一种基于用户问题预测模型的减小线上客户流失的方法与流程
本发明涉及数据处理技术领域,尤其涉及一种基于用户问题预测模型的减小线上客户流失的方法。
背景技术:
随着银行互联网业务的发展,线上客户的流失率越来越被看中,为实现用户的留存,需要分析出客户的流失原因,找到用户的问题所在才能作出改进。通过现状分析发现,如果仅根据人为经验通过页面文案对客户进行引导,当用户已经进入到银行界面后,没有一套工具能够根据用户行为、用户信息等数据实时预测出客户可能在操作过程中所遇见的问题的模型,部分用户在操作中没有及时发现其面临的问题,用户离开页面会直接造成客户的流失,比如在用户注册页面流失率高达97%,用户登录页务失率为94%。客户流失率高,且客户挽回成本高,目前只能线下统计流失客户,进行事后挽回,也只能在客户提出问题后才能知道客户的问题,挽回成本巨大且收效甚微,处理起来十分被动。而通过模型计算出客户在实时操作的过程中可能会遇见的问题,并通过系统实时采集数据,并实时进行运算,实时对前后端发起对应挽回策略,能够有效的留住客户,并且提升用户体验。
本文需要用到的一些专业术语的解释如下:
cnn卷积神经网络:cnn是一种多层神经网络,基于人工神经网络,在人工神经网络前,用滤波器进行特征抽取,使用卷积核作为特征抽取器,自动训练特征抽取器,就是说卷积核以及阈值参数这些都需要由网络去学习。
余弦相似度模型:余弦相似度,又称为余弦相似性。通过计算两个向量的夹角余弦值来评估他们的相似度。
问题预测模型:根据客户行为、浏览轨迹、历史数据等等多数据抽取特征,训练权重,预测客户可能会遇见的问题,后传给后方进行对应的措施。
技术实现要素:
本发明的目的如下:解决现有的互联网银行没有一套工具能够根据用户行为、用户信息数据实时预测出客户可能在操作过程中所遇见的问题的模型,也没有根据此模型的减小线上客户流失的方法,导致客户流失且挽回成本大收效甚微,处理起来十分被动的问题。本发明提供一种基于用户问题预测模型的减小线上客户流失的方法。
本发明的技术方案如下:
一种基于用户问题预测模型的减小线上客户流失的方法,包括如下步骤:
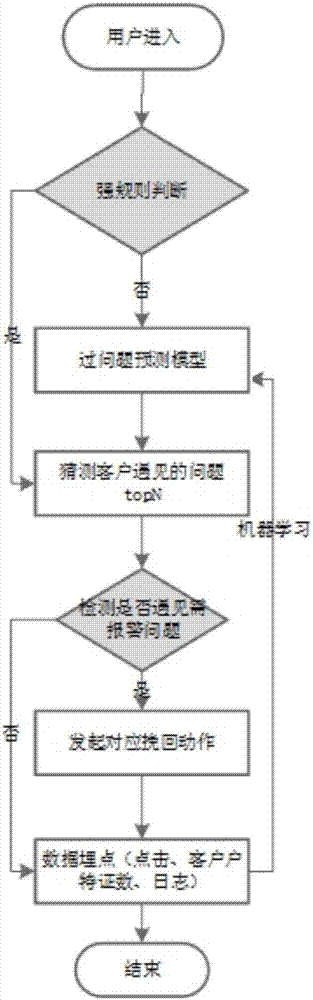
s1:用户进入互联网银行页面;
s2:判断用户身上是否带有强规则,如命中强规则,则走强规则逻辑,再猜测客户可能遇见的问题topn;如没有命中强规则,则进入问题预测模型,猜测客户可能遇见的问题topn;强规则是由业务人员确定的,比如黑名单客户、白名单用户、vip用户等,规则如概括性解释可说:强规则由业务人员确定,在模型之上,属于必需判断的强因子。
s3:检测topn的问题中是否有需要报警的问题,如果有,则对客户发起对应挽回动作,再进行数据埋点;若没有需要报警的问题,则直接进行数据埋点;埋点数据将通过机器学习的方式反馈给问题预测模型中,进行问题预测模型调优处理;
s4:将判断失误的样本作为负样本,判断正确的样本作为正样本,将样本数据通过机器学习的方式反馈只问题预测模型进行调优处理;
s5:结束。
具体地,所述强规则模型通过专家模型和人为经验得到。
具体地,s2中,问题预测模型的步骤为:
s21:样本数据采集;
s22:将样本数据分为正样本数据和负样本数据,用户在实际环境中遇到的问题和银行匹配的问题一致为正样本,用户在实际环境中遇到的问题和银行匹配的问题不一致则为负样本;
s23:通过cnn卷积神经网络算法,提取正样本数据和负样本数据中的有效特征,命中的正样本分类特征的用户特征,称之为有效特征;找出流失用户样本数据中所携带的信息数据及行为特征;
