面向多数据源的疾病类实体识别方法及装置与流程
本发明涉及医疗实体识别技术领域,尤其涉及一种面向多数据源的疾病类实体识别方法及装置。
背景技术:
当前,大数据时代,随着医疗卫生领域的不断发展,医疗卫生领域不同业务不同格式的数据从各个领域涌现出来,这些数据称为医疗大数据。医疗大数据中隐藏着大量可以被识别和挖掘的信息,是一座医学知识宝库。因此如何利用医疗大数据为医疗机构和广大患者服务是目前重要的课题,也是移动互联网医疗时代的热点也是重点问题。目前,医疗大数据的应用方向有:1)临床治疗效果比较研究,主要思想是从医疗大数据中分析病人特征数据和疗效数据,比较不同干预措施的有效性,找到针对特定病人最佳治疗途径,从而提高临床服务质量。2)公共卫生的疫情监测,主要思想是从医疗大数据中分析某地区病人的发病情况、临床症状等数据,预测出该地区患有某疾病的可能与动向,从而提高疾病预报和预警能力,防止疫情爆发。可见,上述的医疗大数据的应用离不开医疗数据中疾病类实体的识别。
近年来,医疗健康领域的蓬勃发展使得该领域的研究逐渐增多,例如医疗问答、智能诊断、疾病预警等。作为医疗健康数据分析的重要的一步,医疗实体识别(特别是疾病类实体识别)可以抽取出相关文本中存在的医疗术语,对后续研究的性能起到重要的作用。目前常见的实体识别技术有基于词表的医学实体识别和基于条件随机场(conditionalrandomfields,简称crf)的医学实体识别,然而基于词表的医学实体识别仅仅依靠语库匹配,缺少上下文语境识别,且语库匹配存在较大局限性。而基于crf的医学实体识别技术,缺少大数据语料库和语言规则的应用,语料均为人工标注后的语料,而没有利用半监督学习等方法,增加对数量更庞大的未标注数据的使用,使得模型不够完善,缺少基于语言学与医疗信息的规则,仅仅依靠模型,对数据的针对性不够强。可见,当前的实体识别方案并不能准确进行疾病类实体识别。
技术实现要素:
本发明的实施例提供一种面向多数据源的疾病类实体识别方法及装置,以解决当前的实体识别方案并不能准确进行疾病类实体识别的问题。
为达到上述目的,本发明采用如下技术方案:
一种面向多数据源的疾病类实体识别方法,包括:
获取原始数据中的待处理语句;
将所述待处理语句进行单字切分,确定待处理语句中的每个文字;
根据预先训练完成的crf训练模型,确定待处理语句中的每个文字在待处理语句中的实体标记,并确定待处理语句的实体标记序列;
根据待处理语句的实体标记序列,确定待处理语句的第一组候选实体;
根据预先设置的疾病类术语切分策略,对所述待处理语句进行术语切分,确定第二组候选实体;
根据第一组候选实体和第二组候选实体中各候选实体的末尾字符,对各候选实体进行筛选,分别形成第一组疾病类候选实体和第二组疾病类候选实体;
若第一组疾病类候选实体和第二组疾病类候选实体不相同,根据预先设置的判断策略从第一组疾病类候选实体和第二组疾病类候选实体中确定疾病类实体结果。
具体的,所述根据预先设置的判断策略从第一组疾病类候选实体和第二组疾病类候选实体中确定疾病类实体结果,包括:
确定待处理语句在进行术语切分时,是否通过预先设置的切分规则进行切分;
若待处理语句在进行术语切分时,通过预先设置的切分规则进行切分,则选择所述第二组疾病类候选实体中的候选实体作为疾病类实体结果;
若待处理语句在进行术语切分时,未通过预先设置的切分规则进行切分,则选择所述第一组疾病类候选实体中的候选实体作为疾病类实体结果;
或者,确定来源于相同待处理语句的原始字符串的第一组疾病类候选实体和第二组疾病类候选实体中,实体个数少,且实体包含的字符数多的一组实体作为疾病类实体结果。
具体的,所述原始数据包括结构化数据、半结构化数据或非结构化数据;所述非结构化数据包括电子病历emr数据、电子健康档案ehr数据;所述结构化数据包括临床结算单数据、网络医疗知识库数据。
具体的,根据预先训练完成的crf训练模型,确定待处理语句中的每个文字在待处理语句中的实体标记,并确定待处理语句的实体标记序列,包括:
从预先设置的语料库中提取待处理语句中的每个文字的crf统计特征值;所述预先设置的语料库中记录有原始数据中各语句、各语句中的实体、以及各语句中的实体在各语句中的位置以及实体类别;所述crf统计特征值包括每个文字在各语句中的分词特征值、词性特征值、字符特征值、上下文特征值以及术语表特征值;
