...,pia,...,pim}∈Ti和rj{pj1,pj2,...,pjb,...,pjn}∈Tj,判断ri和rj是否为关联记录,在关联属性上根据属性值相似度以及属性重要度计算ri和rj的相似度:
其中t为Ti和Tj关联属性对数量,SP(pia,pjb)=1-d(pia,pjb)/n即关联属性值p1i和p2j的相似度,d(pia,pjb)为属性值p1i和p2j的编辑距离,n为p1i和p2j中较长字符串的长度;若SR(ri,rj)>CR,CR为关联记录阈值,则ri和rj为关联记录,可以合并,根据计算结果,合并表Ti和Tj中所有的关联记录;;
步骤303,若所有表均参与连接合并,或者剩余一张表,则第一轮连接合并结束。若第一轮有m对数据表参与连接合并,则一轮合并之后还有(n-m)个表。根据之前的关联矩阵Tnn,重新构建这(n-m)个表的关联矩阵T(n-m)(n-m);
步骤304,根据重构的关联矩阵T(n-m)(n-m),重复步骤301至步骤303操作,直到最终所有数据表合并为一张表,则整个连接合并完成得到最终的连接合并结果集。
本发明的有益效果是:
本发明通过研究数据表的属性重要度,以及数据表间属性的相似度,建立不确定数据表的关联矩阵,然后根据关联矩阵选择关联度大的数据表在关联属性上进行连接合并得到相似记录数据集,经过多轮连接合并操作直至将所有的原始不确定数据表进行充分连接合并,从而实现对不确定数据对象进行全面准确描述的目标。解决了数据项含义不明确、数据对象不明确的不确定数据难以连接合并,从而无法得到数据描述对象的全息影像,造成数据难以理解和使用的问题。
附图说明
图1为方法流程图;
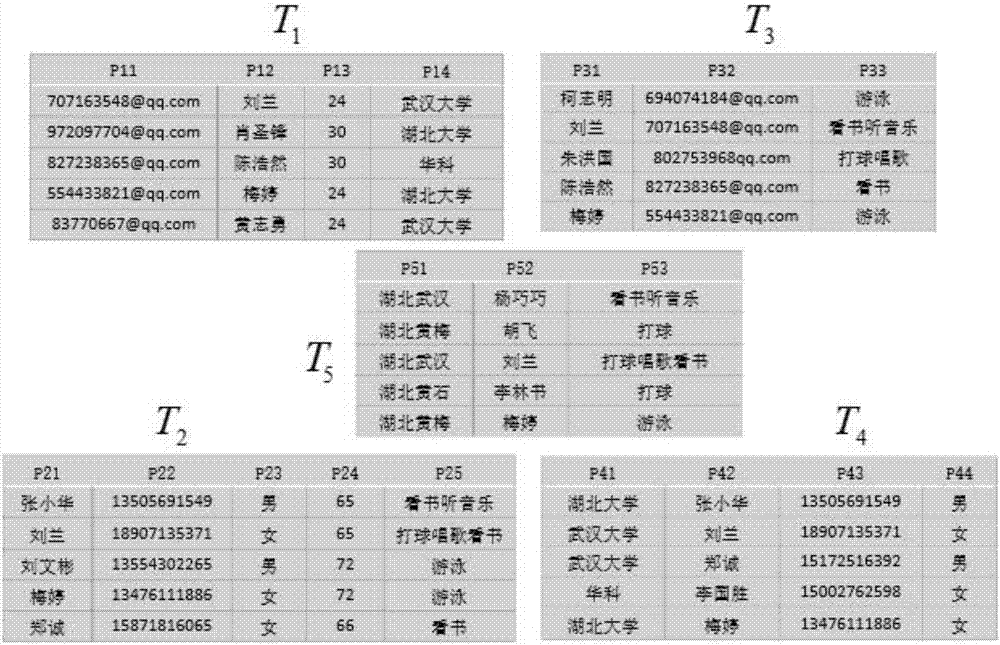
图2为实施例中用到的5个初始表格;
图3图4为图2中的5个初始表格经过第一轮连接合并后的结果;
图5为经过第二轮连接合并后的结果;
图6为经过第三轮连接合并后的结果。
具体实施方式
下面结合附图及实施例对本发明作进一步说明。以下的实施例将有助于本领域的技术人员进一步理解本发明,但不以任何形式限制本发明。
本发明通过建立不确定数据表的关联矩阵,找出数据表之间的关联属性,并根据数据表关联度确定连接合并顺序,从而提高连接合并的准确性以及高效性。具体实现步骤细化如下:
步骤一:确定属性重要度
数据表中的不同数据项对区分对象的重要度不同,计算不确定数据表的属性重要度,在进行连接合并时判断记录相似度考虑记录中各个属性的重要度,可以提高连接合并的准确性。计算不确定数据表的属性重要度具体步骤如下:
1、对于数据表T={P1,P2,...,Pn},Pi的取值为统计Pi中每个不同属性值的出现次数,如表2所列。
表2属性Pi的取值分布
由于同一数据表中存在同一对象的概率很小,因此在大数据表中可以认为每一条记录代表一个不同的对象,基于该假设,其值相等的概率为
由于可得
则属性Pi的重要度为:由于此值范围较大,不利于后期记录相似度的计算,因此对其进行平滑化处理和修正:
