一种基于验证转换图像生成网络的三维视图合成方法与流程
本发明涉及三维图像重建领域,尤其是涉及了一种基于验证转换图像生成网络的三维视图合成方法。
背景技术:
三维图像的重建一直是计算机领域关注的重点,人们欲通过二维图像来完成对三维世界的认知。三维重建的技术,其低成本、易操作、重建的三维模型真实感强等特点,已经逐渐成为研究的热点,尤其在计算机视觉、图形图像学的理论研究领域和医学图像重构、机器人视觉等工程领域,都具有较高的研究价值。此外,三维图像的重建还可以应用在无人导航系统、人体手术辅助系统和远程视觉触摸系统等,甚至在移动设备领域中社交、购物及娱乐方面有着极大的发展潜力,诸如vr产业等新兴经济领域的振兴与该技术密不可分。
根据单幅平面图像对其进行三维视图的转换,重建非连通区域的隐蔽内容,如何准确重现仍然是一个具有挑战性的问题。由于涉及图像的比例缩放、光照条件、纹理特征等诸多因素,三维图像的重建不仅需要利用空间几何知识、内容补偿等,还需要调整合理需求,分辨重建内容的真伪,这对单纯的图像还原造成较高难度。
本发明提出了一种基于深度学习损失函数的新框架。使用rgb-d数据进行训练与测试图像的生成,然后将输入图像与输入图像进行像素匹配与转移,使用非连通域表面流体网络猜测与生成隐蔽区域内容,再使用深度学习网络计算损失函数从而控制内容的修补。本发明可以有效处理三维图像的合成,尤其体现出给定图像经过一定旋转角度后原有非联通隐蔽区域的复原能力,有效提高图像重建过程中的控制能力与精确性。
技术实现要素:
针对解决在三维图像重建中隐蔽区域还原的问题,本发明的目的在于提供一种基于验证转换图像生成网络的三维视图合成方法,提出了一种基于深度学习损失函数的新框架。
为解决上述问题,本发明提供一种基于验证转换图像生成网络的三维视图合成方法,其主要内容包括:
(一)图像集合生成;
(二)非连通域表面流体网络;
(三)视图填补网络。
其中,所述的数据输入,使用rgb-d数据进行图像集合的生成与训练测试;
(1)rgb-d:该数据库广泛用于三维图像模型训练,使用其中数据集中汽车类别模型7497个、椅子类别模型698个,均具有充分的纹理特征;
(2)对所有模型图像进行渲染,根据标高0、10、20和三维转换角度0到340度(间隔20度)生成共54种视图;
(3)所有经过渲染的模型图像,五分之四用作训练,另外五分之一用作测试。
进一步地,所述的非连通域表面流体网络,包括表面流体网络定义、可视化映射、已知对称性可视化映射和背景虚化。
进一步地,所述的表面流体网络定义,基于特殊的图像采样层来学习如何从输入源图像is移动所需像素点到目标图像it:
其中f使用深度卷积编码解码网络的流体预测函数,
进一步地,所述的可视化映射,给定源图像is和目标三维图像的转换角度θ,对于目标图像it中某个像素位置(i,j)的可视化映射值mvis定义为:
其中,
由公式(2),首先由像素坐标得到三维目标的坐标,然后根据给定转换角度θ得到视角投影可得,当且仅当视图向量与表面均值的点积为正值的时候,可视化映射值mvis等于1。
进一步地,所述的已知对称性可视化映射,对于在x,y平面上对称的物体,它的已知对称性可视化映射msym可由公式(2)经过z字形翻转得到,具体地,目标图像it中某个像素位置(i,j)的最终可视化映射值mvis定义为:
其中
进一步地,所述的背景虚化,将源图像is和目标图像it中都出现的物体定义为前景,剩余不变的像素定义为背景,源图像和目标图像的背景用bs和bt表示,则二者统一化背景虚化为:
则由公式(1)(2)(3)(4)可得,输入图像is经过非连通域表面流体网络后得到中间结果idoafn:
idoafn=is⊙mbg+it⊙ms-vis(5)
其中⊙表示点积运算。
进一步地,所述的视图填补网络,包括想象填补和深度学习修复。
进一步地,所述的想象填补,在网络的各层之间使用跳跃桥接的方法合并局部信息与全局信息;
(1)中间结果产生前,保留高阶信息的条件下,网络生成与输入源图像is有持续特征的内容,尤其在非连通域个体面积较大的物体;
(2)中间结果产生时,网络保留得到期望角度的视图和其诸如颜色及纹理等低阶信息;
(3)中间结果产生后,网络不止填补非连通遮掩区域,还对填补的人工痕迹进行修补。
进一步地,所述的深度学习修复,搭建16层深度卷积网络,计算特征重建的损失值,以控制视图填补的程度;
(1)深度学习网络中的视觉损失及对抗学习损失是互补的,因此增加总偏差均一化项去微调图像,其定义为:
-logd(g(is))+αl2(fd(g(is)),fd(g(it)))+βl2(fvgg(g(is)),fvgg(g(it)))+γl1(is,it)
+λltv(g(is))(6)
其中,is是输入图像,g(is)是生成图像,it是目标图像,log(d)是用对抗训练损失网络估计生成图像g(is)真实性的概率,d称作为分类器;
(2)公式(6)中fd和fvgg是用分类器和16层深度网络提取的特征,在第一层和第三层提出的特征合并起来作为分类特征效果最为明显;
(3)生成图像g(is)和真实图像it输入d分类器和16层深度网络计算损失值,提取各自生成的特征,计算这两类特征的平均欧几里得距离;
(4)d分类器的损失函数定义为:
-logd(is)-log(1-d(g(is)))(7)
(5)根据实验,公式(6)中的参数值分别设置为α=100,β=0.001,γ=1,λ=0.0001。
附图说明
图1是本发明一种基于验证转换图像生成网络的三维视图合成方法的系统流程图。
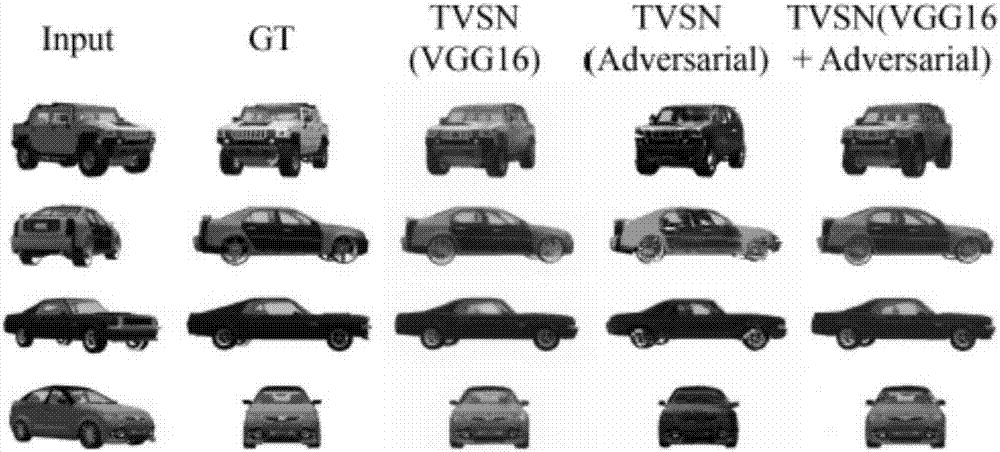
图2是本发明一种基于验证转换图像生成网络的三维视图合成方法的中间过程结果的比较图。
具体实施方式
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互结合,下面结合附图和具体实施例对本发明作进一步详细说明。
图1是本发明一种基于验证转换图像生成网络的三维视图合成方法的系统流程图。主要包括图像集合生成;非连通域表面流体网络;视图填补网络。
其中,使用rgb-d数据进行图像集合的生成与训练测试;
(1)rgb-d:该数据库广泛用于三维图像模型训练,使用其中数据集中汽车类别模型7497个、椅子类别模型698个,均具有充分的纹理特征;
(2)对所有模型图像进行渲染,根据标高0、10、20和三维转换角度0到340度(间隔20度)生成共54种视图;
(3)所有经过渲染的模型图像,五分之四用作训练,另外五分之一用作测试。
非连通域表面流体网络,包括表面流体网络定义、可视化映射、已知对称性可视化映射和背景虚化。
表面流体网络定义,基于特殊的图像采样层来学习如何从输入源图像is移动所需像素点到目标图像it:
其中f使用深度卷积编码解码网络的流体预测函数,