根据每个字在各语句中的crf统计特征值,确定一训练模型;所述训练模型为:
根据所述训练模型,计算待处理语句中的每个文字的实体标记yj;
将每个文字的实体标记进行组合,形成待处理语句的实体标记序列;其中,x表示所述待处理语句;yj表示待处理语句中j位置对应的文字的实体标记;fi(yj,yj-1,x)表示待处理语句中分词特征i的函数值;λi为模型参数;m表示分词特征的个数;n表示待处理语句中的文字位置个数;z(x)表示归一化因子;p(y|x)表示文字在待处理语句中的标记概率。
具体的,根据待处理语句的实体标记序列,确定待处理语句的第一组候选实体,包括:
在实体标记序列中确定各文字对应的分词特征值,并根据所述分词特征值确定待处理语句的第一组候选实体。
进一步的,该面向多数据源的疾病类实体识别方法,还包括:
在所述待处理语句未在预先设置的语料库中被标注,根据公式:
将待处理语句中不确定值为1的实体与预先设置的疾病本体库匹配,若匹配成功,则将匹配成功的实体的实体标记进行保存;
确定待处理语句的预测置信度和字典匹配标记的实体比例;
将预测置信度大于预设置信度阈值和字典匹配标记的实体比例大于预设比例阈值的待处理语句加入到所述语料库中,以进行语料库更新;
其中,所述预测置信度为待处理语句中各文字对应的标记概率的乘积;
所述字典匹配标记的实体比例为:
具体的,根据预先设置的疾病类术语切分策略,对所述待处理语句进行术语切分,确定第二组候选实体,包括:
将待处理语句中的标点符号转换为半角,并将英文字母统一为大写英文字母;
调用预先设置的非医学术语表,检查待处理语句中的原始字符串是否存在非医学术语表中的术语,并将待处理语句中存在的非医学术语表中的术语删除,形成预处理后的待处理语句;
将预处理后的待处理语句采用最大匹配原则与预先设置的疾病本体库进行匹配切分,形成本体切分结果;
根据预处理后的待处理语句以及其中的本体切分结果,确定预处理后的待处理语句中除本体切分结果之外的其他字符;
将所述其他字符与所述本体切分结果以预先设置的切分规则重新进行切分,形成第一切分结果;
将预处理后的待处理语句的原始字符串按顺序检查字符串中的符号,并在字符串中的符号满足预设切分条件时,转换为系统分隔符进行切分,形成基于符号切分结果;
根据所述第一切分结果和基于符号切分结果中符号的类型和位置,以预先设置的切分规则重新进行切分,形成第二组候选实体。
具体的,根据第一组候选实体和第二组候选实体中各候选实体的末尾字符,对各候选实体进行筛选,分别形成第一组疾病类候选实体和第二组疾病类候选实体,包括:
判断第一组候选实体和第二组候选实体中各候选实体的末尾字符是否为预先设置的非疾病术语字符;
若各候选实体的末尾字符为预先设置的非疾病术语字符,将所述候选实体舍弃。
一种面向多数据源的疾病类实体识别装置,包括:
待处理语句获取单元,用于获取原始数据中的待处理语句;
单字切分单元,用于将所述待处理语句进行单字切分,确定待处理语句中的每个文字;
实体标记序列确定单元,用于根据预先训练完成的crf训练模型,确定待处理语句中的每个文字在待处理语句中的实体标记,并确定待处理语句的实体标记序列;
第一组候选实体确定单元,用于根据待处理语句的实体标记序列,确定待处理语句的第一组候选实体;
第二组候选实体确定单元,用于根据预先设置的疾病类术语切分策略,对所述待处理语句进行术语切分,确定第二组候选实体;
候选实体筛选单元,用于根据第一组候选实体和第二组候选实体中各候选实体的末尾字符,对各候选实体进行筛选,分别形成第一组疾病类候选实体和第二组疾病类候选实体;
疾病类实体结果确定单元,用于在第一组疾病类候选实体和第二组疾病类候选实体不相同时,根据预先设置的判断策略从第一组疾病类候选实体和第二组疾病类候选实体中确定疾病类实体结果。
具体的,所述疾病类实体结果确定单元,包括:
术语切分判断模块,用于确定待处理语句在进行术语切分时,是否通过预先设置的切分规则进行切分;
疾病类实体结果确定模块,用于在待处理语句在进行术语切分时,通过预先设置的切分规则进行切分,则选择所述第二组疾病类候选实体中的候选实体作为疾病类实体结果;在待处理语句在进行术语切分时,未通过预先设置的切分规则进行切分,则选择所述第一组疾病类候选实体中的候选实体作为疾病类实体结果;