s24:权重训练,找出对应有效特征分类权重;
s25:产出模型文件;根据权重训练得出的结果,再根据预测概率进行排序,取靠前的用户问题作为用户可能遇见问题的预测结果topn;在产出模型文件后,模型文件在实际的模型应用中又会生产新的正样本和负样本,对新的在正样本和负样本通过机器学习的方式反馈到权重训练中。
具体地,s24中,权重训练的方法为svm分类预测方法,具体步骤如下:
s241:按照用户浏览时间维度、用户操作维度提取行为、操作历史数据;行为、操作历史数据包括页面pv、用户点击、用户填写、用户信息等历史数据;
s242:清洗行为、操作历史数据,提取转换特征;具体地,将用户浏览时间维度分为多个区间,每个区间内每一个维度的数据划分为多个区间;比如pv这个维度在页面category1下会形成以下特征;
s243:将转换特征向量化;根据步骤2提取的特征与特征的索引,将每一个用户用特征向量表示为:f=(f1,f2,f3,..,fn)
其中fi取值为0或则1,向量的维度表示特征的索引;
具体地,s24中,权重训练是通过余弦相似度算法实现的,具体步骤为:
s241:提取样本数据,基于统计计算出用户行为特征,用户操作特征偏好,计算公式如下:
s242:将用户每一个特征偏好组合表示为特征偏好向量:
v1=(p1,p2,p3,...,pn)
s243:将用户问题特征表示为向量:
v2=(1,0,1,...,0)
用户问题的的特征向量维度值取值为0或者1;
s244:计算余弦相似度:
其中simi值越大表示越相似;
s245:执行排序;根据simi值进行排序,取最相似的一部分用户判定用户的问题,并跟进权重排序。
进一步地,s2中,样本数据包括用户的基本信息、用户操作行为、用户服务历史轨迹、用户信用信息、页面日志数据。
采用上述方案后,本发明的有益效果在于:
(1)通过问题预测模型计算出客户在实时操作的过程中可能会遇见的问题,并通过系统实时采集数据,并实时进行运算,从而在客户还未提出问题时,就能猜测到用户的真实意图,达到挽留客户的目的,有利于提升用户体验。
(2)通过积累的正负样本数据,及时分析badcase对模型进行训练和自学习,对不同用户、不同时段动态改变每个用户的有效因子,以及各因子权重,使之实时适应当前最新情况。
附图说明
图1为本发明的整体流程图;
图2为本问题预测模型的流程图;
图3为现有技术的流程图。
具体实施方式
本说明书中公开的所有特征,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。
下面结合附图对本发明作详细说明。
一种基于用户问题预测模型的减小线上客户流失的方法,包括如下步骤:
s1:用户进入互联网银行页面;
s2:判断用户身上是否带有强规则,如命中强规则,则走强规则逻辑,再猜测客户可能遇见的问题topn;如没有命中强规则,则进入问题预测模型,猜测客户可能遇见的问题topn;如强规则为:当用户为黑名单用户时,强规则触发,提示前端展示黑名单用户界面,并终止挽回策略,此时,如用户点击“个人中心-手机号码修改“时,可能会出现原手机号码接收不到短信、现手机号码接收不到短信等问题;所述强规则模型通过专家模型和人为经验得到。
s3:检测topn的问题中是否有需要报警的问题,如果有,则对客户发起对应挽回动作,再进行数据埋点;若没有需要报警的问题,则直接进行数据埋点;埋点数据将通过机器学习的方式反馈给问题预测模型中,进行问题预测模型调优处理;
