基于卷积神经网络的智能化先导化合物发现方法与流程
本发明涉及先导化合物发现的方法,属于以先导化合物发现为目标的人工智能应用技术领域,目的是高效、智能地发现小分子先导化合物。
背景技术:
基于相似性的活性化合物发现策略在药物设计中具有重要的地位,包括了生物电子等排体策略、骨架跃迁策略等等,但这两种方法均在很大程度上依赖于药物研发人员长期积累的经验。而人工智能通过深度学习,能快速、准确地总结出规律,这一过程得以加快药物的发现过程。尤其是借助计算机的高速运算及大存储量这两个人类不具有的优势,人工智能得以快速、准确地识别活性分子,找出活性与结构之间的关系。
活性分子相似性的发现,需要借助图像识别这一技术。卷积神经网络则是实现智能读图的重要技术之一。通过建立卷积神经网络结构,并提供已知特性的图像供该网络结构训练。拟合出对应于该特性的系列参数,最终达到该网络能准确分类该特性的目的。
目前,我国的新药开发正在朝着全新的创新药物方向发展,而新药开发过程中先导化合物的发现是关键的一步,虽然先导化合物并非药物,却是药物之母。面对着难以计数的全新化学实体,如果一一进行活性测试将花费极其巨大的人力物力及财力。因此,借助于人工智能卷积神经网络将加快药物先导化合物的发现,是新药研发的有效辅助手段。
技术实现要素:
本发明的目的是提供一种基于化合物化学结构式的智能识别系统,一种活性先导化合物发现方法。用于解决当前先导化合物发现效率低、方法有限的问题。该方法通过卷积神经网络,对具有各类不同活性属性的化合物结构式图像的学习,拟合出准确分类的矩阵参数,并将参数用于未知活性属性的化合物的预测。本发明可提高先导化合物发现效率,为先导化合物发现带来一种全新的方法。
为解决上述传统药物发现方法的相关问题,本发明提出的技术方案为一种基于卷积神经网络的智能先导化合物发现方法,具体包括如下步骤:
步骤1:对大小、亮度均一致的化合物结构式平面图片进行黑白化及反色处理;
步骤2:根据化合物活性属性进行分类,并对每一类图片加以各类所对应的数字标签,其中一部分图片作为训练集,剩余部分图片作为测试集;
步骤3:将图片根据像素值转变为数字矩阵,与标签数字一一对应;
步骤4:建立卷积神经网络分类器,并调整参数;
步骤5:当评价模型的损失函数逼近0后,完成训练,获得训练后的矩阵参数;
步骤6:以步骤5获得的矩阵计算测试集图片,并对模型进行评估。若评估结果不合要求,扩充数据集,重复上述过程,至符合要求;
步骤7:若评估结果符合要求,步骤5所获得的矩阵参数可对未知活性的化合物进行预测,以发现先导化合物。
进一步,上述步骤2中所述活性属性包括定性的活性属性以及定量的活性属性。
进一步,上述步骤4中所述卷积神经网络的分类器包含以下步骤:
(1)整理数据集。
(2)建立卷积神经网络,具体又包含以下子步骤:
A.确定层数及结构;
B.确定卷积与池化方式;
C.选择损失函数;
D.选择非线性化函数。
(3)开始训练神经网络,具体又包含以下子步骤:
A.初始化矩阵数据;
B.设置每批训练图片的数量;
C.设置训练次数。
进一步,上述步骤4中参数包括以下内容:
(1)层数及节点数;
(2)卷积核大小与采样方式;
(3)池化层矩阵大小与采样方式;
(4)损失函数种类;
(5)非线性化函数种类;
(6)每批训练图片的数量;
(7)训练次数。
进一步,上述步骤5中所述的逼近为损失函数值小于1同时大于0。
进一步,上述步骤6中评估方法包括计算模型预测全部图片以及各类别图片的正确率、错误率,模型针对某分类属性的特异性以及灵敏度。
与传统的先导化合物虚拟发现工具相比,本发明的突出效果在于:
1、受体的结构、受体与配体或药物的结合位点、活性分子的药效构象不再是必要的,更不需要理论计算化学严格、精确的算法;
2、预测速度明显快于传统的先导化合物筛选工具;
3、传统筛选模型多为线性模型,本筛选方法为非线性模型。
附图说明
图1是本发明的方法流程图。
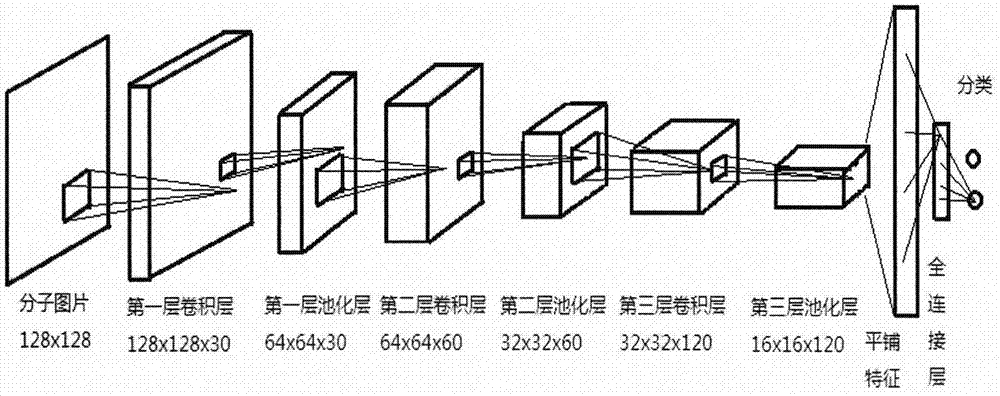
图2是卷积神经网络的结构图。
图3是依照本发明创建的模型的收敛情况。
具体实施方式
现结合附图对本发明的具体实施方式做进一步详细的说明。本发明提出一种基于卷积神经网络的智能化先导化合物发现方法。首先通过建立初步的卷积神经网络结构对训练集中经处理的图片进行深度学习,根据训练情况调整结构中参数,训练完成后保存矩阵数据。以此矩阵数据计算测试集,评价模型的正确率,结果符合要求后,将矩阵数据用于未知化合物的活性预测。若不合要求则通过扩大数据集重复上述过程,见图1。
方法流程:
基于卷积神经网络的智能化先导化合物发现方法的细化步骤如下:
以具有抗肿瘤作用的CDK4抑制剂作为本方法的实施例,数据集中分子图片具有两类属性,一类具有CDK4抑制活性,另一类则不具有。
步骤1:
将具有抗肿瘤活性的241个CDK4抑制剂作为活性化合物,223个不具有抗肿瘤活性的化合物作为非活性化合物。其结构式制做为128×128像素图片,并进行黑白化和反色处理。
步骤2:
对所有图片分类并加以类别数字标签,具有CDK4抑制活性的化合物图片以1为标签,不具有CDK4抑制作用的化合物图片以0作为标签。所有图片随机分为训练集与测试集。训练集与测试集各含图片232张,其中训练集有118张图片属于活性化合物。
步骤3:
将图片由像素值转变为数字矩阵,并与将活性标签一一对应。
步骤4:
如图2所示,建立并调整卷积神经网络分类器,包括如下步骤:
1、数据集的准备:
图片矩阵经整合后为一464×1282的矩阵,第一维为图片索引,第二维为具体的图片像素值数据。标签矩阵为464×1的矩阵,第一维为索引,第二维为数字标签。最后将图片矩阵重整为464×128×128×1。
2、建立卷积神经网络,具体包含以下子步骤:
A.确定层数及结构卷积神经网络整体架构,以一层卷积层加一层池化层为一组,共三组,后为一层全连接层,最后通过一个含有2个输出节点的softmax层输出。详细如下:
a.卷积层及池化层:第一层卷积层具有1个输入节点、30个输出节点,第二层卷积层含30个输入节点、60个输出节点,第三层卷积层含60个输入节点、120个输出节点。其中,每一层卷积层在经非线性化函数处理后均连有池化层,而最后一层池化层的输出作为下一层的输入。非线性化采用relu函数进行处理,relu(x)=max(0,x)。经上述处理后,数据具有三个维度。三维数据需要被重构后输入全连接层。
b.数据重构:由于全连接层对应于线性化的输入数据,故须将输入的三维矩阵进行重构。重构的矩阵为n行一列的二维矩阵,n值为经卷积层与池化层处理后,三维矩阵的各维大小的乘积。重构矩阵的每一行作为全连接层的每一输入节点。
c.全连接层:全连接层为一层,其输入节点数即为重构二维矩阵的行数,输出节点有200个,经relu函数进行非线性化处理后作为softmax层的输入节点。
d.softmax层:softmax层的输出个数为2,对应于标签0及1的概率分布。即最后的softmax层采用softmax函数将输出结果分为两类标签的概率值,是一个二行一列的矩阵。Xi为某一标签对应的计算值,Xj为任一标签的计算值。获取最大概率值在矩阵行数中的索引,即为图片经模型预测后得到的分类标签。预测的标签与真实结果比较后,计算损失函数用于模型评价。
B.确定卷积与池化方式:采用5×5的卷积核,移动步长为1,采用拓展至图片边缘外的采样方式,以max pooling方式在2×2的区域采样。输入的1×128×128×1的图片矩阵,经上述三组卷积层与池化层处理后,矩阵形状依次变为64×64×30、32×32×60、16×16×120。
C.选择损失函数:采用交叉熵函数(cross entropy),cross entropy=-∑y×lg(y′),y为真实的概率分布,y’为预测的概率分布。函数值越逼近0,表明训练越有效。
3、开始训练神经网络,具体又包含以下子步骤:
A.初始化矩阵数据:权重矩阵以随机的正态分布数据构建,偏置矩阵定义为一个内容均为0.1的常数矩阵。
B.优化器的选择:采用Adam随机优化算法对先前的权重矩阵中得数据进行调整,权重衰减为0.0001。
C.设置每批训练图片的数量:每批输入训练集中的160张图片,依次循环。
D.设置训练次数:设置为300步。
步骤5:
当评价模型的损失函数逼近0,同时300步后,完成训练,获得训练后的矩阵参数。本实例的收敛情况如图3。
步骤6:
以获得的矩阵计算测试集,并进行评估。通过读取softmax层概率最大的值索引,获得预测的概率分布。经与真实标签值比较,输出一致为1,不一致为0。应用于本实例,测试集中有105个非活性分子和127个活性分子性,其总正确率为86.2%,其中活性分子的正确率为87.4%,非活性分子的正确率为84.76%。模型的特异性(SP)与灵敏度(SE)反映筛选的重要指标,SE=TP/(TP+FN)、SP=TN/(TN+FP)TP为预测正确活性化合物,FP为预测错误活性化合物,TN为预测正确非活性化合物,FN为预测错误非活性化合物。实例中,特异性为84.8%,灵敏度为87.4%。
步骤7:
获得的矩阵数据对未知活性化合物进行预测,经过softmax层后即可得到未知化合物的概率值。实例中,对11个已上市药物非抗肿瘤药物进行预测,其中结果见下表。其中药物1和2经模型预测,可能具有CDK4抑制活性,有成为抗肿瘤药物潜质,值得进行后续开发研究。
- 还没有人留言评论。精彩留言会获得点赞!