所述疾病类实体结果确定模块,还用于确定来源于相同待处理语句的原始字符串的第一组疾病类候选实体和第二组疾病类候选实体中,实体个数少,且实体包含的字符数多的一组实体作为疾病类实体结果。
具体的,所述待处理语句获取单元中的原始数据包括结构化数据、半结构化数据或非结构化数据;所述非结构化数据包括电子病历emr数据、电子健康档案ehr数据;所述结构化数据包括临床结算单数据、网络医疗知识库数据。
进一步的,所述实体标记序列确定单元,包括:
crf统计特征值提取模块,用于从预先设置的语料库中提取待处理语句中的每个文字的crf统计特征值;所述预先设置的语料库中记录有原始数据中各语句、各语句中的实体、以及各语句中的实体在各语句中的位置以及实体类别;所述crf统计特征值包括每个文字在各语句中的分词特征值、词性特征值、字符特征值、上下文特征值以及术语表特征值;
训练模型确定模块,用于根据每个字在各语句中的crf统计特征值,确定一训练模型;所述训练模型为:
实体标记计算模块,用于根据所述训练模型,计算待处理语句中的每个文字的实体标记yj;
实体标记序列确定模块,用于将每个文字的实体标记进行组合,形成待处理语句的实体标记序列;其中,x表示所述待处理语句;yj表示待处理语句中j位置对应的文字的实体标记;fi(yj,yj-1,x)表示待处理语句中分词特征i的函数值;λi为模型参数;m表示分词特征的个数;n表示待处理语句中的文字位置个数;z(x)表示归一化因子;p(y|x)表示文字在待处理语句中的标记概率。
此外,所述第一组候选实体确定单元,具体用于:
在实体标记序列中确定各文字对应的分词特征值,并根据所述分词特征值确定待处理语句的第一组候选实体。
进一步的,所述的面向多数据源的疾病类实体识别装置,还包括语料库更新单元,用于:
在所述待处理语句未在预先设置的语料库中被标注,根据公式:
将待处理语句中不确定值为1的实体与预先设置的疾病本体库匹配,在匹配成功时,将匹配成功的实体的实体标记进行保存;
确定待处理语句的预测置信度和字典匹配标记的实体比例;
将预测置信度大于预设置信度阈值和字典匹配标记的实体比例大于预设比例阈值的待处理语句加入到所述语料库中,以进行语料库更新;
其中,所述预测置信度为待处理语句中各文字对应的标记概率的乘积;
所述字典匹配标记的实体比例为:
此外,所述第二组候选实体确定单元,包括:
预处理模块,用于将待处理语句中的标点符号转换为半角,并将英文字母统一为大写英文字母;调用预先设置的非医学术语表,检查待处理语句中的原始字符串是否存在非医学术语表中的术语,并将待处理语句中存在的非医学术语表中的术语删除,形成预处理后的待处理语句;
本体切分模块,用于将预处理后的待处理语句采用最大匹配原则与预先设置的疾病本体库进行匹配切分,形成本体切分结果;
第一切分结果形成模块,用于根据预处理后的待处理语句以及其中的本体切分结果,确定预处理后的待处理语句中除本体切分结果之外的其他字符;将所述其他字符与所述本体切分结果以预先设置的切分规则重新进行切分,形成第一切分结果;
符号切分模块,用于将预处理后的待处理语句的原始字符串按顺序检查字符串中的符号,并在字符串中的符号满足预设切分条件时,转换为系统分隔符进行切分,形成基于符号切分结果;
第二组候选实体形成模块,用于根据所述第一切分结果和基于符号切分结果中符号的类型和位置,以预先设置的切分规则重新进行切分,形成第二组候选实体。
此外,所述候选实体筛选单元,包括:
非疾病术语字符判断模块,用于判断第一组候选实体和第二组候选实体中各候选实体的末尾字符是否为预先设置的非疾病术语字符;
候选实体舍弃模块,用于在各候选实体的末尾字符为预先设置的非疾病术语字符时,将所述候选实体舍弃。
