基于受限结构图搜索的目标跟踪方法与流程
本发明涉及一种目标跟踪方法,具体涉及一种基于受限结构图搜索的目标跟踪方法,属于计算机技术领域。
背景技术:
目标跟踪方法是计算机视觉领域的重要研究课题之一。精确的目标跟踪能为视频数据的进一步分析提供可靠的基础,所以广泛应用于自动驾驶、视频监控、无人机和人机交互等重要场合。虽然目标跟踪已经取得较大发展,但是仍然面临着诸多挑战制约其性能的提高,比如目标的几何形变、部分遮挡和背景杂乱等。
目前,绝大多数目标跟踪算法按照目标表示方法分类,可以分为基于目标整体框模型的跟踪算法和基于目标部件模型的跟踪算法。其中,前者采用一个矩形框表示目标,强调对目标整体的表象学习,该方法对光照变化、背景杂乱等情况鲁棒,但是在因形变、遮挡或者尺度变化引起的表象剧烈变化时容易跟踪失败,后者采用目标部件(像素、超像素或矩形部件等)的集合表示目标,主要学习其局部结构信息,因为单个目标部件鉴别力低,通常需要建立目标结构图来考虑部件之间的结构信息,将目标跟踪问题转化为图匹配问题。
基于图模型的跟踪算法通常包含以下三个顺序模块:目标部件选择、目标部件匹配和目标状态估计。其中,目标部件选择是指使用表象模型从背景中区分出候选目标部件,目标部件匹配是指根据表象和结构相似性来关联相邻两帧的部件,目标状态估计是指根据匹配结果估计出目标状态(目标中心位置和目标尺度)。
但是这样的顺序机制并不足以实现在复杂场景下的鲁棒跟踪。
首先,目标部件选择和后续两个模块相对独立,使得不精确的表象模型会直接对匹配结果造成负面影响,进而造成跟踪失败。
其次,它们并没有考虑全局限制,使其在杂乱背景下对背景噪声比较敏感。
进一步的,该机制不足以反映这三个模块的真实关系:
(1)连续两帧的部件匹配能为当前帧的部件选择提供补充信息,反之亦然;
(2)部件选择和匹配提取了局部表象变化,有助于整体目标状态估计;
(3)估计的目标状态反过来能为部件选择和匹配提供一个整体约束,取得更高精度。
如果能同时考虑三个模块之间的相互支持和促进关系,将有助于建立更加精确的跟踪模型。而先前的工作并没有考虑这些问题。
技术实现要素:
为解决现有基于图模型的跟踪算法局限于局部表象建模,而不能同时考虑各模块相互支持促进的不足,本发明的目的在于提供一种基于受限结构图搜索的目标跟踪方法。
为了实现上述目标,本发明采用如下的技术方案:
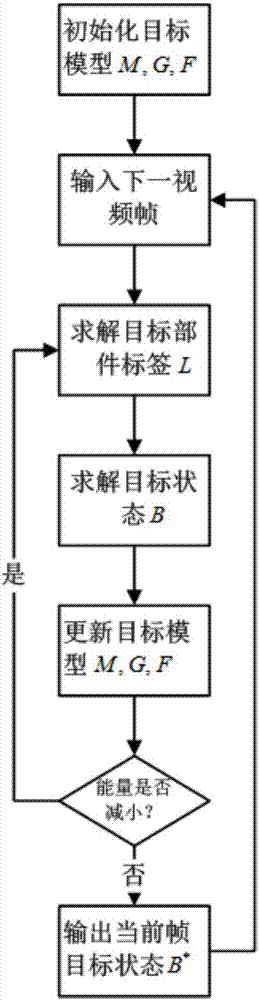
基于受限结构图搜索的目标跟踪方法,其特征在于,包括以下步骤:
s0、初始化目标模型
根据第一帧标定的目标状态,得到目标尺度两倍大小的目标搜索区域r,然后将该目标搜索区域r过分割为一系列颜色相似像素的超像素
s1、输入下一视频帧
根据上一帧的目标状态b,确定当前帧的目标搜索区域,在目标中心位置的两倍当前目标尺度搜索,然后将该目标搜索区域过分割为一系列超像素;
s2、求解目标部件标签
给定目标模型m,g,f和目标状态b,则能量最小化函数可表示为:
其中,eps和epm分别表示目标部件选择的能量、目标部件匹配的能量,
然后使用图割算法求解得到目标部件标签l;
s3、求解目标状态
得到目标部件标签l以后,联合相关滤波器模型f求解目标状态b;
s4、更新目标模型
根据求解得到的目标部件标签l和目标状态b更新目标模型m,g,f,如下式所示:
其中,eda表示超像素部件p属于前景或者背景的概率,epm表示目标部件匹配的能量,f(b,r)表示搜索区域r中任意目标状态b对应的响应分数,λ1为平衡两项的系数;
各项相互独立,可以分别更新各个模型,通过目标部件标签l和目标状态b得到训练样本,学习新的目标模型m,g,f;
s5、输出当前帧目标状态
在步骤s4中,如果能量减小,则接受模型更新,转到步骤s2继续迭代优化;否则,退出迭代循环,输出当前帧最优的目标状态,转到步骤s1。
前述的基于受限结构图搜索的目标跟踪方法,其特征在于,在步骤s0中,将目标搜索区域r过分割为一系列颜色相似像素的超像素
前述的基于受限结构图搜索的目标跟踪方法,其特征在于,在步骤s3中,求解目标状态b的方法为:
(1)使用采样方法得到一系列候选目标状态;
(2)基于上一帧目标尺度选择当前帧的目标中心位置;
(3)选出使目标函数能量最小的目标尺度。
本发明的有益之处在于:
(1)相比于之前基于结构图模型的目标跟踪算法相对独立考虑各模块的促进作用,本发明将基于图模型的跟踪算法的顺序组织的模块在能量最小化框架中统一考虑,能更好挖掘各模块之间的相互支持关系,使它们相互约束和促进,提升跟踪效果;
(2)本发明采用基于轮换迭代的优化方法,将原始的多变量优化问题分解为多个较易处理的能量最小化子问题来逐一求解,使得学习到的目标结构图模型在全局目标表象约束下更好地表示目标结构的局部变化,提高了目标跟踪精度。
