一种基于3DCNN的肺结节假阳性样本抑制方法与流程
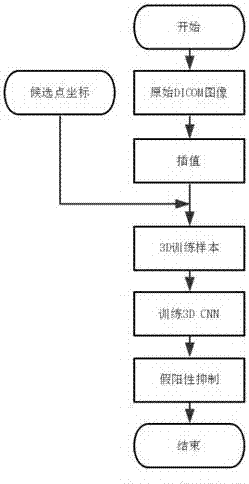
本发明属于医学影像的智能诊断领域,尤其涉及一种基于3dcnn的肺结节假阳性样本抑制方法。
背景技术:
:肺结节的检测对于肺部ct影像的处理十分关键,它是肺癌在早期状态的一种主要表现形式。而对于肺结节进行有效的早期检测和筛查能显著提高肺癌患者的五年存活率,因此具有十分重要的研究价值和意义。虽然目前随着ct影像技术和各种新型诊断、检测手段的出现和发展,以及各种新型ct技术的出现,使得肺癌的诊断相比之前变得相对容易,但因为在早期发现癌症仍然不易,而且新型ct技术,如多排ct产生数量巨大的ct片子,会给影像科医生的阅片增加繁重负担,在高强度的工作下,造成漏诊率偏高;再者,即使医生给出了结果,但对初期恶性肿瘤的误诊率较高,常常使得病人疏于防范,仍然不能在早期发现肺癌病例,造成发现时已经很难治愈。为了把影像科医生从繁重的阅片负担中解脱出来,众多科研人员先后研制了肺部影像计算机辅助诊断系统,即肺部cad(computeraideddiagnosis,计算机辅助诊断),辅助医生进行肺结节检测、肺结节良恶性判断等工作。当前相关研究领域中基于肺部ct影像进行计算机辅助肺结节的自动检测系统一般包括两个关键步骤:第一步是肺结节候选点检测,即通过一些阈值规则进行粗略的候选区域筛选,这些候选区域中,包含肺结节的则定义为阳性样本,否则定义为阴性样本或假阳性样本。第二步是假阳性样本抑制,即通过训练一个合适的肺结节分类器,对正负样本进行分类,最终选择出真正包含结节的候选区。通常情况下,由第一步检测得到的候选点中除了真实的阳性样本外,还会包含大量的假阳性样本,选用合适的技术方案对候选点中的假阳性样本进行抑制,是提高肺结节检测系统精度的重要步骤和手段。目前的假阳性样本抑制方法多基于传统的图像处理方法,这些方法基于阳性样本和假阳性样本之间的区别,通过人工选择和设计的特征来设计分类器,对真假阳性样本进行分类,从而达到假阳性样本抑制的效果。但肺结节的真假阳性样本区分度十分不明显,人工选择和设计能够将其区分开来的特征任务复杂,往往需要具有丰富专业知识的研究者长达数年的研究,才能选择出符合任务需求的特征,建立分类器;而一旦任务发生了变化,已经选择和设计的特征失效,还需要根据新任务的特点选择和设计新的特征。如此研究,耗费大量的人力物力,还不能取得令人满意的效果。深度学习是近年来随着各类研究中数据量的增大、计算机计算能力的增强以及人工神经网络模型中的一些关键技术的推演而由传统人工神经网络发展来的具有强大拟合和泛化能力的分析模型。因为其不需要研究者手动选择和设计特征,能够根据不同的具体应用自动对图像中的特征进行分析提取,深度学习在图像分析处理中获得了广泛应用,并取得了很大成功。比如在经典的imagenet图像分类识别比赛中,深度学习如今已经具有统治地位,基于深度学习而开发的算法已经获得了超越人类水平的结果[1][2]。对ct影像进行肺结节检测和假阳性抑制是一个典型的图像处理中的识别和分类任务,使用基于深度学习技术而研发的3d深度网络能够综合分析肺结节的3d图像特征,并通过对损失函数的加权操作巧妙地解决真假阳性样本不均衡的问题,从而训练出对肺结节特征进行有效提取并对真假阳性样本精准分类的3d深度神经网络模型,解决这一肺部cad系统中的重要问题。技术实现要素:本发明的目的在于提供一种基于3dcnn的肺结节假阳性样本抑制方法,旨在通过训练3dcnn模型对肺部ct图像中检测到的肺结节候选点进行假阳性抑制,以达到准确检测肺结节,从而筛查早期肺癌,提高潜在肺癌病人的生存可能性。为实现上述目的,本发明提供的基于3dcnn的肺结节假阳性样本抑制方法包括以下步骤:a)从肺部ct影像序列数据中检测肺结节候选点坐标;b)对原始的dicom图像进行插值,得到插值后的3d原始图像数据;c)对此前检测得到的候选点坐标,按照如上b)插值步骤进行相应处理,将其映射到插值后的3d原始图像数据上;d)对于每个候选点,根据其转换后的坐标,从插值后的3d原始图像数据中切出3d数据,作为训练样本;e)根据每个候选点的坐标,与原始图像中的标签(label)进行对应,为步骤c)中切出的每一个3d数据贴上相应的label;f)使用准备好的3d数据训练3dcnn网络;g)使用训练得到的3dcnn模型对候选点进行假阳性抑制。进一步地,所述步骤b)中对原始dicom图像进行插值,将z方向的切片间隔(spacing)插值为与x、y方向的像素间隔相等。这样,在插值完成后,x、y、z三个方向的间隔相等。进一步地,所述步骤d)中,根据转换后的候选点坐标,从插值后的3d原始图像数据中切出3d数据,切出数据的长宽高(x、y、z方向)均为40像素,即数据大小为40×40×40。