本发明实施例提供的一种面向多数据源的疾病类实体识别方法及装置,首先,获取原始数据中的待处理语句;将所述待处理语句进行单字切分,确定待处理语句中的每个文字;根据预先训练完成的crf训练模型,确定待处理语句中的每个文字在待处理语句中的实体标记,并确定待处理语句的实体标记序列;根据待处理语句的实体标记序列,确定待处理语句的第一组候选实体;然后,根据预先设置的疾病类术语切分策略,对所述待处理语句进行术语切分,确定第二组候选实体;根据第一组候选实体和第二组候选实体中各候选实体的末尾字符,对各候选实体进行筛选,分别形成第一组疾病类候选实体和第二组疾病类候选实体;若第一组疾病类候选实体和第二组疾病类候选实体不相同,根据预先设置的判断策略从第一组疾病类候选实体和第二组疾病类候选实体中确定疾病类实体结果。本发明将条件随机场crf统计机器学习方法与术语切分方法相结合,能够自动识别疾病类实体,克服了当前的实体识别的数据源较为单一,实体识别不准确的问题。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的一种面向多数据源的疾病类实体识别方法的流程图一;
图2为本发明实施例提供的一种面向多数据源的疾病类实体识别方法的流程图二;
图3为本发明实施例提供的一种面向多数据源的疾病类实体识别装置的结构示意图一;
图4为本发明实施例提供的一种面向多数据源的疾病类实体识别装置的结构示意图二。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图1所示,本发明实施例提供一种面向多数据源的疾病类实体识别方法,包括:
步骤101、获取原始数据中的待处理语句。
步骤102、将所述待处理语句进行单字切分,确定待处理语句中的每个文字。
步骤103、根据预先训练完成的crf训练模型,确定待处理语句中的每个文字在待处理语句中的实体标记,并确定待处理语句的实体标记序列。
步骤104、根据待处理语句的实体标记序列,确定待处理语句的第一组候选实体。
步骤105、根据预先设置的疾病类术语切分策略,对所述待处理语句进行术语切分,确定第二组候选实体。
步骤106、根据第一组候选实体和第二组候选实体中各候选实体的末尾字符,对各候选实体进行筛选,分别形成第一组疾病类候选实体和第二组疾病类候选实体。
步骤107、若第一组疾病类候选实体和第二组疾病类候选实体不相同,根据预先设置的判断策略从第一组疾病类候选实体和第二组疾病类候选实体中确定疾病类实体结果。
本发明实施例提供的一种面向多数据源的疾病类实体识别方法,首先,获取原始数据中的待处理语句;将所述待处理语句进行单字切分,确定待处理语句中的每个文字;根据预先训练完成的crf训练模型,确定待处理语句中的每个文字在待处理语句中的实体标记,并确定待处理语句的实体标记序列;根据待处理语句的实体标记序列,确定待处理语句的第一组候选实体;然后,根据预先设置的疾病类术语切分策略,对所述待处理语句进行术语切分,确定第二组候选实体;根据第一组候选实体和第二组候选实体中各候选实体的末尾字符,对各候选实体进行筛选,分别形成第一组疾病类候选实体和第二组疾病类候选实体;若第一组疾病类候选实体和第二组疾病类候选实体不相同,根据预先设置的判断策略从第一组疾病类候选实体和第二组疾病类候选实体中确定疾病类实体结果。本发明将条件随机场crf统计机器学习方法与术语切分方法相结合,能够自动识别疾病类实体,克服了当前的实体识别的数据源较为单一,实体识别不准确的问题。
为了使本领域的技术人员更好的了解本发明,下面结合具体的实例来说明本发明。如图2所示,本发明实施例提供一种面向多数据源的疾病类实体识别方法,包括:
步骤201、获取原始数据中的待处理语句。
具体的,所述原始数据包括结构化数据、半结构化数据或非结构化数据;所述非结构化数据包括电子病历emr(electronicmedicalrecord)数据、电子健康档案ehr(electronichealthrecord)数据;所述结构化数据包括临床结算单数据、网络医疗知识库数据、文献库数据等。可见,本发明实施例所能处理的原始数据多样,不仅仅局限于单一数据源。
步骤202、将所述待处理语句进行单字切分,确定待处理语句中的每个文字。
例如,待处理语句为“高血压怎么治疗?”,则单字切分后,每个文字为:“高”、“血”、“压”、“怎”、“么”、“治”、“疗”、“?”。
步骤203、从预先设置的语料库中提取待处理语句中的每个文字的crf统计特征值。
所述预先设置的语料库中记录有原始数据中各语句、各语句中的实体、以及各语句中的实体在各语句中的位置以及实体类别;所述crf统计特征值包括每个文字在各语句中的分词特征值、词性特征值、字符特征值、上下文特征值以及术语表特征值。
对于预先设置的语料库可以由人为预先标注,例如语句:
“高血压能否吃法华林?”
“高血压怎么治疗?”