附图说明
图1是本发明的基于受限结构图搜索的目标跟踪示意图;
图2是本发明的基于受限结构图搜索的目标跟踪方法流程图。
具体实施方式
以下结合附图和具体实施例对本发明作具体的介绍。
参照图1和图2,本发明的基于受限结构图搜索的目标跟踪方法包括以下步骤:
s0、初始化目标模型
根据第一帧标定的目标状态,得到目标尺度两倍大小的目标搜索区域r,然后使用simplelineariterativeclustering算法(slic算法)将该目标搜索区域r过分割为一系列颜色相似像素的超像素
收集在目标框内的超像素为正样本,目标框外的超像素为负样本,这样学习一个线性支持向量机模型作为表象模型m以及相关滤波器模型f作为整体约束,另外,建立目标结构图模型g={v,c},其中v表示目标部件集合,c表示临近目标部件集合关系组成的边的集合。
s1、输入下一视频帧
根据上一帧的目标状态b,确定当前帧的目标搜索区域,即在目标中心位置的两倍当前目标尺度搜索,然后将该目标搜索区域过分割为一系列超像素。
s2、求解目标部件标签
对于目标部件选择,其目标为借助于表象模型m从背景(记作f0)中选择出目标部件
终上所述,本发明建立的能量最小化模型如下式所示:
其中,eps、epm和ese分别表示目标部件选择的能量、目标部件匹配的能量和目标状态估计的能量,λse为平衡系数。
各项具体定义如下:
(1)目标部件选择的能量eps的定义为:
其中,eda表征超像素部件属于前景或者背景的概率,esm确保了标签标记的连续性,λb为平衡系数。
(2)目标部件匹配的能量epm的定义为:
其中,eap衡量超像素部件对结构图模型g中目标部件的相似性,ege衡量目标部件的局部结构的相似性,λb为平衡系数。
(3)目标状态估计的能量ese的定义为:
其中,f(b,r)表示搜索区域r中任意目标状态b对应的响应分数,而
在给定了目标模型m,g,f和目标状态b之后,本发明的能量最小化模型可以重新表示为:
由于上述能量最小化模型包含了多类变量,很难同时优化,所以本发明采用轮换迭代的优化方式将优化过程分为三个阶段:
(1)固定目标模型m,g,f和目标状态b,求解目标部件标签l;
(2)固定目标模型m,g,f和目标部件标签l,求解目标状态b;
(3)固定目标状态b和目标部件标签l,更新目标模型m,g,f。
如此三个阶段交替进行,直到总能量不再降低而退出迭代循环,最后计算得到当前帧最优的目标状态b*(如图1所示)。
在求解目标部件标签l这一步中,我们执行的是上述优化过程的第一个阶段,即固定目标模型m,g,f和目标状态b,求解目标部件标签l,并具体使用图割算法求解得到目标部件标签l。
s3、求解目标状态
在求解目标状态b这一步中,我们执行的是上述优化过程的第二个阶段,即得到目标部件标签l以后,联合相关滤波器模型f,求解目标状态b。具体地,采样一系列候选目标状态中选择出最小能量的状态,以满足目标公式
求解目标状态b的方法具体为:
(1)使用采样方法得到一系列候选目标状态;
(2)基于上一帧目标尺度选择当前帧的目标中心位置;
(3)选出使目标函数能量最小的目标尺度。
s4、更新目标模型
在更新目标模型m,g,f这一步中,我们执行的是上述优化过程的第三个阶段,即为了适应目标在运动过程中的表象变化,根据求解得到的目标部件标签l和目标状态b,更新目标模型m,g,f,如下式所示:
其中,eda表示超像素部件p属于前景或者背景的概率,epm表示目标部件匹配的能量,f(b,r)表示搜索区域r中任意目标状态b对应的响应分数,λ1为平衡两项的系数。
各项相互独立,可以分别更新各个模型,具体地,通过目标部件标签l和目标状态b得到训练样本,学习新的目标模型m,g,f。
s5、输出当前帧目标状态
在步骤s4中,如果能量减小,则接受模型更新,转到步骤s2继续迭代优化;如果能量不再降低,则退出迭代循环,输出当前帧最优的目标状态b*,转到步骤s1。
综上所述,本发明通过建立一个统一的能量最小化模型,将基于图模型的目标跟踪算法的各模块集成到了一起,不仅同时考虑到了算法各模块的促进作用,而且还挖掘了其相互支持的关系,最终使得跟踪效果得到了进一步提高。
此外,针对该能量最小化模型,本发明采用轮换迭代的优化方法对各变量进行求解,基于能量逐渐减小的迭代过程,可以在全局目标表象的约束下搜索得到更加可靠的目标结构图模型用以表达目标部件的表象和结构。
需要说明的是,上述实施例不以任何形式限制本发明,凡采用等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!