一种基于社交网络的位置预测系统及方法与流程
本发明属于社交网络位置预测技术领域,尤其涉及一种基于社交网络的位置预测系统及方法。
背景技术:
随着互联网的快速发展和可定位设备的大量普及,基于地理位置服务的网络应用越来越普及,如定向广告(targetedadvertisement)、跟踪人口流动、预防疾病蔓延、网络安全、性能优化等,地址位置作为一种质量极高的信息资源被广泛应用。同时伴随着在线社交网络的发展,位置服务和在线社交网络逐渐趋于融合,即产生了lbsn。基于位置的lbsn是位置和社交的结合体,它支持用户随时随地在社交平台记录并分享自己的地理信息,它是以通信网络为媒介,以智能终端为主要载体的新型平台。在lbsn中,大量用户通过签到向朋友分享位置信息或地理标签。位置社交网络让基于位置的社交成为一种新的社交模式,使得线上社交和线下社交得到有机的结合,极大的改变了人们的生活方式。社交网络催生了许多基于位置的服务,为了提供更好的服务,预测用户最有可能的下一个位置是非常重要的。如通过预测用户下一个位置,商家可以更加有效的投放定向广告。现有预测方法有基于gps轨迹历史数据的位置预测,有基于社交网络签到数据的位置预测。社交网络签到数据和gps轨迹历史数据有着明显的区别。社交网络签到历史数据较稀疏,位置预测范围较大。相比于社交网络签到数据,连续记录的gps数据之间间隔5-10米。但是gps数据仅仅包括经度、纬度和时间戳信息,没有包括语义信息,无法根据社交关系进行位置预测。现有的基于社交网络的位置预测主要有运动轨迹的预测和下一地点的预测。运动轨迹的预测相对复杂,开销较大,对周期性轨迹预测表现良好,但是对周期性不明显的轨迹预测精度较差。现有基于社交网络下一位置预测假设下一位置用户曾经访问过,下一位置仅仅从个人历史位置中选择,容易造成“冷启动”,导致常规位置预测良好,非常规位置预测精度较低。
综上所述,现有技术存在的问题是:现有基于gps历史数据位置预测不包含语义信息,无法根据社交关系进行位置预测。现有的基于社交网络轨迹相似性位置预测存在运动轨迹预测相对复杂,开销较大,对周期性不明显的轨迹预测精度较差,容易造成“冷启动”。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于社交网络的位置预测系统及方法。
本发明是这样实现的,一种基于社交网络的位置预测方法,所述基于社交网络的位置预测方法包括以下步骤:
步骤一,爬取社交网络签到数据;
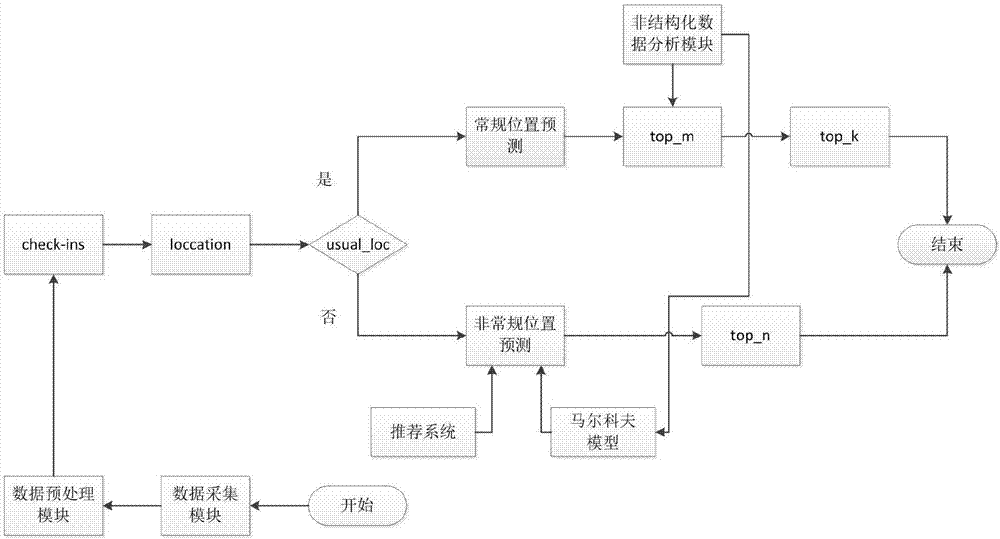
步骤二,对爬取的社交网络签到数据进行预处理,过滤掉签到次数小于平均签到次数的数据,清洗掉无效的数据,利用核平滑插值技术对签到数据的稀疏性进行处理;在f(x)中,若使用邻域样本的均值进行插值,则使f(x)不平滑,所以使用一个核函数对估计值平滑;具体使用核加权平均,公式为:
步骤三,结合常规位置预测的输出概率pr(loc)和非常规位置预测的输出概率pu(loc),预测下一位置是否为常规位置;
步骤四,通过常规位置预测模块,得到top-m个位置列表;通过提取分析数据采集模块中采集的非结构化信息,应用于top-m位置列表,提高位置预测精度,得到top-k个位置列表,k<=m。
进一步,所述预测下一位置是否为常规位置公式为:
p(loc)=λpr(loc)+(1-λ)pu(loc)。
其中pr(loc)为常规位置预测概率,pu(loc)为非常规位置预测概率,λ为调节参数,λ∈{0,1}。
进一步,所述常规位置预测采用mhmm算法,hmm结合时间特征和空间特征对位置进行预测。不考虑时间和空间的影响,给定相同的观测序列,hmm总是得到相同的预测结果;考虑到社交用户的签到行为受到时间和空间的影响,选用混合hmm算法对下一位置进行预测。
进一步,所述非常规位置预测结合构建知识图谱,挖掘社交关系,采用融合社交关系的马尔科夫模型结合位置推荐系统对非常规位置进行预测。利用签到数据集构建知识图谱,在知识图谱上进行推理,挖掘相似用户,基于历史签到数据并融合相似用户训练一个马尔科夫模型对下一位置进行预测。最后将马尔科夫模型和位置推荐系统结合在一起,提高位置预测精度。