则对于疾病类实体,可以分别标注出:
c=高血压p=1:01:2
c=高血压p=2:02:2
其中,c表示疾病类实体,p表示疾病类实体所在语料库中句子的行号及句子中字符位置。
对于crf统计特征值,例如语句“高血压怎么治疗?”,其实体标记序列为“bieooooo”。例如,对于“压”字,crf统计特征说明如下表1所示:
表1:
步骤204、根据每个字在各语句中的crf统计特征值,确定一训练模型。
其中,所述训练模型为:
步骤205、根据所述训练模型,计算待处理语句中的每个文字的实体标记yj。
其中,x表示所述待处理语句;yj表示待处理语句中j位置对应的文字的实体标记;fi(yj,yj-1,x)表示待处理语句中分词特征i的函数值;λi为模型参数,训练得到的模型参数可使句子的训练模型p(y|x)的和达到最大;m表示分词特征的个数;n表示待处理语句中的文字位置个数;z(x)表示归一化因子;p(y|x)表示文字在待处理语句中的标记概率。
对于fi(yj,yj-1,x),其表示若yj、yj-1、x均出现在语料中,则fi(yj,yj-1,x)=1,否则为0。
步骤206、将每个文字的实体标记进行组合,形成待处理语句的实体标记序列。
例如语句“高血压怎么治疗?”,其实体标记序列为“bieooooo”。
步骤207、在实体标记序列中确定各文字对应的分词特征值,并根据所述分词特征值确定待处理语句的第一组候选实体。
例如,对于“高血压怎么治疗?”,其第一组候选实体为“高血压”。
步骤208、将待处理语句中的标点符号转换为半角,并将英文字母统一为大写英文字母。
步骤209、调用预先设置的非医学术语表,检查待处理语句中的原始字符串是否存在非医学术语表中的术语,并将待处理语句中存在的非医学术语表中的术语删除,形成预处理后的待处理语句。
步骤210、将预处理后的待处理语句采用最大匹配原则与预先设置的疾病本体库进行匹配切分,形成本体切分结果。
疾病本体库是以国际icd10为基本框架,在不改变icd10本身术语、结构和使用方法的基础上构建自然语言及不同版本icd10与卫生部icd10的关联关系。构建方法首先对卫生部版icd-10进行结构化,对每一个icd-10分类和实体进行规范化的描述。每一个icd-10分类和实体至少有一个正式的概念描述(标准术语),这些标准术语基于编码用一个树状结构来表示,并且每一个语义关联都包含基数信息。这一步主要的目的主要有两个:(1)从每一个类别名称当中识别其组成概念范畴;(2)赋予每一个标准术语语义关系来形成树状结构。
举例如下:
如,原始数据“患者无高血压冠心病”,如果术语表中有术语“血压”、“高血压”、“冠心病”,则匹配结果为“患者无[高血压][冠心病]”(方括号内的为匹配到的术语)。
再如,原始数据“初步诊断为:胸腺瘤,a型”,如果术语表中有术语“胸腺瘤,a型”,则匹配结果为“初步诊断为:[胸腺瘤,a型]”(方括号内的为匹配到的术语)。
步骤211、根据预处理后的待处理语句以及其中的本体切分结果,确定预处理后的待处理语句中除本体切分结果之外的其他字符。
步骤212、将所述其他字符与所述本体切分结果以预先设置的切分规则重新进行切分,形成第一切分结果。
当上述步骤210抽出的两个词之间是带有“伴、合并”等连接词时,需重新将该两词与“伴、合并”作为整体抽出。
例如原始数据“前列腺增生伴急性尿潴留”,基于本体抽词后的结果为“[前列腺增生]伴[急性尿潴留]”,基于步骤212的切分规则后的第一切分结果为“[前列腺增生伴急性尿潴留]”。
当上述步骤210抽出的两个词之间是表示疾病程度或解剖术语时,将疾病程度或解剖术语与第二个词作为整体抽出。
例如原始数据“前列腺增生急性肾性贫血”,基于本体抽词后的结果为“[前列腺增生]急性[肾性贫血]”,基于切分规则后的结果为“[前列腺增生][急性肾性贫血]”。上述的方括号内的内容为抽出的术语。
当上述步骤210完成后,剩下的字符串为原始术语的开头部分,且是疾病程度或解剖术语,则将疾病程度或解剖术语与其后相连的术语作为整体抽出。例如原始数据“亚急性支气管炎前列腺增生”,基于本体抽词后的结果为“亚急性[支气管炎][前列腺增生]”,基于切分规则后的结果为“[亚急性支气管炎][前列腺增生]”。上述的方括号内的内容为抽出的术语。