随后对切出的数据进行如下处理:将小于-1000hu的数据置为-1000hu,将大于400hu的数据置为400hu,并将处理后的图像数据归一化到0到1之间。如果候选点为阳性样本,则还需要对其进行数据扩充(augmentation),扩充方式包括平移、缩放和旋转等。对每一个阳性样本扩充个数大约为阴性样本总数除以原始阳性样本个数(如果所除结果不是整数,则取最近的整数),以使得扩充后的阴阳性样本均衡。进一步地,所述步骤e)中,为每一个3d数据贴上相应的label:如果候选点距任意一个结节的外接边框(boundingbox)中心点的距离小于该结节的半径,则候选点的label为1;否则,该候选点的label为0。进一步地,所述步骤f)中,使用准备好的3d数据训练3dcnn网络,网络结构(如图2)如下:输入为40×40×40大小的3d数据,逐步通过以下网络层进行处理:卷积层1:16个大小为3×3×3的卷积核prelu层1最大池化层1:大小为2×2×2的池化核卷积层2:32个大小为3×3×3的卷积核prelu层2最大池化层2:大小为2×2×2的池化核卷积层3:64个大小为3×3×3的卷积核prelu层3最大池化层3:大小为2×2×2的池化核卷积层4:128个大小为3×3×3的卷积核prelu层4最大池化层4:大小为2×2×2的池化核输出数据拉伸为大小为128×2×2×2即1024的一列数据全连层1:大小为1024×32的核dropout层:drop概率为0.5全连层2:大小为32×2的核softmax层得到的输出,即为输入样本分别属于阴阳性样本的概率。进一步地,所述步骤f)中3dcnn网络模型中权值参数的初始化使用khe等[3]提出的初始化激活函数为relu的神经网络的方式完成,该方法以方差为输入到当前层的神经元个数的倒数的2倍的截断高斯分布小随机数来初始化当前层的权值参数,如下:var=2/nin。进一步地,所述步骤f)中训练3dcnn模型时,其loss函数如下:loss=weighted_sparse_softmax_cross_entropy+l1_l2_regularizer其中,weighted_sparse_softmax_cross_entropy为加权稀疏交叉熵损失函数,其通过如下方式构建:对于原始的阳性样本,计算其标准的稀疏交叉熵损失函数得到损失值,并乘以一个权重,将所得乘积作为该样本的损失值;对于其他样本,使用标准的稀疏交叉熵损失函数,计算其损失值;对于任一batch的所有样本,将使用以上方法得到的加权损失值和不需加权的原始损失值求和,将其作为该batch最终的加权稀疏交叉熵损失函数值;其中公式中的l1_l2_regularizer为对3dcnn模型中的各可训练参数如权值和偏差添加l1和l2正则化项,以保证训练得到的参数的稀疏性,并保证其具有较小值,从而达到抑制模型过拟合的目的。进一步地,所述步骤f)中训练3dcnn模型时,其学习速率设定一个初始值0.01,随后随着训练过程进行衰减调整,在训练的一个epoch中衰减5次,每次变为原来的学习速率的0.95倍。在本发明的技术方案中,先从样本中检测到肺结节候选点,建立3d训练样本,再通过这些样本训练3d深度神经网络,训练出对肺结节特征进行有效提取并对真假阳性样本精准分类的3d深度神经网络模型。该发明方法使用损失函数的加权操作巧妙地解决真假阳性样本不均衡的问题,而在3dcnn网络模型中权值参数的初始化使用khe等[3]提出的初始化激活函数为relu的神经网络的方式能更好地达到目的,将本发明使用于医学临床上,能够精准高效的检测肺结节,从而筛查早期肺癌,提高患者生存可能性。附图说明图1是本发明方法流程图。图2是本发明方法3dcnn网络结构图。图3是本发明名3d肺结节样本实例。图4是基于肺结节候选点训练的模型的froc曲线。具体实施方式下面结合附图和实例来说明基于3dcnn的肺结节假阳性样本抑制方法在实际中的应用,并对本发明做进一步的说明和解释。以被本领域研究者广泛关注和使用的肺部ct影像公开数据库lidc中的888个切片间隔在2.5mm以内(切片间隔大于2.5mm的对小结节的研究效果大打折扣,故忽略)的病例来进行本方法的演示和说明,并随机选择其中第582个病例(seriesuid为1.3.6.1.4.1.14519.5.2.1.6279.6001.100621383016233746780170740405)进行本方法中数据处理部分的演示和说明。步骤一:前期使用候选点检测方法得到的肺结节候选点中心坐标如下所示:-76.62,156.53,-529.43120.13,160.73,-404.6894.23,171.24,-392.76等等。第582个病例一共有602个候选点,全部lidc病例一共有55万余肺结节候选点。