为了便于进行属性重要度比较,我们需要对属性重要度做进一步的归一化处理,得到:
其中Wp max表示数据表T所有属性重要度的最大值。
2、对所有的n个数据表进行同样的处理,得到n个表的属性重要度统计结果如下表3:
表3属性重要度统计
步骤二:确定关联矩阵
对于不同来源且数据项含义不明确、数据对象不明确的数据表,要连接合并表中表示同一对象的记录。如果直接在两个表之间进行连接匹配,计算量非常大。若两表维度分别为m维和n维,两表记录之间需要进行m*n次属性值相似匹配。因此为减少计算量,采用的策略是先在数据表之间找出关联属性,然后只需在关联属性上去判断各记录是否为同一对象,这样记录之间的连接匹配计算将大大减少,可以极大提高数据表的连接合并效率。计算n个不确定数据表之间属性的相似度,构建关联矩阵Tnn,具体步骤如下:
(一)计算不确定数据表之间属性的相似度,对于表Ti中的各个属性集合以及表Tj的各个属性集合为减少计算量,根据步骤一中各表的属性重要度计算结果,若两属性的属性重要度Wia、Wjb差距较小,则计算这两个属性值集合的相似度。设表Ti、Tj在某个属性上取值集合分别为PVia和PVjb,它们的交集元素在并集中所占的比例,称为两个集合的杰卡德相似系数,即为属性值集合PVia和PVjb的相似度:
SP(PVia,PVjb)=|PVia∩PVjb|/|PVia∪PVjb|
SP(PVia,PVjb)取值范围为[0,1],当两个属性越相似,该值越接近1;反之,接近0。因此可以认为当SP(PVia,PVjb)>CP时,CP为相似度阈值,Pia和Pjb即为关联属性,记为J(Pjb,Pjb)。
(二)计算不确定数据表之间关联度,表Ti与表Tj的关联度计算如下:
其中t为表Ti和表Tj关联属性对数目,表示关联属性Pia、Pjb在Ti和Tj的属性重要度平均值。
(三)建立数据表的关联矩阵Tnn,根据上述步骤1、2得到n个不确定数据表的两两之间的关联属性以及数据表的关联度,建立如下关联矩阵:
其中:Cij(i,j∈{1,...,n}且i<j)表示集合。J(Pia,Pjb)表示关联属性Pia和Pjb,
步骤三:进行连接合并操作
根据关联矩阵Mnn,连接合并数据表,按表之间的关联度Sij从大到小进行排序,依次选择关联度大且未进行连接合并的两个数据表进行连接合并,直到强联度的数据表都进行连接合并,更新合并后表的关联矩阵,根据新的关联矩阵,再次进行连接合并,直到最终所有表连接合并为一张表。
连接合并过程具体细节如下:
(一)按数据表之间的关联度Sij从大到小排序,依次取关联度最大且未进行连接合并的两个表Ti和Tj进行连接合并,合并两表中的关联记录过程如步骤2;
(二)对于记录ri{pi1,pi2,...,pia,...,pim}∈Ti和rj{pj1,pj2,...,pjb,...,pjn}∈Tj,判断ri和rj是否为关联记录,可以在关联属性上根据属性值相似度以及属性重要度计算ri和rj的相似度:其中t为Ti和Tj关联属性对数量,SP(pia,pjb)=1-d(pia,pjb)/n即关联属性值p1i和p2j的相似度,d(pia,pjb)为属性值p1i和p2j的编辑距离,n为p1i和p2j中较长字符串的长度。若SR(ri,rj)>CR,则ri和rj为关联记录,可以合并,根据计算结果,合并表Ti和Tj中所有的关联记录;