当上述步骤210完成后,剩下的字符串为原始术语的末尾部分,且是疾病程度或解剖术语,则将疾病程度或解剖术语与其前相连的术语作为整体抽出。例如示例中的“支气管炎前列腺癌晚期”,基于本体抽词后的结果为“[支气管炎][前列腺癌]晚期”,基于切分规则后的结果为“[支气管炎][前列腺癌晚期]”。上述方括号内的内容为抽出的术语。
步骤213、将预处理后的待处理语句的原始字符串按顺序检查字符串中的符号,并在字符串中的符号满足预设切分条件时,转换为系统分隔符进行切分,形成基于符号切分结果。
预设切分条件可以是例如:
数字与“,、.。”的组合,将这个组合整体进行切分。
对于“:”,如果冒号前后不全是汉字,则切分,否则不予处理。如“腹痛:?”,需切分,如“先天性心脏病:室间隔缺损”不处理。
对于“+”,判断前后术语是否都是中文,如果是则切分,否则不处理。
对于“-”,不予处理。
对于“;;.。??!!“'‘\"|\n\t,,、/()”这样的字符,则直接切分。
步骤214、根据所述第一切分结果和基于符号切分结果中符号的类型和位置,以预先设置的切分规则重新进行切分,形成第二组候选实体。
此处,在步骤214中,该预先设置的切分规则可以为:
如果符号是顿号、斜杠、逗号、括号时,如果基于符号切分后的两个连续字符串中,有一个字符是疾病限定时,则需将此两字符串连同符号一起作为整体抽出。例如“急、慢性肺炎”,“高血压,3级”。
如果符号是顿号、斜杠、逗号、括号时,如果基于符号切分后的两个连续字符串中,有一个字符是解剖术语时,则需将此两字符串连同符号一起作为整体抽出。例如示例中的“支气管/肺炎”。
如果符号是顿号、斜杠、逗号、括号时,如果基于符号切分后的两个连续字符串中,有一个字符是单字时时,则需将此两字符串连同符号一起作为整体抽出。例如“支/衣原体感染”,“急、慢性肺炎”。
步骤215、判断第一组候选实体和第二组候选实体中各候选实体的末尾字符是否为预先设置的非疾病术语字符。
该预先设置的非疾病术语字符可以是例如“手术、检查、胶囊、药、术”等。
步骤216、若各候选实体的末尾字符为预先设置的非疾病术语字符,将所述候选实体舍弃。
在步骤216之后,执行步骤217或者步骤220。
步骤217、在第一组疾病类候选实体和第二组疾病类候选实体不相同时,确定待处理语句在进行术语切分时,是否通过预先设置的切分规则进行切分。
在步骤217之后,执行步骤218或者步骤219。
步骤218、若待处理语句在进行术语切分时,通过预先设置的切分规则进行切分,则选择所述第二组疾病类候选实体中的候选实体作为疾病类实体结果。
步骤219、若待处理语句在进行术语切分时,未通过预先设置的切分规则进行切分,则选择所述第一组疾病类候选实体中的候选实体作为疾病类实体结果。
例如,原始数据“初步诊断:前列腺增生急性肾性贫血,高血压,3级”,
第一组疾病类候选实体为“[前列腺增生]急性[肾性贫血],[高血压],3级”;
第二组疾病类候选实体为“[前列腺增生][急性肾性贫血],[高血压,3级]”,即第二组疾病类候选实体是经过切分规则切分形成的。
则,最终结果为“[前列腺增生][急性肾性贫血],[高血压,3级]”。
步骤220、在第一组疾病类候选实体和第二组疾病类候选实体不相同时,确定来源于相同待处理语句的原始字符串的第一组疾病类候选实体和第二组疾病类候选实体中,实体个数少,且实体包含的字符数多的一组实体作为疾病类实体结果。
例如,原始数据“便秘(脾虚型),埃博拉病毒出血热”,第一组疾病类候选实体为“[便秘(脾虚型)][埃博拉出病毒血热]”,第二组疾病类候选实体为“[便秘][脾虚型][病毒][出血热]”,则最终结果为““[便秘(脾虚型)][埃博拉出病毒血热]”。
通过上述步骤201至步骤220,最终可以得到疾病类实体识别结果,例如原始数据为:“病人因风湿性联合瓣膜病、慢性支气管炎感染加重入院”。则疾病类实体识别结果为:
风湿性联合瓣膜病【疾病】;
慢性支气管炎【疾病】;
感染【疾病】;
为了实现对语料库进行更新,可以由人工总结发现新的句型特征,并人工标注加入到语料库中;另外,还可以在所述待处理语句未在预先设置的语料库中被标注,根据公式:
将待处理语句中不确定值为1的实体与预先设置的疾病本体库匹配,若匹配成功,则将匹配成功的实体的实体标记进行保存。
确定待处理语句的预测置信度和字典匹配标记的实体比例。
将预测置信度大于预设置信度阈值和字典匹配标记的实体比例大于预设比例阈值的待处理语句加入到所述语料库中,以进行语料库更新。
其中,所述预测置信度为待处理语句中各文字对应的标记概率的乘积。