在此示例中,检测出的候选点坐标为世界坐标。步骤二:对该病例的原始图像数据进行插值处理,得到插值后的图像数据。对应于每一个肺结节候选点的x,y,z坐标,根据对病例数据进行的插值处理过程,对中心坐标进行相应的处理和转换,并将其转换为像素坐标。步骤三:根据转换后的病例图像数据和肺结节候选点的中心点坐标,从病例图像数据中切出大小为40×40×40像素的立方体,作为该结节候选点的图像数据。步骤四:根据肺结节候选点的阴阳性,决定是否对该候选点进行数据扩充。因为我们检测出的候选点一共有55万个左右,而阳性样本(即涵盖肺结节的样本)一共有1351个,所以,为保证正负样本的均衡,我们对阳性样本进行55万除以1351,即大约408倍的数据扩充。考虑到病例数据和肺结节的特点,我们选择的数据扩充方式包括:平移、缩放和旋转。平移范围在±5个像素之间,缩放比例在图像的0.9到1.1倍之间,旋转则在±30°之间。步骤五:根据以上处理,生成用以训练模型的数据,并根据以上分析,该数据一共有大约55万×2,即110万个;此外,为了保证训练效果的最优化,我们对该数据进行了一个随机乱序。同时,为了接下来对损失函数进行加权处理的方便,我们维护了一个用以记录这110万个数据的顺序的文件,该文件中记录了每个数据的病例id、真假阳性、是否通过数据扩充得到,等等。从生成的数据中随机取出的一个肺结节图像图3所示。步骤六:根据以上生成的肺结节候选点数据训练3dcnn深度神经网络,网络结构图在前面已经进行了详细描述。此处需要注意的是,需要根据不同的数据对损失函数进行处理,包括是否需要对其进行加权,等等。比如,如果数据属于原始的55万个假阳性样本,或者数据属于阳性样本经数据扩充得到的样本,则对其损失值不进行特别处理;而对于1351个阳性样本,则需要对其损失值进行加权处理,权值取为55万除以1351,即408。同时,为处理的简便考虑,直接将由1351个阳性样本得到的损失值乘以这个权值,并将其作为最终损失值。步骤七:依以上分析和处理训练3dcnn,神经网络的权值初始化使用以方差为输入到当前层的神经元个数的倒数的2倍的截断高斯分布小随机数来完成,训练的一个迭代(epoch)中有110万个样本。对学习速率的选择和处理如下:初始学习速率取为0.01,每经过1/5个迭代过程,即大约22万步训练之后,学习速率下降为原来的0.95倍。如此迭代训练,直到110万个样本中1351个真阳性样本的总体正确率达到98%以上(当然,也可以根据具体需求,对其进行灵活选择),或者根据我们的经验,训练2个epoch后保存模型停下即可。模型的训练在ubuntu上基于google的tensorflow框架完成。下面列举分析本示例在选出的lidc的888个病例上使用本发明的方法训练3dcnn进行假阳性抑制的效果。图4是基于551065个肺结节候选点训练的模型的froc曲线,888个病例中平均每个病例有大约620个左右的候选点,包含1351个真阳性候选点。这些前期由其他检测方法检测出的候选点涵盖了所有1186个结节中的1120个,其敏感度为94.4%。将图4中的数据摘录如下表:假阳性0.1250.250.51248~620敏感度0.7470.8260.8950.9300.9400.9430.94360.944最初的检测结果为,在每个病例有大约620个假阳性样本的情况下,其敏感度为94.4%;经过使用本发明的方法训练的3dcnn模型进行假阳性抑制之后,在抑制掉大量假阳性样本的情况下,可以保持与检测结果基本相同的敏感度。这证明了本发明的方法在对肺结节假阳性样本进行假阳性抑制时的有效性。参考文献[1]a.krizhevsky,i.sutskever,andg.e.hinton,“imagenetclassificationwithdeepconvolutionalneuralnetworks,”inadvancesinneuralinformationprocessingsystems,2012,pp.1097–1105.[2]k.he,x.zhang,s.ren,andj.sun,“deepresiduallearningforimagerecognition,”arxivprepr.arxiv1512.03385,2015.[3]k.he,x.zhang,s.ren,andj.sun,“delvingdeepintorectifiers:surpassinghuman-levelperformanceonimagenetclassification,”inproceedingsoftheieeeinternationalconferenceoncomputervision,2016。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1