基于神经网络结合遗传算法实时优化补料产丙氨酸的方法与流程
本发明涉及微生物发酵领域。更具体地说,本发明涉及一种用基于神经网络结合遗传算法实时优化补料产丙氨酸的方法。
背景技术:
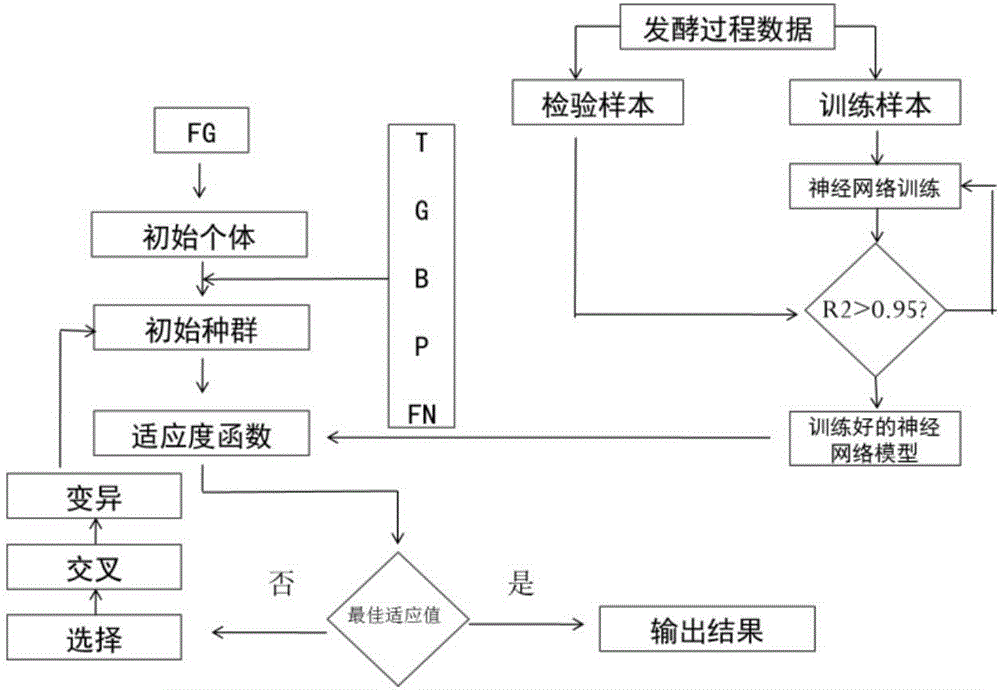
:发酵工业是技术密集型的产业,它涉及到微生物学、生物化学、化工、自动控制技术和计算机技术等。自70年代以来,国外对发酵过程动力学模型和优化控制做了大量的研究工作。并且从1979年起每隔三年举行一次计算机在发酵工程中应用的世界大会。在国内,发酵工业生产技术水平相对比较落后,对发酵过程的机理、模型化和优化控制研究起步较晚。对于具有高度非线性、时变性和复杂相关性的生化过程,为了获得高的产率和提高经济效益,加强生化过程的监督和控制是非常重要的。认为困难在于:生化过程机理复杂,通过机理建模难度大,得到的模型应用范围窄、精度低,并无多少实用性;生化参数检测手段不全,许多关键参数无法实时测量;生化过程中的不可逆性造成了控制困难,有些生化过程实际上缺乏有力的控制手段。针对上述困难,提出人工智能控制方法的应用是一种有效的解决方法。GA算法来源于进化论和群体遗传学。它是模拟生物进化机制得来的。在模拟生物从低级向高级进化的过程中所经历的突变、自然选择和繁殖过程,在GA算法中用选择、变异、交叉算法来对应;物竞天择、优胜劣汰的原则由种群依据目标函数的选择来体现;进化中的偶然性则由随机数来产生。经过逐代的进化,种群不断得到新的优良品种,最终要寻找的最优参数就产生了。目前国内尚没有对发酵过程动态变化进行实时监控发酵参数并控制补料的研究。技术实现要素:本发明的一个目的是解决至少上述问题,并提供至少后面将说明的优点。本发明还有一个目的是提供一种基于神经网络结合遗传算法实时优化补料产丙氨酸的方法,其能够根据发酵输入与输出构建神经网络模型,对补料控制参数(葡萄糖流加量)进行二进制编码,执行选择、交叉、变异,对产生的每个个体以神经网络进行预测,以预测值与最优值的方差为适应度函数,获得能够产生最优值的补料参数,通过应用此补料参数到发酵过程控制中以提高L-丙氨酸的转化速率。为了实现根据本发明的这些目的和其它优点,提供了一种基于神经网络结合遗传算法实时优化补料产丙氨酸的方法,包括以下步骤:S1:以葡萄糖为原料,采用XZ-A26菌株厌氧流加发酵产L-丙氨酸,建立各时刻多个发酵参数和L-丙氨酸浓度的发酵过程历史数据集,构建并训练BP神经网络模型,形成各时刻多个发酵参数和L-丙氨酸浓度与下一时刻L-丙氨酸浓度的映射关系,选择葡萄糖流加量为控制变量,构建遗传算法模型并优化计算,获得使预测的下一时刻L-丙氨酸浓度最大时葡萄糖流加量的模拟值;S2:发酵过程取样并测定各时刻的各发酵参数和L-丙氨酸浓度,发酵进行至吸光度达到预定值时,将测定的T时刻的L-丙氨酸浓度列为输出的训练数据,把测定的T-1时刻各发酵参数和L-丙氨酸浓度列为输入的训练数据,与历史数据集的训练数据合并训练BP神经网络模型,然后将测定的T时刻的除葡萄糖流加量以外的各发酵参数和L-丙氨酸浓度应用于遗传算法模型并优化计算,获得使预测的T+1时刻L-丙氨酸浓度最大时T时刻的葡萄糖流加量的最优值,并于T时刻投放相应量的葡萄糖完成补料,逐个时刻训练模型和优化计算,获得任意时刻葡萄糖流加量的最优值。优选的是,所述的基于神经网络结合遗传算法实时优化补料产丙氨酸的方法,多个发酵参数包括各时刻对应的OD值、葡萄糖浓度、葡萄糖流加量以及氨水流加量。