进一步,利用签到数据集作为数据来源,构建社交知识图谱,在知识图谱上进行推理。推理方法有三类:embedding-based技术,pathrankingalgorithms,和probabilisticgraphicalmodels概率模型。社交关系的推理采用embedding-based技术。embedding-based技术是以隐式因子模型为基本思想的方法,它是基于低维向量的表示方法,将知识图谱中的实体和关系在低维的向量空间里进行表达,然后进行推理。首先将实体和关系进行向量表示;其次,定义打分函数来衡量关系成立的可能性。再者,参数估计,根据打分函数推理相似用户。相似用户推理综合打分函数结构化信息和非结构化分析模块提取的兴趣相似度,表示如下:
sim(u,v)=αs(u,v)+(1-α)w(u,v);
其中,α是调节参数,取值为[0,1],反应结构化信息和非结构化信息相似度所占比重,s(u,v)代表结构化信息相似度,w(u,v)代表非结构信息相似度。非结构化信息相似度是非结构信息分析模块提取兴趣关键字,然后根据余弦相似度计算用户之间的相似度。计算如下:
其中ui,uj表示用户i和用户j兴趣关键字向量表示。余弦值取值范围为[0,1],0表示完全不同,1表示完全相同。
在历史签到数据的基础上,融合相似用户的影响,训练马尔科夫模型对位置进行预测,即lm=maxp(am|h,sim(u,v)),其中am代表马尔科夫算法,h代表历史签到数据,sim(u,v)代表用户相似度。
最后,综合融合相似用户的马尔科夫模型和位置推荐系统,提高位置预测精度。其公式如下:
ltop-n=βlm+(1-β)sr;
其中lm代表融合相似用户的马尔科夫模型,sr代表位置推荐系统,β为调节权重,取0.6。综合融合相似用户的马尔科夫模型和位置推荐系统,得到top-n位置列表。
本发明的另一目的在于提供一种所述基于社交网络的位置预测方法的基于社交网络的位置预测系统包括:
数据采集模块,应用爬虫系统,爬取社交网络签到数据;
数据预处理模块,对爬取的社交网络签到数据进行预处理,清洗掉无效的数据,利用核平滑插值技术对签到数据的稀疏性进行处理;
判断模块,结合常规位置预测的输出概率pr(loc)和非常规位置预测的输出概率pu(loc),预测下一位置是否为常规位置;
常规位置预测模块,用于对预测位置进行分类,先预测位置的类别,预测位置;
非结构化数据分析模块,通过常规位置预测模块,得到top-m个位置列表;通过提取分析数据采集模块中采集的非结构化信息,应用于top-m位置列表,提高位置预测精度,得到top-k个位置列表;
非常规位置预测模块,结合构建知识图谱,挖掘相似用户,采用融合相似用户的马尔科夫模型结合位置推荐系统对非常规位置进行预测。
本发明的另一目的在于提供一种应用所述基于社交网络的位置预测方法的社交网络终端。
本发明的优点及积极效果为:基于社交网络签到数据,结合模糊聚类、知识图谱和位置推荐对下一地点进行预测,既适用于常规模式位置预测,又适用于非常规模式位置预测。本发明结合时间和位置因素对位置预测的影响,充分挖掘社交网络签到信息中的语义信息,解决了常规位置预测问题,同时通过对非常规位置预测解决了位置预测中的“冷启动”问题。本发明运用知识图谱,挖掘隐含相似用户;运用概率论知识预测下一位置为常规位置或非常规位置。对于非常规位置,结合位置推荐系统,提高非常规位置预测精度。
附图说明
图1是本发明实施例提供的基于社交网络的位置预测方法流程图。
图2是本发明实施例提供的基于社交网络的位置预测方法实现流程图。
图3是本发明实施例提供的基于社交网络的位置预测系统结构示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
下面结合附图对本发明的应用原理作详细的描述。
如图1所示,本发明实施例提供的基于社交网络的位置预测方法包括以下步骤:
s101:爬取社交网络签到数据;
s102;对爬取的社交网络签到数据进行预处理,清洗掉无效的数据,利用核平滑插值技术对签到数据的稀疏性进行处理;
s103:结合常规位置预测的输出概率pr(loc)和非常规位置预测的输出概率pu(loc),预测下一位置是否为常规位置:
s104:通过常规位置预测模块,得到top-m个位置列表;通过提取分析数据采集模块中采集的非结构化信息,应用于top-m位置列表,提高位置预测精度,得到top-k个位置列表(k<=m)。