所述字典匹配标记的实体比例为:
可见,通过语料库的更新,可以实现实体识别所需语料数据利用半监督自学习方法,实现语料库不断丰富,解决了语料库数目不足、不完整的问题。
本发明实施例提供的一种面向多数据源的疾病类实体识别方法,首先,获取原始数据中的待处理语句;将所述待处理语句进行单字切分,确定待处理语句中的每个文字;根据预先训练完成的crf训练模型,确定待处理语句中的每个文字在待处理语句中的实体标记,并确定待处理语句的实体标记序列;根据待处理语句的实体标记序列,确定待处理语句的第一组候选实体;然后,根据预先设置的疾病类术语切分策略,对所述待处理语句进行术语切分,确定第二组候选实体;根据第一组候选实体和第二组候选实体中各候选实体的末尾字符,对各候选实体进行筛选,分别形成第一组疾病类候选实体和第二组疾病类候选实体;若第一组疾病类候选实体和第二组疾病类候选实体不相同,根据预先设置的判断策略从第一组疾病类候选实体和第二组疾病类候选实体中确定疾病类实体结果。本发明将条件随机场crf统计机器学习方法与术语切分方法相结合,能够自动识别疾病类实体,克服了当前的实体识别的数据源较为单一,实体识别不准确的问题。
对应于上述图1和图2所示的方法实施例,如图3所示,本发明实施例提供一种面向多数据源的疾病类实体识别装置,包括:
待处理语句获取单元31,用于获取原始数据中的待处理语句。
单字切分单元32,用于将所述待处理语句进行单字切分,确定待处理语句中的每个文字。
实体标记序列确定单元33,用于根据预先训练完成的crf训练模型,确定待处理语句中的每个文字在待处理语句中的实体标记,并确定待处理语句的实体标记序列。
第一组候选实体确定单元34,用于根据待处理语句的实体标记序列,确定待处理语句的第一组候选实体。
第二组候选实体确定单元35,用于根据预先设置的疾病类术语切分策略,对所述待处理语句进行术语切分,确定第二组候选实体。
候选实体筛选单元36,用于根据第一组候选实体和第二组候选实体中各候选实体的末尾字符,对各候选实体进行筛选,分别形成第一组疾病类候选实体和第二组疾病类候选实体。
疾病类实体结果确定单元37,用于在第一组疾病类候选实体和第二组疾病类候选实体不相同时,根据预先设置的判断策略从第一组疾病类候选实体和第二组疾病类候选实体中确定疾病类实体结果。
具体的,如图4所示,所述疾病类实体结果确定单元37,包括:
术语切分判断模块371,用于确定待处理语句在进行术语切分时,是否通过预先设置的切分规则进行切分。
疾病类实体结果确定模块372,用于在待处理语句在进行术语切分时,通过预先设置的切分规则进行切分,则选择所述第二组疾病类候选实体中的候选实体作为疾病类实体结果;在待处理语句在进行术语切分时,未通过预先设置的切分规则进行切分,则选择所述第一组疾病类候选实体中的候选实体作为疾病类实体结果。
所述疾病类实体结果确定模块372,还可以确定来源于相同待处理语句的原始字符串的第一组疾病类候选实体和第二组疾病类候选实体中,实体个数少,且实体包含的字符数多的一组实体作为疾病类实体结果。
具体的,所述待处理语句获取单元31中的原始数据包括结构化数据、半结构化数据或非结构化数据;所述非结构化数据包括电子病历emr数据、电子健康档案ehr数据;所述结构化数据包括临床结算单数据、网络医疗知识库数据。
进一步的,如图4所示,所述实体标记序列确定单元33,包括:
crf统计特征值提取模块331,用于从预先设置的语料库中提取待处理语句中的每个文字的crf统计特征值;所述预先设置的语料库中记录有原始数据中各语句、各语句中的实体、以及各语句中的实体在各语句中的位置以及实体类别;所述crf统计特征值包括每个文字在各语句中的分词特征值、词性特征值、字符特征值、上下文特征值以及术语表特征值。
训练模型确定模块332,用于根据每个字在各语句中的crf统计特征值,确定一训练模型;所述训练模型为:
实体标记计算模块333,用于根据所述训练模型,计算待处理语句中的每个文字的实体标记yj。
实体标记序列确定模块334,用于将每个文字的实体标记进行组合,形成待处理语句的实体标记序列;其中,x表示所述待处理语句;yj表示待处理语句中j位置对应的文字的实体标记;fi(yj,yj-1,x)表示待处理语句中分词特征i的函数值;λi为模型参数;m表示分词特征的个数;n表示待处理语句中的文字位置个数;z(x)表示归一化因子;p(y|x)表示文字在待处理语句中的标记概率。