可视化映射,给定源图像is和目标三维图像的转换角度θ,对于目标图像it中某个像素位置(i,j)的可视化映射值mvis定义为:
其中,
由公式(2),首先由像素坐标得到三维目标的坐标,然后根据给定转换角度θ得到视角投影可得,当且仅当视图向量与表面均值的点积为正值的时候,可视化映射值mvis等于1。
已知对称性可视化映射,对于在x,y平面上对称的物体,它的已知对称性可视化映射msym可由公式(2)经过z字形翻转得到,具体地,目标图像it中某个像素位置(i,j)的最终可视化映射值mvis定义为:
其中
背景虚化,将源图像is和目标图像it中都出现的物体定义为前景,剩余不变的像素定义为背景,源图像和目标图像的背景用bs和bt表示,则二者统一化背景虚化为:
则由公式(1)(2)(3)(4)可得,输入图像is经过非连通域表面流体网络后得到中间结果idoafn:
idoafn=is⊙mbg+it⊙ms-vis(5)
其中⊙表示点积运算。
视图填补网络,包括想象填补和深度学习修复。
想象填补,在网络的各层之间使用跳跃桥接的方法合并局部信息与全局信息;
(1)中间结果产生前,保留高阶信息的条件下,网络生成与输入源图像is有持续特征的内容,尤其在非连通域个体面积较大的物体;
(2)中间结果产生时,网络保留得到期望角度的视图和其诸如颜色及纹理等低阶信息;
(3)中间结果产生后,网络不止填补非连通遮掩区域,还对填补的人工痕迹进行修补。
深度学习修复,搭建16层深度卷积网络,计算特征重建的损失值,以控制视图填补的程度;
(1)深度学习网络中的视觉损失及对抗学习损失是互补的,因此增加总偏差均一化项去微调图像,其定义为:
-logd(g(is))+αl2(fd(g(is)),fd(g(it)))+βl2(fvgg(g(is)),fvgg(g(it)))+γl1(is,it)
+λitv(g(is))(6)
其中,is是输入图像,g(is)是生成图像,it是目标图像,log(d)是用对抗训练损失网络估计生成图像g(is)真实性的概率,d称作为分类器;
(2)公式(6)中fd和fvgg是用分类器和16层深度网络提取的特征,在第一层和第三层提出的特征合并起来作为分类特征效果最为明显;
(3)生成图像g(is)和真实图像it输入d分类器和16层深度网络计算损失值,提取各自生成的特征,计算这两类特征的平均欧几里得距离;
(4)d分类器的损失函数定义为:
-logd(is)-log(1-d(g(is)))(7)
(5)根据实验,公式(6)中的参数值分别设置为α=100,β=0.001,γ=1,λ=0.0001。
图2本发明一种基于验证转换图像生成网络的三维视图合成方法的中间过程结果的比较图。如图所示,从上至下分别是四辆不同车辆的实验结果,从左至右分别是每辆车辆的输入图像、转换图像、单纯16层网络结果、单纯对抗网络结果,16层网络加对抗网络结果,可以观察到最后一列即合成方法的效果最好,纹理特征最接近验证结果,即第二列。
对于本领域技术人员,本发明不限制于上述实施例的细节,在不背离本发明的精神和范围的情况下,能够以其他具体形式实现本发明。此外,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围,这些改进和变型也应视为本发明的保护范围。因此,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
- 还没有人留言评论。精彩留言会获得点赞!