优选的是,所述的基于神经网络结合遗传算法实时优化补料产丙氨酸的方法,将历史数据集的数据按发酵批次随机分为训练数据和测试数据,训练数据和测试数据的比值为3:1,发酵批次为15~20批次。优选的是,所述的基于神经网络结合遗传算法实时优化补料产丙氨酸的方法,BP神经网络模型以各时刻对应的时刻、吸光度值、葡萄糖浓度、L-丙氨酸浓度、葡萄糖流加量以及氨水流加量列为输入的训练数据,以下一时刻对应的L-丙氨酸浓度列为输出的训练数据,隐含层为两层,第一层为10个单元、第二层为3个单元,形成拓扑结构为6-10-3-1模式的BP神经网络模型。优选的是,所述的基于神经网络结合遗传算法实时优化补料产丙氨酸的方法,BP神经网络模型采用premnmx函数对输入的数据归一化处理,采用postmnmx函数对输出的预测的丙氨酸浓度反归一化处理,神经网络架构如下net=newff(pn,tn,[10,3],{'tansig','logsig','purelin'},'trainlm','learngdm')。优选的是,所述的基于神经网络结合遗传算法实时优化补料产丙氨酸的方法,其特征在于,构建遗传算法模型时,确定葡萄糖流加量的取值范围,进行二进制编码,在该取值范围内产生50个初始种群数量,设置迭代次数为100次,Pc交叉概率为0.25,Pm突变概率为0.01。优选的是,所述的基于神经网络结合遗传算法实时优化补料产丙氨酸的方法,其特征在于,吸光度达到的预定值为5。优选的是,所述的基于神经网络结合遗传算法实时优化补料产丙氨酸的方法,S2中取样、测定、训练模型、优化计算、投放葡萄糖完成补料整个过程的时间不超过30min,各时刻的间隔为2h。本发明至少包括以下有益效果:将BP神经网络模型和遗传算法结合,应用于发酵过程的动态变化,实时监控发酵参数并根据实时训练、优化计算获得最优补料控制参数,以提高L-丙氨酸的产量。本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。附图说明图1为本发明的BP神经网络模型的结构示意图;图2为本发明的BP神经网络模型和遗传算法模型的流程图;图3为本发明所述的方法实时优化L-丙氨酸补料发酵控制流程图;图4为本发明应用于发酵过程中(T=20)时刻的遗传算法模型的优化计算图。具体实施方式下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不配出一个或多个其它元件或其组合的存在或添加。需要说明的是,下述实施方案中所述实验方法,如无特殊说明,均为常规方法,所述试剂和材料,如无特殊说明,均可从商业途径获得。一种基于神经网络结合遗传算法实时优化补料产丙氨酸的方法,如图3所示,具体包括以下步骤:步骤一:葡萄糖为原料,采用XZ-A26菌株(保藏号为CGMCCNo.4036)厌氧流加发酵产L-丙氨酸,建立各时刻多个发酵参数和L-丙氨酸浓度的发酵过程历史数据集;具体来说,该历史数据集包括:发酵过程中记录的每个时间点的吸光度B(T)、葡萄糖浓度G(T)、丙氨酸浓度P(T)、氨水流加量FN(T)和葡萄糖流加量FG(T);步骤二:按照发酵批次划分,四分之三批次的发酵数据作为训练数据,剩余四分之一的发酵数据为测试数据;发酵批次越多,发酵数据越多,以提高训练的BP神经网络模型的准确性;步骤三:根据所要建立的BP神经网络模型的输入输出,构建神经网络模型,形成各时刻多个发酵参数和L-丙氨酸浓度与下一时刻L-丙氨酸浓度的映射关系;设定输入为T时刻吸光度、葡萄糖浓度、丙氨酸浓度、氨水流加量和葡萄糖流加量,输出为T+1时刻的丙氨酸浓度。