s4:将判断失误的样本作为负样本,判断正确的样本作为正样本,将样本数据通过机器学习的方式反馈只问题预测模型进行调优处理;
s5:结束。
s2中,问题预测模型的步骤为:
s21:样本数据采集;
s22:将样本数据分为正样本数据和负样本数据,用户在实际环境中遇到的问题和银行匹配的问题一致为正样本,用户在实际环境中遇到的问题和银行匹配的问题不一致则为负样本;
s23:通过cnn卷积神经网络算法,提取正样本数据和负样本数据中的有效特征,计算详情如下:
通过计算即可从样本数据中抽取出对应有效特征。x随样本量的变化会进行动态调整。找出流失用户样本数据中所携带的信息数据及行为特征;
s24:权重训练,找出对应有效特征分类权重;
s25:产出模型文件;根据权重训练得出的结果,再根据预测概率进行排序,取靠前的用户问题作为用户可能遇见问题的预测结果topn。
另一方面,s24中,权重训练的方法为svm分类预测方法时,具体步骤如下:
s241:按照用户浏览时间维度、用户操作维度提取行为、操作历史数据;行为、操作历史数据包括页面pv、用户点击、用户填写、用户信息等历史数据;
s242:清洗行为、操作历史数据,提取转换特征;具体地,将用户浏览时间维度分为多个区间,每个区间内每一个维度的数据划分为多个区间;比如pv这个维度在页面category1下会形成以下特征;
s243:将转换特征向量化;根据步骤2提取的特征与特征的索引,将每一个用户用特征向量表示为:f=(f1,f2,f3,..,fn)
其中fi取值为0或则1,向量的维度表示特征的索引。
5.根据权利要求3所述的一种基于用户问题预测模型的减小线上客户流失的方法,其特征在于,s24中,权重训练是通过余弦相似度算法实现的,具体步骤为:
s241:提取样本数据,基于统计计算出用户行为特征,用户操作特征偏好,计算公式如下:
s242:将用户每一个特征偏好组合表示为特征偏好向量:
v1=(p1,p2,p3,…pn)
s243:将用户问题特征表示为向量:
v2=(1,0,1,…,0)
用户问题的的特征向量维度值取值为0或者1;
s244:计算余弦相似度:
其中simi值越大表示越相似;
s245:执行排序;根据simi值进行排序,取最相似的一部分用户判定用户的问题,并跟进权重排序。
s2中,样本数据包括:
用户的基本信息,例如“用户地址”、“用户姓名”、“用户身份证”、“用户注册时间”、“用户账户等级”等。
用户操作行为,例如“浏览界面”、“界面停留时间”、“浏览轨迹”、“输入时间”、“输入内容”、“点击轨迹”、“点击行为”等。
用户服务历史轨迹,例如“两小时内来电次数”、“72小时内用户是否通过自助渠道提问”、“用户是否求助过客服服务”等。
用户信用信息,例如“用户芝麻信用评分”、“用户白骑士评分数据”、“用户我行信用评分数据”、“用户是否黑名单用户”、“用户是否白名单用户”等。
页面日志数据,例如“页面pv“、”页面uv“、”页面报错次数“等。
其他数据,例如“今天星期几“、“社会舆情信息“、”今天几号“等。
现有技术的流程为:(1)用户开始进入;(2)用户浏览网页;(3)用户操作;(4)操作过程中点击选项决定是否进入下一环节,若用户进入下一环节,则继续重复网页浏览操作,知道业务办理完毕结束;若用户不进入下一环节,则在此环节停留一段时间后结束流程。可见,用户进入到页面后,银行没有对任何的客户问题可能遇见的问题进行识别以及采取相应的应对的措施,在获客成本高昂的情况下,用户进入页面即流失成本消耗极大,部分用户本可转化而因为没有采取实时有效措施而流失。
- 还没有人留言评论。精彩留言会获得点赞!