(三)若所有表均参与连接合并,或者剩余一张表,则第一轮连接合并结束。若第一轮有m对数据表参与连接合并,则一轮合并之后还有(n-m)个表。根据之前的关联矩阵Tnn,重新构建这(n-m)个表的关联矩阵T(n-m)(n-m);
(四)根据重构的关联矩阵,重复以上三步操作,直到最终所有数据表合并为一张表,则整个连接合并完成得到最终的连接合并结果集。
实例:要将图2中的五个数据表中为同一对象的记录合并在一起,得到对象的详细信息,具体步骤如下:
步骤一:计算五个表的属性重要度,得到各个表属性重要度计算结果如表4:
表4属性重要度计算示例
步骤二:确定关联矩阵
(一)计算五个表之间属性相似度,T1与T2属性相似度计算结果如表5所示(行代表T1,列代表T2),实际应用中为减少计算量,重要度差距较大的属性可以认为它们不可能具有相同的含义(如T1中的属性P11和T2中的属性P23),因此不考虑它们的相似度。
表5属性相似度计算示例
通过计算结果,可以看出表T1和T2的关联属性为J(P11,P22)。同理可得五个表的关联属性如表6:
表6关联属性计算示例
(二)计算五个表之间的关联度,并构建五个表的关联矩阵,表T1、T2、T3、T4、T5的关联矩阵为:
步骤三:进行连接合并操作
(一)第一轮连接合并
根据五个表的关联矩阵M55,将表关联度从大到小进行排序:
(S24=2.38)>(S13=2)>(S23=1.67)=(S25=1.67)=(S35=1.67)>
(S14=1.53)>(S12=1)=(S34=1)=(S45=1)>(S15=0.53)
1.根据排序结果,对T2和T4、表T1和T3中所有关联记录进行合并,得到连接合并结果集分别为T24、T13,如图3图4所示。
2.根据关联矩阵M55,重新构建T13、T24、T5三个数据表的关联矩阵M33。
(二)第二轮连接合并
根据关联矩阵M33,按照表关联度进行排序
(S13,24=2.20)>(S13,5=1.67)=(S24,5=1.67)。
再次将表T13和T24进行连接合并。得到连合并结果表T1324如图5所示;
第二次连接完成后,剩下表T1324和T5,根据关联矩阵M33,生成新的关联矩阵M22。
(三)第三轮连接合并
根据关联矩阵M22,再次将表T1324和T5进行连接合并,得到最终的结果表T13245如图6所示。
根据以上过程,原始的5张表合并为一张表。在这一张表中,对象数据得到全面性和准确性展示。
说明书中未阐述的部分均为现有技术或公知常识。本实施例仅用于说明该发明,而不用于限制本发明的范围,本领域技术人员对于本发明所做的等价置换等修改均认为是落入该发明权利要求书所保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!