通过多次训练确定隐含层的为两层,第一层为10个节点,第二层为3个节点。则神经网络为6-10-3-1模式,如图1所示。采用premnmx函数归一化数据;神经网络架构如下net=newff(pn,tn,[10,3],{'tansig','logsig','purelin'},'trainlm','learngdm');设置训练参数net.trainParam.showWindow=true;net.trainParam.max_fail=10;net.trainParam.show=50;net.trainParam.lr=0.2;net.trainParam.mc=0.9;net.trainParam.epochs=1000;net.trainParam.goal=0.0001;训练后将预测值通过反归一函数postmnmx进行反归一化每层的传递函数分别为tansig,logsig,purelin;步骤四:如图2所示,根据发酵过程所要优化计算的发酵过程控制变量为葡萄糖流加量,确定其取值范围0~30,进行二进制编码,产生初始种群数量为50,以构建好的BP神经网络模型通过初始种群预测它们对应的丙氨酸产量,以预测值与最优值的方差为适应度函数(也就是预测值随着迭代进行越来越大,在接近最大值,从而获得预测值达到最大的葡萄糖流加量)计算它们的适应值,计算初始种群适应度,返回适应度Fitvalue和积累概率cumsump;执行选择、交叉、变异等程序,迭代次数为100,交叉概率为0.25,突变概率为0.01,优化结果如图4所示;获得使预测的下一时刻L-丙氨酸浓度最大时葡萄糖流加量的模拟值;步骤五:发酵进行至吸光度为5时,取样30min内测定T时刻的吸光度、葡萄糖浓度、丙氨酸浓度、氨水流加量,并把测定的丙氨酸浓度输入至训练数据输出序列中,把T-1时刻前测定输入参数数据输入到训练数据中,将它们与历史数据一起,训练BP神经网络模型;步骤六:将测定的T时刻的吸光度、葡萄糖浓度、丙氨酸浓度、氨水流加量应用至遗传算法程序中,计算寻优能够使T+1时刻丙氨酸达到最大的T时刻的葡萄糖补加量,将计算的葡萄糖流加量输入到发酵控制面板中,在一个时间间隔(本发酵为2h)中完成本次补料;步骤七:逐个时间点进行优化控制参数的计算,获得下一时刻葡萄糖流加量的最优值,并完成补料。<产量试验>按照以上操作步骤,进行三次的发酵实验,实验组为采用神经网络遗传算法控制的葡萄糖流加,对照组为按照氨水消耗与糖消耗的比值控制葡萄糖流加,每小时单位OD转化葡萄糖产生的丙氨酸的量如表所示(=最终产量/时间/最大OD),结果如下表所示:2015122016011320160117实验组0.0409310.041360.04081对照组0.037140.035230.035由上表可知,基于神经网络结合遗传算法控制的补料可以明显提高L-丙氨酸的转化速率。这里说明的设备数量和处理规模是用来简化本发明的说明的。对本发明的应用、修改和变化对本领域的技术人员来说是显而易见的。尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的细节。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1