常规位置预测采用mhmm算法,hmm结合时间特征和空间特征对位置进行预测。不考虑时间和空间的影响,给定相同的观测序列,hmm总是得到相同的预测结果;考虑到社交用户的签到行为受到时间和空间的影响,选用混合hmm算法对下一位置进行预测。
所述非常规位置预测结合构建知识图谱,挖掘社交关系,采用融合社交关系的马尔科夫模型结合位置推荐系统对非常规位置进行预测。利用签到数据集构建知识图谱,在知识图谱上进行推理,挖掘相似用户,基于历史签到数据并融合相似用户训练一个马尔科夫模型对下一位置进行预测。最后将马尔科夫模型和位置推荐系统结合在一起,提高位置预测精度。
利用签到数据集作为数据来源,构建社交知识图谱,在知识图谱上进行推理。推理方法有三类:embedding-based技术,pathrankingalgorithms,和probabilisticgraphicalmodels概率模型。社交关系的推理采用embedding-based技术。embedding-based技术是以隐式因子模型为基本思想的方法,它是基于低维向量的表示方法,将知识图谱中的实体和关系在低维的向量空间里进行表达,然后进行推理。首先将实体和关系进行向量表示;其次,定义打分函数来衡量关系成立的可能性。再者,参数估计,根据打分函数推理相似用户。相似用户推理综合打分函数结构化信息和非结构化分析模块提取的兴趣相似度,表示如下:
sim(u,v)=αs(u,v)+(1-α)w(u,v);
其中,α是调节参数,取值为[0,1],反应结构化信息和非结构化信息相似度所占比重,s(u,v)代表结构化信息相似度,w(u,v)代表非结构信息相似度。非结构化信息相似度是非结构信息分析模块提取兴趣关键字,然后根据余弦相似度计算用户之间的相似度。计算如下:
其中ui,uj表示用户i和用户j兴趣关键字向量表示。余弦值取值范围为[0,1],0表示完全不同,1表示完全相同。
在历史签到数据的基础上,融合相似用户的影响,训练马尔科夫模型对位置进行预测,即lm=maxp(am|h,sim(u,v)),其中am代表马尔科夫算法,h代表历史签到数据,sim(u,v)代表用户相似度。
最后,综合融合相似用户的马尔科夫模型和位置推荐系统,提高位置预测精度。其公式如下:
ltop-n=βlm+(1-β)sr;
其中lm代表融合相似用户的马尔科夫模型,sr代表位置推荐系统,β为调节权重,取0.6。综合融合相似用户的马尔科夫模型和位置推荐系统,得到top-n位置列表。
图2是本发明实施例提供的基于社交网络的位置预测方法实现流程图。
如图3所示,本发明实施例提供的基于社交网络的位置预测系统包括:
数据采集模块,应用爬虫系统,爬取社交网络签到数据。
数据预处理模块,对爬取的社交网络签到数据进行预处理,清洗掉无效的数据,然后利用核平滑插值技术对签到数据的稀疏性进行处理。
判断模块,结合常规位置预测的输出概率pr(loc)和非常规位置预测的输出概率pu(loc),预测下一位置是否为常规位置:
p(loc)=λpr(loc)+(1-λ)pu(loc),λ∈{0,1}。
常规位置预测模块,常规位置即频繁模式,周期性模式;如8点半上班,中午12点在公司附近午餐,下午6点半下班回家,回家后在家看电视不外出。常规位置预测精度受到时间因素、地理因素和历史数据的影响。采用ghmm算法,hmm结合时间特征和空间特征对位置进行预测。为了克服预测范围大的困难,首先对预测位置进行分类,先预测位置的类别,然后进一步预测位置。
非结构化数据分析模块,通过常规位置预测模块,得到top-m个位置列表。非结构化预测模块通过提取分析数据采集模块中采集的非结构化信息,应用于top-m位置列表,提高位置预测精度,得到top-k个位置列表(k<=m)。
非常规位置预测模块,位置预测不仅涉及常规位置,由于人们的新奇特性,随众模式,在移动模式上会表现出对非常规位置的探索。如周六去看电影,周天去购物等。非常规位置预测模块结合非结构化分析模块,同时构建知识图谱,挖掘相似用户,采用融合相似用户的马尔科夫模型结合位置推荐系统对非常规位置进行预测。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!