此外,所述第一组候选实体确定单元34,具体用于:
在实体标记序列中确定各文字对应的分词特征值,并根据所述分词特征值确定待处理语句的第一组候选实体。
进一步的,如图4所示,所述的面向多数据源的疾病类实体识别装置,还包括语料库更新单元38用于:
在所述待处理语句未在预先设置的语料库中被标注,根据公式:
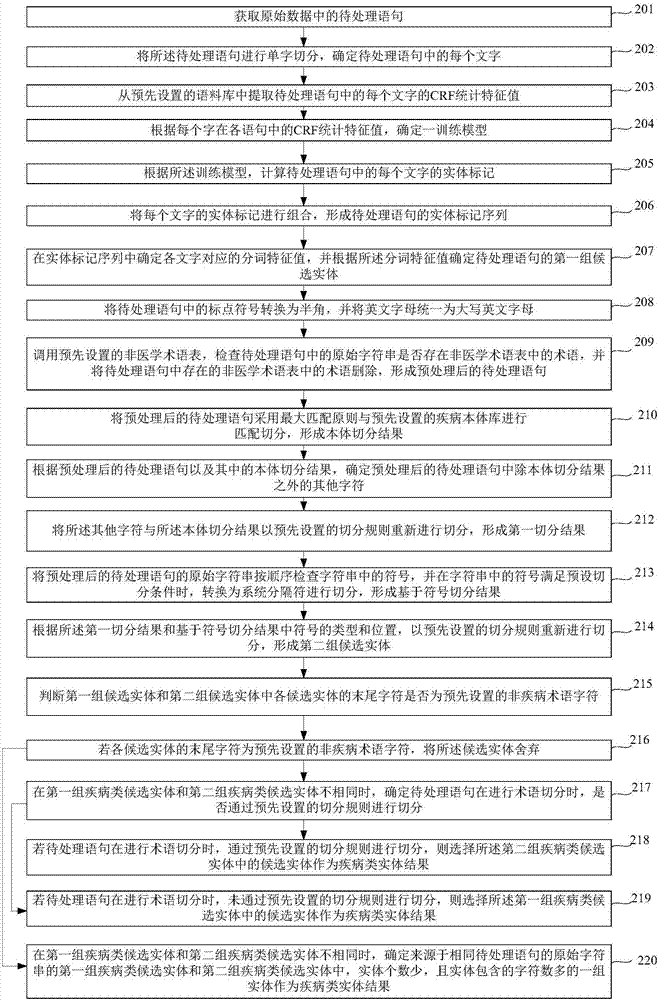
将待处理语句中不确定值为1的实体与预先设置的疾病本体库匹配,在匹配成功时,将匹配成功的实体的实体标记进行保存。
确定待处理语句的预测置信度和字典匹配标记的实体比例。
将预测置信度大于预设置信度阈值和字典匹配标记的实体比例大于预设比例阈值的待处理语句加入到所述语料库中,以进行语料库更新。
其中,所述预测置信度为待处理语句中各文字对应的标记概率的乘积。
所述字典匹配标记的实体比例为:
此外,如图4所示,所述第二组候选实体确定单元35,包括:
预处理模块351,用于将待处理语句中的标点符号转换为半角,并将英文字母统一为大写英文字母;调用预先设置的非医学术语表,检查待处理语句中的原始字符串是否存在非医学术语表中的术语,并将待处理语句中存在的非医学术语表中的术语删除,形成预处理后的待处理语句。
本体切分模块352,用于将预处理后的待处理语句采用最大匹配原则与预先设置的疾病本体库进行匹配切分,形成本体切分结果。
第一切分结果形成模块353,用于根据预处理后的待处理语句以及其中的本体切分结果,确定预处理后的待处理语句中除本体切分结果之外的其他字符;将所述其他字符与所述本体切分结果以预先设置的切分规则重新进行切分,形成第一切分结果。
符号切分模块354,用于将预处理后的待处理语句的原始字符串按顺序检查字符串中的符号,并在字符串中的符号满足预设切分条件时,转换为系统分隔符进行切分,形成基于符号切分结果。
第二组候选实体形成模块355,用于根据所述第一切分结果和基于符号切分结果中符号的类型和位置,以预先设置的切分规则重新进行切分,形成第二组候选实体。
此外,如图4所示,所述候选实体筛选单元36,包括:
非疾病术语字符判断模块361,用于判断第一组候选实体和第二组候选实体中各候选实体的末尾字符是否为预先设置的非疾病术语字符。
候选实体舍弃模块362,用于在各候选实体的末尾字符为预先设置的非疾病术语字符时,将所述候选实体舍弃。
值得说明的是,本发明实施例提供的一种面向多数据源的疾病类实体识别装置的具体实现方式可以参见上述的方法实施例,此处不再赘述。
本发明实施例提供的一种面向多数据源的疾病类实体识别装置,首先,获取原始数据中的待处理语句;将所述待处理语句进行单字切分,确定待处理语句中的每个文字;根据预先训练完成的crf训练模型,确定待处理语句中的每个文字在待处理语句中的实体标记,并确定待处理语句的实体标记序列;根据待处理语句的实体标记序列,确定待处理语句的第一组候选实体;然后,根据预先设置的疾病类术语切分策略,对所述待处理语句进行术语切分,确定第二组候选实体;根据第一组候选实体和第二组候选实体中各候选实体的末尾字符,对各候选实体进行筛选,分别形成第一组疾病类候选实体和第二组疾病类候选实体;若第一组疾病类候选实体和第二组疾病类候选实体不相同,根据预先设置的判断策略从第一组疾病类候选实体和第二组疾病类候选实体中确定疾病类实体结果。本发明将条件随机场crf统计机器学习方法与术语切分方法相结合,能够自动识别疾病类实体,克服了当前的实体识别的数据源较为单一,实体识别不准确的问题。
本领域内的技术人员应明白,本发明的实施例可提供为方法、系统、或计算机程序产品。因此,本发明可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本发明可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本发明是参照根据本发明实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
本发明中应用了具体实施例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均会有改变之处,综上所述,本说明书内容不应理解为对本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!